Convolutional Neural Network
-
input(입력 데이터)
-
feature extraction(특징이 추출되는 부분 Conv~Pooling)
-
classification(분류를 위한 신경망)
-
cnn은 이미지의 공간적 특성을 보존하며 학습할 수 있음(이미지의 일부분을 훑으면서 연산이 진행되고 특징을 잡아내면서 학습하기 때문에 층이 깊어지더라도 공간적 특정을 보존함)
padding
- 이미지 외부를 특정한 값으로 둘러싸서 처리해주는 방식
- 이미지가 급격하게 작아지는 것을 방지
- 이미지의 테두리라는 것을 네트워크에 알려줌
- 연산된 output은 feature map의 크기를 조절하고 실제 이미지 값을 충분히 활용하기 위해 사용됨
Convolution
- 합성곱 필터가 슬라이딩 하며 이미지 부분의 특징을 읽어나감
Stride
- 슬라이딩 시에 몇 칸 씩 건너뛸지를 나타냄
pooling(=sampling)
- conv layer에서 resize(=sampling)하는 것을 pooling이라고 함
- pooling 한 값을 다시 쌓음
- 풀링 층은 학습해야할 가중치가 없으며 채널 수가 변하지 않는다는 특징을 가짐
max pooling
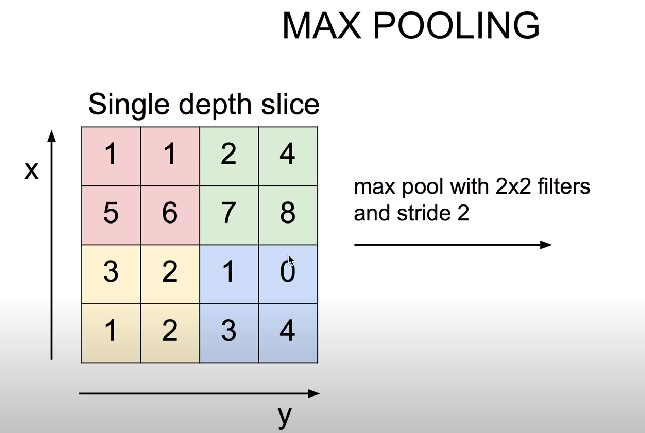
- 2*2안에 있는 값들 중 가장큰 값을 사용
일반적으로 이미지를 처리할 땐 각 부분의 특징을 최대로 보존하기 위한 최대 풀링을 사용
fully connected layer
- 완전 연결 신경망(=분류기)
- 완전 연결 신경망은 다층 퍼셉트론 신경망으로 구성되어 있으며 풀어야 하는 문제에 따라 출력층을 잘 설계해야함
LeNet-5
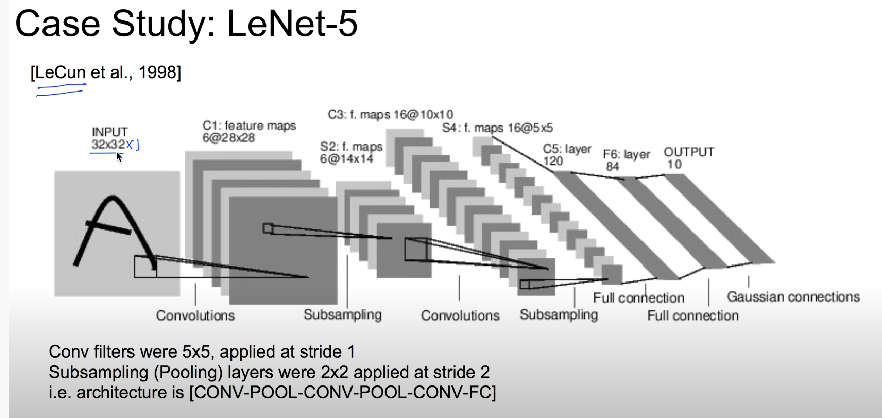
구조
- 인풋 레이어, 3개의 컨볼루션 레이어(c1, c3, c5), 2개의 서브 샘플링(s2, s4), 1층의 full-connected 레이어, 아웃풋 레이어
- c1부터 f6까지 활성화 함수로 tanH을 사용함
AlexNet

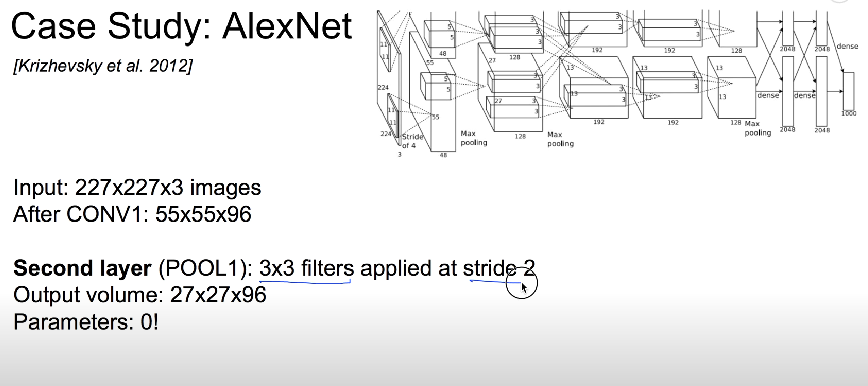
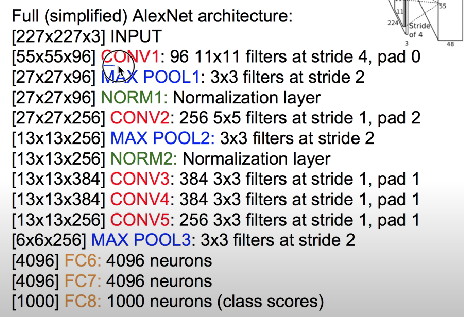
detail/retrospectives
- relu를 처음 사용함
- Norm layer를 사용했으나 이제는 더이상 사용하지 않음(필요성을 못느끼기 때문)
- 무거운 데이터 증강
- dropout 0.5
- batch size 128
- SGD Momentum 0.9
- learning rate 1e-2
- L2 가중치 감소 5e-4
- 7 CNN 앙상블: 18.2% => 15.4%로 에러를 줄이게 됨
- LeNet-5와 비슷하며 더 크고 깊은 구조
- 처음으로 합성곱 층 위에 풀링층을 쌓지 않고 합성곱 층끼리 쌓음
- 과대적합을 줄이기위해 2가지 규제 기법을 사용함
- 드롭아웃
- 데이터 증식
- LRN이라 부르는 경쟁적인 정규화 단계 사용
- 가장 강하게 활성화된 뉴런이 다른 특성 맵에 있는 같은 위치의 뉴런을 억제함
- 특성 맵을 각기 특별하게 다른 것과 구분되게 하고, 더 넓은 시각에서 특징을 탐색하도록해 일반화 성능을 향상시킴
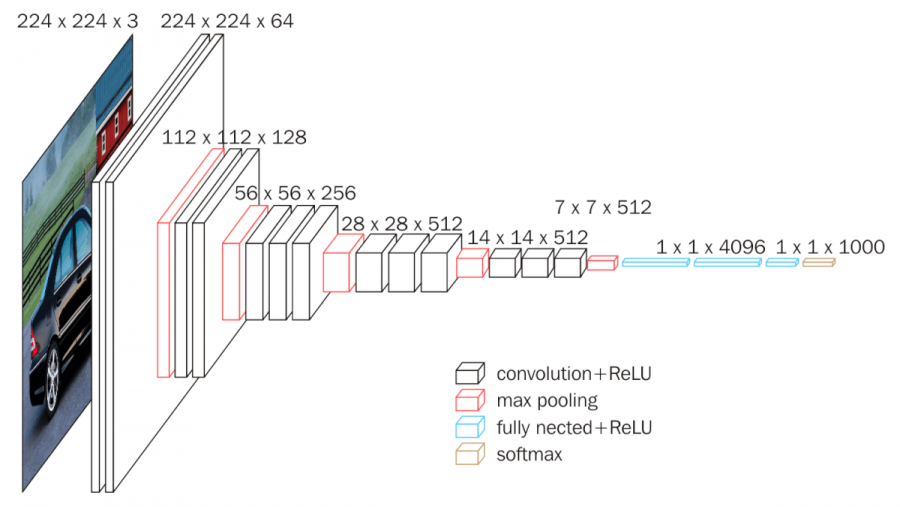
VGG
- 모든 conv 층에서 33 크기의 필터 사용
(층을 깊게 쌓으면서 77, 11*11 크기의 필터 이상의 표현력을 가질 수 있도록 함) - 활성화 함수로 ReLU를 사용하고 가중치 초깃값으로 He초기화를 사용
(층을 깊게 쌓았음에도 기울기 소실 문제가 발생하지 않음) - 완전 연결 층에 Dropout을 사용해 과적합 방지, 옵티마이저는 아담 사용
Google net
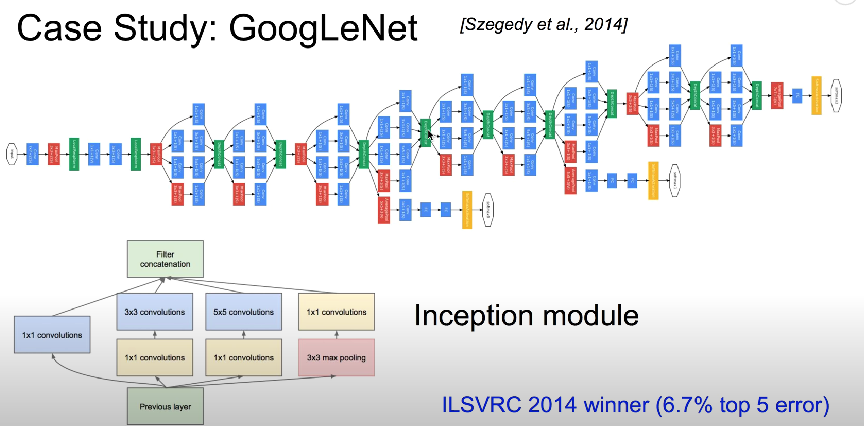
- 가로 방향으로 넓은 신경망 층을 가지고 있으며 이렇게 가로 방향으로 층을 넓게 구성한 것을 인셉션 구조라고 함
- 인셉션 구조를 활용해 크기가 다른 필터와 풀링을 병렬적으로 적용한 뒤 결과를 조합함
ResNet
- 152개의 layers
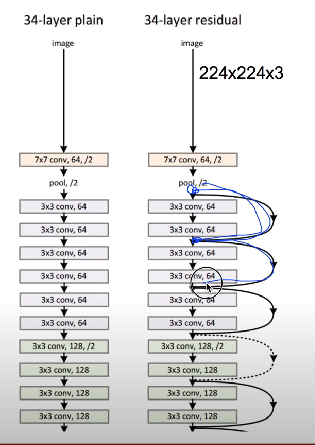
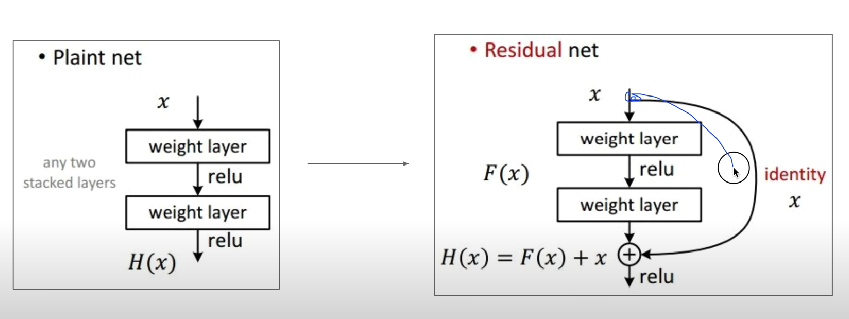
residual connection
- 층을 거친 데이터의 출력에 거치지 않은 출력을 더해줌
- 이 과정덕에 역전파 시 미분을 적용해도 1이상의 값으로 보존되어 기울기 소실 문제를 해결해줌
Sequence data
- 음성 인식, 자연어 같이 시리즈 형식일 때
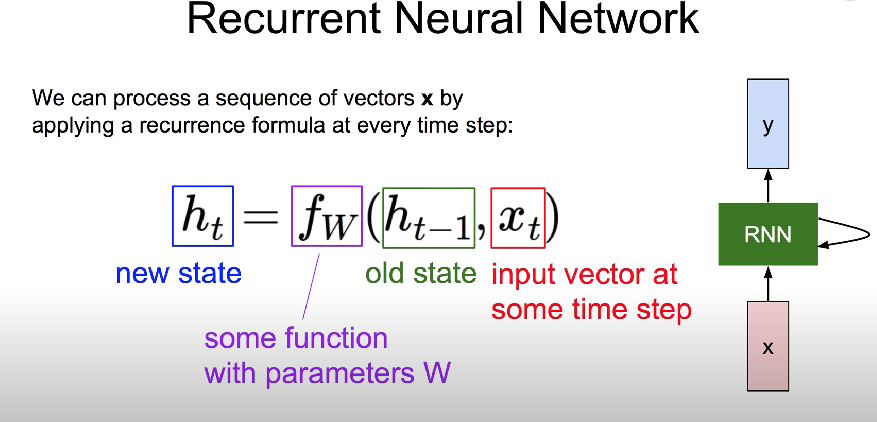
- x라는 입력값과 old state를 가지고 새로운 스테이트를 계산
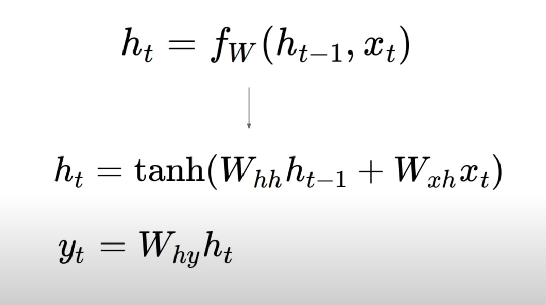

안녕하세요. 기억보다 기록을 믿는 레나입니다!