vanising gradient
- 그림 왼쪽으로 갈수록 경사도가 사라지고 있음 == 학습하기 어렵다 == 그림 가장 왼쪽의 입력이 가름 가장 오른쪽 결과에 영향을 미치지 않는 다는 것

- 이 문제 때문에 NN은 2차 겨울에 들어감
문제가 해결되는데..How?
- we used the wrong type of non-linearity
시그모이드를 잘 못 쓴거 같음 다른걸 써보자! - 기존 시그모이드 문제점: 입력값이 1보다 작아짐, 체인룰로 인해 계속 1보다 작은 값으로 곱해나가니까
ReLU(Rectified Linear Unit)
- 0보다 작으면 반응 안함
- 0보다 크면 무한대로 커짐(activation)
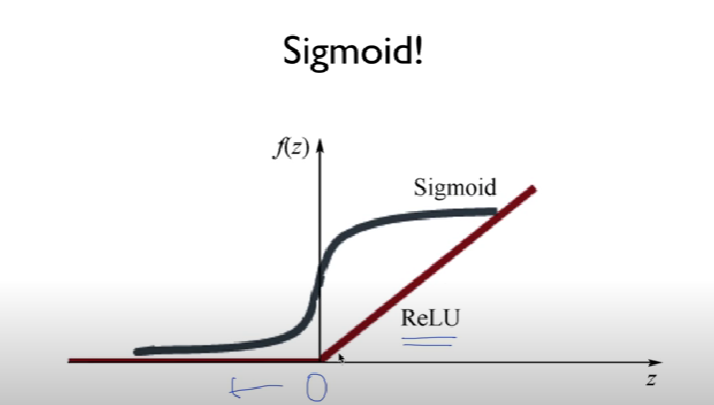
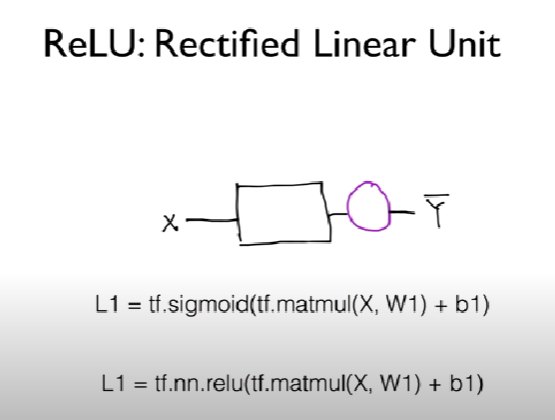
- activation 값에 relu를 넣어줌
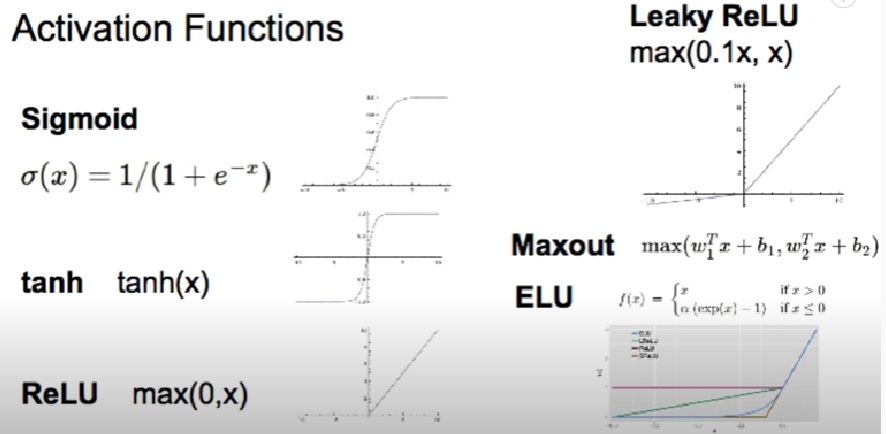
다양한 activation functions
Need to set the initial weight values wisely
- Not all 0's => 네트워크가 학습이 안됨
어떤방법으로 초기화?
- Restricted Boatman Machine(RBM)
- 지금은 많이 사용하지 않음
- 레이어 두개가 있을때 인코더 디코더를 계속해서 초기값(=내가 준값)과 유사하게 만드는 것
- 근데 RBM은 복잡해서 간단한 방법이 있음
simple method
1. Xavier initialization
- 하나의 노드에 몇개의 입력값과 출력값을 가지는지를 알고 그거에 맞게 초기값을 설정함
2. He's initialization
- relu 사용시 Xavier 초기값 설정이 비효율적인 것을 확인
- he 초기화 방법을 사용하는데 이때 정규분호와 균등 분포 두가지 방법이 사용됨
Dropout과 Ensenble
- 하는 이유는 오버피팅때문에
- 학습에서는 99퍼, 테스트 데이터에는 85퍼일때
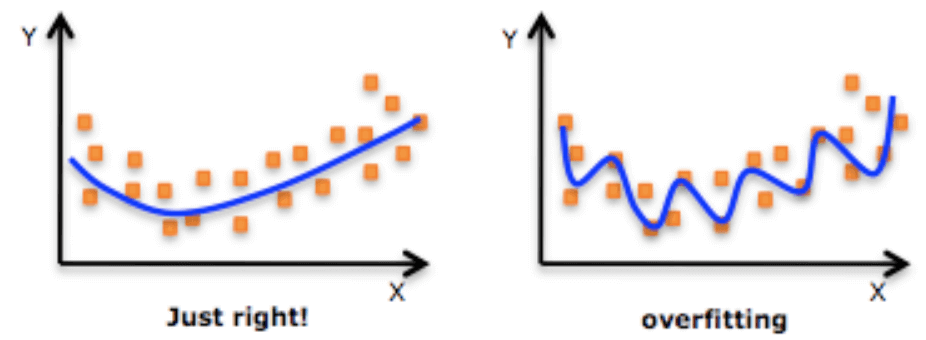
solutions for overfitting
- more training data
- reduce the number of features(딥러닝에서는 안그대로 됨)
- regularization
regularization
- 가중치를 너무 크게 주지 말자(=분류할때 너무 구불거리게 분류하지 말자)
Dropout
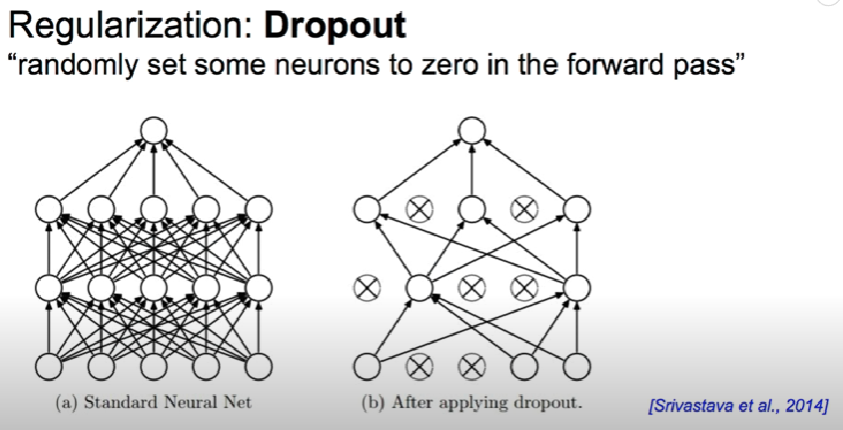
- 랜덤으로 뉴런들을 끊어서 버리자
Ensenble
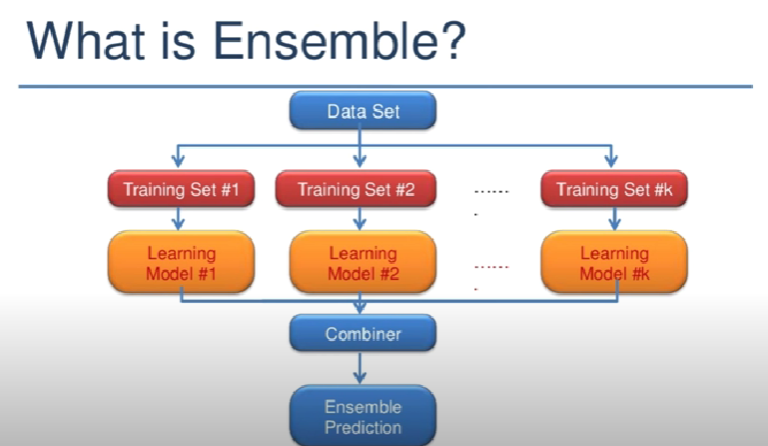
- 트레인셋 여러개를 주고 동일한 형태의 딥러닝을 만들음 => 각각 학습을 시킴 => 마지막에 합쳐서 결과를 냄

안녕하세요. 기억보다 기록을 믿는 레나입니다!