
Data Wrangling
데이터 랭글링은 분석을 하거나 모델을 만들기 전에 데이터를 사용하기 쉽게 변형학나 맵핑하는 과정
보통 모델링 과정 중 가장 많은 시간이 소요되는 단계
데이터를 학습모델에 돌리기 전에 수행하는 전처리과정에 포함된 다른용어다라고 생각하면 됨
raw data>formatted data > modeling
!pip install tqdm
import requests #http 요청을 보내는 모듈
from tqdm.notebook import tqdm #파이썬 진행 프로세스바
def download_file(url):
filename = url.split('/')[-1]
chuckSize = 1024
r = requests.get(url, stream=True)
with open(filename, 'wb') as f:
pbar = tqdm(unit="KB", total=int(r.headers['Content=Length]))
for chunk in r.iter_content(chunk_size=chunksize):
if chunk:
pbar.update(len(chunk))
f.write(chunk)
downloda_file('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/instacart/instacart.zip')
#압축 해제
import zipfile
with zipfile.ZipFile('instacart.zip', 'r') as zip_ref:
zip_ref.extractall() #extractall 모든파일 압축해제
#압축해제 후 만들어진 폴더로 이동
%cd instacart
#csv 파일을 프린트
from glob import glob
for filename in glob('*.csv'):
print(filename)
# 각 파일의 shape, head를 출력
from IPython.display import display
import pandas as pd
def preview():
for filename in glob('*.csv'):
df = pd.read_csv(filename)
print(filename, df.shape)
display(df.head())
print('\n')
priview()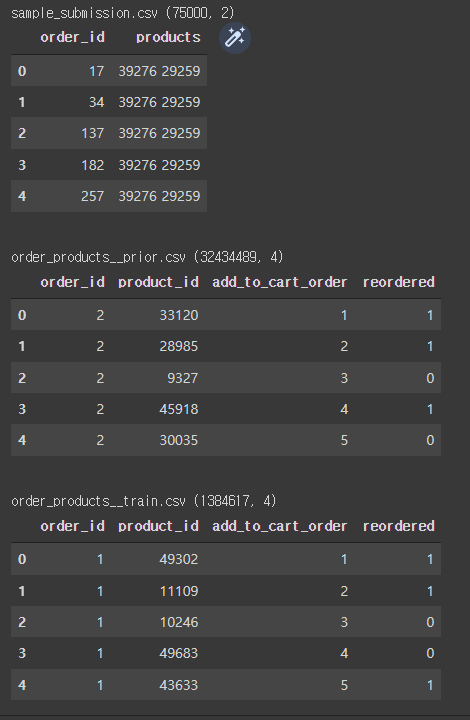

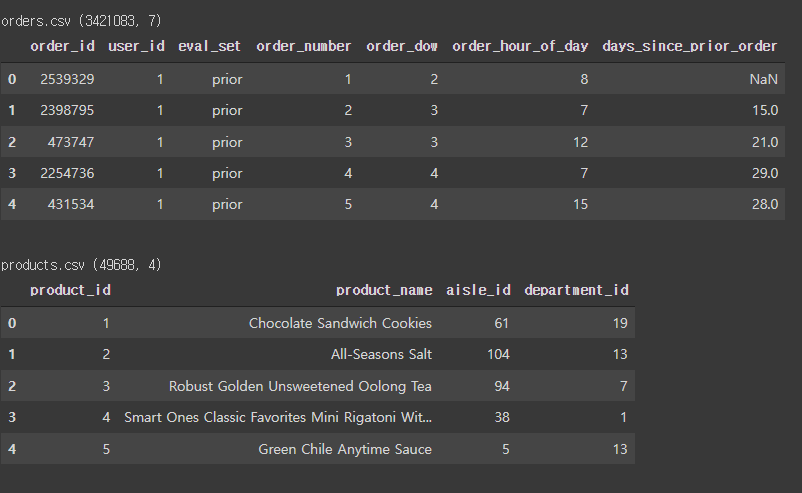
tqdm: 파이썬 프로세스 바, 보통 for문 같은 반복문에 사용한다(잘 실행되고 있는지 알기위해서)
문제: 고객이 다음 주문에서 어떤 제품을 주문할지 예측
import numpy as np
import pandas as pd
prior = pd.read_csv('order_products__prior.csv')
train = pd.read_csv('order_products__train.csv')
products = pd.read_csv('products.csv')
orders = pd.read_csv('orders.csv')
submission = pd.read_csv('sample_submission.csv')
orders.head(40)
prior.head(3)
train.head(3)
submission.head(3)
submission.head(3)orders['eval_set'] == test 또는 train 세트가 완전히 분리되어 있는지 확인
# set1.isdisjoint(set2)
set(orders[orders['eval_set']=='test']['user_id']\
.isdisjoint(set(orders[orders['eval_set']=='train']['user_id']))
#테스트, 훈련세트에서 각 고객에 대한 중복 샘플이 있는지 확인
len(orders[orders['eval_set'].isin(['train','test'])])\
, len(orders[orders['eval_set'].isin(['train','test'])]['user_id'].unique())
#(206209, 206209)원래는 고객이 지금까지 구매한 연속 상품구매정보(prior)가 특성들이 되고 이 정보를 바탕으로 앞으로 구매할 제품들을 예측하는 문제인데
여기서 어떤 고객들의 최근 구매 product_id는 학습을 위한 타겟 특성이 되고 어떤 고객들은 이 타겟정보가 주어지지 않은 상태로 테스트 데이터가 됨
예측 문제를 정의하기 위해 데이터를 분석
기존 문제: 고객들마다 어떤 상품들이 재구매 될 것인가? 보다 조금 더 간단한 문제를 만들고 싶음, so 구매자가 특정 상품을 구매할 것인지 말것인지(binary classification)을 예측하는 문제로 바꾸기 위한 데이터를 준비
특정 상품은 데이터가 많을수록 좋기 때문에, 지금까지 가장 고객들이 많이 구입한 제품으로 정하면 좋을 것 같음
앞으로 다음과 같은 질문에 대한 답을 찾는 과정에서 데이터를 만들어 보겠음
- 고객들이 가장 빈번하게 주문하는 제품은?
- 고객들이 이 제품을 최근에 얼마나 구매를 하는지?
- 어떤 고객들이 이 제품을 이전에(prior) 구매했었는지?
- 이 제품을 구입한 이력이 있는 고객 데이터세트는?
- 어떤 특성을 엔지니어링 해야 고객이 이 제품을 재구매할 것이라 예측할 수 있을까요?
1. 고객들이 가장 빈번하게 주문하는 제품은?
가장 빈번하게 나타나는 product_id를 찾기
최빈값을 찾는 mode 함수나 value_counts을 사용할 수 있음
prior['product_id'].mode()
#0 24852
prior['product_id'].value_counts()
#24852 472565
train['product_id'].mode()
#0 24852prior, train에서 가장 많이 구매하는 제품은 모두 24852이다.
상위 5개 구매 제품 찾기
top5_products = prior['product_id'].value_counts()[:5]
top5_products
top5_index = list(top5_products.index)
top5_index
product_id는 중복값이 없기 때문에 인덱스로 만들어 사용하면 편리할 것 같습니다
products.set_index('product_id').loc[top5_index]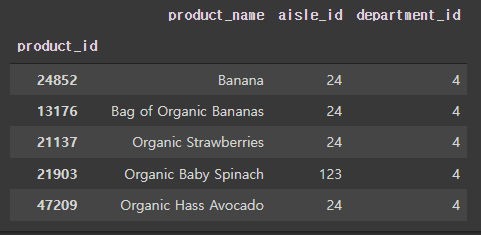
prior와 product df를 합쳐보겠습니다.
prior, train에 product 정보가 함께 있으면 제품의 정보를 확인하기에 더 편리할 것 같습니다
len(products.product_id.unique()) == len(products)
prior = prior.merge(products, on='product_id')
# train 데이터도 products와 병합해놓기
train = train.merge(products, on='product_id')
train.head()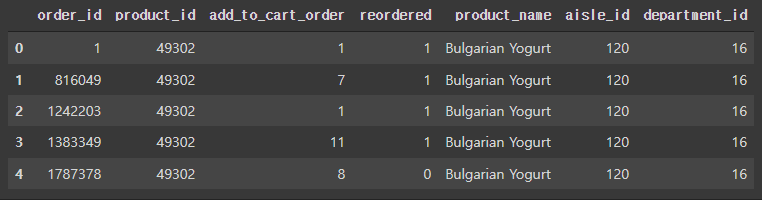
sol1. 고객들이 가장 빈번하게 주문하는 제품은? 바나나(product_id = 24852)입니다.
우리가 만드는 모델의 타겟은 이 바나나의 재구매 여부를 맞추는 모델이 될 것입니다.
2. 고객들이 최근에 바나나를 얼마나 구매 하는지?
데이터 세트 3종류에 대해 다시 한 번 정리하기
- 고객이 주문한 가장 최근 데이터는 'train','test'에 존재합니다.
('prior'는 최근 주문보다 이전 주문들 기록입니다.) - 'test'는 제품 레이블(product_id)이 없기 때문에 학습에 사용할 수 없습니다.
(레이블은 kaggle과 instacart만 가지고 있습니다.) - 'train'은 각 행이 한 제품이고 고객이 구매한 여러 제품이 한 order_id내에 있습니다.
여기서 우리는 한 주문이 속하는 여러 제품을 order_id 별로 그룹화해 한 줄로 나타내고 이 주문에 바나나(product_id=24852)가 포함되어있는지 true, false로 나타내는 새로운 이진 특성(banana)을 만들어 사용하겠습니다.
id_Banana = 24852
train['banana'] = train['product_id'] == id_Banana
#이 비율은 모든 구입 제품 중 바나나의 비율
train['banana'].value_counts(normalize=True)
방법1. apply 사용
apply는 데이터프레임에 축(axis)을 기준으로 특정한 함수를 적용(apply)하기 위한 메소드 입니다.
최근 주문 별로 몇 개의 제품을 구입했는지 확인하려면 다음과 같습니다. 그리고 각 주문리스트에 바나나가 포함되었는지 확인하기
train.groupby('order_id')['product_id'].count()주문 별 구입한 제품들의 product_id를 리스트로 얻기
train.groupby('order_id)['product_id'].apply(list)
#lamda X : id_Banana in list(x) 람다함수는 주문에 바나나가 있는 경우 True를 리턴합니다.
train.groupby('order_id')['product_id'].apply(lambda x : id_Banana in list(x)).value_counts(normalize=True)
방법2. groupby any 매서드 사용
# any(): 주문(order_id) 중에서 한 번이라도 Banana 주문이 있는 경우 True
train.groupby('order_id')['banana'].any().value_counts(normalize=True)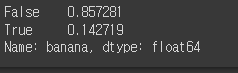
sol2. 최근 구매 주문(train)중 바나나가 포함되느 주문은? 14%
이제 타겟을 사용해 학습 데이터를 만들 수 있습니다.
학습 데이터는 df로 만들어 나가겠습니다.(바나나 재구매를 예측하기 위한 데이터를 만들기 위해 banana를 reorder_banana로 미리 변경하겠습니다.)
df = train.groupby('order_id')['banana'].any().reset_index().rename(columns={'banana':'reorder_banana'})
df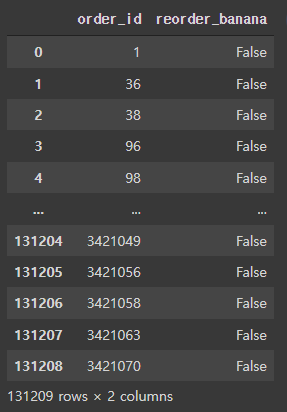
df['reorder_banana'].value_counts(normalize=True)
target = 'reorder_banana'3. 어떤 고객들이 바나나를 이전에(prior) 구매했나요?
- 고객은 user_id로 구분합니다.
- 제품은 product_id로 구분합니다.
현재 이 두 아이디를 같이 가지고 있는 테이블이 없는 상황입니다. 테이블들을 조인해서 만들어보기
sol3. 바나나를 한 번이라도 구매한 이력이 있는 user_id를 구하기
order_ids = prior[prior.product_id==id_Banana]['order_id']
user_ids = orders[orders.order_id.isin(order_ids)]['user_id'].unique()
print('한 번이라도 banana를 구매한 이력(prior)이 있는 유저 수: ', len(user_ids))
#한 번이라도 banana를 구매한 이력(prior)이 있는 유저 수: 739564. 바나나를 구입한 이력이 있는 고객 데이터 세트는?
모델은 바나나 재구매를 예측하기 때문에 모델 입력값은 한 번이라도 바나나를 구매한 고객이 대상이 될 것 입니다. Prior에서 바나나를 구매한 이력이 없는 고객은 입력이 될 수 없습니다.
이제 바나나를 한 번이라도 구입한 적이 있는 고객의 데이터만 남기겠습니다.
banana를 구입한 이력이 있는 고객의 주문정보로 orders제한
orders.shape #(3421083, 7)
orders = orders[orders['user_id'].isin(user_ids)]
orders.shape
#(1512975, 7)
order_ids = orders['order_id'].unique()
prior.shape
#(32434489, 7)
prior = prior[prior['order_id'].isin(order_ids)]
prior.shape
#(16534534, 7)
df.shape
#(131209, 2)
df = df[df['order_id'].isin(order_ids)]
df.shape
#(46964, 2)
df.head()
5. 어떤 특성 엔지니어링 해야 고객이 바나나를 재구매 할 것이라 예측을 할 수 있을까요?
여러가지 생각해 볼 수 있는 특성들이 있습니다.
- 고객의 주문당 평균 구입 제품의 수
- 주문한 시간
- 바나나 구매 횟수, 빈도
- 바나나 외에 다른 과일을 같이 구매 하는지
- 바나나 재구매 사이의 일수
- 최근 몇일 전에 바나나를 구매했는지?
우선 학습데이터에 orders 데이터를 조인하여 특성들을 추가해 보겠습니다.
df = df.merge(orders)
#1) 고객의 주문당 평균 구입 제품의 수
prior = prior.merge(orders, how='left', on='order_id')
# 유저별 주문당 제품 수
prior.groupby(['user_id','order_id']).count()
prior.groupby(['user_id','order_id']).count().reset_index().groupby('user_id').mean()
products_per_order = (prior
.groupby(['user_id','order_id'])
.count()
.reset_index()
.groupby('user_id')['product_id']
.mean()
.reset_index()
.rename(columns={'product_id':'products_per_order'}))
products_per_order
df = df.merge(products_per_order, on='user_id')
df.head()- 고객들이 바나나를 가장 많이 구입한 시간?
order_hour_of_day에 대해서 분포를 살피기
prior.head(1)
hb = prior[prior.product_id==id_Banana]['order_hour_of_day'].value_counts()
hnb = prior[prior.product_id!=id_Banana]['order_hour_of_day'].value_counts()
print(hb[:3])
print(hnb[:3])
hb = hb.sort_index()
hnb = hnb.sort_index()
fig, ax = plt.subplots(1,2,figsize=(15,5))
sns.barplot(x=hb.index, y=hb.values, ax=ax[0]);
sns.barplot(x=hnb.index, y=hnb.values, ax=ax[1]);
ax[0].set(xlabel='hour', title="ordered banana")
ax[1].set(xlabel='hour', title="without banana")
sns.barplot(x=hb.index, y=hb.values);
print(hb.sort_values(ascending=False).index.tolist())
print(hnb.sort_values(ascending=False).index.tolist())
- 바나나 구매 횟수
num_ordered_banana = (prior[(prior.user_id.isin(df.user_id)) & (prior.product_id==id_Banana)]
.groupby('user_id')['product_id']
.count()
.reset_index()
.rename(columns={'product_id':'num_ordered_banana'}))
num_ordered_banana
df = df.merge(num_ordered_banana,on='user_id')4) 최근 몇일 전에 바나나를 구입했는지?
최근 주문이 언제 일어날지 모르는 상황으로 보고,
prior에서 가장 최근 바나나 구입부터 가장 최근 주문 날까지 days_since_prior_order 값을 합산
# order_ids: prior, 바나나 포함된 주문 아이디
order_ids = prior[prior.product_id==id_Banana]['order_id']
banana_in_order = orders[(orders.eval_set=='prior') & (orders.order_id.isin(order_ids))][['order_id']]
banana_in_order['banana_in_order'] = True
banana_in_order
orders = orders.merge(banana_in_order,how='left',on='order_id')
orders['banana_in_order'].value_counts(normalize=True, dropna=False)
last_banana_order_number = (orders[(orders.banana_in_order==True) & (orders.eval_set=='prior')]
.groupby(['user_id'])
.tail(n=1)[['user_id','order_number']]
.rename(columns={'order_number':'last_banana_order_number'}))
last_banana_order_number
orders = orders.merge(last_banana_order_number, how='left', on='user_id')
orders[orders.user_id==2]
orders_cut = orders[orders.order_number > orders.last_banana_order_number]
orders_cut
days_since_banana_order = (orders_cut
.groupby('user_id')['days_since_prior_order']
.agg('sum')
.reset_index()
.rename(columns={'days_since_prior_order':'days_since_banana_order'}))
days_since_banana_order
df = df.merge(days_since_banana_order,how='left',on='user_id')
df