
주요 라이브러리
eli5
xgboost
*import 하기 전 설치하기
특성 중요도 계산 방법
1.Feature Importances(Mean decrease impurity, MDI)
-
sklearn 트리 기반 분류기에서 디폴트로 사용되는 특성 중요도는 속도는 빠르지만 결과를 주의해서 봐야함
각각 특성을 모든 트리에 대해 '평균불순도감소'를 계산한 값 -
특성 중요도가 높게 나온 feature는 유의해서 봐야함(high-cardinality특성일수도 있어서)
2.Drop-Colum Importance
- 매 특성을 drop한 후 fit을 다시해야해서 매우 느림
- 특성이 n개 존재할 때 n+1번 학습이 필요
3. 순열중요도
(Permutation Importance, Mean Decrease Accuracy, MDA)
- 순열 중요도는 기본 특성 중요도와 drop-column 중요도 중간에 위치하는 특징을 가짐
- 중요도 측정은 관심있는 특성에만 무작위로 노이즈를 주고 예측을 하였을 때 성능 평가지표(정확도,F1,R2등)가 얼마나 감소하는지를 측정
-Drop-column 중요도를 계산하기 위해 재학습을 해야 했다면, 순열중요도는 검증데이터에서 각 특성을 제거하지 않고 특성값에 무작위로 노이즈를 주어 기존 정보를 제거하여 특성이 기존에 하던 역할을 하지 못하게 하고 성능을 측정, 이때 노이즈를 주는 가장 간단한 방법이 그 특성값들을 샘플들 내에서 섞는 것(shuffle, pertutation)
-한번만 핏함
Boosting(Xgboost for gradient boosting)를 사용
분류문제를 풀기 위해서는 트리 앙상블 모델을 많이 사용함
- 트리 앙상블은 랜덤포레스트나 그래디언트 부스팅 모델을 이야기하며 여러 문제에서 좋은 성능을 보이는 것을 확인
- 트리모델은 (non-linear, non-monotonic관계, 특성간 상호작용이 존재하는 데이터 학습에 적용하기 좋음)
- 한 트리를 깊게 학습시키면 과적합을 일으키기 쉽기 때문에 배깅(Baging)이나 부스팅앙상블 몯ㄹ을 사용해 과적합을 피함
- 랜덤포레스트의 장점은 하이퍼파라미터에 상대적으로 덜 민감한 것인데, 그래디언트 부스팅의 경우 하이퍼파라미터 셋팅에 따라 랜덤포레스트 보다 더 좋은 예측성능을 보여줄 수 있음
부스팅과 배깅의 차이점
- 만드는 방법에서 차이가 있음
- 랜덤포레스트: 각 트리를 독립적으로 만듦
- 부스팅: 만들어진 트리가 이전에 만들어진 트리에 영향을 받음
- 부스팅 알고리즘 중 adaboost는 트리(약한 학습기)가 만들어질 때 잘못 분류되는 관측치에 가중치를 둠, 그리고 다음 트리가 만들어질 때 이전에 잘못 분류된 관측치가 더 많이 샘플링되게 하여 그 관측치를 분류하는데 더 초점을 맞춤
Adaboost의 알고리즘 예시
- 모든 관측치에 대해 가중치를 동일하게 설정
- 관측치를 복원추출하여 약한 학습기 Dn을 학습하고 +,-분류
- 잘못 분류된 관측치에 가중치를 부여해 다음 과정에서 샘플링이 잘되도록 함
- 1~2과정을 n회 반복(n=3) 합니다.
- 분류기들을 결합하여 최종 예측을 수행
*잘못분류한 값에 가중치를 줘서 다음 트리를 만듦
gradient boosting
- 그래디언트 부스팅은 회귀와 분류문제에 모두 사용 가능
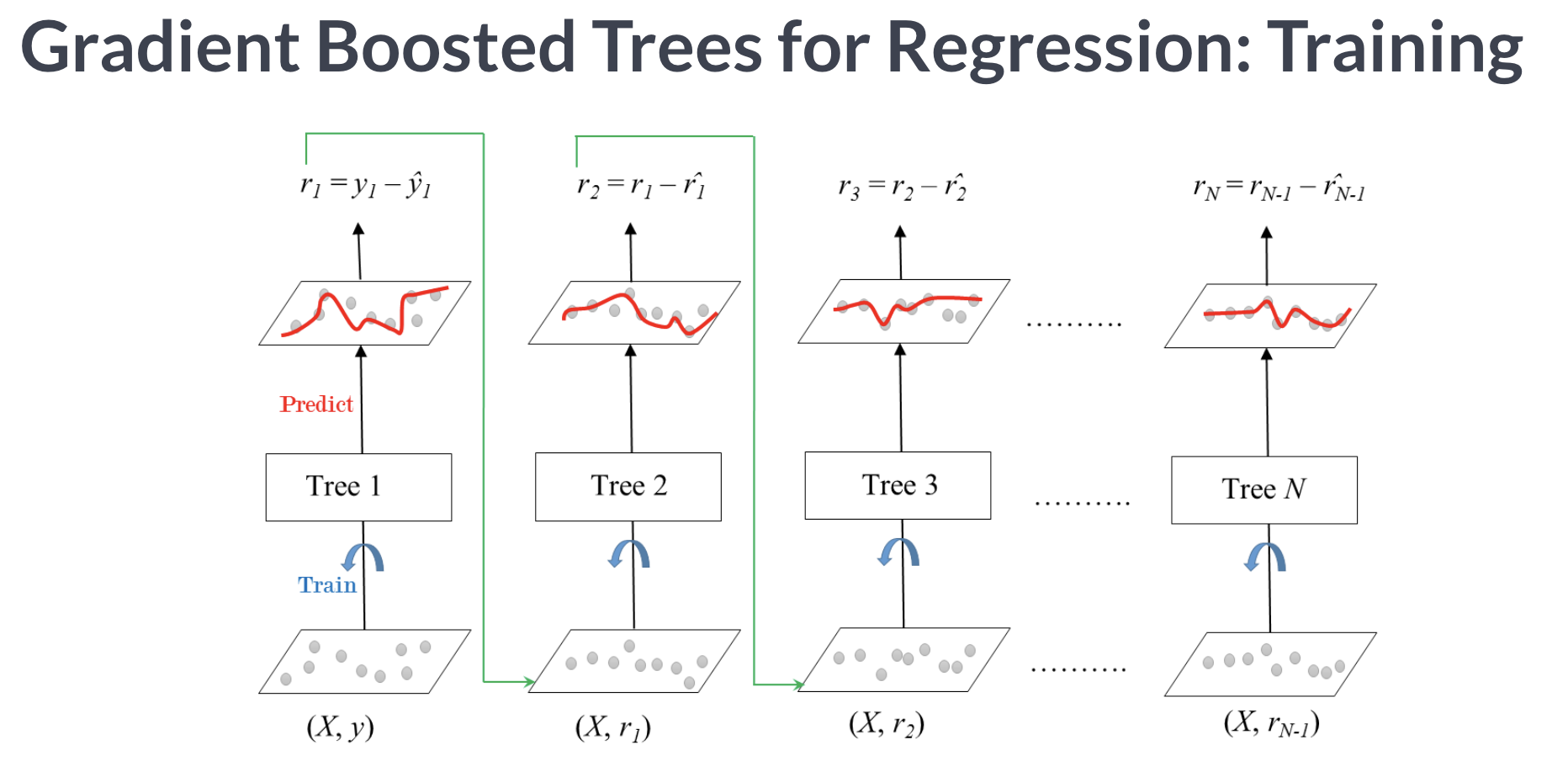
그래디언트 부스팅은 Adaboost와 유사하지만 비용함수(loss function)을 최적화하는 방법에 있어서 차이가 있음
그래디언트 부스팅에서는 샘플의 가중치를 조정하는 대신 잔차(residual)을 학습하도록 함
이것은 잔차가 더 큰 데이터를 더 학습하도록 만드는 효과가 있음
Python libraries for Gradient Boosting
scikit-learn Gradient Tree Boosting: 상대적으로 속도가 느려질 수 있음
xgboost:결측값을 수용하며, monotonic constraints를 가제할 수 있음
- Anaconda, Mac/Linux: conda install -c conda-forge xgboost
- Windows: conda install -c anaconda py-xgboost
- Google Colab: already installed
LightGBM: 결측값을 수용하며, monotonic constraints를 강제할 수 있음
- Anaconda: conda install -c conda-forge lightgbm
- Google Colab: already installed
CatBoost: 결측값을 수용, categorical features를 전처리 없이 사용할 수 있음
- Anaconda: conda install -c conda-forge catboost
- Google Colab: pip install catboost
XGBoosting : 앙상블 학습 알고리즘
장점
- 뛰어난 예측 성능: 일반적으로 분류/회귀에서 예측 성능이 높음
- GBM대비 빠른 수행시간: GBM Weak learner 가중치 증감해서 속도가 느림
그러나 XGB는 병렬 수행하고 다양한 기능으로 GBM에 비해 빠른 수행성능을 보장- 과적합 규제
- tree pruning: max-depth 파라미터로 분할 깊이 조정하지만 tree pruning으로 더이상 긍정 이득이 없는 분할을 가지치기해서 분할수를 더 줄이는 추가적인 장점을 가짐
- 자체 내장된 교차 검증: 반복 수행 시 내부적으로 교차 검증 수행해 최적화된 반복 수행 횟수를 가질 수 있음, 지정된 반복 횟수가 아니라 교차 검증을 통해 평가 데이터 세트의 평가 값이 최적화 되면 반복을 중간에 멈출수 있는 조기 중단기능이 있음
- 결손값 자체 처리: XGBoost는 결손값을 자체 처리 할 수 있는 기능을 가지고 있음
파라미터를 튜닝하는 경우
- 핏쳐 간 상관되는 정도가 많을때
- 핏쳐 수가 많을때
- 데이터 세트에 따라 과적합 문제가 심각할 때
how to?
- eta값 낮춤(0.01~0.1)
eta값 낮출 경우 num_round(or n-estimators)는 반대로 높여줘야함 - max_depth 값 낮춤
- min_child_weight 값을 높임
- gamma 값을 높임
- subsample, colsample_bytree를 조정하면 트리가 너무 복잡하게 생성되는 것을 막아 과적합 문제에 도움이 됨
early stopping
- xgb 수행 속도를 향상시키는 기능
- n_estimators에 지정한 부스팅 반복 횟수에 도달하지 않더라도 예측 오류가 더이상 개선되지 않으면 반복을 끝까지 수행하지 않고 중지해 수행 시간을 개선할 수 있음
early_stopping_rounds
- 파라미터를 설정해 조기 중단을 수행하기 위해서는 반드시 eval_set과 eval_metric이 함께 설정돼야함
- eval_set은 성능 평가를 수행할 평가용 데이터 세트를 설정
- eval_metric은 평가 세트에 적용할 성능평가 방법(분류일경우 주로 'error'분류오류, 'logloss'를 적용
XGB 패키지는 핏쳐의 중요도를 시각화해주는 모듈인 plot_importance를 함께 제공

안녕하세요. 기억보다 기록을 믿는 레나입니다!