
이번 논문은 실제 현장에서 많이 사용하는 욜로를 공부해볼 예정입니다.
YOLOv3 Code
https://pjreddie.com/darknet/yolo/
Papers
https://pjreddie.com/media/files/papers/YOLOv3.pdf
Abstract
- Yolo 모델을 약간의 변화들로 업데이트 했고 이 새로운 모델은 지난 번 보다 사이즈가 커졌지만 더 정확해졌다
- SSD처럼 정확하지만 SSD 보다 3배 빠르다
- TitanX(그래픽카드)에서 57.9AP in 51ms를 성취했고 RetinaNet과 유사하지만 3.8배 더 빠름
The Deal
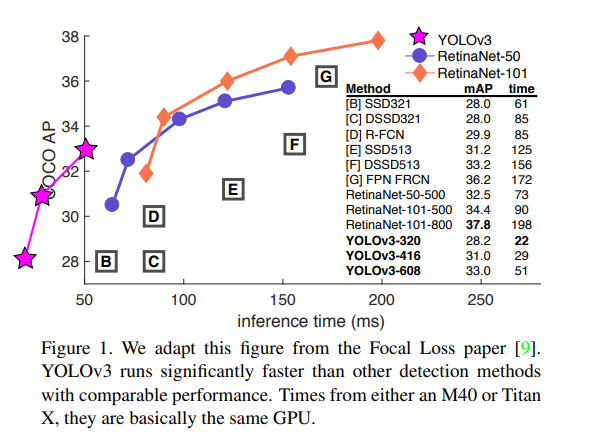
- Focal Loss 논문에서 가져온 위의 그래프를 보면 YOLOv3가 다른 디텍션 방법들보다 상당히 빠르게 작동하는 것을 알 수 있음
Focal Loss란 욜로같이 localization과 classification을 동시에 처리하는 one stage detecter의 정확도 성능을 개선하기 위해 나옴
즉, 학습 시 배경에 박스를 친것이 많다는 것이고 그 빈도수가 많으면 학습에 방해되기 때문에 이렇게 어렵거나 쉽게 오분류 되는 케이스에 더 큰 가중치를 주는 방법임
Focal Loss에 대한 자세한 설명은 아래의 블로그에서 확인(자세하게 잘 설명되어있음)
https://gaussian37.github.io/dl-concept-focal_loss/
2.1 바운딩 박스 예측
-
anchor boxes처럼 dimesion clusters를 사용해서 바운딩 박스를 예측한다
-
위 네트워크를 4coordinates로 각각의 바운딩 박스를 예측한다
4 coordinates란
1) True Positive(TP): 맞다고 추측하고 실제로 맞음 IoU >= Threshold
2) False Positive(FP): 맞다고 추측하고 실제로 틀림 IoU < Threshold
3) False Negative(FN): 아니라고 추측하고 실제로는 맞음
4) True Negative(TN): 아니라고 추측하고 실제로 아님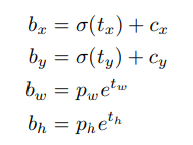
-
훈련하는 동안 error loss의 제곱의 합을 사용한다
-
만약 coordinate 예측의 ground truth(정답)가 T&일때, 우리의 기울기는 ground truth value - prediction임
-
Yolov3는 각각의 바운딩 박스의 objectness 점수를 로지스틱 회귀를 사용해서 예측한다
Objectness는 어떤 Bounding box가 검출이 될때 이 Bounding box는 x, y, w, h, confidence로 구성된다. x, y는 박스의 중앙값이고 w, h는 넓이와 높이 이다.
confidence는 박스에 객체가 있는지 없는지에 대한 확률 이다.
따라서, Objectness(Confidence threshold)를 0.3으로 두면 30% 정확도가 안될때, 그 박스는 버려지게 된다. -
우리는 threshold를 0.5로 사용했다
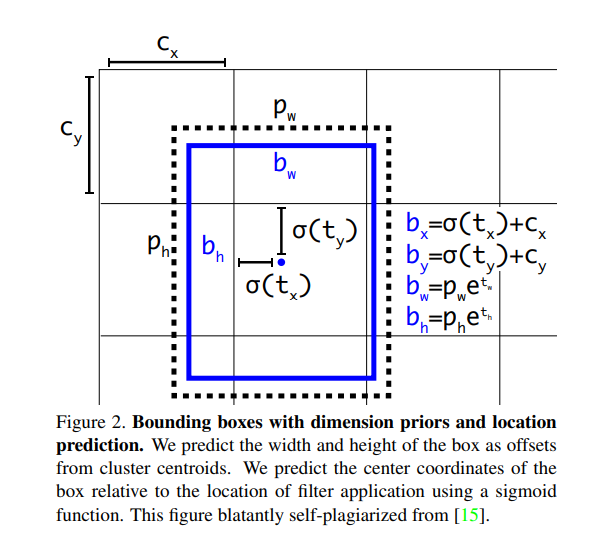
- cluster 중심 점으로부터 박스의 높이와 너비를 예측하고 시그모이드 함수를 사용해서 핕터가 적용된 위치와 관련된 박스의 중심 coordinates를 예측한다
2.2 클래스 예측
-
각각의 박스는 Multi-label classification(다중 분류)를 사용해서 바운딩 박스의 클래스를 예측한다
-
근데, Softmax를 사용하지 않았고 softmax대신 independent logistic classifier를 사용했다
-
훈련동안에는 binary cross-entropy loss를 클래스 예측하는데 사용했다
binary cross entropy(손실함수)
cross entropy는 두 개의 확률분표 p와 q에 대해 하나의 사건 X가 갖는 정보량으로 정의됨
즉, 서로 다른 두 확률분포에 대해 같은 사건이 가지는 정보량을 계산한 것이고 q에 대한 정보량을 p에 대해서 평균 낸 것
Binary cross entropy는 두개의 클래스 중에 하나를 예측하는 테스크에 대한 cross entropy의 special case임 -
이 방법을 왜 사용했냐면 데이터 셋 안에 많이 겹치는 라벨들이(예시: 여성 과 사람) 있을때 소프트맥스를 사용하면 각각의 박스를 정확하게 하나의 클래스를 가지려고 하기 때문에 실제로는 그 클래스가 아닌데도, 그래서 멀티라벨 접근법이 훨씬더 좋은 모델을 만든다
2.3 Predictions Across Scales
-
yolo v3는 3개의 다른 스케일에서 박스들을 예측함
-
이는 피라미드 네트워크 특징을 추출하는 개념과 유하하게 사용해서 위의 3개의 스케일에서 피쳐들을 추출한다
-
3 scales: 3-d tensor encoding bounding box, objectness, class predictions
-
coco 데이터셋에서 우리는 각각의 스케일로 3개의 박스들을 예측했다
-
그래서, 그 텐서는 NxNx[3x(4+1+80)]이다(4개의 바운딩 박스 offsets, 1개의 objectness prediction, 80개의 class Predictions)
-
그다음 2층의 핏쳐 맵을 가지고나서 2배로 업샘플링 한다
-
네트워크 초반에 핏쳐 맵을 가지고 업샘플 된 핏쳐를 concatenation을 사용해서 합쳐줌
-
이방법은 더 많은 의미있는 정보를 줌
-
합쳐준 다음에 몇개의 conv layer들을 더해주고(결합된 피쳐맵을 프로세스 하려고) 유사한 텐서를 예측한다
-
K-means clustering을 바운딩 박스 priors를 구별하기위해 사용한다
-
9개의 클러스터와 3개의 scales 사용하고 scale이 평평해지는 구간에서 클러스터들을 나눈다
2.4 Feature Extractor
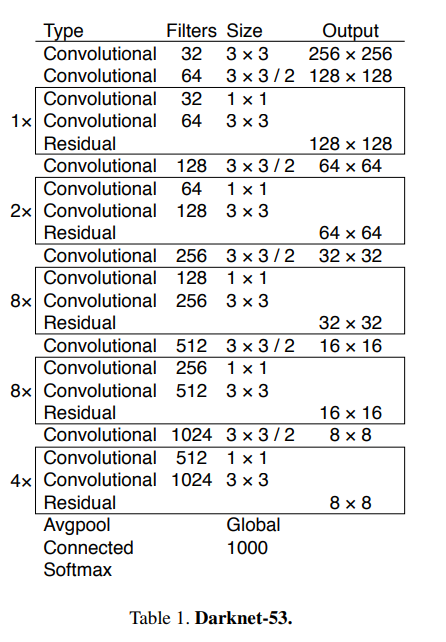
- 53개의 convolutional layers를 가져서 Darknet-53이라고 부름
- Darknet-19보다 강하고 resnet-101 또는 resnet-152보다 효율적임
2.5 Training
- Multi scale 훈련과 많은 데이터 증강, batch normalization을 사용함
- 훈련과 테스트 동안 다크넷 신경망 프레임워크를 사용했음
How we do
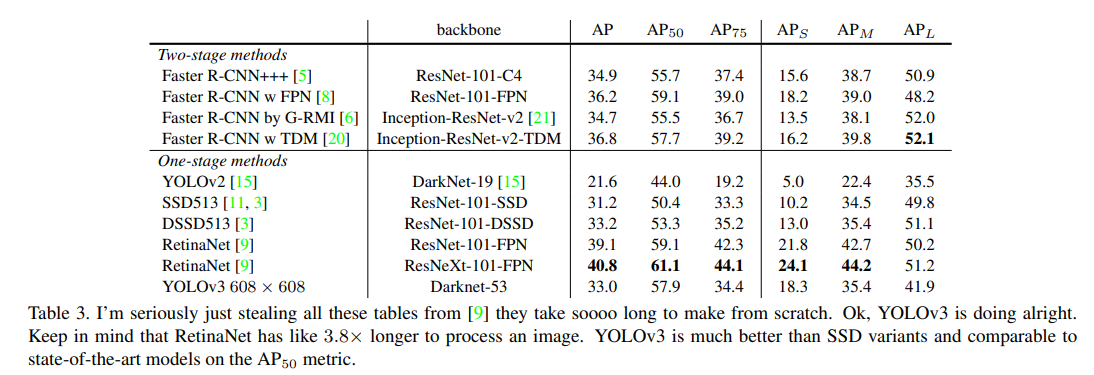
- mAP at IOU가 0.5일때 yolo v3는 매우 강했고 이는 거의 Retinanet 정도 이고 ssd보다 조금더 높음
- 하지만, Iou 임계값이 증가하면서 성능이 떨어졌고 Yolov3가 박스를 객체와 정렬하는데 어려움을 겪었다
- 예전 Yolo는 작은 오브젝트에 어려움이 있었는데 지금은 잘 찾는다 이는 멀티 스케일 예측 때문이고 yolov3는 상대적으로 높은 APs 퍼포먼스를 가진다
- 그러나 큰 사이즈의 오브젝트에는 낮은 퍼포먼스를 보였다
What This All Means
- Yolo v3는 빠르고 정확함, coco에서 0.5~ 0.95 Iou metric에서 평균 AP는 좋지 못했지만 Yolo v3는 old detection metric에선 좋은 결과를 보였다
