
분류 알고리즘 정리
- 나이브베이즈: 베이즈 통계과 생성 모델에 기반
- 로지스틱회귀: 독립/종속변의 선형 관계성에 기반
- 결정트리: 데이터 균일도에 따른 규칙 기반
- 서포트 벡터 머신: 개별 클래스 간 최대 분류 마진을 효과적으로 찾아줌
- 최소 근접 알고리즘: 근접 거리 기준
- 신경망: 심층 연결 기반
- 앙상블: 서로 다른(또는 같은) 머신러닝 알고리즘 결합
[결정트리] 에서 주요사용할 라이브러리
- category_encoders
- graphviz
- numpy
- pandas
- scikit-learn
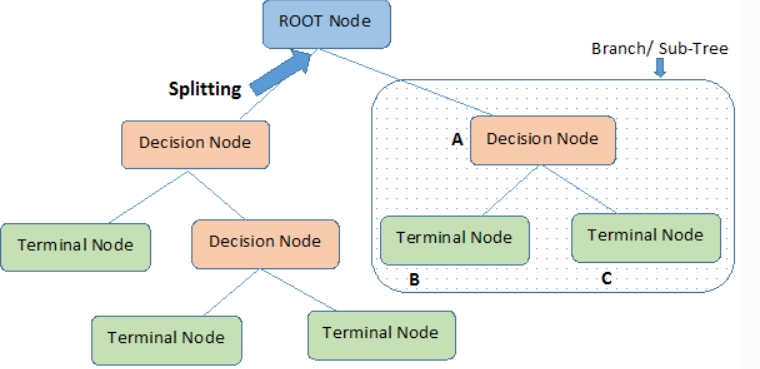
결정트리
결정트리
- If-else 기반으로 나타냄
- 결정트리의 각 노드는 뿌리, 중간, 말단노드로 나눠진다.
[장점]
- 특성 해석하기 좋음
- 회귀때보다 전처리에 덜 신경써도 됨
왜냐면 스케일링, 정규화 등 사전 가공의 영향이 적기때문에
[단점]
- 샘플 민감해서 트리구조 바끼고 해석도 바뀜
- 예측 성능을 향상시키기 위해 복잡한 규칙 구조를 가짐
- 과적합이 쉽게 발생해 성능이 저하됨
결정트리는 회귀에 적용가능하다?
- YES 분류/회귀 모두 적용가능하다
결정 트리 학습 알고리즘
어떤 기준으로 트리를 나눌까?
"결정노드"를 어떻게 분류하는지에 따라 트리를 나눈다
- 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙 조건을 만들어줌
정보의 균일도를 측정하는 방법
엔트로피
- 주어진 데이터의 혼잡도
- 다른 값 섞여있으면 엔트로피 높다. 같은 값이 섞여있으면 엔트로피 낮다.
1. 정보 이득(엔트로피 개념 기반)
정보 이득 지수는 1-엔트로피 지수
정보이득이 높은 걸 기준으로 트리를 나눔
정보 획득량(Information Gain)은 부모 노드의 Entropy 에서 자식노드들의 Entropy 가중평균합을 뺀 값이다.
2. 지니 계수(엔트로피 개념 기반X)
- 지니 계수가 낮을수록 데이터 균일도가 높음
- 계산이 빠름
- 부모 노드의 Gini Impurity 보다 자식노드들의 Gini Impurity(가중평균합)가 커지면 더이상 트리를 나누지 않고, 부모 노드가 마지막 말단 노드가 된다.
ex) 사이킷런 DecisionTreeClassifier는 지니 계수를 이용해 데이터 세트 분할

왜 결정트리에서는 Standard Scaler를 사용하지 않을까?
- 평균을 0으로 표준편차를 1로 맞춰주기 때문에 의사결정도구에 적합하지 않음, 하나의 핏쳐로 구분이 되기때문데 스케일이 필요하지 않음
a,b 클래스가 혼합된 데이터가 있을때 비율이 각각 (45%, 55%), (80%,20%)이면 불순도가 높은 것은?
- 45%, 55%)가 범주가 비슷해서 불순도가 더 높고 (80%,20%)은 상대적으로 a보다 불순도가 낮다.
선형모델 VS 결정트리
선형모델
- 거리를 계산해서 예측
(기하학, 디스턴스, 지오매트리 모델이라고도 함)
트리모델
- if-then ~ else ~방식으로 2진 분류
- 트리모델은 비선형, 비단조일때 사용 가능
- 트리모델은 특성들의 상호작용에도 큰 문제없이 사용 가능
feature importance 특성 중요도
선형모델) 특성이 종속변수에 어떻게 영향을 미치는가를 뭘 보고 알수 있었나? 회귀계수
결정나무) 어떻게 트리모델이 각 특성이 영향을 미칠까?
- 특성 중요도가 얼마나 일찍 그리고 자주 분기에 사용되는지
- 회귀계수와 달리 양수값을 가짐
특성 중요도가 낮은걸 빼고 모델링 하는것도 특성공학 방법 중 하나
왜 결정트리는 과적합이 될까?
- 결정트리는 서브 트리를 만들때마다 핏쳐가 규칙을 만드는데 규칙이 많아질 수록 분류를 만드는 결정하는 방법이 복잡해지고 과적합으로 이어짐!
결정트리 과적합 해결 방법
트리의 복합도를 줄이기 위해 자주 사용하는 하이퍼 파라미터
1. min_sampes_split
- 노드에서 분기를 만들기위해 최소한 몇개의 노드가 있는지 확인
- 용도: 최소한의 샘플 데이터 수로 과적합을 제어
2. min_samples_leaf
- 마지막 리프 노드의 최소한 몇개의 샘플이 존재하는지 설명
- 용도: 과적합 제어
-but, 비대칭적 데이터의 경우 특정 클래스의데이터가 극도로 작을 수 있어서 이 경우는 작게 설정이 필요
3. max_depth
- 가장 강력하게 트리의 전체적인 깊이를 조절함
- 깊이가 깊어지면 min_sampes_split 설정대로 최대로 분할하다가 과적합 될 수 있어서 적절한 값으로 제어가 필요
사이킷런 파이프라인(pipelines)
파이프라인
- 결측치 처리 > 스케일링 >인코딩 > 모델을 한번에!
- 중복된 코드 최소화 검증정확도도 좋음
- named_steps
결측치 처리 > 스케일링 >인코딩 > 모델을 한번에!
from category_encoders import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
# 파이프 라인을 사용하지 않았을 때
enc = OneHotEncoder()
imp_mean = SimpleImputer()
scaler = StandardScaler()
model_lr = LogisticRegression(n_jobs=-1)
X_train_encoded = enc.fit_transform(X_train)
X_train_imputed = imp_mean.fit_transform(X_train_encoded)
X_train_scaled = scaler.fit_transform(X_train_imputed)
model_lr.fit(X_train_scaled, y_train)
X_val_encoded = enc.transform(X_val)
X_val_imputed = imp_mean.transform(X_val_encoded)
X_val_scaled = scaler.transform(X_val_imputed)
# score method: Return the mean accuracy on the given test data and labels
print('검증세트 정확도', model_lr.score(X_val_scaled, y_val))
X_test_encoded = enc.transform(X_test)
X_test_imputed = imp_mean.transform(X_test_encoded)
X_test_scaled = scaler.transform(X_test_imputed)
y_pred = model_lr.predict(X_test_scaled)코드가 여러줄이고 복잡합니다.
#파이프라인을 사용했을 때
pipe = make_pipeline(
OneHotEncoder(),
SimpleImputer(),
StandardScaler(),
LogisticRegression(n_jobs=-1)
)
pipe.fit(X_train, y_train)
print('검증세트 정확도', pipe.score(X_val, y_val))
y_pred = pipe.predict(X_test)파이프라인을 사용하면 최소화하고 간단하게 적용할 수 있다.

안녕하세요. 기억보다 기록을 믿는 레나입니다!