
주요 라이브러리
category_encoders
ipywidgets
matplotlib
pandas
scikit-learn
랜덤포레스트
랜덤포레스트가 결정트리와 어떻게 다른가?
결정트리는 하나의 트리임, 상부 에러가 하부까지 가져감, 과적합 문제도 있었음
=> 위 문제를 랜덤포레스트로 해결
왜 랜덤포레스트는 과적합을 결정트리보다 더 피할 수 있을까?
=> 데이터를 랜덤으로 복원추출하고 여러모델로 종합을 내는데 에러를 발견하고 보완을 해줌
=> 랜덤포레스트의 랜덤성은 두가지가 있음
1. 랜덤포레스트에서 학습되는 트리들은 베깅을 통해 만들어짐(bootstrap = true)
이때 각 기본 트리에 사용되는 데이터가 랜덤으로 선택됨
2. 각각 트리는 무작위로 선택된 특성들을 가지고 분기를 수행함(max_features = auto)
베깅의 의미
- 베깅(Bagging, Bootstrap Aggregating)
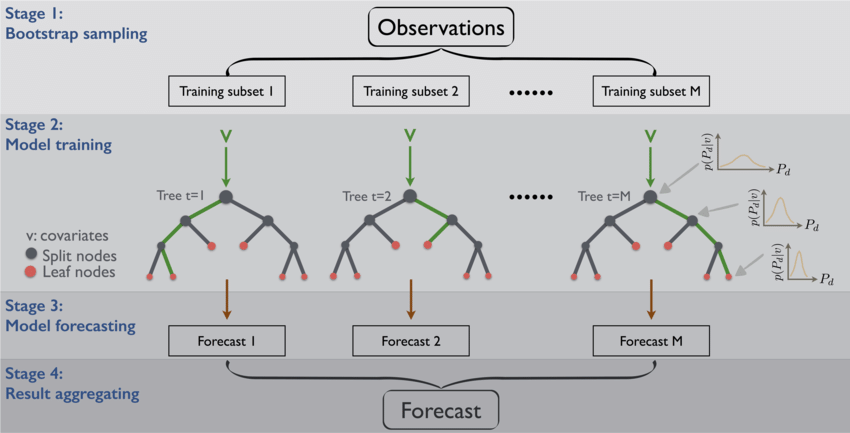
- 학습 데이터 세트에 총 1000개의 행이있을때 임의로 100개씩 행을 선택해서 의사결정 트리를 만들며 복원추출로 해서 중복을 허용함
- 부트스트랩을 여러번해서, 여러 훈련 세트를 만들고 각각의 훈련세트에 모델을 적용해서 그 결과 값을 모델에 적용하고 그 결과 값을 평균을 냄으로써 분산을 줄이는 방법
-데이터에서 샘플추출: 부트스트랩 > 기본모델(결정트리) > 종합: 평균, 최빈값(다수결)
out-of-bag sample 의미
- 랜덤포레스트 검증방법
- oob 샘플들이 각각의 모든 DT에 통과한다(OOB는 부트스트랩 트레이닝데이터에는 포함되지 않음)
- oob는 완벽하게 예상된 열의 수를 계산함

랜덤포레스트(결정트리를 기본모델로 사용)
앙상블 방법
- 한 종류의 데이터로 여러 머신러닝 학습모델(weak base leaner, 기본모델)을 만들어 그 모델들의 예측결과를 다수결이나 평균을 내어 예측하는 방법
- 기본 모델의 몇가지 조건을 충족하는 여러 종류의 모델을 사용할 수 있음
- 즉, 랜덤포레스트는 결정트리를 기본모델로 사용하는 앙상블 방법
(독립적으로 만들어짐)- 결정트리는 독립적으로 만들어지고 각각 랜덤으로 예측하는 성능보다 좋을 경우 랜덤포레스트는 결정트리보다 성능이 좋음
- 여러모델을 종합 > 다수결, 평균의 값 > 하나의 모델 > 예측
- 전문가 한명이 모든문제를 해결하기보다 여러명의 사람이 문제를 해결하는게 더 좋은 것 처럼 약한 학습모델을 기본모델로 두는것이다.
부트스트랩 샘플링(복원추출)
- 앙상블에서 사용하는 작은 모델들은 부트스트래핑이라는 샘플링 과정으로 얻은 부트스트랩 세트
- 원본 데이터에서 샘플링하는데 임의로 복원추출(샘플 뽑고 값을 추출하고 다시 넣는 것)을 한다는 것
-복원추출이라서 부트스트랩세트는 같은 샘플이 반복될수 있음
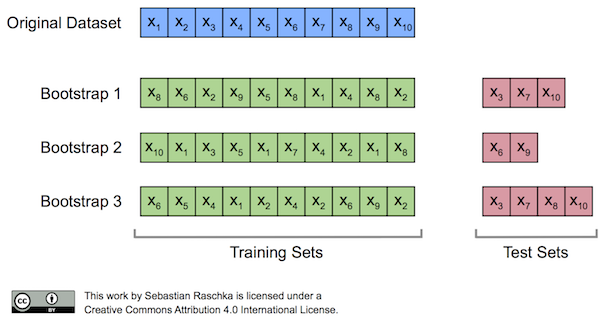
- 뽑히지 않는 샘플은?
=>OOB
랜덤포레스트 기본 모델
- 기본모델들의 트리를 만들 때 무작위로 선택한 특성세트를 사용
- 결정트리 알고리즘과 한가지 다른점
: 특성 n개 중 일부분 k개의 특성을 선택(sampling)하고 이 k개에서 최적의 특성을 찾아내어 분할함, k개는 일반적으로 log2n를 사용
랜덤포레스트 특성 중요도 비교
- 랜덤포레스트는 학습 후에 특성들의 중요도 정보(Gini importance)를 제공함
- 중요도는 노드들의 지니불순도(Gini impurity)를 가지고 계산하는데 노드가 중요할 수록 불순도가 크게 감소함하는 사실을 이용함
- 노드는 한 특성의 값을 기준으로 분리가 되기 때문에 불순도를 크게 감소하는데 많이 사용된 특성이 중요도가 올라감
Ordinal encoding 순서형 인코딩
(원핫인코딩과 구분하여 사용)
- 범주형 자료의 다른 인코딩 방법
- 순서형인코딩: 순서형
- 원핫인코딩: 명목형
명목형 변수에서 순서형 인코딩을 사용해도 된다. 왜?
- 특성을 기준으로 분할해서 거리나 위치가 중요한 것이 아니기 때문에 사용해도 됨
순서형 인코딩을 권장하는 이유는?
- 특성 중요도를 정확하게 캐치하기 어려우니까 오디널 인코더를 권장한다.
how to?
- 범주에 숫자를 맵핑, [a,b,c]세 범주가 있다면 이것을 [1,2,3]이렇게 숫자로 인코딩
트리구조 학습에서 원핫인코딩을 사용하면 문제가 있음- 트리구조에서는 중요한 특성이 상위노드에서 먼저 분할이 일어남 그래서 범주 종류가 많은 특성은 원핫인코딩으로 인해 상위노드에서 선택될 기회가 적어짐
- 원핫인코딩을 안 받는 수치형 특성이 상위노드를 차지할 기회가 높아지고 전체적인 성능저하가 일어날 수 있음
주의사항
- 범주를 순서가 있는 숫자형으로 바꾸면 원래 없었던 순서 정보가 생김
ex) food특성에 (밥, 빵)이라는 두 범주가 있을 때 순서형 인코딩을 하면 (1,2) 이렇게 인코딩이되서 원하지 않게 밥은 1, 빵은 2라는 순위를 매길 수 있는 정보가 생김 - 순서형 인코딩은 범주들간에 분명한 순위가 있을때 그 연관성에 맞게 숫자를 정해주는 것이 좋음
ex) 영화 평점

안녕하세요. 기억보다 기록을 믿는 레나입니다!