[TIL]Multiple-regression 다중선형회귀모델
Codestates Section2

다중선형회귀
Multiple regression analysis
종속변수는 하나, 독립변수가 두개 이상인 경우
예시) 아파트 집 값(종속변수)에 미치는 변수(독립변수)가 위치, 평수, 층수, 년식 등 변수가 많은 것
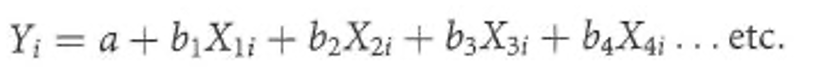
선형을 띔
독립변수 2개 이상
기준모델: 평균
모델해석: 회귀계수
예시) Y=B0+B1X1+B2X2 모델 해석하는법
X1=-50
X2=100
각각의 계수를 가지고 계산을 해주면면됨
x1은 한 단위 증가할때마다 y가 50감소
x2는 한 단위 증가할때마다 y가 100증가
즉, 각각의 독립변수에 어떻게 영향을 미치는지 해석하면된다.
다항회귀모델
Polynomial regression analysis
왜? 선형 회귀 안쓰고 다항 회귀를 쓰나요?
분석하고자 하는 데이터의 변수가 선형이 아닌 곡선의 형태로 되어있는경우, 선형 회귀 모델을 이용해 계산하면 오차가 크게 나타나기 떄문에 데이터 분포가 2차원의 곡선이면 2차원 곡선으로, 3차원의 곡선 형태이면 3차원 곡선으로 접근하는것이 오차가 작다.
헷갈림 주의) 다항회귀는 그래프 모양이 직선이 아니지만 선형회귀다!!
즉, 선형 회귀 모델의 한계를 다차원의 회귀식인 다항 회귀 분석으로 극복한 것
회귀계수가 일차원이고 선형 결합이되면서 선형모델이라고 한다
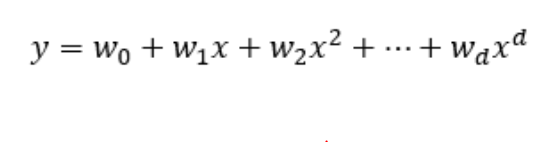

이미지 출처:https://www.inflearn.com/questions/188911
과대적합, 과소적합

이미지 출처: https://m.blog.naver.com/jevida/221860836806

이미지 출처 : educative.io
일반화? 우리가 다른곳에도 적용이 가능한 것
즉, 학습데이터(Training data)와 input 데이터가 달라져도 출력에 대한 성능차이가 나지 않는 것이며 우리가 모델링하는 목적이 다른 외부의 데이터를 모델에 집어 넣어도 학습 데이터로 모델을 학습시켜서 얻은 정확도(Accuracy)와 비슷한 값을 가지게 하기위해서입니다.
예) 샘플외에 데이터(모르는 데이터) input > 예측 > 잘맞춘다
일반화가 안된 모델 중 과대적합이란?
학습 데이터(training data)에만 너무 잘 맞춰져서 모르는 데이터가 왔을때 못맞춘다(즉, 모델을 너무 복잡하게 학습해서 학습 데이터에는 너무 잘 맞지만 새로운 데이터는 예측/분류를 수행하지 못한다)
보통은 과적합이 많아서 과적합을 줄이는 과정을 많이 진행하게 될 것
과적합 해결 방법
-훈련데이터를 더 많이 모음
-정규화(Regularization): 핏쳐(독립변수)는 그대로 두고 파라미터를 줄임
-noise 줄이기: 오류 수정하고 이상치를 제거
일반화가 안된 모델 중 과소적합이란?
과대적합의 반대말, 모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할때 발생한다.
과소적합 해결방법
-파라미터가 더 많은 복잡한 모델을 선택
-모델의 제약을 줄이기
-조기 종료 시점까지 충분히 학습
편향-분산 트레이드오프
편향과 분산은 trade off로 시소처럼 한쪽이 올라가면 한쪽이 내려가는 관계
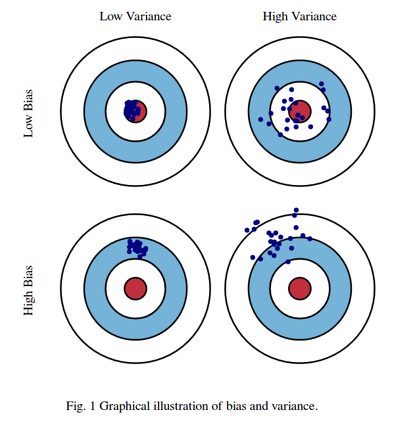
이미지출처: https://datacookbook.kr/48
편향
편향이 높다는 것은 실측치와 예측지 간의 오차가 크다는거고 꾸준히 틀리는 과소적합 상황인 것이다.

왼쪽 그림: 편향이 높다
오른쪽 그림: 편향이 낮다
분산
분산이 높다는 것은 예측의 범위가 넓어서 예측분포가 큰 과대적합 상황이다.
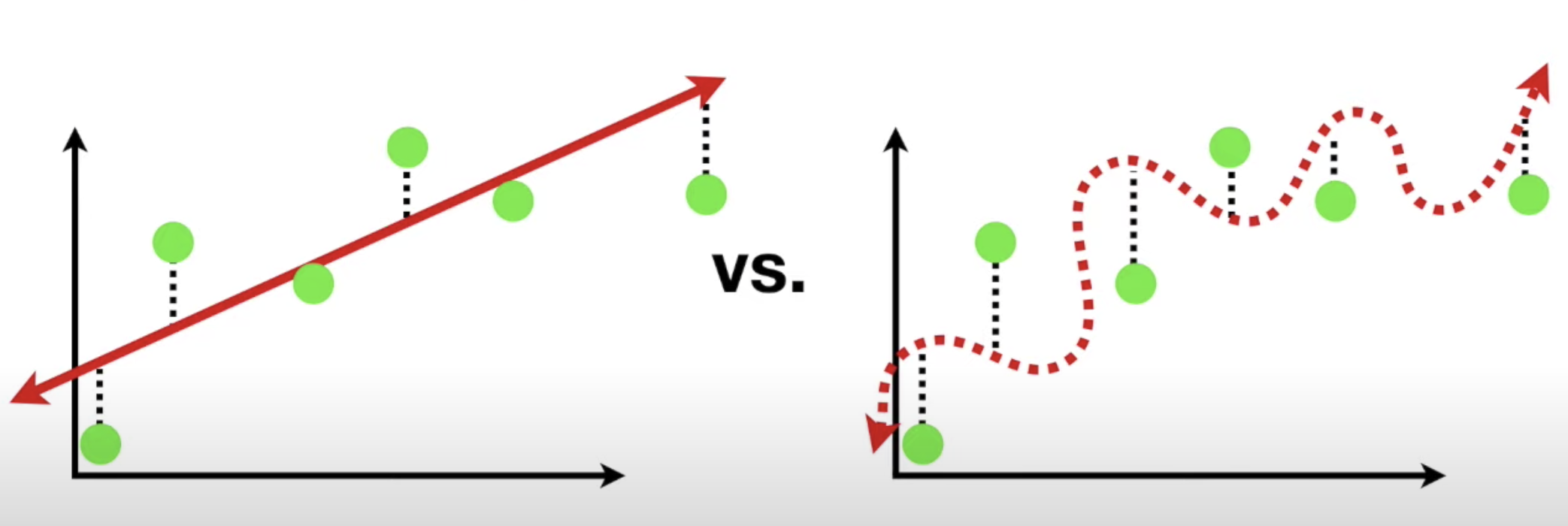
왼쪽 그림: 분산이 작다
오른쪽 그림: 분산이 크다
모델이 복잡하다?
복잡성의 기준은 분산을 통해서 볼수 있으며 트레이닝 데이터를 항을 계속 추가하면 복잡하게 된다. 즉, 파라미터가 많아지면 모델이 복잡해진다!
회귀 모델의 평가지표

이미지 출처: https://www.datatechnotes.com/2019/02/regression-model-accuracy-mae-mse-rmse.html
- MSE (Mean Squared Error): 잔차 제곱의 합의 평균
-L2-norm
-제곱을 해서 이상치(outlier)에 민감하다.
- MAE (Mean absolute error): 잔차 절대값의 합의 평균
-L1-norm
-Mse보다는 특이치에 덜 민감하도록 절대값으로 사용
- RMSE (Root Mean Squared Error): 잔차 제곱의 합의 평균에 루트를 씌운 값
-오류 지표를 실제값과 유사한 단위로 변환해서 해석이 용이해짐
- R-squared (Coefficient of determination): 결정계수
-MAE, MSE는 데이터의 SCALE에 따라 값이 다른데 R2는 상대적인 성능이 어느정도인지 직관적으로 판단 가능

적절한 평가지표를 어떻게 선택하고 사용하는지 구분하기
각각의 지표가 어떤특징이 있는지 정리가 되면 어쩔때 언제쓰는지 알수 있을것
