
🎯 범주형 자료에 사용하는 "원핫인코딩"
원핫인코딩(One-Hot encoding)
범주형 데이터를 1(한개의 요소),0(한개 빼고 나머지)로 인코딩 해주는 기법
회귀 모델은 문자를 인식을 못하기 때문에 원핫인코딩을 진행
범주형 변수
명목형: 순서 또는 높고 낮음이 없는 데이터
순서형: 순서 정보가 있는 데이터
*순서가 의미 없는 범주들을 순서 인코딩을 하면 안좋은 결과를 가져옴!
📜 어떻게 보여지나요?
명목형 컬럼(color) 값(red, yellow, green)을 여러개의 0과 하나의 1로 나타냄
출처: 코드스테이츠

컬럼이 너무 많아지면?
각 특성의 범주에 들어가는 변수들이 모두 새로운 특성이 되므로 범주의 종류가 많아질수록 전체 데이터의 특성이 엄청나게 늘어남 (이렇게 많아지는걸 ⚠️high cardinality라고 말함) 이럴경우 원핫인코딩이 좋지 않음
🚫 원핫인코딩 한계점
1. 컬럼의값이 많아질수록 벡터를 저장하기 위해 필요한 공간이 계속 늘어나는 단점이 있다. 백터의 차원이 늘어난다는 것인데 각각의 값이 하나의 값만 가지고 0을 가진 나머지의 벡터들 때문에 저장공간 측면에서는 매우 비효율적이다.
2. 단어의 유사도를 표현하기 어렵다. 레몬, 라임, 체리, 앵두라는 단어에 원핫인코딩을 했을때 레몬,라임과 체리,앵두가 유사한 단어지만 유사하다는 것을 표현할 수 없다. 이는 검색 시스템에서 문제가 되며 제주도 호텔을 검색했을 때 제주도 호텔 예약, 제주도 특가 호텔과 같은 유사 단어에 대한 결과를 함께 보여줄 수 없을 것이다.
원핫인코딩 구현
- pandas get_dummies
- category_encoders
정보적으로 불필요한 컬럼 없앰(기준은?)
도메인 지식에 따라 다름
🎯 특성 선택(Feature selection)
특성공학(Feature enineering): 도메인 지식을 사용해 데이터에서 피쳐를 변형 또는 생성
특성추출(Feature Extraction): 차원축소등 새로운 중요 피쳐를 추출
특성선택(Feature Selection): 기존 피쳐에서 원하는 피쳐만(변경없이)선택
특성을 뽑는 방법?
-SelectKbest를 이용
-타겟과 가장 상관관계가 높은(가장 효과적인!) 특성을 뽑아서 진행
특성 선택 장단점
⭕️장점)각 특성들이 독립적으로 평가가되므로 빠르고 모델과 상관없이 전처리에서 사용함
⭕️장점)과적합 줄이고 모델 성능을 높임(모델 훈련시간도 감소)
❌단점)특성은 갯수가 늘어날 수록 그 조합이 기하급수적으로 늘어남
-몇가지 스코어 함수를 사용하는데 회귀에서는 f_regression을 주로 사용함
🎯 릿지 회귀를 통해 일반화하기
릿지 회귀
이미지 출처:https://ichi.pro/ko/seonhyeong-hoegwieseo-lisji-hoegwi-lasso-mich-elastic-net-eulo-86512636393446
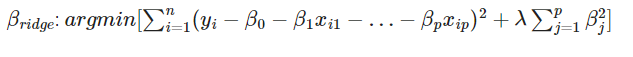
출처:https://ratsgo.github.io/machine%20learning/2017/05/22/RLR/
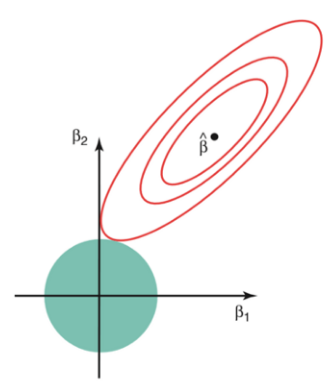
그림설명
빨간 선: MSE가 동일한 [β1,β2]의 자취
베타 검정점(빨간 선 중앙): 선형회귀 모델의 MSE가 최소가 되는 지점
녹색 원: 트레이닝 상태에 적합한 L2 norm으로 제약을 걸어둔 것
즉, 녹색원이 작아질 수록 L2 norm이 감소하고 제약이 커집니다.
(수식)람다가 커질수록 β의 L2 norm이 줄어듭니다.
📌릿지회귀
릿지회귀는 편향을 높이고 분산을 줄여서 일반화를 진행한다.
즉, 일부로 덜 학습시켜서 장기적으로 더 좋은 모델을 만드는 것인데 기존의 다중회귀모델을 훈련데이터에 덜 적합하게 만드는 것이다.
how to?
정규화(어제 배운 내용과 다름): 선형회기계수에 제약(L2-norm)주고>과적합을 방지
회귀계수를 제약을줘서 축소시키면 연산속도가 빨라지고 일반화도 잘 유도된다!!
(람다가 0에 가까워지면 다중회귀모델이 됨)
ridge cv: 릿지회귀의 람다값을 결정할때 사용할 수 있는 방법(최적의 패널티 값 찾기), 최적의 람다값(람다값의 범위 alphas)
일부만 사용하는 모델 어떻게 선택?
select K best를 사용한다.
🎯 라쏘 회귀
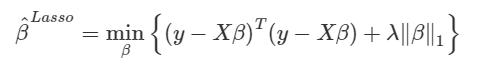
출처:https://ratsgo.github.io/machine%20learning/2017/05/22/RLR/
라쏘회귀
릿지회귀와 동일하지만 L1 norm을 제약함
라쏘회귀는 예측에 중요하지 않는 변수의 회귀계수를 감소시키면서 변수선택하는 효과가 있다.
🎯 엘라스틱넛

출처:https://ratsgo.github.io/machine%20learning/2017/05/22/RLR/
엘라스틱넛
L1,L2 norm 모두 쓰는 기법


