Node.js가 작업을 처리하는 방법
V8과 libuv는 Node.js의 두 가지 핵심 구성 요소입니다. 각각은 다음과 같은 역할을 수행한다.
- V8: 이는 Google에 의해 개발된 자바스크립트 엔진이다. Node.js는 V8 엔진 위에서 구현되며, 이 엔진은 자바스크립트 코드를 빠르게 실행할 수 있게 해 준다. V8은 기본적으로 자바스크립트 코드를 기계 코드로 컴파일하고 실행하는 역할을 한다.
- libuv: 이 라이브러리는 Node.js가 비동기 I/O를 처리하기 위해 사용된다. 파일 시스템 액세스, 네트워크 작업 등에 사용되며, 이벤트 루프와 워커 스레드 풀을 관리한다. libuv는 Node.js가 동시에 여러 I/O 작업을 효율적으로 처리할 수 있게 해 준다.
V8과 libuv의 관계
-
코드 실행: 사용자가 작성한 자바스크립트 코드는 V8 엔진에 의해 실행된다. 이 코드 내에서 비동기 API 호출(예: 파일 읽기, 네트워크 요청 등)이 발생하면, 그 처리는 libuv로 위임된다.
-
이벤트 루프: libuv는 이벤트 루프를 관리한다. 이벤트 루프는 외부 이벤트를 모니터링하고 해당 이벤트에 콜백 함수를 실행한다. 이때 이벤트 루프는 V8 엔진과 상호 작용하여 콜백 함수 (자바스크립트 코드)를 실행시킨다.
-
비동기 작업: libuv는 비동기 I/O 작업을 위한 워커 스레드 풀을 관리한다. 비동기 작업이 완료되면, 그 결과는 이벤트 루프를 통해 자바스크립트 콜백 함수로 전달된다. 이 콜백 함수는 다시 V8에 의해 실행된다.
-
언어 바인딩: V8과 libuv 사이의 연결은 C++로 작성된 바인딩을 통해 이루어진다. 이 바인딩은 자바스크립트와 네이티브 C/C++ 코드 사이의 "다리" 역할을 한다.
결과적으로, V8과 libuv는 서로 상호 작용하면서 Node.js의 주요 기능인 빠른 코드 실행과 효율적인 비동기 I/O 처리를 가능하게 한다.
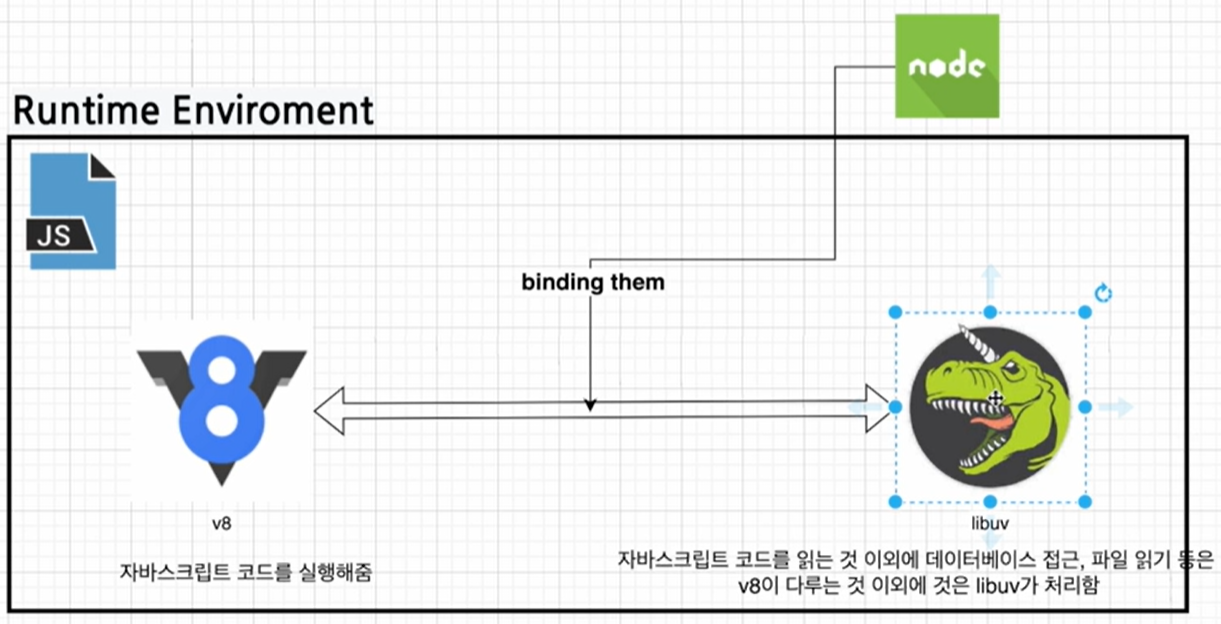
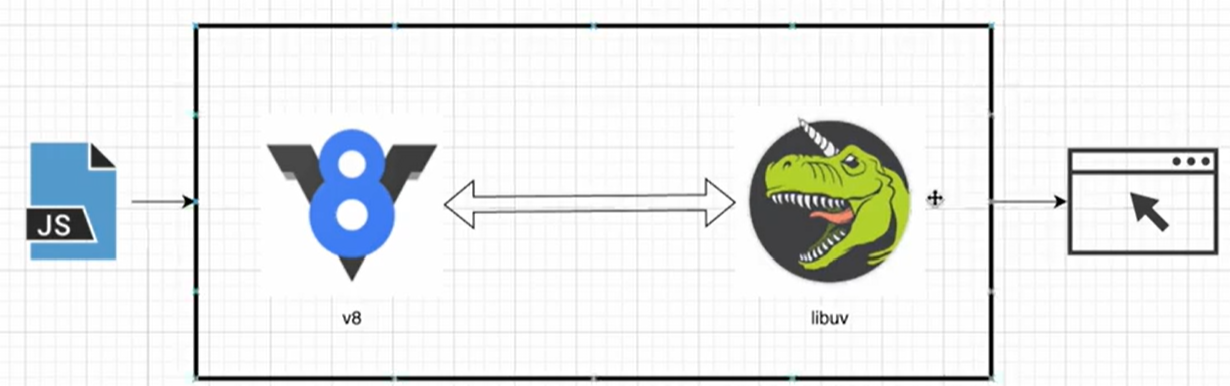
↑ v8으로 처리할 수 있는 JS는 처리하고, 나머지는 libuv가 처리한다음, 브라우저를 보여준다.
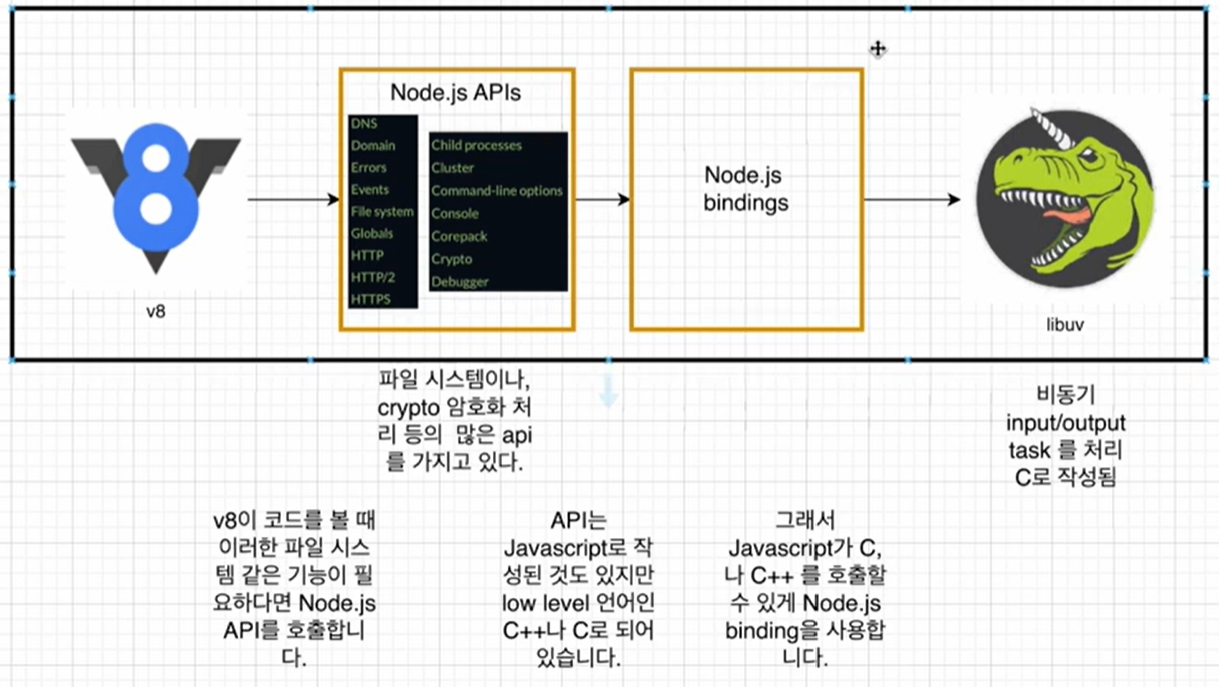
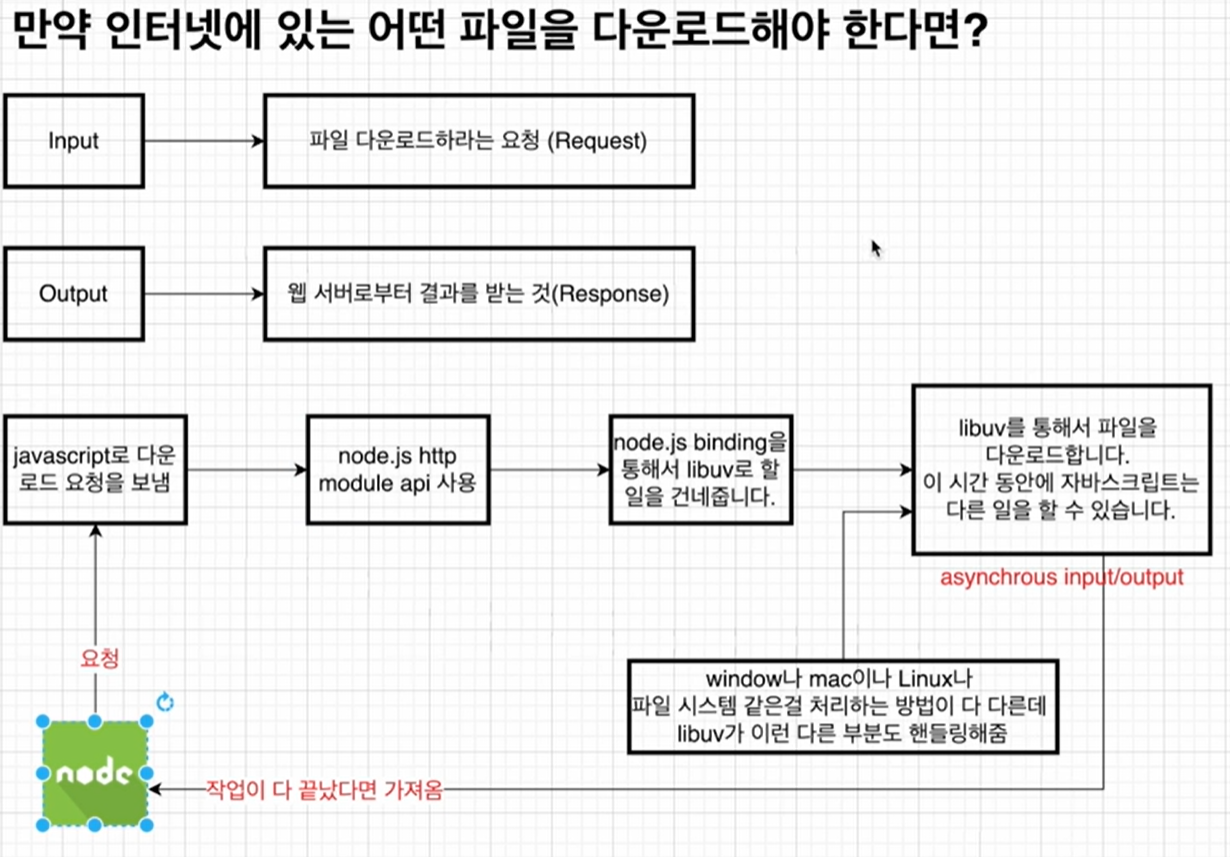
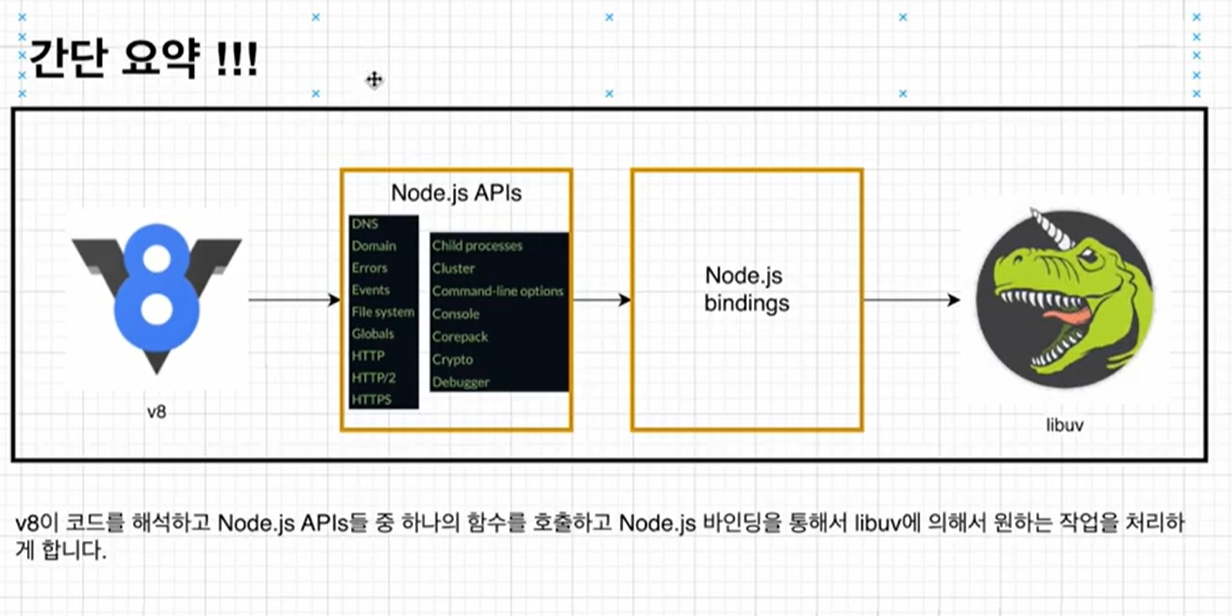
Node 오픈소스 코드를 통한 이해
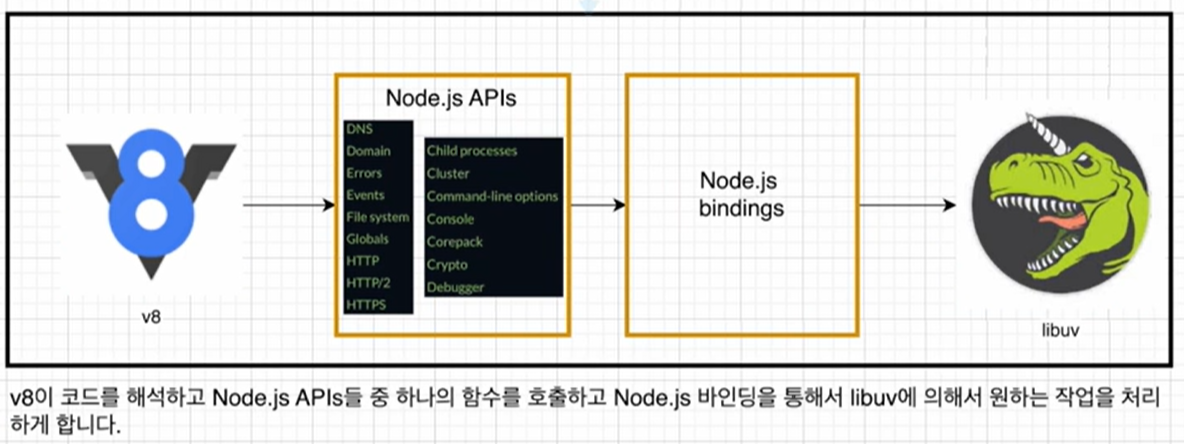
위 과정이 어떻게 처리되는지, 오픈소스 코드를 통해 이해해보자.
libuv

libuv는 Node.js의 핵심 부분 중 하나로, 크로스 플랫폼 비동기 I/O 작업을 지원하는 C 라이브러리이다. libuv는 원래 Node.js를 위해 개발되었지만, 이제는 다른 여러 프로젝트에서도 사용되고 있다.(Julia, Luvit, pyuv등) Node.js는 이 라이브러리를 사용하여 지원되는 모든 플랫폼에서 통합 인터페이스로 I/O작업을 추상화 한다. 즉 libuv를 쓰면 각 플랫폼(window, linux)의 가장 빠른 비동기 IO인터페이스로 통일된 코드로 돌릴 수 있다는 장점이 있다.
이 라이브러리의 주요 기능은 다음과 같다.
-
이벤트 루프
libuv는 Node.js의 이벤트 루프를 제공한다. 이 이벤트 루프는 비동기 작업을 스케줄링하고 완료를 처리한다. -
비동기 I/O 연산
libuv는 파일 시스템 작업, 네트워크 작업 (TCP, UDP), DNS 조회 등 다양한 비동기 I/O 작업을 지원한다. -
스레드 풀
CPU-bound 작업이나 블로킹 I/O 작업을 위해 libuv는 내부적으로 스레드 풀을 관리한다. 이 스레드 풀은 블로킹 작업을 백그라운드에서 수행할 수 있게 해준다. -
타이머와 타임아웃
libuv는 높은 정밀도 타이머와 타임아웃을 지원하여 지연이나 반복 작업을 스케줄링할 수 있다. -
신호 처리
Unix 신호를 비동기적으로 처리할 수 있는 기능도 제공한다. -
크로스 플랫폼
libuv는 Windows, macOS, Linux 등 다양한 운영체제에서 작동한다. 이로 인해 Node.js 애플리케이션은 다양한 플랫폼에서 실행 가능하게 된다. -
스트림과 버퍼
libuv는 데이터 스트림 처리와 버퍼 관리 기능을 제공한다.
이러한 기능들 덕분에 libuv는 Node.js에서 비동기 I/O 작업과 이벤트 루프를 효율적으로 처리할 수 있게 해준다.
비동기와 동기 (asynchronous vs synchronous)
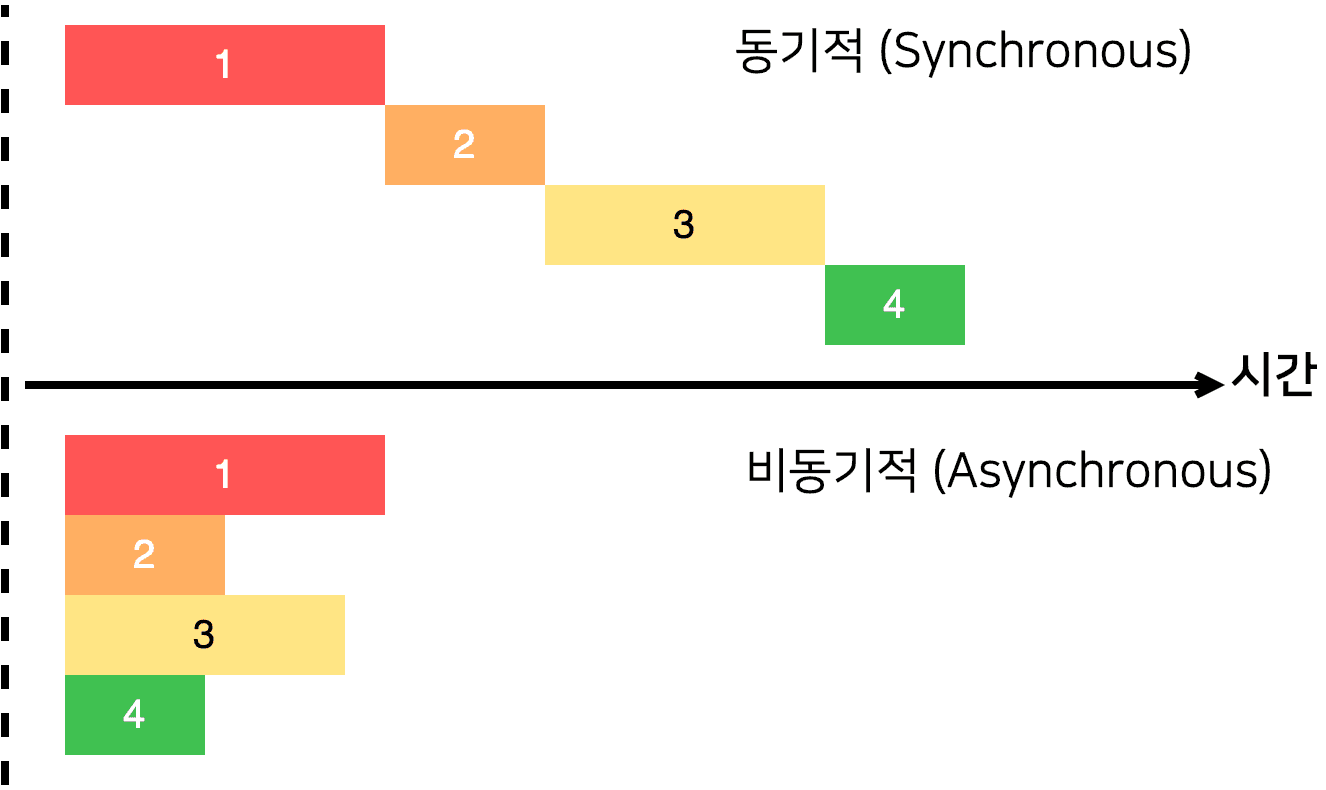
동기 (Synchronous) 작업
동기적인 작업은 한 번에 하나씩 순차적으로 처리다. 즉, 하나의 작업이 완료될 때까지 다음 작업은 대기 상태에 있다. 동기 코드는 보통 더 쉽게 이해하고 디버그할 수 있지만, 느린 I/O 작업(예: 파일 읽기, 네트워크 통신)이 있을 때 전체 시스템이 블로킹(blocking)되어 대기하는 문제가 있을 수 있다.
const fs = require('fs');
console.log('Reading file...');
const data = fs.readFileSync('file.txt', 'utf8');
console.log(data);
console.log('File read complete.');비동기 (Asynchronous) 작업
비동기적인 작업은 여러 작업이 동시에 처리될 수 있다. 하나의 작업이 완료되기를 기다리지 않고 다음 작업을 시작할 수 있다. 이렇게 하면 느린 I/O 작업이 있을 때도 시스템이 다른 작업을 계속 처리할 수 있다.
const fs = require('fs');
console.log('Reading file...');
fs.readFile('file.txt', 'utf8', (err, data) => {
if (err) throw err;
console.log(data);
});
console.log('File read initiated.');비동기 코드는 일반적으로 콜백, 프로미스, async/await 등을 사용하여 구현된다. 이러한 방식은 동기 코드보다 복잡할 수 있지만, 더 높은 성능과 사용성을 제공한다.
콜백 (Callback)
비동기 작업이 완료될 때 호출될 함수를 인자로 전달하는 방식이다.
프로미스 (Promise)
비동기 작업의 최종 성공 또는 실패를 나타내는 객체이다. .then()과 .catch() 메서드를 사용하여 비동기 결과를 처리할 수 있다.
Async/Await
async와 await 키워드를 사용하여 비동기 코드를 마치 동기 코드처럼 보이게 만드는 ES2017의 새로운 기능이다. 내부적으로 프로미스를 사용한다.
정리
- 동기: 작업이 순차적으로 실행됩니다. 하나가 완료될 때까지 다음 작업은 대기한다.
- 비동기: 여러 작업이 동시에 실행될 수 있습니다. 작업의 완료 순서는 보장되지 않는다.
비동기 작업은 특히 I/O 바운드 작업이나 네트워크 작업 등에서 유용하다. 이를 통해 시스템이 더 효율적으로 동작하고, 대기 시간을 최소화할 수 있다.
코드로 보는 async, sync
동기
console.log('1')
console.log('2')
// 1
// 2비동기
setTimeout(() => {
console.log('1')
}, 1000);
console.log('2')
// 2
// 1노드 js에서 비동기를 주요 사용한다.
노드js에서 비동기를 주로 사용함.
데이터 베이스에서 데이터를 읽을 때, 저장할 때, 지울 때 등 대부분의 요청이 비동기로 이루어진다.
대부분의 작업이 어느정도의 시간을 요하기 때문이다.
이 덕분에 여러개의 작업을 해도 다른 작업을 기다리지 않고 빠르게 여러 작업을 처리할 수 있다.
Javascript는 Synchronous언어
자바스크립트는 한 줄 실행하고 또 다음 줄 실행하는 동기언어이다.
하지만 생각해보면 콜백 함수를 실행하는 비동기 코드를 사용했다.
setTimeout(() => {
console.log('1')
}, 1000);
console.log('2')
// 2
// 1비동기 코드를 작성하기 위해서 자바 스크립트 이외의 도움을 받는다.
위의 setTimeout도 보면 사실 자바스크립트의 부분이 아니다.
브라우저에서 사용을 한다면 브라우저 api를 사용하는 것이며(window object).
Node에서 사용한다면 Node api를 사용하는 것이다. (global object)
blocking, non-blocking in node.js
Blocking (블로킹)
Blocking이라는 용어는 특정 작업의 완료를 기다리는 동안 프로그램이 다른 작업을 수행할 수 없다는 것을 의미한다. 즉, 해당 작업이 완료될 때까지 모든 것이 '막혀있다(blocked)'고 볼 수 있다.
Node.js에서는 이러한 동기적(synchronous) 작업을 수행할 수 있으나, 주로 비동기적(asynchronous) 방식이 권장된다. 왜냐하면 Node.js는 싱글 스레드(single-threaded) 이벤트 루프를 사용하기 때문에, 블로킹 연산은 모든 시스템 작업에 영향을 줄 수 있다.
Blocking Function
JSON.stringfy 함수와 window.alert는 Blocking 함수이다.
해당 작업을 마쳐야 다음 작업을 수행할 수 있다.
Node.js에 있는 Blocking 메소드
const fs = require('fs');
const data = fs.readFileSync('/file.md'); // blocks here until file is read
console.log(data)
moreWork(); // will run after console.logNode.js 표준 라이브러리의 모든 I/O메서드는 non-blocking및 callback함수를 허용하는 비동기 버전을 제공한다. 일부 메서드에는 이름이 Sync로 끝나는 차단 상대도 있다.
Non-Blocking (논블로킹)
Non-Blocking은 반대로 어떤 작업의 완료를 기다리지 않고 다른 작업을 계속 수행할 수 있다. Node.js는 이러한 비동기적(asynchronous) 작업을 위한 여러 가지 메커니즘을 제공한다. 이렇게 하면 I/O 작업 등이 수행되는 동안에도 다른 작업을 계속 처리할 수 있어 효율성이 높아진다.
Non-Blocking Method 사용
const fs = require('fs');
fs.readFIle('/file.md', (err, data) => {
if (err) throw err;
console.log(data);
});
moreWork // will run before console.log첫 번째 예는 두 번째 예보다 간단해 보이지만 두 번째 줄이 전체 파일을 읽을 때까지 추가 JavaScript실행을 차단하는 단점이 있다. 동기식 버전에서는 오류가 발생하면 이를 잡아야 하며 그렇지 않으면 프로세스가 중단된다. 비동기 버전에서 표시된 대로 오류를 발생시켜야 하는지 여부는 작성자가 결정한다.
Blocking코드와 Non-Blocking코드를 함께 쓸 때 발생할 수 있는 문제
const fs = require('fs')
fs.readFile('/file.md', (err, data) => {
if (err) throw err;
console.log(data);
});
fs.unlinkSync('/file.md');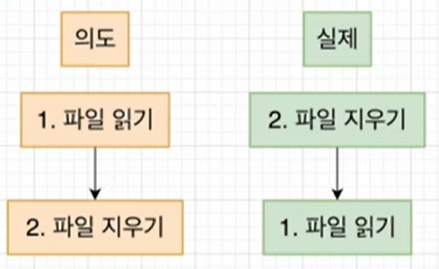
의도와 실제가 다르게 작동할 수 있다.
const fs = require('fs')
fs.readFile('/file.md', (readFileErr, data) => {
if (readFileErr) throw readFileErr;
console.log(data);
fs.unlink('/file.md'. (unlinkErr) => {
if (unlinkErr) throw unlinkErr;
});
});위 내용은 올바른 작업 순서를 보장하는 fs.readFile()의 콜백 내에서 fs.unlink()에 대한 non-blocking 호출을 배치한다.
정리
- Blocking (동기적, Synchronous): 하나의 작업이 완료될 때까지 프로그램의 실행이 중지한다.
- Non-Blocking (비동기적, Asynchronous): 하나의 작업이 완료되기를 기다리지 않고 다음 작업을 진행한다.
Node.js에서는 논블로킹 방식이 권장되는데, 이는 Node의 이벤트 루프와 싱글 스레드 구조 때문이다. 논블로킹 방식을 사용하면 더 많은 요청을 빠르고 효율적으로 처리할 수 있다.
프로세스 및 스레드
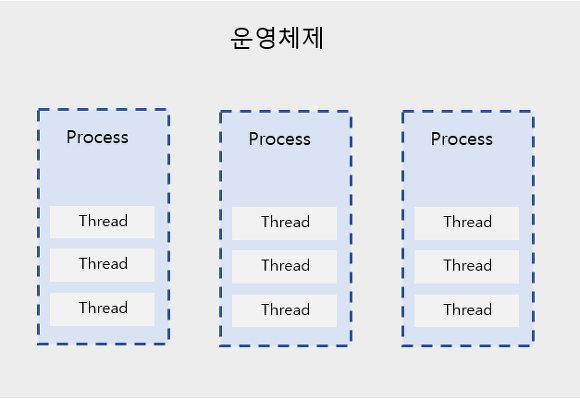
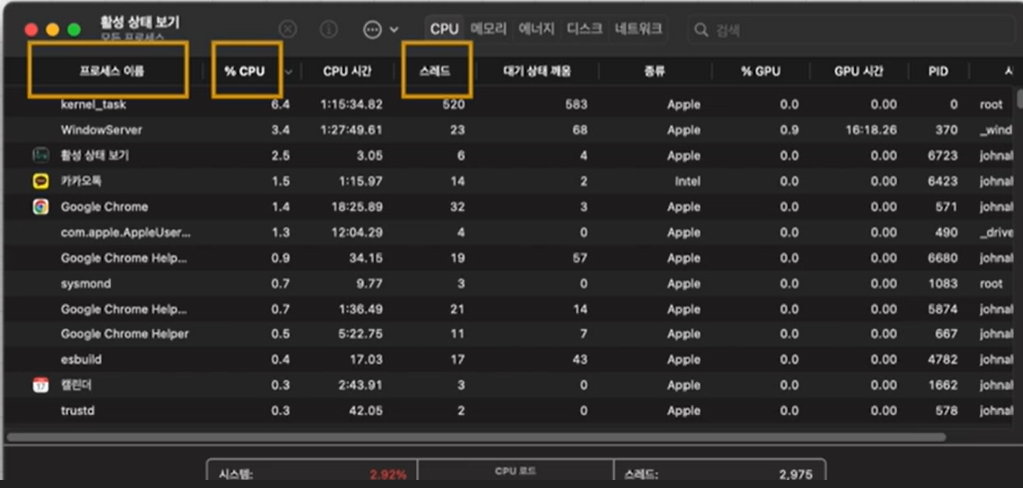
위애서 프로세스가 몇 개의 스레드를 사용하는지 볼 수 있다.
프로세스 (Process)
프로세스는 컴퓨터에서 연속적으로 실행되는 프로그램 인스턴스를 의미한다. 각 프로세스는 독립적인 메모리 공간, 데이터, 인스트럭션 및 다른 리소스를 가진다. 운영 체제는 이러한 프로세스들을 관리하며, 필요에 따라 CPU 시간을 할당하거나 I/O 작업을 조정한다.
프로세스는 다음과 같은 특징을 가진다.
- 독립적인 메모리 공간을 가진다.
- 프로세스 간에는 메모리가 분리되어 있어, 하나의 프로세스가 다른 프로세스의 리소스에 직접 접근할 수 없다.
- 프로세스 간의 통신 (Inter-Process Communication, IPC)은 특별한 메커니즘을 통해 이루어진다 (예: 소켓, 파이프, 메시지 큐 등).
프로세스란 좀 더 자세히...
실행파일을 클릭했을 때, 메모리(RAM)할당이 이루어지고 이 순간부터 이 프로그램은 '프로세스'라 불리게 된다.
다음 이미지는 메인 메모리 내부 프로세스의 단순화된 레이아웃을 보여준다.
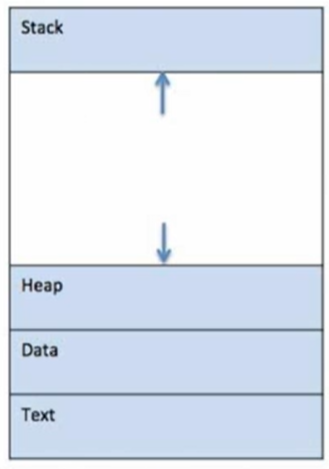
Stack: 프로세스 스택에는 메서드/함수 매개변수, 반환 주소 및 지역 변수와 같은 임시 데이터가 포함된다.
Heap: 이것은 런타임 동안 프로세스에 동적으로 할당된 메모리이다.
Data: 이 섹션에는 전역 및 정적 변수가 포함되어 있다.
Text: 여기에는 Program Counter값과 프로세서 레지스터의 내용이 나타내는 현재 활동이 포함된다.
Heap의 영역이 증가하여 Stack의 영역을 침범하면 Heap Overflow
Stack의 영역이 증가하여 Heap의 영역을 침범하면 Stack Overflow
이러한 상황이 될 때 사용되는 메모리의 자유 영역 또한 존재한다.
프로세스 메모리의 속도는 Stack > Data > Code > Heap 순으로 빠르다.
스레드 (Thread)
스레드는 프로세스 내에서 실행되는 가장 작은 실행 단위이다. 스레드는 해당 프로세스의 메모리와 리소스를 공유하며 실행된다. 즉, 하나의 프로세스 내에서 여러 스레드가 생성되면, 이러한 스레드들은 같은 메모리 공간에 접근할 수 있다.
스레드는 다음과 같은 특징을 가진다.
- 같은 프로세스 내의 스레드들은 메모리와 리소스를 공유한다.
- 스레딩은 병렬 처리를 가능하게 하므로, 멀티코어 프로세서의 이점을 최대한 활용할 수 있다.
- 스레드 간의 통신은 비교적 쉽고 빠르지만, 리소스를 공유하기 때문에 동기화 문제가 발생할 수 있다.
카카오 프로그램을 실행해 놓으면 알림도 오고 광고도 나와야 한다. 결국 한 프로세스 내에서 여러가지 작업이 동시에 이뤄져야한다. 이 때 쓰레드를 이용하게 된다.
스레드란 프로세스 내에서 일을 처리하는 세부 실행 단위를 말한다.
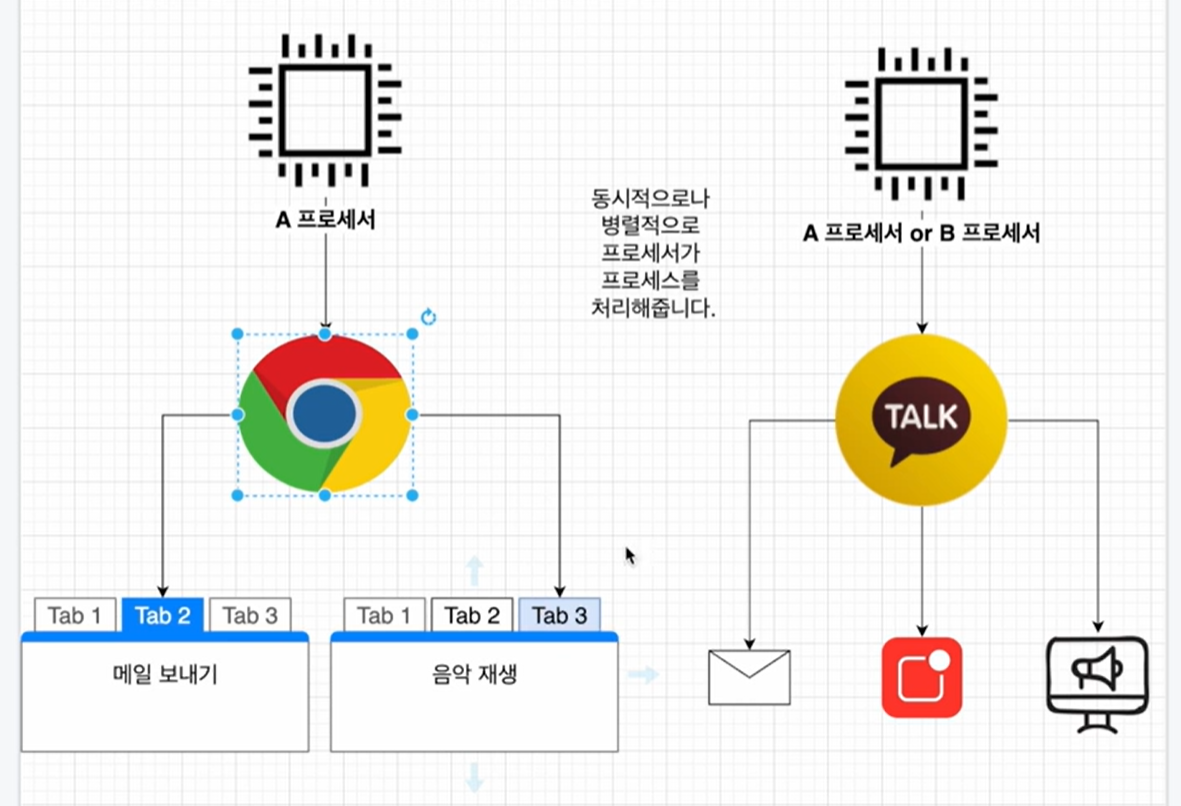
쓰레드는 자원 공유
아래의 그림에서 처럼 하나의 프로세스 안에서 스레드들은 자원을 공유하게 된다.
카카오톡 프로세스 안에서는 비슷한 일을 할 수 있기 때문에 자원을 공유하는게 효율적이다.
자원을 공유해서 나오는 단점은 공유하는 자원에 여러개의 쓰레드가 동시에 접근할 때 에러가 날 수 있다. 이러한 경우를 위한 코등을 하기도 디버깅을 하기도 어렵다.
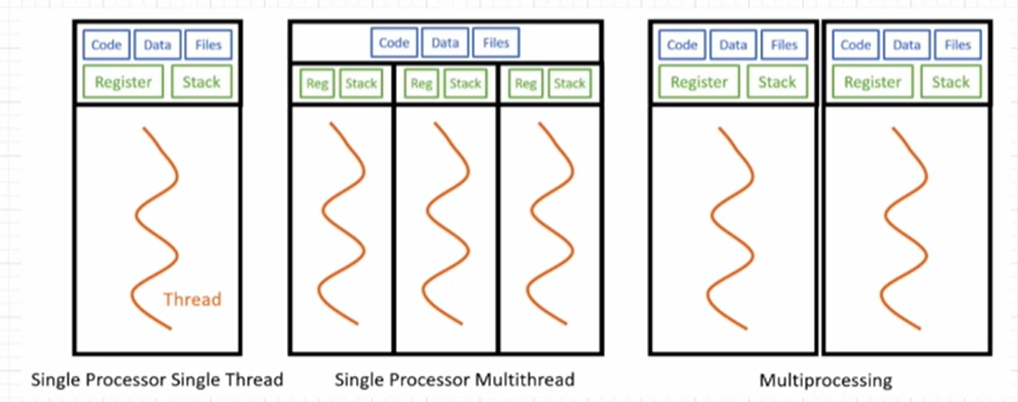
싱글 스레드, 멀티 스레드
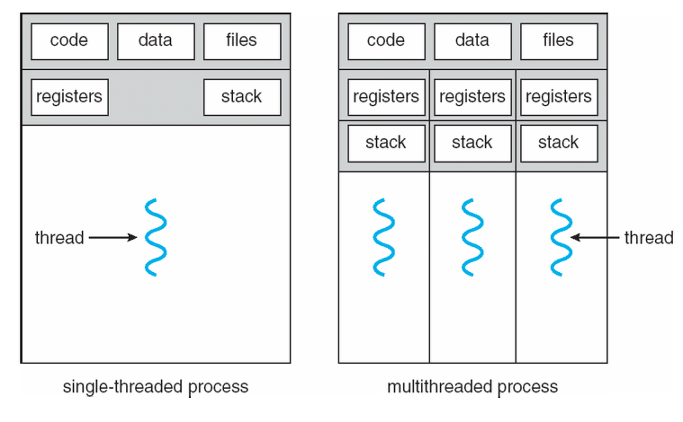
| 싱글 스레드 | 멀티 스레드 |
|---|---|
| 하나의 프로세스에서 하나의 스레드를 실행한다. 그래서 프로세스 내의 작업을 순차적으로 실행한다. | 하나의 프로세스 내에 여러 개의 스레드가 실행된다. |
| 위와 같은 특징으로 인해서 여러가지 작업 처리가 늦어 질 수 있다. | 각각의 스레드가 다른 작업을 할당받아서, 프로세스가 병렬적으로 여러 작업을 동시에 수행할 수 있다. |
| 각각 Stack만 따로 할당받고, Code, Data, Heap영역은 공유한다. |
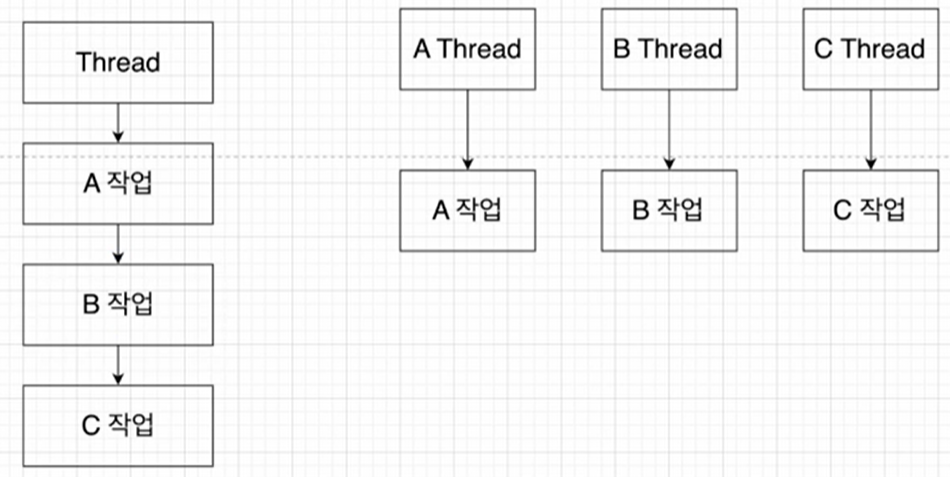
(왼쪽은 싱글스레드, 오른쪽을 멀티스레드의 작업 방식)
멀티 쓰레딩의 단점
- 공유하는 자원에서 동시에 접근할 때 신경을 써줘야 함
- 스레드 간에 데이터와 힙 영역을 공유하기 때문에 변수나 자료 구조에서 겹쳐서 오류가 날 수 있다.
- 이러한 문제로 동기화 작업이 필요하다.
- 병목 현상이 생겨 성능을 저하시킬 수 있다.
- 결국은 멀티 스레딩을 관리하는 것은 쉽지 않다!
정리
- 프로세스: 독립적인 실행 단위, 자체 메모리 공간 및 리소스를 가짐.
- 스레드: 프로세스 내에서 실행되는 더 작은 단위, 메모리와 리소스를 프로세스와 공유.
각각의 방식은 그에 따른 장단점이 있으며, 특정 작업이나 문제 상황에 따라 적절한 선택이 필요하다.
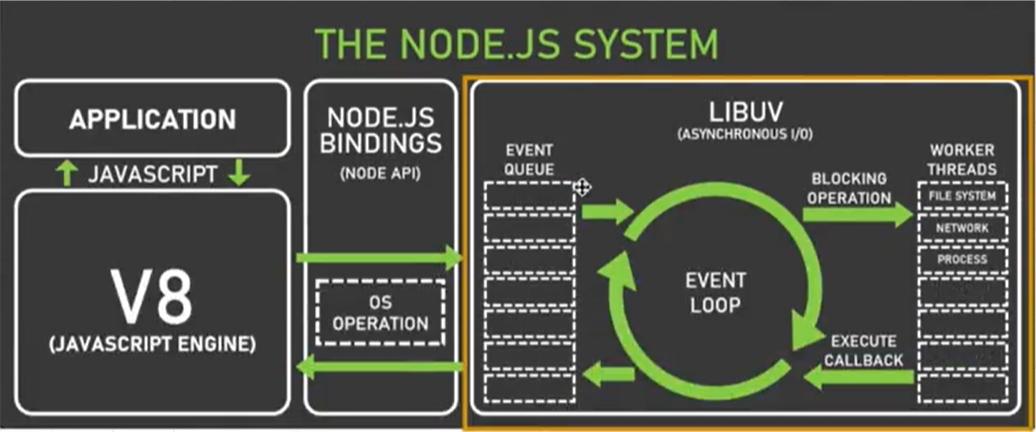
Node.js가 비동기 작업을 처리하는 방법
자바스크립트는 싱글 스레드이고, Node.js는 자바스크립트 언어를 사용한다.
싱글 스레드면 한 번에 하나의 작업만 할 수 있는데, Node.js를 보면 어떻게 비동기로 파일을 열고 HTTP리퀘스트를 보낼 수 있을까?
노드는 LIBUV에서 제공하는 Event Loop를 이용한다.
아래 도표에서 처럼 어떠한 Task들이 들어오면 Libuv에 있는 이벤트 루프를 이용해 처리해주고 있다.
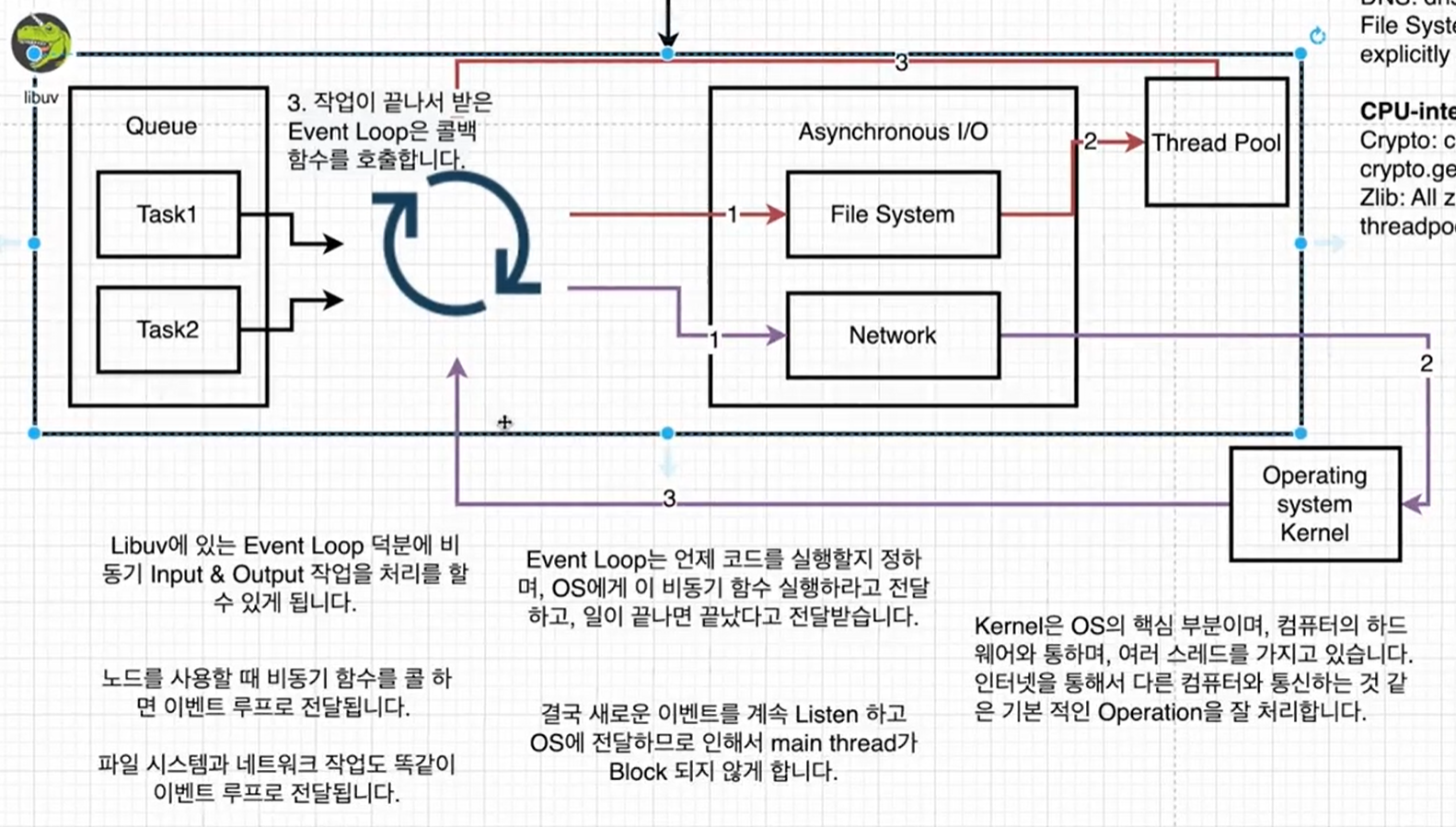
Event Loop에서 일을 전달할 때 어디로 전달하나?
File System은 Thread Pool로
Network는 Operating System에 있는 커널로 직접 전달한다.
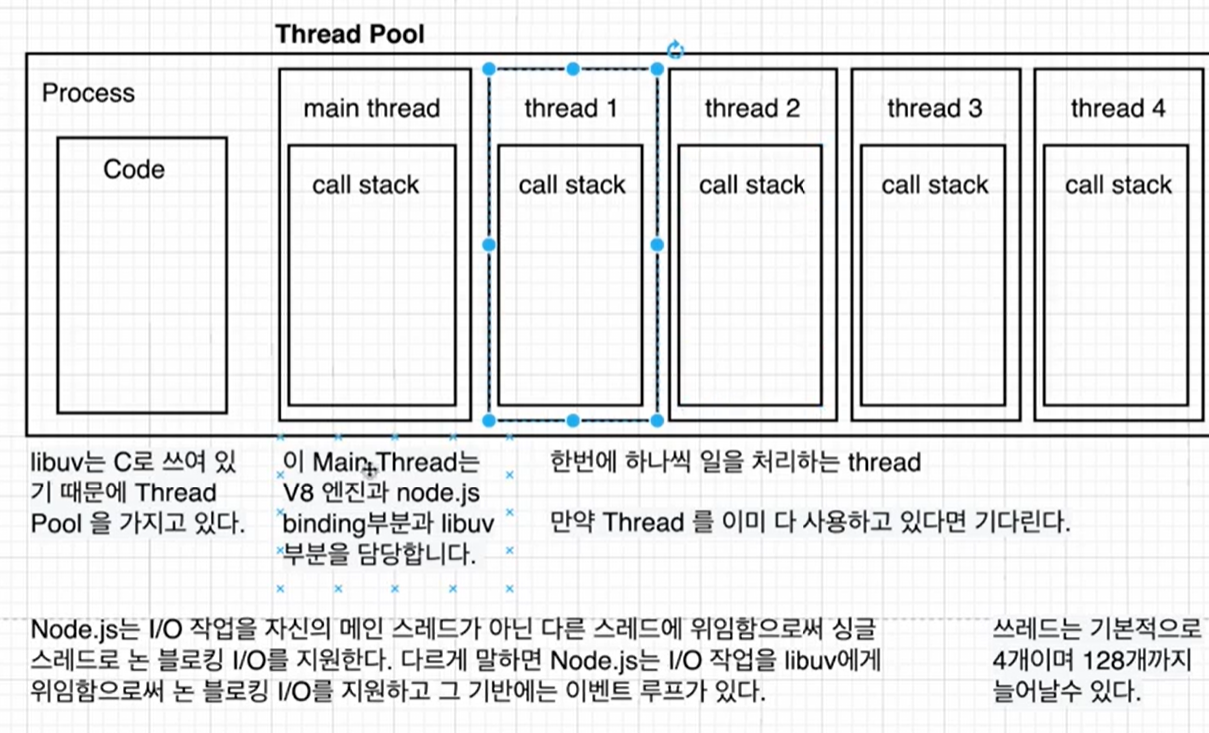
쓰레드는 기본적으로 4개이며 128개까지 늘어날 수 있다.
만약 500명이 한꺼번에 비동기 요청을 한다면?
처음부터 1,2,3,4 쓰레드에서 처리하고 나머지는 기다리고 끝나면 하나씩 계속 처리 한다.
비동기 작업을 처리하는 방법 정리
Node.js는 비동기 작업을 처리하기 위해 이벤트 루프와 비동기 I/O를 활용한다. Node.js는 기본적으로 단일 스레드로 작동하기 때문에 블로킹(Blocking) 연산을 피해야 여러 요청을 효율적으로 처리할 수 있다. 다음은 Node.js에서 비동기 작업을 처리하는 주요 요소다.
-
이벤트 루프 (Event Loop)
이벤트 루프는 Node.js의 핵심 구성요소 중 하나로, 블로킹이 발생하지 않도록 하여 단일 스레드에서도 높은 처리 능력을 유지한다. 이벤트 루프는 콜백 큐에서 함수를 꺼내와 실행하며, 콜 스택이 비어있을 때만 이 작업을 수행한다. -
콜백 함수 (Callback)
Node.js는 대부분의 I/O 작업을 비동기 방식으로 처리한다. 이러한 비동기 함수는 보통 마지막 인수로 콜백 함수를 받아, 작업이 완료되었을 때 해당 콜백 함수를 호출한다. -
프로미스 (Promise) 및 Async/Await
콜백 지옥(Callback Hell)을 해결하기 위해 프로미스(Promise)와 Async/Await 같은 추상화 메커니즘이 도입되었다. 이러한 메커니즘은 비동기 작업을 좀 더 가독성 있고 관리하기 쉬운 코드로 작성할 수 있게 도와준다. -
libuv 라이브러리
Node.js는 libuv라는 C 라이브러리를 사용하여 이벤트 루프와 비동기 I/O를 처리합니다. libuv는 다양한 플랫폼에서 일관된 비동기 I/O 성능을 제공한다. -
Non-Blocking I/O
Node.js는 파일 시스템 작업, 네트워크 요청, 데이터베이스 쿼리 등의 I/O 작업을 비동기로 처리하여, 이러한 작업들이 이벤트 루프를 블로킹하지 않게 한다.
이러한 메커니즘과 도구들을 통해 Node.js는 단일 스레드로도 높은 처리 능력과 스케일링 능력을 가질 수 있다.
정리
-
코드가 호출 스택에 쌓인 후 실행하되 그것이 비동기 작업이라면 이벤트 루프는 비동기 작업을 위임한다.
-
Node를 구성하는 libuv는 해당 비동기 작업이 OS커널에서 할 수 있는 것인지, 아닌지(thread pool에서 처리)를 판단하여 비동기 함수를 처리한다.
-
비동기 작업을 처리하고 콜백 함수를 호출한다.
Event Loop
이벤트 루프(Event Loop)는 비동기 작업을 처리하기 위한 핵심 메커니즘이며, 많은 프로그래밍 언어와 환경, 특히 자바스크립트와 Node.js에서 중요한 역할을 한다. 이벤트 루프의 기본적인 역할은 "이벤트" 또는 "작업"이 발생했을 때 해당 작업을 처리하고 적절한 콜백 함수를 실행하는 것이다.
(X) => console.log("Hello World") 동기작업
(O) => file.readFile('file.txt', callback) 비동기 작업
이러한 비동기 작업들을 모아서 관리하고 순서대로 실행할 수 있게 해주는 도구.
이벤트 루프 구조
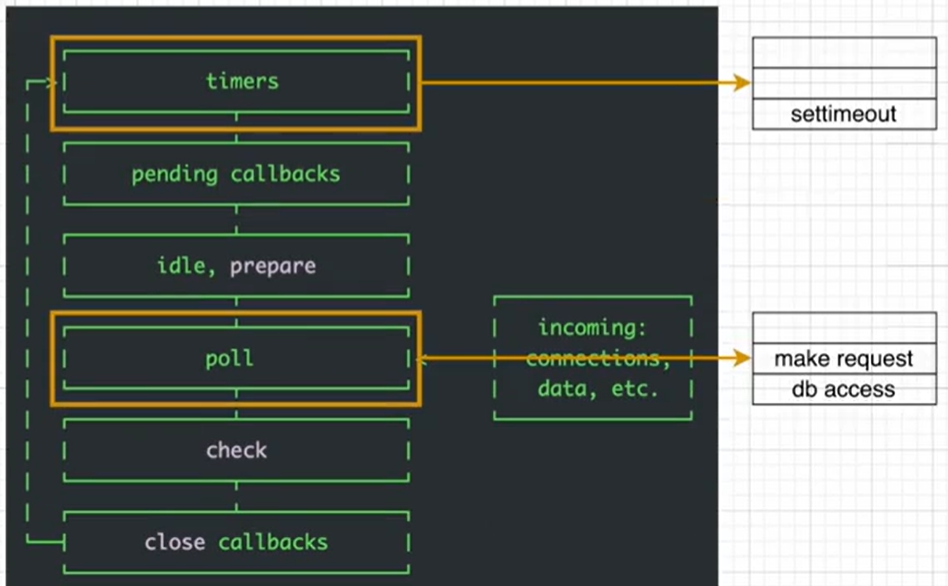
-
timers: 이 단계에서는 setTimeout 및 setInterval 에 의해 예약된 콜백이 실행된다. 지정된 시간이 경과한 후에 실행될 콜백이 실행된다.
-
pending callbacks: 이 단계에서는 지연된 I/O 콜백들이 처리된다. 대부분의 I/O 관련 콜백은 다음 단계인 poll에서 처리되지만, TCP 오류와 같은 특정 경우의 콜백은 이 단계에서 처리된다.
-
idle, prepare: 내부적으로 libuv에 의해 사용되는 단계로, Node.js 프로그래밍에 직접적인 영향을 미치지 않는다. (이 단계에서 이벤트 루프는 아무 작업도 수행하지 않는다.)
-
poll: 이 단계에서 이벤트 루프는 새로운 I/O 이벤트를 받아들인다. 대부분의 I/O 콜백(예: 파일 읽기, 네트워크 연산)이 이 단계에서 처리된다. poll은 새로운 I/O 이벤트를 계속해서 확인하며, 적어도 하나의 콜백이 대기 중이거나 타이머가 실행될 시간이 되면 다음 단계로 넘어간다.
-
check: 이 단계에서는 setImmediate 콜백이 실행된다. setImmediate는 다른 콜백보다 우선하여 즉시 실행되어야 하는 작업에 사용된다.
-
close callbacks: 이 단계에서는 close 이벤트의 콜백들이 실행된다. 예를 들어, socket.on('close', ...)와 같은 콜백이 이 단계에서 처리된다.
이벤트 루프의 각 실행 사이에 Node.js는 비동기 I/O또는 타이머를 기다리고 있는지 확인하고 없는 경우 완전히 종료한다.
이벤트 루프는 위 단계를 계속해서 순환하며, 각 단계에 해당하는 작업들을 처리한다. 따라서 Node.js 애플리케이션은 비동기적으로 여러 작업을 동시에 처리할 수 있다.
- 각 박스는 특정 작업을 수행하기 위한 페이즈(Phase)를 의미한다.
- 그리고 한 페이즈에서 다음 페이즈로 넘어가는 것을 틱(Tick)이라 부른다.
- 각 단계(Phase)에서는 각각의 큐(queue)가 있다. 예를 들어서 settimeout함수가 불러지면 timer라는 페이즈에 있는 큐에 쌓이게 된다. 그리고 이 큐는 First in First Out (FIFO)로, 먼저 들어온 게 먼저 나가게 된다.
- 그리고 싱글 스레드 이기 때문에 timers 페이즈에 있는 일을 끝내거나 최대 콜백 수가 될 때까지 한 후에 다른 단계(페이즈)로 이동하게 된다. (timers 끝내고 => pending callback로 이동)
- 여기서 만약 poll이라는 단계에 왔는데 큐에 콜백 함수(A)하나가 쌓여있었는데 그 (A)콜백 함수 안에 B라는 콜백 함수가 있다면, A콜백 함수 처리 후 B콜백 함수를 poll Queue에 추가한다. 그런데 Node.js가 poll단계를 다시 보고 Q에 B콜백 함수가 남아있으니 그것도 처리한다. 이렇게 다 처리한 후 다음 단계(페이즈)로 넘어간다.
Event Loop 심화
Timer
Timer phase는 이벤트 루프의 시작을 알리는 페이즈이다. 이 페이즈가 가지고 있는 큐에는 setTimeout이나 setInterval타이머들의 콜백을 저장하게 된다.
이 부분에서 바로 타이머들의 콜백이 큐에 들어가는 것은 아니며 타이머들은 min heap에 들어가 있게 된다.
힙에 만료된 타이머가 있는 경우 이벤트 루프는 연결된 콜백을 가져와서 타이머 대기열이 비어 있을 때까지 지연의 오름차순으로 실행을 시작한다.
min heap은 데이터를 이진트리 형태로 관리하며 최솟값을 찾아내는 데 효율적인 구조. 그래서 가장 먼저 실행되는 Timer를 손쉽게 발견할 수 있다.
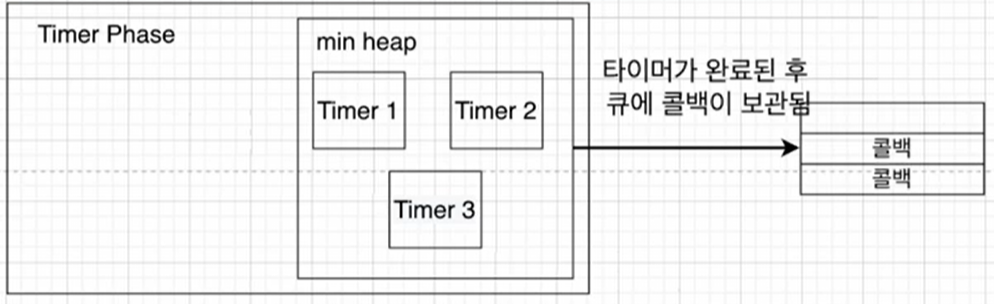
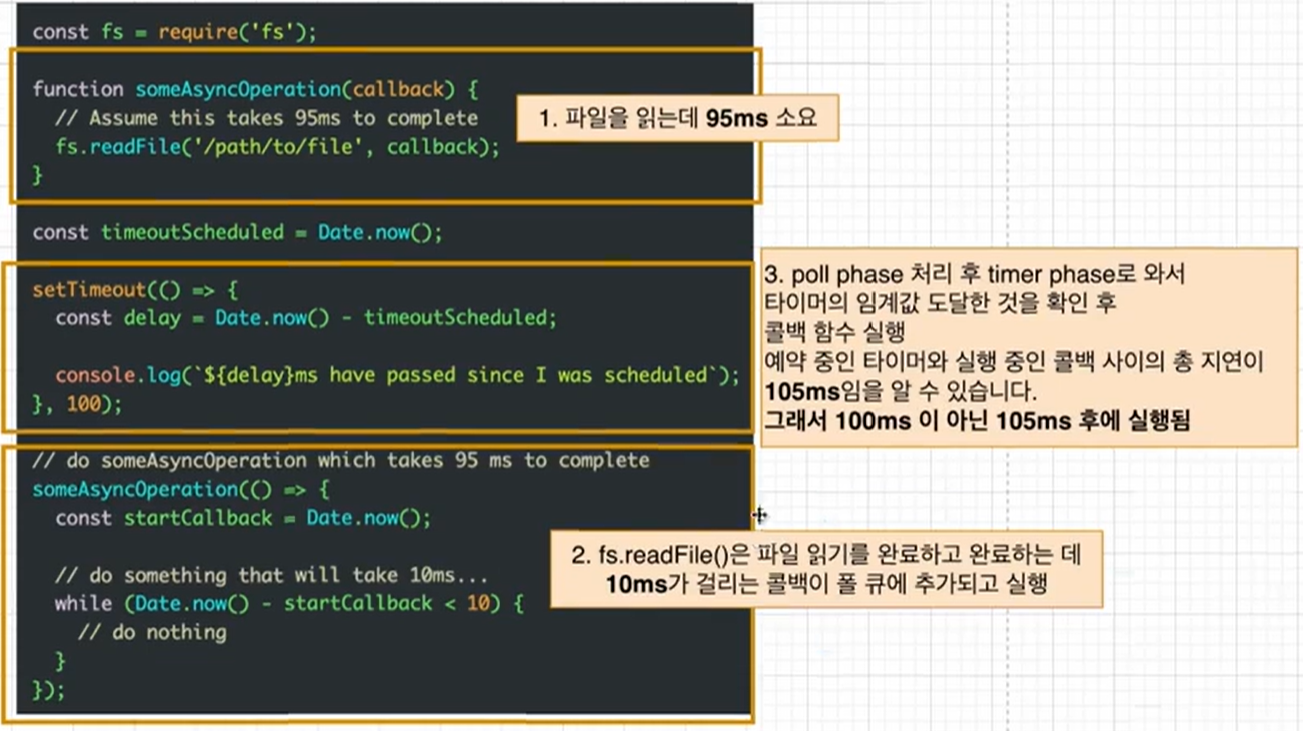
만약 setTimeout(A function, 1000)를 하면, min heap에서 찾아서 실행하기에 1초가 흐르기 전에 실행되는 것을 방지하고 딱 1초 후에 실행되는 것은 아니다. 결국 1초 이후에 실행이 된다.
그리고 이것(타이머 콜백의 실행)은 poll phase가 제어(control)한다.
Poll
Event Loop가 Poll Phase에 들어왔다면 다음과 같은 Queue에 들어 있는 일을 처리해 준다.
- 데이터 베이스 관련 작업으로 인한 겨로가가 왔을 때 실행되는 콜백
- HTTP 요청으로 인한 응답이 왔을 때 실행되는 콜백
- 파일을 비동기로 읽은 후에 실행되는 콜백
이 과정 또한 Queue가 비거나 시스템 실행 한도 초과에 다다를 때까지 게속된다.
Poll Phase는 또한 다른 Phase와 다르게 Poll Phase에 일이 다 소진되더라도 바로 다음 Phase에 이동하는 것은 아니다.
이벤트 루프 Poll단계에 들어가고 예약된 타이머가 없으면 다음 두 가지 중 하나가 발생한다.
-
폴 큐가 비어있지 않은 경우 이벤트 루프는 큐가 소진되거나 시스템의 실행 한도에 도달할 때 까지 동기적으로 콜백을 실행하는 콜백 큐를 반복한다
-
폴 큐가 비어 있으면 다음 두 가지 중 하나가 더 발생한다
- 스크립트가
setImmediate()에 의해 예약된 경우 이벤트 루프는 폴링 단계를 종료하고 예약된 스크립트를 실행하기 위해 Check 단계로 계속된다. - 스크립트가
setImmediate()에 의해 예약되지 않은 경우 이벤트 루프는 콜백이 Queue에 추가될 때까지 기다렸다가 즉시 실행한다.
- 스크립트가
폴 큐가 비어 있으면 이벤트 루프는 시간 임계값에 도달한 타이머를 확인한다. 하나 이상의 타이머가 준비되면 이벤트 루프는 타이머 단계로 돌아가 해당 타이머의 콜백을 실행한다.
Check
이 단계에서는 Poll단계가 완료된 직후 콜백을 실행할 수 있다. 폴 단계가 Idle상태가 되고 스크립트가 setImmediate()를 사용하여 Queue에 지정된 경우 이벤트 루프는 기다리지 않고 Check단계를 계속할 수 있다.
이벤트 루프의 동작 방식
-
콜 스택(Call Stack): 코드에서 함수가 호출되면 이벤트 루프는 해당 함수를 "콜 스택"이라는 데이터 구조에 넣는다.
-
콜백 큐(Callback Queue): 비동기 작업(예: setTimeout, AJAX 호출 등)이 완료되면, 정의된 콜백 함수는 "콜백 큐"라는 대기열에 넣어진다.
-
Event Loop: 이벤트 루프는 콜 스택이 비어있을 때, 콜백 큐에서 함수를 가져와 콜 스택으로 이동시킵니다. 이렇게 콜 스택에 쌓인 함수는 실행된다.
이 과정이 빠르게 반복되며, 이를 통해 자바스크립트는 단일 스레드로도 비동기 작업을 효율적으로 처리할 수 있다.
이벤트 루프의 중요성
-
비동기 프로그래밍: 이벤트 루프 덕분에 자바스크립트는 비동기 프로그래밍을 할 수 있다. 사용자 인터페이스, I/O 작업, 네트워크 통신 등을 블로킹 없이 처리할 수 있다.
-
성능: 이벤트 루프를 통해 여러 작업을 병렬로 처리할 수 있으므로 응용 프로그램이 더 빠르고 반응성이 좋아진다.
-
스케일링: 특히 Node.js 같은 환경에서 이벤트 루프는 서버가 많은 수의 동시 연결을 효율적으로 처리할 수 있도록 해준다.
이벤트 루프는 비동기 프로그래밍의 복잡성을 추상화하여 개발자가 더 직관적으로 비동기 코드를 작성할 수 있게 도와준다.
setlmmediate vs setTimeout vs process.NextTick
setTimeout(() => console.log('timeout'), 0);
setImmediate(() => console.log('immediate'));
process.nextTick(() => console.log('nextTick'));
console.log('current event loop');
// current event loop
// nextTick
// timeout
// immediatesetImmediate, setTimeout, 그리고 process.nextTick은 Node.js에서 비동기 작업을 스케줄링하는 메서드들이다. 이 메서드들이 어떻게 다른지 이해하기 위해서는 Node.js의 이벤트 루프와 작업 큐의 구조에 대한 기본적인 이해가 필요하다.
처리되는 단계
setTimeout(), setInterval()는 Timers 단계에서 처리
setImmediate()는 Check 단계에서 처리
process.nextTick()은 이벤트 루프 시작 시와 이벤트 루프의 각 단계 사이에서 처리
process.nextTick()
- process.nextTick() 함수는 현재 이벤트 루프의 모든 동기 작업이 완료된 직후에 실행될 콜백을 등록한다.
- process.nextTick()은 다른 모든 형태의 이벤트나 콜백 보다 먼저 실행된다.
- 이것은 별도의 큐를 가지고 있으며, 이벤트 루프가 다른 작업 큐 사이에서 전환할 때마다 해당 큐가 먼저 비워진다.
- 주어진 단계에서 process.nextTick()이 호출되면 이벤트 루프가 계속되기 전에 process.nextTick()에 전달된 모든 콜백이 해결된다. 이렇게 process.nextTick()이 재귀적으로 호출하면 이벤트 루프를 차단하게 된다.
process.nextTick(() => {
console.log('nextTick callback');
});
console.log('Synchronous log');
// Synchronous log
// nextTick callback예제1: process.nextTick() 재귀 호출 시 이벤트 루프 block
let count = 0
const cb = () => {
console.log(`Processing nextTick cb ${++count}`)
process.nextTick(cb) // 재귀적으로 호출
}
setImmediate(() => console.log('setImmediate is called'))
setTimeout(() => console.log('setTimeout executed'), 100)
process.nextTick(cb)
console.log('Start')
// Start
// Processing nextTick cb 1
// Processing nextTick cb 2
// Processing nextTick cb 3
// .....위 예처럼, process.nextTick()에 대한 재귀 호출은 지속적으로 처리되고 event loop가 차단됬다.
따라서 setImmediate() 및 setTimeout() 콜백은 실행되지 않는다.
예제2: setImmediate() 재구 호출 시?
let count = 0
const cb = () => {
console.log(`Processing setImmediate cb ${++count}`)
setImmediate(cb)
}
setImmediate(cb)
setTimeout(() => console.log('setTimeout executed'), 50)
console.log('Start')
// Start
// ...
// Processing setImmediate cb 1020
// Processing setImmediate cb 1021
// Processing setImmediate cb 1022
// setTimeour executed
// Processing setImmediate cb 1023
// Processing setImmediate cb 1024
// Processing setImmediate cb 1025
// Processing setImmediate cb 1026
// ...야기서 setImmediate()가 재귀적으로 호출되더라도 이벤트 루프를 차단하지 않으며 지정된 시간 초과 후에 setTimeout()콜백이 실행된다.
setImmediate & nextTick 이름
기본적으로 서로의 이름이 바뀌어야 한다.
왜냐하면 process.nextTick()이 setImmediate()보다 더 즉시 발생하기 때문이다. 그렇지만 현재는 이 둘의 이름을 바꿀 수는 없다. 왜냐하면 이 둘의 이름을 바꾼다면 이 둘을 사용하고 있는 대다수의 npm 패키지가 망가질 수도 있기 때문이고, 매일 새로운 모듈이 더해지고 있으므로 잠재적으로 더 많은 npm패키지가 깨질 수 있다. 그래서 이 둘의 이름은 바뀔 수가 없다.
모든 경우에 setImmediate()를 사용하기를 추천하는데, 사용하기 쉽고 browser등의 다양한 환경에서 호환이 더 잘되기 때문이다.
setTimeout()
- setTimeout()은 지정된 시간이 지난 후에 콜백을 실행하도록 스케줄링한다.
- 시간 지연은 최소 지연 시간을 보장하지만 정확한 시간을 보장하지는 않는다.
setTimeout(() => {
console.log('setTimeout callback');
}, 0);
console.log('Synchronous log');
// Synchronous log
// setTimeout callbacksetImmediate()
- setImmediate()는 현재 이벤트 루프의 단계가 완료되면 콜백을 실행하도록 스케줄링한다.
- setImmediate()는 setTimeout(fn, 0)와 비슷해 보이지만, 둘 사이에는 차이가 있다.
setImmediate(() => {
console.log('setImmediate callback');
});
console.log('Synchronous log');
// Synchronous log
// setImmediate callback차이점
-
process.nextTick()은 이벤트 루프의 현재 단계가 끝나면 즉시 실행되므로, 재귀적으로 호출하면 이벤트 루프는 다른 큐의 이벤트를 처리할 기회 없이 계속 블로킹될 수 있다.
-
setTimeout()과 setImmediate()은 비슷해 보이지만, 다른 타이밍으로 실행될 수 있다. 일반적으로 setImmediate()는 setTimeout(fn, 0)보다 먼저 실행된다.
-
setImmediate()는 I/O 작업의 콜백이나 다른 타이머 이후에 실행되기 좋다.
이러한 함수들은 서로 다른 우선순위와 시점에서 실행되므로, 어떤 작업을 어떤 시점에 수행할 것인지 결정할 때 이러한 차이를 고려해야 한다.
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
});
// 두 타이머가 실행되는 순서는 프로세스의 성능에 의해 제한되기 때문에 비결정적이다.
// 누가 더 빨리 출력될지는 랜덤.I/O사이클 안에서 둘을 같이 호출
const fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}. 0);
setImmediate(() => {
console.log('immediate');
});
});
// immediate
// timeoutI/O주기 내에서 두 타이머를 호출하면 setImmediate콜백이 항상 먼저 실행된다.
작업 순서(왜 항상 setImmediate이 먼저 실행되는 것 보장?)
- fs.readFile을 만나면 이벤트 루프는 libuv에게 해당 작업을 위임한다.
- 파일 읽기는 libuv에 있는 스레드에서 해당 작업을 처리한다.
- 작업이 완료되면 이벤트 루프는 Pending i/o callback phase의 pending_queue에 작업의 콜백을 등록한다.
- 이벤트 루프가 Pending i/o callback phase를 지날 때 해당 콜백을 실행한다.
- setTimeout이 Timer phase의 큐에 등록된다. 해당 콜백은 다음 Timer phase때 실핼될 것이다.
- setImmediate의 콜백이 Check phase의 check_queue에 등록된다.
- Poll phase에서는 할 일 없어서 넘어간다. 하지만 Check phase의 큐에 작업이 있으므로 바로 Check Phase로 이동한다.
- setImmediate 콘솔 출력하고 Timer phase에는 타이머가 등록되어 있으므로 다시 이벤트 루프가 시작된다.
- Timer phase에서 타이머를 검사, 딜레이가 0이므로 setTimeout의 콜백을 바로 실행한다.
이런 과정을 거쳐서 setImmediate의 콜백이 반드시 setTimeout보다 먼저 실행되는 것을 보장할 수 있는 것이다.
setTimeout()보다 setImmediate()를 사용하는 주요 이점은 존재하는 타이머 수와 관계없이 I/O주기 내에서 예약된 경우 setImmediate()가 항상 타이머보다 먼저 실행된다는 것이다.
Node.js Event Emitter
브라우저에서 JavaScript로 작업한 경우 마우스 클릭, 키보드 버튼 누르기, 마우스 움직임에 대한 반응 등과 같은 이벤트를 통해 사용자 상호 작용이 얼마나 처리되는지 알 수 있다
이러한 것처럼 백엔드 측에서 Node.js도 event-driven시스템을 이용해서 작동 된다.
Node.js의 EventEmitter 클래스는 이벤트 기반의 아키텍처를 사용하기 위해 제공된다. EventEmitter를 사용하면 객체가 이벤트를 발행(publish)하거나 이벤트를 구독(subscribe)하는 것이 가능해진다. 이것은 Node.js에서 매우 중요한 패턴이며, 많은 내장 모듈에서도 사용된다. 예를 들어, 파일을 읽고 쓰는 fs 모듈, HTTP 서버 생성을 위한 http 모듈, 스트림 등에서 이벤트가 사용된다.
Observer Design Pattern
event-driven시스템을 이용하는 것을 Observer Design Pattern이라고도 부른다.
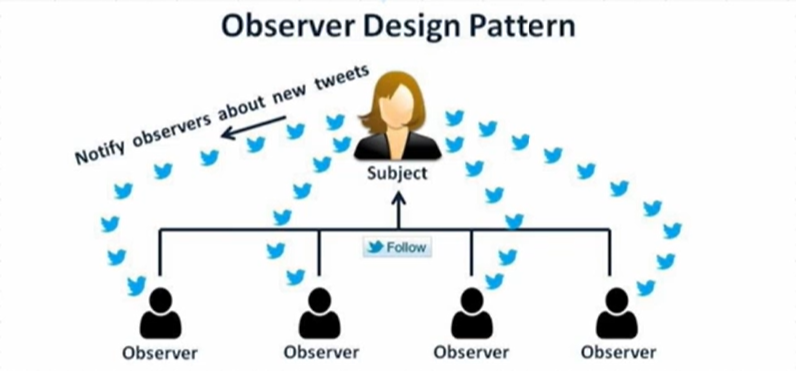
이 패턴에는 특정 Subject를 관찰하는 많은 Observer가 있다.
관찰자는 기본적으로 관심이 있고 해당 주제 내부에 변경 사항이 있을 때 알림을 받기를 원한다.
그래서 그들은 그 주제에 스스로 등록(Register)한다.
주제에 대한 관심을 잃으면 단순히 해당 주제에서 등록을 취소한다.
이 모델은 게시자-구독자(Publiser-Subscriber)모델이라고도 한다.
유튜브의 구독 시스템과 같이, 특정 유튜버의 최신 업데이트를 모두 받고싶으면 구독을 누르고, 흥미를 잃으면 구독을 취소한다.
여기서 우리는 구독자를 관찰자(Observer)로, 유튜버를 주체(Subject)로 생각할 수 있다.
EventEmitter의 주요 메서드
emitter.emit(event, [...args]): 이벤트를 발생시킨다.emitter.on(event, listener): 이벤트가 발생했을 때 호출되는 리스너를 등록한다.emitter.once(event, listener): 이벤트가 발생했을 때 한 번만 호출되는 리스너를 등록한다.emitter.removeListener(event, listener): 특정 이벤트의 리스너를 제거한다.emitter.removeAllListeners([event]): 모든 이벤트 혹은 특정 이벤트의 모든 리스너를 제거한다.
간단한 예제
const EventEmitter = require('events');
// EventEmitter 인스턴스 생성
const myEmitter = new EventEmitter();
// 이벤트 리스너 등록
myEmitter.on('hello', name => {
console.log(`Hello, ${name}!`);
});
// on은 이벤트가 트리거 될 때 실행될 콜백 함수를 추가하는 데 사용된다.
// 이벤트 발생
myEmitter.emit('hello', 'John'); // Output: "Hello, John!"코드 분석
이 코드는 Node.js의 EventEmitter 클래스를 사용하여 간단한 이벤트 핸들링 예제를 보여준다.
- 모듈 임포트: EventEmitter 클래스를 events 모듈에서 불러온다.
const EventEmitter = require('events');- EventEmitter 인스턴스 생성: EventEmitter 클래스의 인스턴스를 생성한다. 이 인스턴스는 이벤트를 발생시키고 리스너를 등록할 수 있는 객체다.
const myEmitter = new EventEmitter();- 이벤트 리스너 등록: on 메서드를 사용하여 'hello' 이벤트에 대한 리스너를 등록한다. 이 리스너는 인자로 name을 받아, Hello, ${name}! 형태의 문자열을 콘솔에 출력한다.
myEmitter.on('hello', name => {
console.log(`Hello, ${name}!`);
});- 이벤트 발생: emit 메서드를 사용하여 'hello' 이벤트를 발생시킨다. 이때 'John'이라는 문자열을 인자로 전달하면, 위에서 등록한 리스너가 실행되어 Hello, John!이 콘솔에 출력된다.
myEmitter.emit('hello', 'John'); // Output: "Hello, John!"코드가 실행되면, 이벤트 'hello'가 발생하면서 해당 이벤트에 등록된 리스너가 호출된다. 리스너는 'John'이라는 인자를 받아 Hello, John!을 콘솔에 출력한다.
다양한 이벤트와 파라미터 사용 예제
const EventEmitter = require('events');
class MyEmitter extends EventEmitter {}
const myEmitter = new MyEmitter();
myEmitter.on('event1', function(a, b) {
console.log(a, b, this);
});
myEmitter.emit('event1', 'arg1', 'arg2');이러한 방식으로 Node.js에서 이벤트 기반의 비동기 프로그래밍이 가능해진다. 이는 Node.js가 단일 스레드 환경에서 높은 성능을 낼 수 있게 도와준다.
