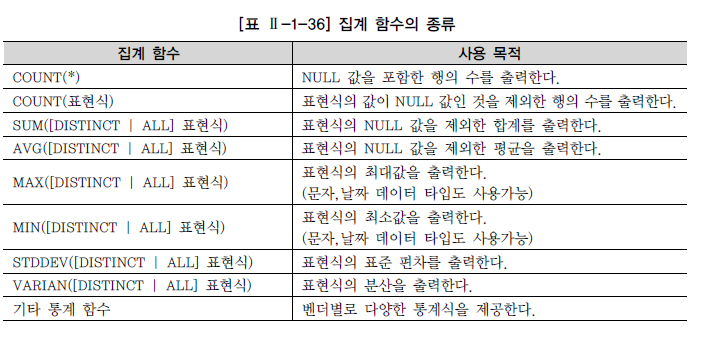
집계 함수 (Aggregate Function)
집계 함수는 여러 행의 데이터를 그룹화하여 하나의 결과값을 반환하는 함수이다. 이러한 함수는 데이터베이스에서 데이터를 요약하거나 통계적인 정보를 얻을 때 사용된다. 다음은 집계 함수의 주요 특성과 사용 예시이다.
주요 집계 함수는 다음과 같다.
- COUNT: 행의 개수를 세는 함수
COUNT(*): 테이블의 전체 행 수를 셀 때 사용COUNT(column): NULL이 아닌 특정 컬럼의 행 수를 셀 때 사용
- SUM: 숫자 컬럼 값의 합을 구하는 함수
- AVG: 숫자 컬럼 값의 평균을 구하는 함수
- MAX: 컬럼 값 중 최대값을 구하는 함수
- 숫자, 문자, 날짜 유형 모두 적용 가능
- MIN: 컬럼 값 중 최소값을 구하는 함수
- 숫자, 문자, 날짜 유형 모두 적용 가능
1️⃣ 사용 예시
SELECT COUNT(*) AS "전체 행수",
COUNT(HEIGHT) AS "키 건수",
MAX(HEIGHT) AS "최대키",
MIN(HEIGHT) AS "최소키",
ROUND(AVG(HEIGHT), 2) AS "평균키"
FROM PLAYER;-- 실행 결과
전체 행수 키 건수 최대키 최소키 평균키
-------- ------ ---- ---- -----
480 447 196 165 179.31위 예제에서 COUNT(HEIGHT)는 HEIGHT 컬럼의 NULL 값을 제외한 행 수를 세기 때문에 COUNT(*)의 값보다 작다.
GROUP BY 절
GROUP BY 절은 데이터를 특정 기준에 따라 그룹화하여 소그룹별로 집계 함수를 사용할 수 있게 한다. 이를 통해 각 그룹별 통계 정보를 얻을 수 있다.
1️⃣ 주요 특성
GROUP BY절은SELECT절,WHERE절 뒤에 위치한다.GROUP BY절을 사용하여 소그룹을 지정한 후,SELECT절에서 집계 함수를 사용할 수 있다.- 집계 함수는
NULL값을 제외한 행에 대해 수행된다. GROUP BY절에서는 컬럼의ALIAS명을 사용할 수 없다.WHERE절은 데이터를 그룹으로 나누기 전에 행을 필터링한다.HAVING절은 그룹화된 데이터에 조건을 적용할 때 사용된다.
2️⃣ 예시
SELECT POSITION AS "포지션",
COUNT(*) AS "인원수",
COUNT(HEIGHT) AS "키대상",
MAX(HEIGHT) AS "최대키",
MIN(HEIGHT) AS "최소키",
ROUND(AVG(HEIGHT), 2) AS "평균키"
FROM PLAYER
GROUP BY POSITION;-- 실행 결과
포지션 인원수 키대상 최대키 최소키 평균키
----- ------ ------ ---- ---- -----
GK 43 43 196 174 186.26
DF 172 142 190 170 180.21
FW 100 100 194 168 179.91
MF 162 162 189 165 176.31위 실행 결과에서 각 포지션별로 인원수, 키대상 인원수, 최대키, 최소키, 평균키가 제대로 출력된 것을 확인할 수 있다. 이처럼 GROUP BY 절을 통해 소그룹별 통계 정보를 얻을 수 있다.
HAVING 절
HAVING 절은 그룹화된 데이터에 대해 조건을 적용할 때 사용된다. WHERE 절과 유사하지만, WHERE 절은 그룹화되기 전에 행을 필터링하는 반면, HAVING 절은 그룹화된 결과에 조건을 적용한다. 이를 통해 그룹별로 특정 조건을 만족하는 데이터만 선택할 수 있다.
1️⃣ 주요 특성
- WHERE 절은 개별 행에 대해 조건을 적용하지만, HAVING 절은 그룹에 대해 조건을 적용한다.
- HAVING 절은 집계 함수와 함께 사용되어 그룹별로 필터링할 수 있다.
- HAVING 절은 GROUP BY 절 뒤에 위치한다.
2️⃣ 예제 및 실행 결과
K-리그 선수들의 포지션별 평균키를 구하는데, 평균키가 180 센티미터 이상인 정보만 표시하는 SQL문은 다음과 같다.
SELECT POSITION 포지션, ROUND(AVG(HEIGHT),2) 평균키
FROM PLAYER
GROUP BY POSITION
HAVING AVG(HEIGHT) >= 180;-- 실행 결과
포지션 평균키
------ ------
GK 186.26
DF 180.21전체 포지션 중에서 평균 키가 180cm 이상인 포지션만 출력된다.
3️⃣ HAVING 절의 순서 변경
GROUP BY 절과 HAVING 절의 순서를 바꾸어도 실행 결과는 동일하다. 그러나 논리적으로 먼저 GROUP BY를 통해 그룹핑을 하고, 그 후에 HAVING 절로 필터링하는 것이 맞기 때문에 순서를 지키는 것이 좋다.
SELECT POSITION 포지션, ROUND(AVG(HEIGHT),2) 평균키
FROM PLAYER
HAVING AVG(HEIGHT) >= 180
GROUP BY POSITION;포지션 평균키
------ ------
GK 186.26
DF 180.214️⃣ WHERE 절과 HAVING 절 비교
삼성블루윙즈(K02)와 FC서울(K09)의 인원수를 구하는 SQL 문은 다음과 같다.
-- WHERE 사용
SELECT TEAM_ID 팀ID, COUNT(*) 인원수
FROM PLAYER
WHERE TEAM_ID IN ('K09', 'K02')
GROUP BY TEAM_ID;-- HAVING 사용
SELECT TEAM_ID 팀ID, COUNT(*) 인원수
FROM PLAYER
GROUP BY TEAM_ID
HAVING TEAM_ID IN ('K09', 'K02');-- 실행 결과
팀ID 인원수
---- -----
K02 49
K09 49위 두 쿼리는 같은 결과를 출력하지만, WHERE 절을 사용하는 것이 더 효율적이다. 이는 WHERE 절이 GROUP BY 연산 전에 필터링을 수행하여 필요한 데이터만 그룹화하기 때문이다.
1. WHERE문 실행 과정
SELECT TEAM_ID 팀ID, COUNT(*) 인원수
FROM PLAYER
WHERE TEAM_ID IN ('K09', 'K02')
GROUP BY TEAM_ID;쿼리문의 초기 상태는 위와 같다.
먼저, FROM 절이 실행되어 PLAYER 테이블을 선택한다.
그 다음, WHERE 절이 실행되어 PLAYER 테이블에서 TEAM_ID가 'K09' 또는 'K02'인 행을 필터링한다. 이 절차에서 조건에 맞는 행만 남는다.
SELECT *
FROM PLAYER
WHERE TEAM_ID IN ('K09', 'K02');-- 예시로, 필터링 후엔 아래와 같다고 가정하자.
| PLAYER_ID | TEAM_ID | POSITION | SALARY |
|-----------|---------|----------|--------|
| 1 | K09 | FW | 1000 |
| 2 | K02 | MF | 1200 |
| 3 | K09 | DF | 1100 |
| 4 | K02 | GK | 900 |
| 5 | K02 | FW | 1300 |
| 6 | K09 | MF | 1400 |그 후엔, GROUP BY 절이 실행되어 필터링된 데이터에서 TEAM_ID를 기준으로 그룹화한다.
SELECT TEAM_ID, COUNT(*)
FROM (
SELECT *
FROM PLAYER
WHERE TEAM_ID IN ('K09', 'K02')
)
GROUP BY TEAM_ID;그룹화 결과는 아래와 같다.
| PLAYER_ID | TEAM_ID | POSITION | SALARY |
|-----------|---------|----------|--------|
| 1 | K09 | FW | 1000 |
| 3 | K09 | DF | 1100 |
| 6 | K09 | MF | 1400 || PLAYER_ID | TEAM_ID | POSITION | SALARY |
|-----------|---------|----------|--------|
| 2 | K02 | MF | 1200 |
| 4 | K02 | GK | 900 |
| 5 | K02 | FW | 1300 |그 다음엔, SELECT 절 및 집계 함수를 하여, 각 그룹에서 COUNT(*)를 사용하여 행의 개수를 센다.
SELECT TEAM_ID, COUNT(*)
FROM (
SELECT *
FROM PLAYER
WHERE TEAM_ID IN ('K09', 'K02')
)
GROUP BY TEAM_ID;| TEAM_ID | 인원수 |
|---------|--------|
| K09 | 3 |
| K02 | 3 |2. HAVING절의 실행 과정
SELECT TEAM_ID 팀ID, COUNT(*) 인원수
FROM PLAYER
GROUP BY TEAM_ID
HAVING TEAM_ID IN ('K09', 'K02');- FROM 절: PLAYER 테이블을 선택한다.
- GROUP BY 절: 테이블의 데이터를 TEAM_ID를 기준으로 그룹화한다. 이 단계에서는 모든 행을 TEAM_ID별로 그룹화한다.
SELECT TEAM_ID, COUNT(*)
FROM PLAYER
GROUP BY TEAM_ID;그룹화된 데이터는 다음과 같을 수 있다:
- TEAM_ID = 'K09'인 그룹
- TEAM_ID = 'K02'인 그룹
- TEAM_ID = 'K14'인 그룹
- TEAM_ID = 'K06'인 그룹
- 기타 등등...
- 집계 함수 적용: 각 그룹에서
COUNT(*)를 사용하여 행의 개수를 센다.
SELECT TEAM_ID, COUNT(*) AS 인원수
FROM PLAYER
GROUP BY TEAM_ID;-- 그룹화 및 집계 후 데이터가 다음과 같다고 가정하자.
| TEAM_ID | 인원수 |
|---------|--------|
| K09 | 10 |
| K02 | 15 |
| K14 | 7 |
| K06 | 12 |- HAVING 절: 그룹화된 데이터에서 HAVING 조건을 적용한다. 이 조건은 그룹별로 집계된 결과에 대해 적용되며, TEAM_ID가 'K09' 또는 'K02'인 그룹만 필터링한다.
SELECT TEAM_ID, COUNT(*)
FROM PLAYER
GROUP BY TEAM_ID
HAVING TEAM_ID IN ('K09', 'K02');-- 필터링된 결과
| TEAM_ID | 인원수 |
|---------|--------|
| K09 | 10 |
| K02 | 15 |- SELECT 절: HAVING 절을 통해 필터링된 결과에서
TEAM_ID와COUNT(*)를 선택합니다.
최종적으로, HAVING 절의 조건을 만족하는 그룹만 선택되어 결과가 반환된다.
SELECT 절에 없는 집계 함수 사용
포지션별 평균키를 출력하는데, 최대키가 190cm 이상인 포지션의 정보만 출력하는 SQL문은 아래와 같다.
SELECT POSITION 포지션, ROUND(AVG(HEIGHT),2) 평균키
FROM PLAYER
GROUP BY POSITION
HAVING MAX(HEIGHT) >= 190;-- 실행 결과
포지션 평균키
------ ------
GK 186.26
DF 180.21
FW 179.91포지션별로 최대키가 190cm 이상인 경우만 출력된다. 여기서 HAVING 절은 SELECT 절에 포함되지 않은 MAX(HEIGHT)를 조건으로 사용하고 있다.
- WHERE 절은 개별 행을 필터링한다.
- HAVING 절은 그룹화된 데이터에 조건을 적용한다.
- GROUP BY 절로 그룹핑한 후, HAVING 절로 필터링 조건을 지정할 수 있다.
- 효율성을 위해 가능한 WHERE 절을 사용하여 필터링을 먼저 수행하는 것이 좋다.
CASE 표현을 활용한 월별 데이터 집계
CASE 표현과 GROUP BY 절을 사용하여 월별 데이터를 집계하는 방법에 대해 설명하겠다. 이 기법은 반복되는 칼럼을 여러 개의 레코드로 변환하여 집계 보고서를 작성하는 데 유용하다. 여기서는 부서별로 월별 입사자의 평균 급여를 구하는 예제를 통해 설명한다.
예제
- 개별 데이터 확인
- 먼저, 개별 입사 정보를 확인하여 월별 데이터를 추출한다. 이는 월별 정보가 필요할 때 사용하는 단계이다.
- Oracle, SQL Server에서 월별 데이터 추출하는 SQL문은 다음과 같다.
-- Oracle
SELECT ENAME, DEPTNO, EXTRACT(MONTH FROM HIREDATE) AS 입사월, SAL
FROM EMP;
-- SQL Server
SELECT ENAME, DEPTNO, DATEPART(MONTH, HIREDATE) AS 입사월, SAL
FROM EMP;
-- SQL Server (또 다른 방법)
SELECT ENAME, DEPTNO, MONTH(HIREDATE) AS 입사월, SAL
FROM EMP;-- 결과
-- MONTH(HIREDATE) AS 입사월은 HIREDATE에서 'MONTH'를 추출하고, 입사월로 열의 이름을 바꾼다.
ENAME DEPTNO 입사월 SAL
------ ------- ------ -----
SMITH 20 12 800
ALLEN 30 2 1600
WARD 30 2 1250
JONES 20 4 2975
MARTIN 30 9 1250
BLAKE 30 5 2850
CLARK 10 6 2450
SCOTT 20 7 3000
KING 10 11 5000
TURNER 30 9 1500
ADAMS 20 7 1100
JAMES 30 12 950
FORD 20 12 3000
MILLER 10 1 1300- 월별 데이터 구분
- 추출된 월별 데이터를 CASE 표현을 사용하여 12개의 월별 칼럼으로 구분한다. 이는 최종 보고서에서 필요로 하는 형식이다.
월별 데이터를 구분하는 SQL문은 아래와 같다.
SELECT ENAME, DEPTNO,
CASE WHEN MONTH = 1 THEN SAL END AS M01,
CASE WHEN MONTH = 2 THEN SAL END AS M02,
CASE WHEN MONTH = 3 THEN SAL END AS M03,
CASE WHEN MONTH = 4 THEN SAL END AS M04,
CASE WHEN MONTH = 5 THEN SAL END AS M05,
CASE WHEN MONTH = 6 THEN SAL END AS M06,
CASE WHEN MONTH = 7 THEN SAL END AS M07,
CASE WHEN MONTH = 8 THEN SAL END AS M08,
CASE WHEN MONTH = 9 THEN SAL END AS M09,
CASE WHEN MONTH = 10 THEN SAL END AS M10,
CASE WHEN MONTH = 11 THEN SAL END AS M11,
CASE WHEN MONTH = 12 THEN SAL END AS M12
FROM (
SELECT ENAME, DEPTNO, EXTRACT(MONTH FROM HIREDATE) AS MONTH, SAL
FROM EMP
);-- 실행결과
ENAME DEPTNO M01 M02 M03 M04 M05 M06 M07 M08 M09 M10 M11 M12
------ ------ ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
SMITH 20 800
ALLEN 30 1600
WARD 30 1250
JONES 20 2975
MARTIN 30 1250
BLAKE 30 2850
CLARK 10 2450
SCOTT 20 3000
KING 10 5000
TURNER 30 1500
ADAMS 20 1100
JAMES 30 950
FORD 20 3000
MILLER 10 1300- 부서별 데이터 집계
- 부서별로 월별 입사자의 평균 급여를 구하기 위해
GROUP BY절과AVG집계 함수를 사용한다
- 부서별로 월별 입사자의 평균 급여를 구하기 위해
SELECT DEPTNO,
AVG(CASE WHEN MONTH = 1 THEN SAL END) AS M01,
AVG(CASE WHEN MONTH = 2 THEN SAL END) AS M02,
AVG(CASE WHEN MONTH = 3 THEN SAL END) AS M03,
AVG(CASE WHEN MONTH = 4 THEN SAL END) AS M04,
AVG(CASE WHEN MONTH = 5 THEN SAL END) AS M05,
AVG(CASE WHEN MONTH = 6 THEN SAL END) AS M06,
AVG(CASE WHEN MONTH = 7 THEN SAL END) AS M07,
AVG(CASE WHEN MONTH = 8 THEN SAL END) AS M08,
AVG(CASE WHEN MONTH = 9 THEN SAL END) AS M09,
AVG(CASE WHEN MONTH = 10 THEN SAL END) AS M10,
AVG(CASE WHEN MONTH = 11 THEN SAL END) AS M11,
AVG(CASE WHEN MONTH = 12 THEN SAL END) AS M12
FROM (
SELECT ENAME, DEPTNO, EXTRACT(MONTH FROM HIREDATE) AS MONTH, SAL
FROM EMP
)
GROUP BY DEPTNO;DEPTNO M01 M02 M03 M04 M05 M06 M07 M08 M09 M10 M11 M12
------ ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
30 1425 2850 1375 950
20 2975 2050 1900
10 1300 2450 5000SAL END AS?
CASE문의 기본 문법은 아래와 같다.
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE resultN
END AS alias_nameCASE: 표현식의 시작을 나타낸다.WHEN condition THEN result: 조건(condition)이 참일 때 반환할 값을 지정한다.ELSE result: 위의 조건이 모두 거짓일 때 반환할 값을 지정한다. ELSE 부분은 선택사항이다.END: CASE 표현식의 끝을 나타낸다.AS alias_name: CASE 표현식의 결과에 대한 별칭을 지정한다.
아래 코드를 다시 보면
CASE WHEN MONTH = 1 THEN SAL END AS M01CASE: 표현식 시작.WHEN MONTH = 1: MONTH 값이 1일 때.THEN SAL: SAL 값을 반환.END: CASE 표현식 종료.AS M01: 결과 값을 M01이라는 별칭으로 지정.
예제 DECODE
Oracle에서는 DECODE 함수를 사용하여 비슷한 결과를 얻을 수 있다.
SELECT DEPTNO,
AVG(DECODE(MONTH, 1, SAL)) AS M01,
AVG(DECODE(MONTH, 2, SAL)) AS M02,
AVG(DECODE(MONTH, 3, SAL)) AS M03,
AVG(DECODE(MONTH, 4, SAL)) AS M04,
AVG(DECODE(MONTH, 5, SAL)) AS M05,
AVG(DECODE(MONTH, 6, SAL)) AS M06,
AVG(DECODE(MONTH, 7, SAL)) AS M07,
AVG(DECODE(MONTH, 8, SAL)) AS M08,
AVG(DECODE(MONTH, 9, SAL)) AS M09,
AVG(DECODE(MONTH, 10, SAL)) AS M10,
AVG(DECODE(MONTH, 11, SAL)) AS M11,
AVG(DECODE(MONTH, 12, SAL)) AS M12
FROM (
SELECT ENAME, DEPTNO, EXTRACT(MONTH FROM HIREDATE) AS MONTH, SAL
FROM EMP
)
GROUP BY DEPTNO;DECODE의 문법은 아래와 같다.
DECODE(expression, search1, result1, [search2, result2, ...,] [default])해당 문법의 예시 쿼리문은 아래와 같은데,
SELECT ENAME,
DECODE(DEPTNO,
10, 'ACCOUNTING',
20, 'RESEARCH',
30, 'SALES',
40, 'OPERATIONS',
'UNKNOWN') AS DEPT_NAME
FROM EMP;- DECODE 함수는 DEPTNO 값을 평가한다.
- DEPTNO 값이 10이면 'ACCOUNTING', 20이면 'RESEARCH', 30이면 'SALES', 40이면 'OPERATIONS'를 반환한다.
- 어떤 값과도 일치하지 않으면 'UNKNOWN'을 반환한다.
CASE 문의 종류
단순 CASE
-- 단순 CASE문
-- = 생략 가능
CASE 식1
WHEN 식2 THEN 식3
WHEN 식4 THEN 식5
ELSE 식6
END간단한 CASE 표현식은 하나의 표현식을 여러 값과 비교하여 해당하는 결과를 반환한다. 이 경우, WHEN 절에서 비교 연산자를 사용하지 않는다.
SELECT ENAME,
CASE DEPTNO
WHEN 10 THEN 'ACCOUNTING'
WHEN 20 THEN 'RESEARCH'
WHEN 30 THEN 'SALES'
ELSE 'UNKNOWN'
END AS DEPARTMENT_NAME
FROM EMP;SELECT LOC,
CASE LOC
WHEN 'NEW YORK' THEN 'EAST'
WHEN 'LOS ANGELES' THEN 'WEST'
ELSE 'ETC'
END AS AREA
FROM DEPT;이 쿼리에서는 LOC 열의 값을 기준으로 WHEN 절에서 직접 값을 비교한다. LOC 값이 'NEW YORK' 또는 'LOS ANGELES'와 일치할 경우 각각 'EAST'와 'WEST'를 반환하고, 그렇지 않으면 'ETC'를 반환한다.
검색 CASE
-- 검색 CASE 문
-- = 생략 불가
CASE
WHEN 조건식1 THEN 식1
[WHEN 조건식2 THEN 식2 ...]
[ELSE 식3]
END검색 CASE 표현식은 여러 조건을 평가하여 해당하는 결과를 반환한다. 이 경우, 각 WHEN 절에서 조건을 명시적으로 평가해야 하므로 비교 연산자를 사용한다.
SELECT DEPTNO,
AVG(CASE WHEN MONTH = 1 THEN SAL END) AS M01,
AVG(CASE WHEN MONTH = 2 THEN SAL END) AS M02,
AVG(CASE WHEN MONTH = 3 THEN SAL END) AS M03,
AVG(CASE WHEN MONTH = 4 THEN SAL END) AS M04,
AVG(CASE WHEN MONTH = 5 THEN SAL END) AS M05,
AVG(CASE WHEN MONTH = 6 THEN SAL END) AS M06,
AVG(CASE WHEN MONTH = 7 THEN SAL END) AS M07,
AVG(CASE WHEN MONTH = 8 THEN SAL END) AS M08,
AVG(CASE WHEN MONTH = 9 THEN SAL END) AS M09,
AVG(CASE WHEN MONTH = 10 THEN SAL END) AS M10,
AVG(CASE WHEN MONTH = 11 THEN SAL END) AS M11,
AVG(CASE WHEN MONTH = 12 THEN SAL END) AS M12
FROM (
SELECT ENAME, DEPTNO, EXTRACT(MONTH FROM HIREDATE) AS MONTH, SAL
FROM EMP
)
GROUP BY DEPTNO;이 쿼리에서는 MONTH 열의 값이 특정 값인지 확인하기 위해 조건을 평가한다. 따라서 각 WHEN 절에서 = 연산자를 사용하여 조건을 명시적으로 평가해야 한다.
집계 함수와 NULL
집계 함수와 NULL 처리에 대해 설명하겠다. 특히, 집계 함수에서 NULL을 어떻게 처리하는지, 그리고 이를 적절하게 다루는 방법을 알아보자.
- NULL 처리와 집계 함수
- 집계 함수는 NULL 값을 포함한 데이터에서 NULL을 자동으로 제외하고 연산을 수행한다. 예를 들어, AVG 함수는 전체 데이터 중에서 NULL 값을 제외한 나머지 값들의 평균을 계산한다. 그러나, 전체 데이터가 NULL인 경우 집계 함수의 결과는 NULL이 된다.
- NVL 및 ISNULL 함수 사용
- 리포트에서 빈 칸을 NULL 대신 0으로 표현하고자 할 때
NVL(Oracle)또는ISNULL(SQL Server)함수를 사용할 수 있다. 하지만 다중 행 함수 안에서 이 함수를 사용하는 것은 불필요한 부하를 발생시킬 수 있다. - 예를 들어, SUM(NVL(SAL, 0)) 대신 NVL(SUM(SAL), 0)을 사용하는 것이 더 효율적이다. SUM(SAL)에서 SAL이 NULL인 경우는 자동으로 제외되기 때문에 불필요한 연산을 줄일 수 있다.
- 리포트에서 빈 칸을 NULL 대신 0으로 표현하고자 할 때
- CASE 표현 사용 시 NULL 처리
- CASE 표현을 사용할 때 ELSE 절을 생략하면 기본 값은 NULL이다. 이를 이용하여 불필요한 연산을 피할 수 있다.
- 예를 들어,
SUM(CASE MONTH WHEN 1 THEN SAL ELSE 0 END)처럼 ELSE 절을 0으로 지정하면 불필요하게 0이 SUM 연산에 포함될 수 있다. 따라서 ELSE 절을 생략하거나 NULL을 기본 값으로 두는 것이 더 효율적이다.
예제
다음은 팀별 포지션별 인원수와 팀별 전체 인원수를 구하는 SQL 문장이다. 데이터가 없는 경우 0으로 표시한다.
-- Oracle - SIMPLE_CASE_EXPRESSION 조건
SELECT TEAM_ID,
NVL(SUM(CASE POSITION WHEN 'FW' THEN 1 ELSE 0 END), 0) AS FW,
NVL(SUM(CASE POSITION WHEN 'MF' THEN 1 ELSE 0 END), 0) AS MF,
NVL(SUM(CASE POSITION WHEN 'DF' THEN 1 ELSE 0 END), 0) AS DF,
NVL(SUM(CASE POSITION WHEN 'GK' THEN 1 ELSE 0 END), 0) AS GK,
COUNT(*) AS SUM
FROM PLAYER
GROUP BY TEAM_ID;-- Oracle - SIMPLE_CASE_EXPRESSION 조건 (ELSE NULL 생략)
SELECT TEAM_ID,
NVL(SUM(CASE POSITION WHEN 'FW' THEN 1 END), 0) AS FW,
NVL(SUM(CASE POSITION WHEN 'MF' THEN 1 END), 0) AS MF,
NVL(SUM(CASE POSITION WHEN 'DF' THEN 1 END), 0) AS DF,
NVL(SUM(CASE POSITION WHEN 'GK' THEN 1 END), 0) AS GK,
COUNT(*) AS SUM
FROM PLAYER
GROUP BY TEAM_ID;-- Oracle - SEARCHED_CASE_EXPRESSION 조건
SELECT TEAM_ID,
NVL(SUM(CASE WHEN POSITION = 'FW' THEN 1 END), 0) AS FW,
NVL(SUM(CASE WHEN POSITION = 'MF' THEN 1 END), 0) AS MF,
NVL(SUM(CASE WHEN POSITION = 'DF' THEN 1 END), 0) AS DF,
NVL(SUM(CASE WHEN POSITION = 'GK' THEN 1 END), 0) AS GK,
COUNT(*) AS SUM
FROM PLAYER
GROUP BY TEAM_ID;-- SQL Server - SEARCHED_CASE_EXPRESSION 조건
SELECT TEAM_ID,
ISNULL(SUM(CASE WHEN POSITION = 'FW' THEN 1 END), 0) AS FW,
ISNULL(SUM(CASE WHEN POSITION = 'MF' THEN 1 END), 0) AS MF,
ISNULL(SUM(CASE WHEN POSITION = 'DF' THEN 1 END), 0) AS DF,
ISNULL(SUM(CASE WHEN POSITION = 'GK' THEN 1 END), 0) AS GK,
COUNT(*) AS SUM
FROM PLAYER
GROUP BY TEAM_ID;-- 실행 결과
TEAM_ID FW MF DF GK SUM
------- -- -- -- -- ---
K14 0 1 1 0 2
K06 11 11 20 4 46
K13 1 0 1 1 3
K15 1 1 1 0 3
K02 10 18 17 4 49
K12 1 0 1 0 2
K04 13 11 18 4 46
K03 6 15 23 5 49
K07 9 22 16 4 51
K05 10 19 17 5 51
K08 8 15 15 4 45
K11 1 1 1 0 3
K01 12 15 13 5 45
K10 5 15 13 3 36
K09 12 18 15 4 49예제2
GROUP BY 절 없이 전체 선수들의 포지션별 평균 키와 전체 평균 키를 출력할 수 있다.
SELECT ROUND(AVG(CASE WHEN POSITION = 'MF' THEN HEIGHT END), 2) AS 미드필더,
ROUND(AVG(CASE WHEN POSITION = 'FW' THEN HEIGHT END), 2) AS 포워드,
ROUND(AVG(CASE WHEN POSITION = 'DF' THEN HEIGHT END), 2) AS 디펜더,
ROUND(AVG(CASE WHEN POSITION = 'GK' THEN HEIGHT END), 2) AS 골키퍼,
ROUND(AVG(HEIGHT), 2) AS 전체평균키
FROM PLAYER;미드필더 포워드 디펜더 골키퍼 전체평균키
------- ------ ------ ------ ---------
176.31 179.91 180.21 186.26 179.31
- 집계 함수는 NULL 값을 제외하고 연산한다.
- 다중 행 함수 내부에서
NVL/ISNULL함수를 사용하지 않는 것이 좋다.- CASE 표현에서 ELSE 절을 생략하면 기본 값은 NULL이 됩니다.
NVL(SUM(SAL), 0)과 같은 방식으로 전체 SUM의 결과가 NULL인 경우에만NVL/ISNULL함수를 사용하는 것이 좋다.
