데이터 그룹화 하기
"고객 등급 별 매출 통계 뽑아주세요."
"상품 카테고리별 실적 통계 뽑아주세요."
위와 같은 명령을 받았을때 우리는 데이터를 그룹화해서 통계를 내야 한다.
GROUP BY
컬럼에서 동일한 값을 가지는 로우를 그룹화하는 키워드
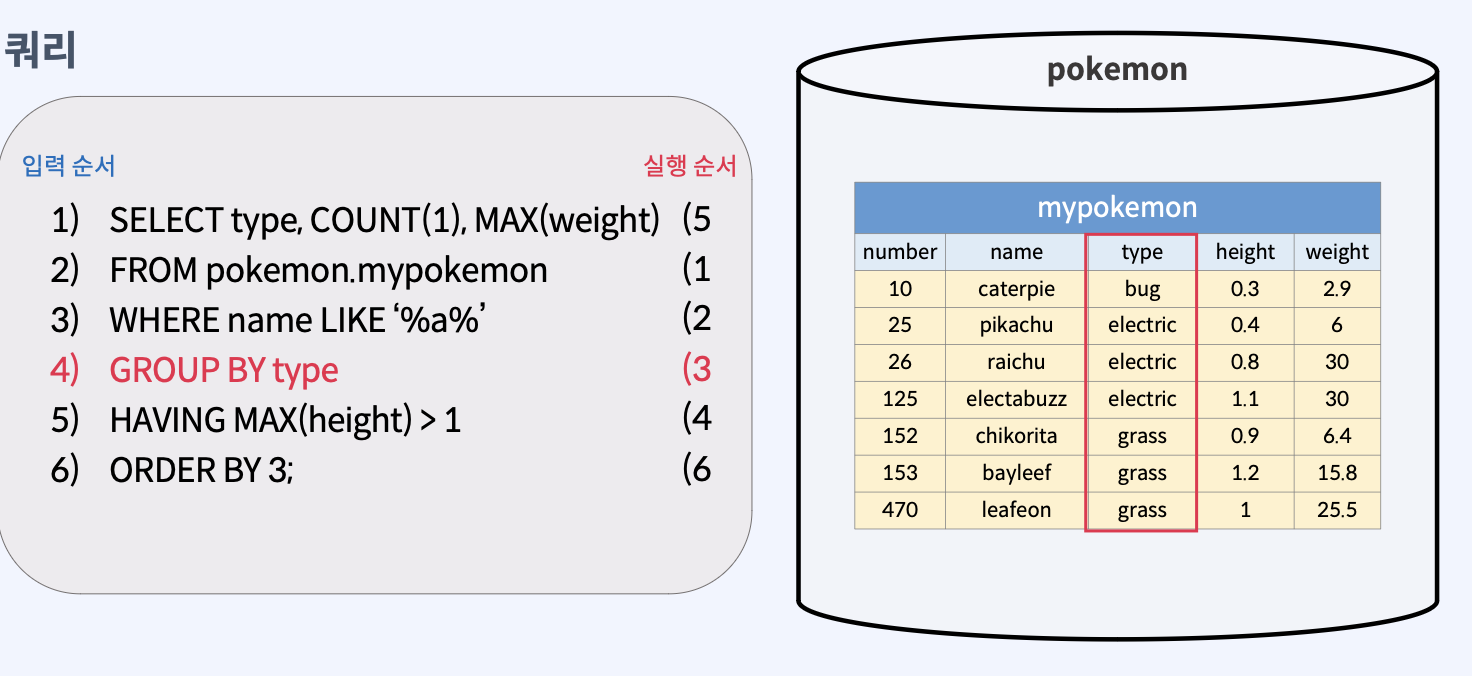
GROUP BY [컬럼 이름]형식으로 사용한다.- 주로 그룹 별 데이터를 집계할 때 사용하며, 엑셀의 피벗 기능과 유사하다.
- GROUP BY가 쓰인 쿼리의 SELECT 절에는 GROUP BY 대상 컬럼과 그룹 함수만 사용 가능한다.
- 만약, GROUP BY 대상 컬럼이 아닌 컬럼을 SELECT 하면, 에러가 발생한다.
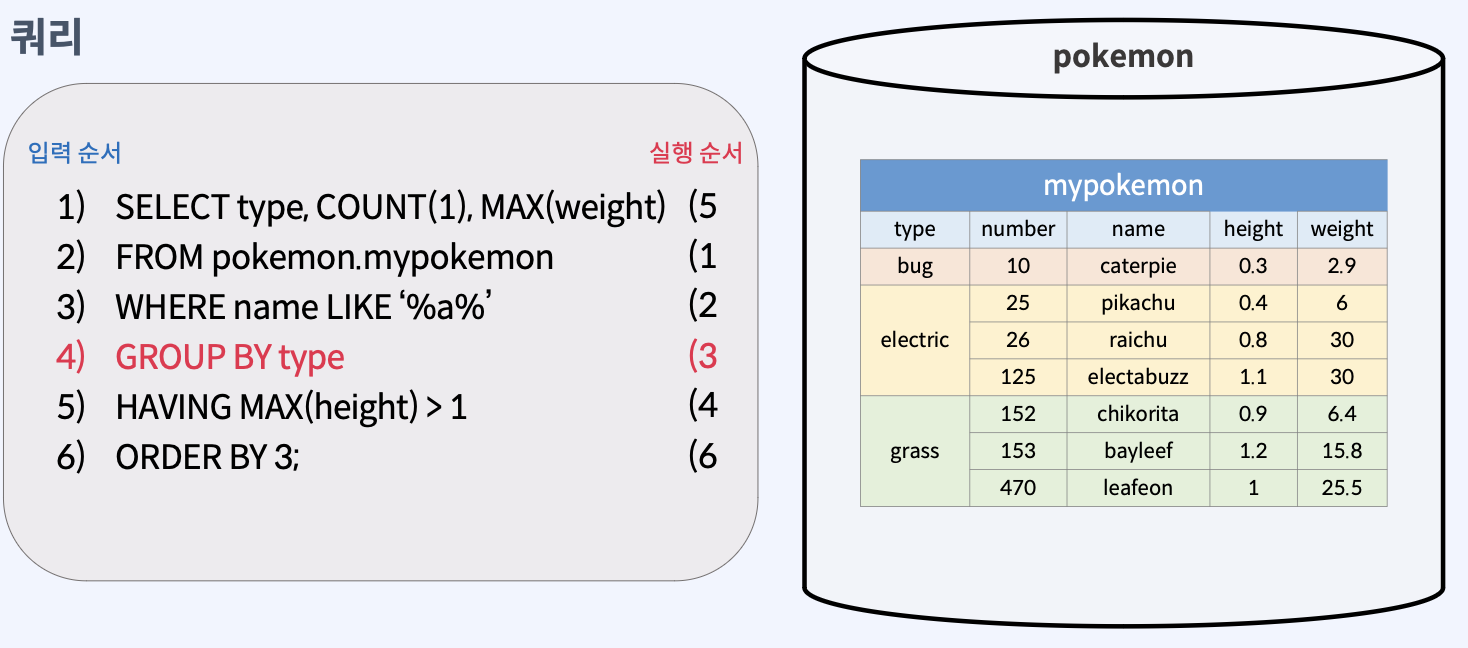
- 여러 컬럼으로 그룹화도 가능하며, 키워드 뒤에
[컬럼 이름]을 복수 개 입력하면 된다. - 컬럼 번호로도 그룹화가 가능하다.
- 이 때, 컬럼 번호는 SELECT 절의 컬럼 이름의 순서를 의미한다.
SELECT [GROUP BY 대상 컬럼 이름], ... , [그룹 함수] FROM [테이블 이름]
WHERE 조건식
GROUP BY [컬럼 이름];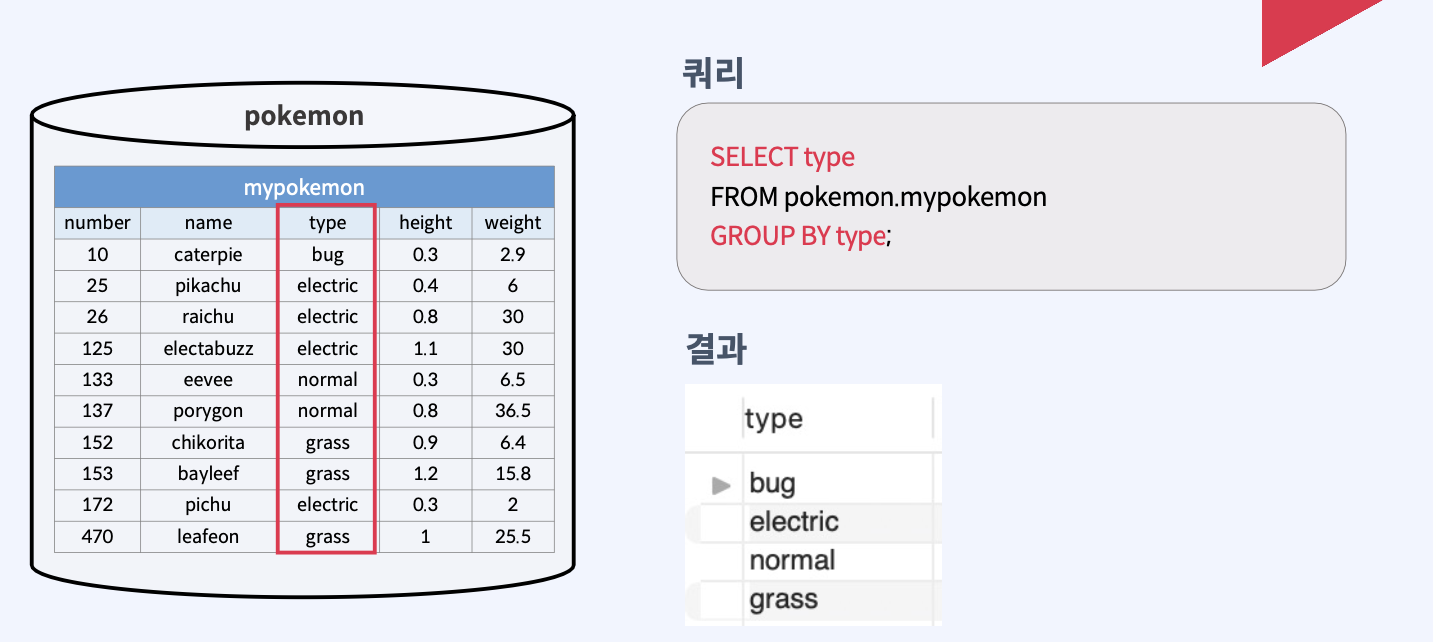
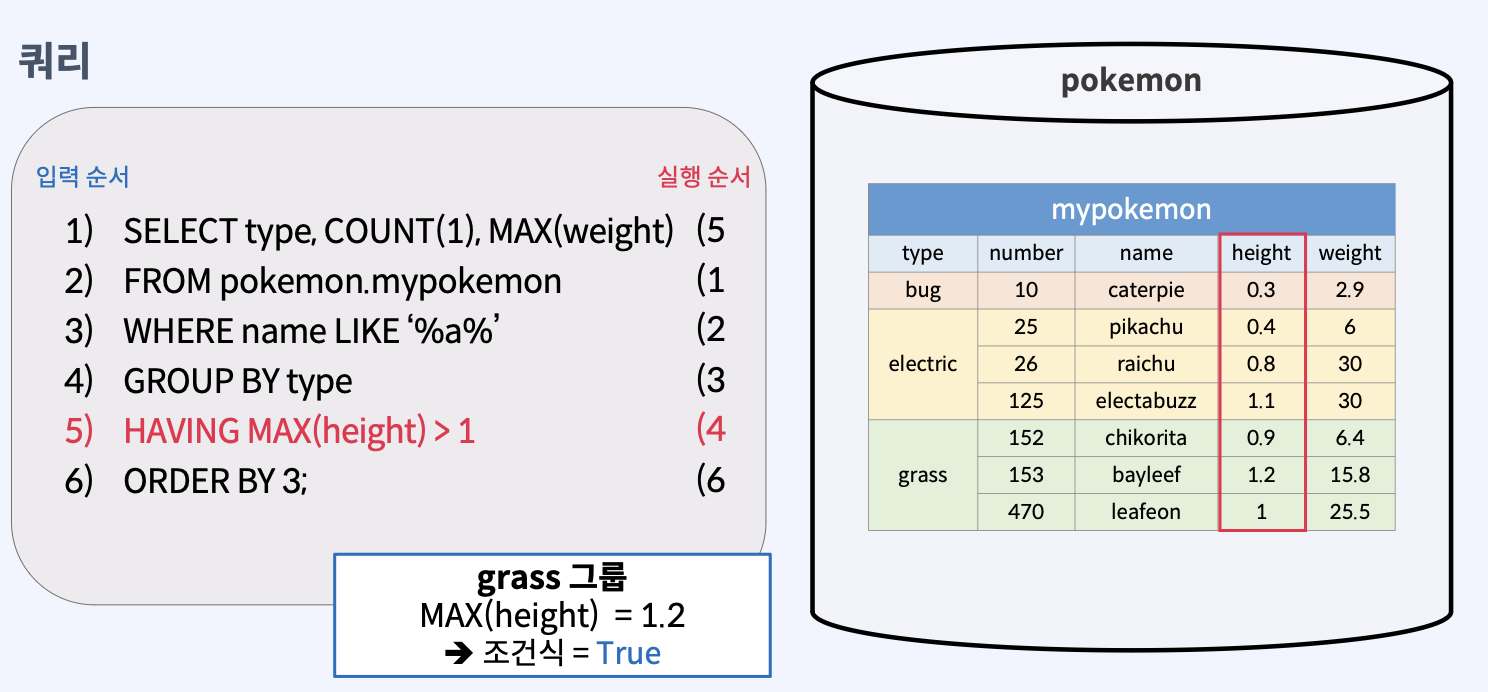
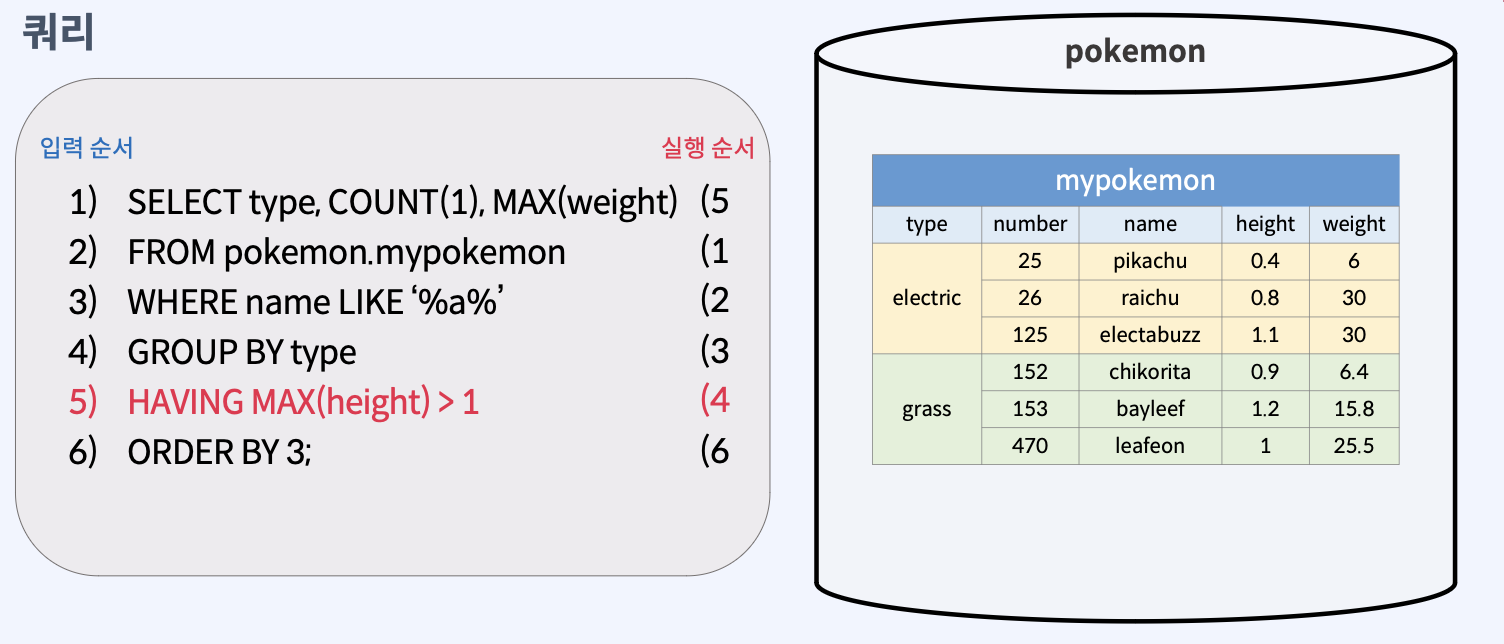
그룹에 조건 주기
데이터 그룹화해서 원하는 그룹만 통계 내기
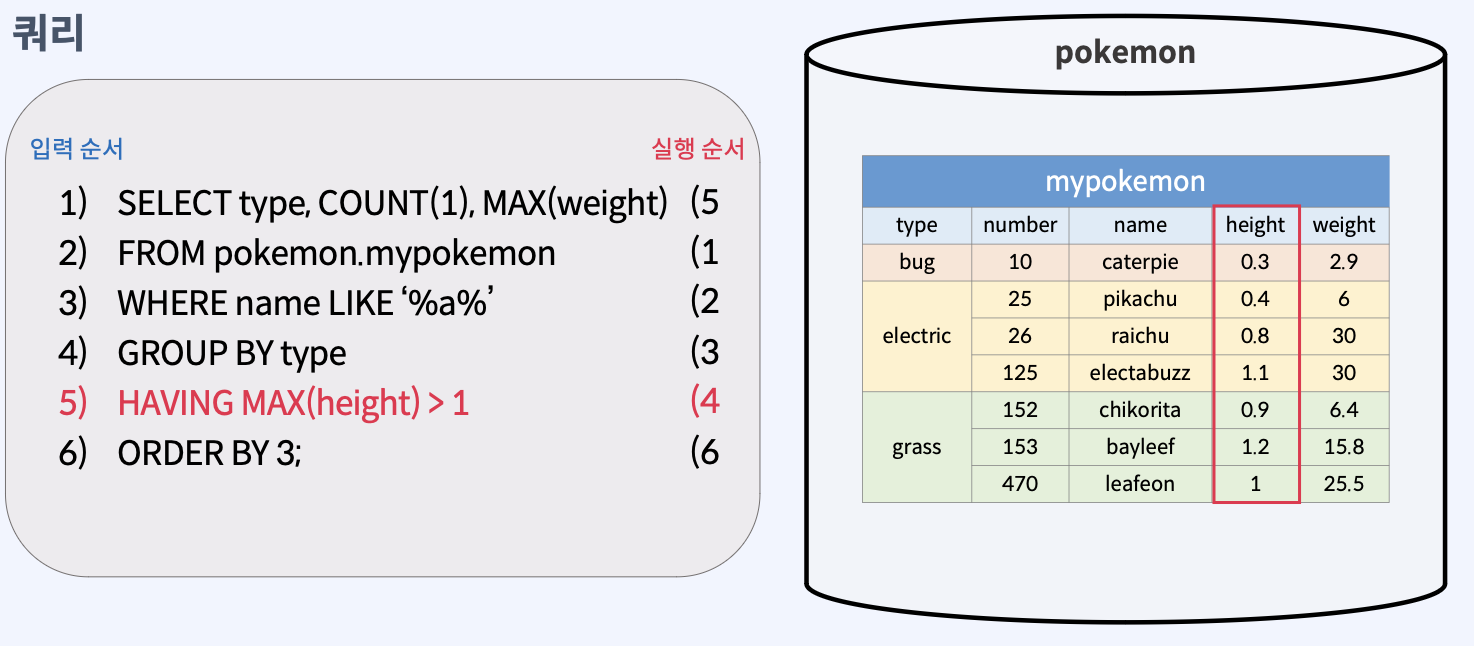
HAVING
가져올 데이터 그룹에 조건을 지정해주는 키워드
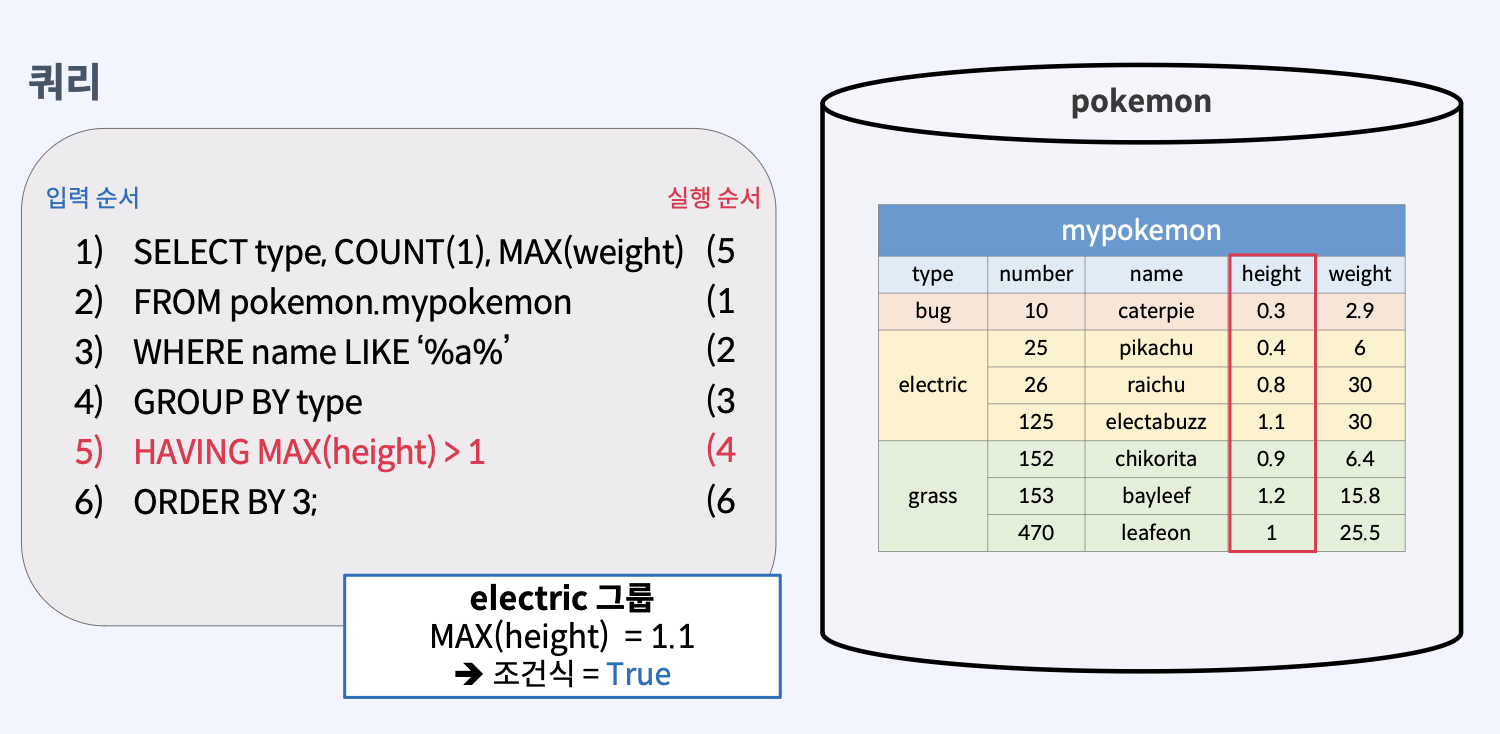
HAVING 조건식형식으로 사용한다.- 조건식이 True(참)이 되는 그룹만 선택한다.
- HAVING 절의 조건식에서는 그룹함수를 활용한다.
쿼리 문법
SELECT [컬럼 이름], ..., [그룹 함수] FROM [테이블 이름]
WHERE 조건식
GROUP BY [컬럼 이름]
HAVING 조건식;다양한 그룹 함수 알아보기
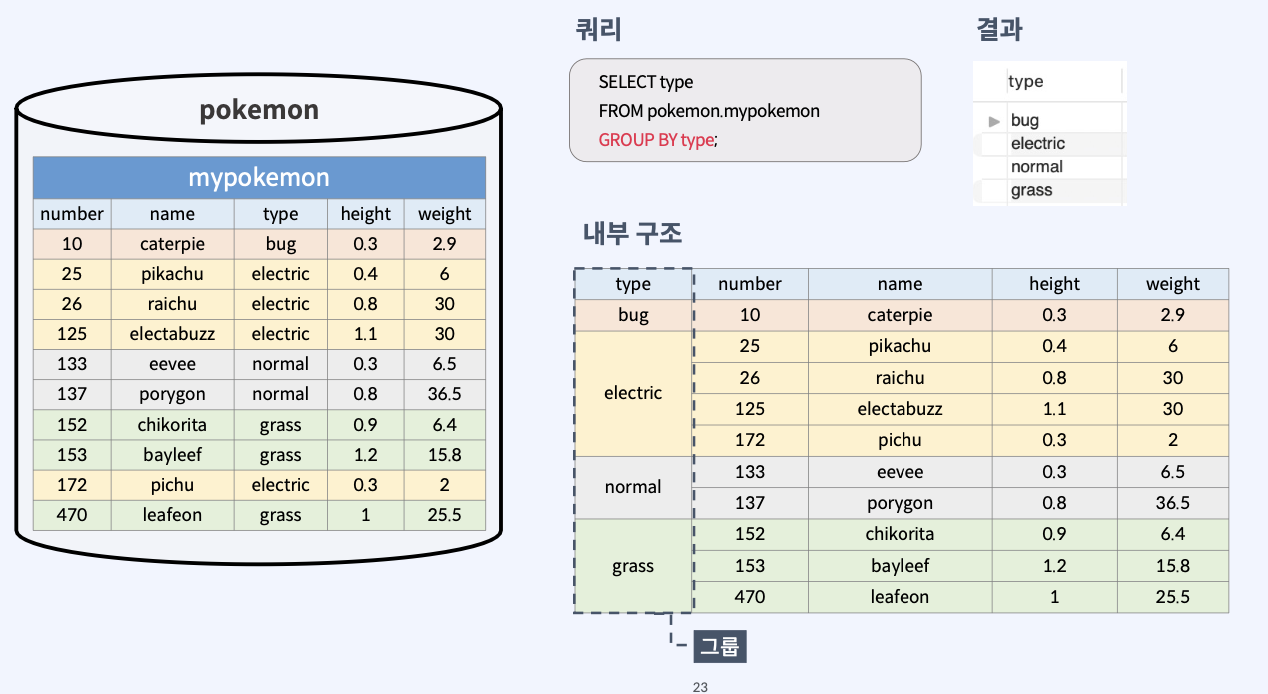
그룹 내부 구조
COUNT
- 그룹의값수를세는함수
COUNT([컬럼 이름])형식으로 SELECT, HAVING 절에서 사용한다.- 집계할 컬럼 이름은 그룹의 기준이 되는 컬럼 이름과 같아도 되고,같지 않아도 됩된다.
- COUNT(1)은 하나의 값을 1로 세어주는 표현으로 COUNT 함수에 자주 사용한다.
- GROUP BY가 없는 쿼리에서도 사용 가능하며, 이때는 전체 로우에 함수가 적용 된다.
SELECT [컬럼 이름], ..., COUNT([컬럼 이름]) FROM [테이블 이름]
GROUP BY [컬럼 이름]
HAVING 조건문;SUM
- 그룹의 합을 계산하는 함수
SUM([컬럼 이름])형식으로 SELECT, HAVING 절에서 사용한다.- 집계할 컬럼 이름은 그룹의 기준이 되는 컬럼 이름과 같아도 되고, 같지 않아도 된다.
- GROUP BY가 없는 쿼리에서도 사용 가능하며, 이때는 전체 로우에 함수가 적용 된다.
SELECT [컬럼 이름], ..., SUM([컬럼 이름]) FROM [테이블 이름]
GROUP BY [컬럼 이름]
HAVING 조건문;AVG
- 그룹의 평균을 계산하는 함수
AVG([컬럼 이름])형식으로 SELECT, HAVING 절에서 사용한다.- 집계할 컬럼 이름은 그룹의 기준이 되는 컬럼 이름과 같아도 되고, 같지 않아도 된다.
- GROUP BY가 없는 쿼리에서도 사용 가능하며, 이때는 전체 로우에 함수가 적용 된다.
SELECT [컬럼 이름], ..., AVG([컬럼 이름]) FROM [테이블 이름]
GROUP BY [컬럼 이름]
HAVING 조건문;MIN
- 그룹의 최솟값을 반환하는 함수
MIN([컬럼 이름])형식으로 SELECT, HAVING 절에서 사용한다.- 집계할 컬럼 이름은 그룹의 기준이 되는 컬럼 이름과 같아도 되고, 같지 않아도 된다.
- GROUP BY가 없는 쿼리에서도 사용 가능하며, 이때는 전체 로우에 함수가 적용 된다.
SELECT [컬럼 이름], ..., MIN([컬럼 이름]) FROM [테이블 이름]
GROUP BY [컬럼 이름]
HAVING 조건문;MAX
- 그룹의 최댓값을 반환하는 함수
MAX([컬럼 이름])형식으로 SELECT, HAVING 절에서 사용한다.- 집계할 컬럼 이름은 그룹의 기준이 되는 컬럼 이름과 같아도 되고, 같지 않아도 된다.
- GROUP BY가 없는 쿼리에서도 사용 가능하며, 이때는 전체 로우에 함수가 적용 된다.
SELECT [컬럼 이름], ..., MAX([컬럼 이름]) FROM [테이블 이름]
GROUP BY [컬럼 이름]
HAVING 조건문;그룹 함수 사용 예제 (SELECT절에서 사용)
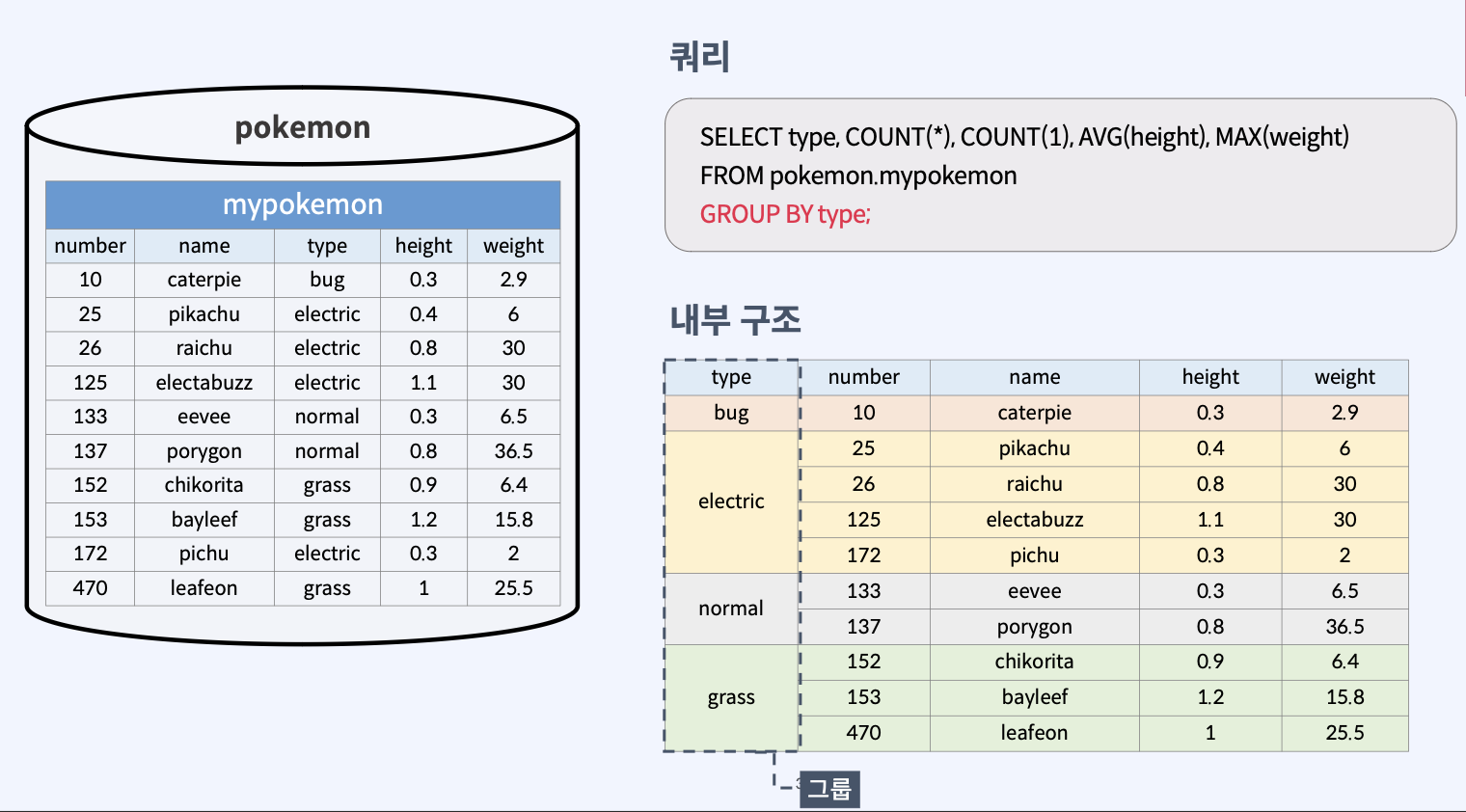
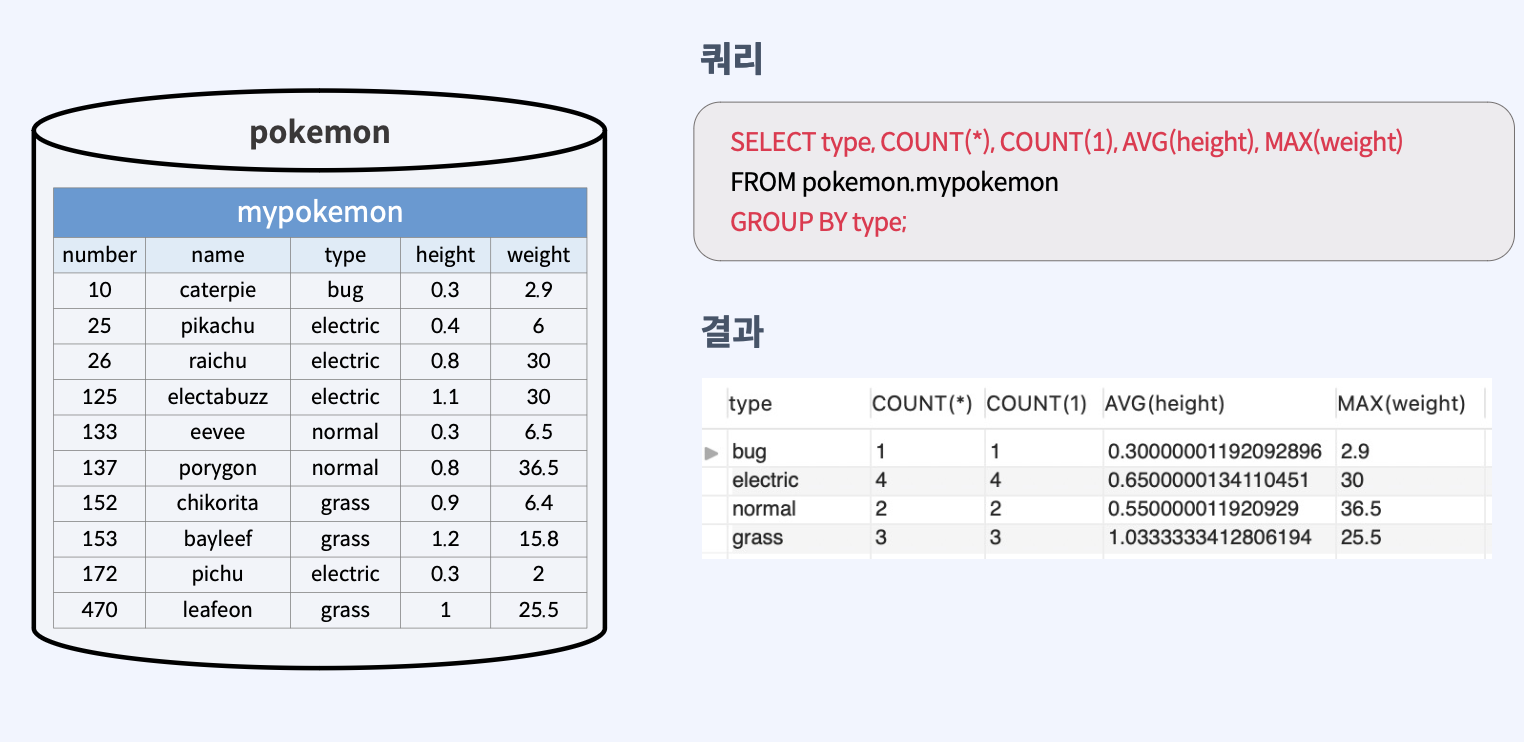
이 SQL 쿼리는 'pokemon.mypokemon' 테이블에서 'type' 별로 그룹화된 포켓몬의 정보를 추출한다. 구체적으로, 다음과 같은 정보들이 선택된다.
type: 포켓몬의 타입이다. 이 필드에 따라 결과가 그룹화된다.COUNT(*): 각 타입별 포켓몬의 총 개수이다.COUNT(*)는 해당 타입에 속하는 모든 행(레코드)의 수를 세는데 사용된다.COUNT(1): 역시 각 타입별 포켓몬의 총 개수이다. COUNT(1)은COUNT(*)와 동일한 기능을 수행하지만, 일부 SQL 엔진에서는 COUNT(1)이 더 최적화되어 빠를 수 있다.AVG(height): 각 타입별 포켓몬의 평균 키다. 'height' 필드의 평균값을 계산한다.MAX(weight): 각 타입별 포켓몬 중에서 가장 무거운 포켓몬의 무게이다. 'weight' 필드의 최대값을 찾는다.
쿼리의 FROM pokemon.mypokemon 부분은 데이터를 조회할 테이블을 지정한다. 여기서는 'pokemon' 데이터베이스의 'mypokemon' 테이블에서 데이터를 조회한다.
GROUP BY type는 결과를 'type' 필드의 값에 따라 그룹화하라는 지시이다. 이로 인해 각각의 타입(예: 물, 불, 풀 등)에 대한 위에 나열된 계산들이 타입별로 수행된다.
이 쿼리의 결과는 각 포켓몬 타입별로 그룹화된, 포켓몬의 수, 평균 키, 최대 무게 등의 요약 정보를 제공한다.
그룹 함수 사용 예제 (HAVING절 에서 사용)
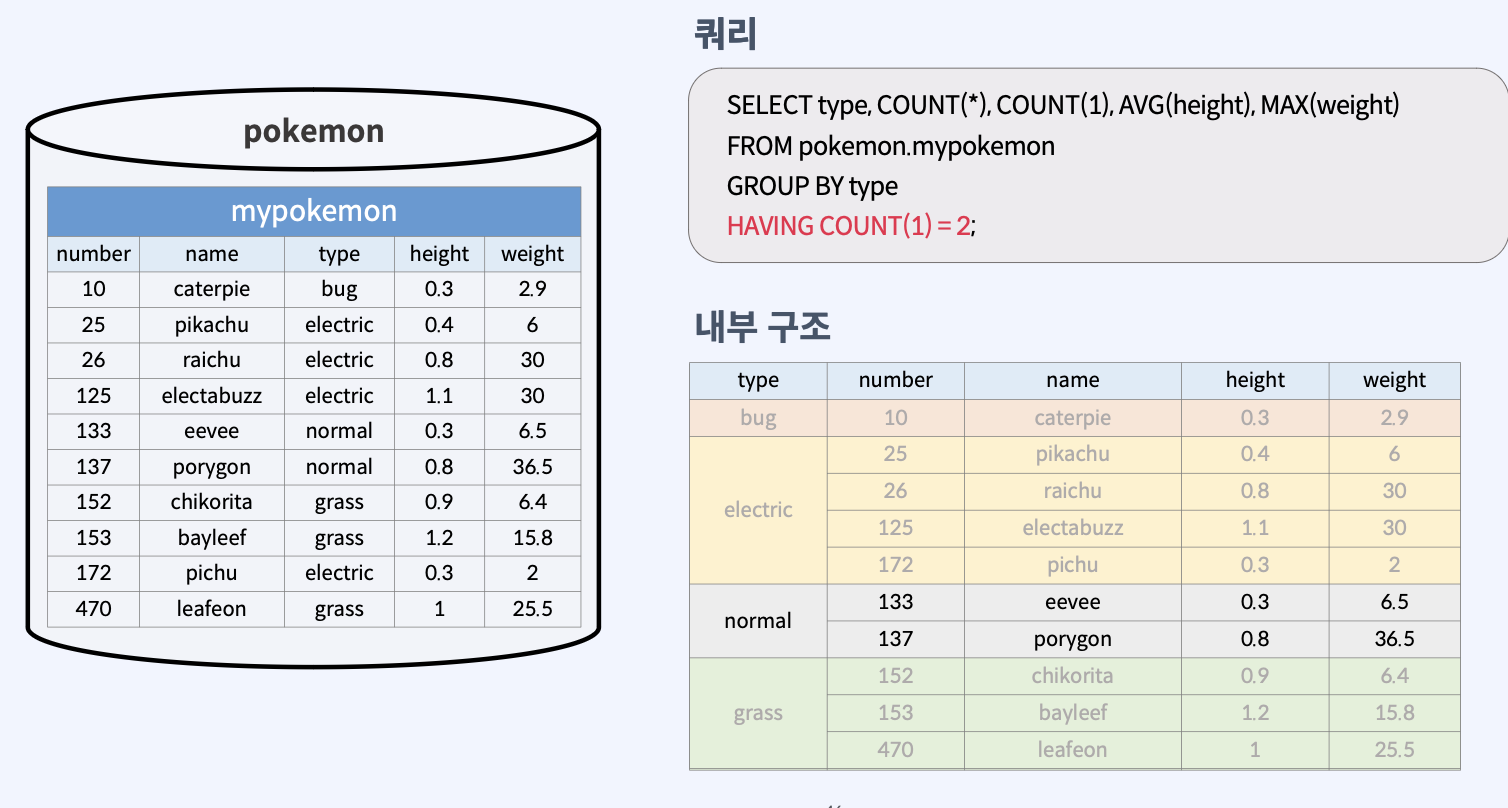
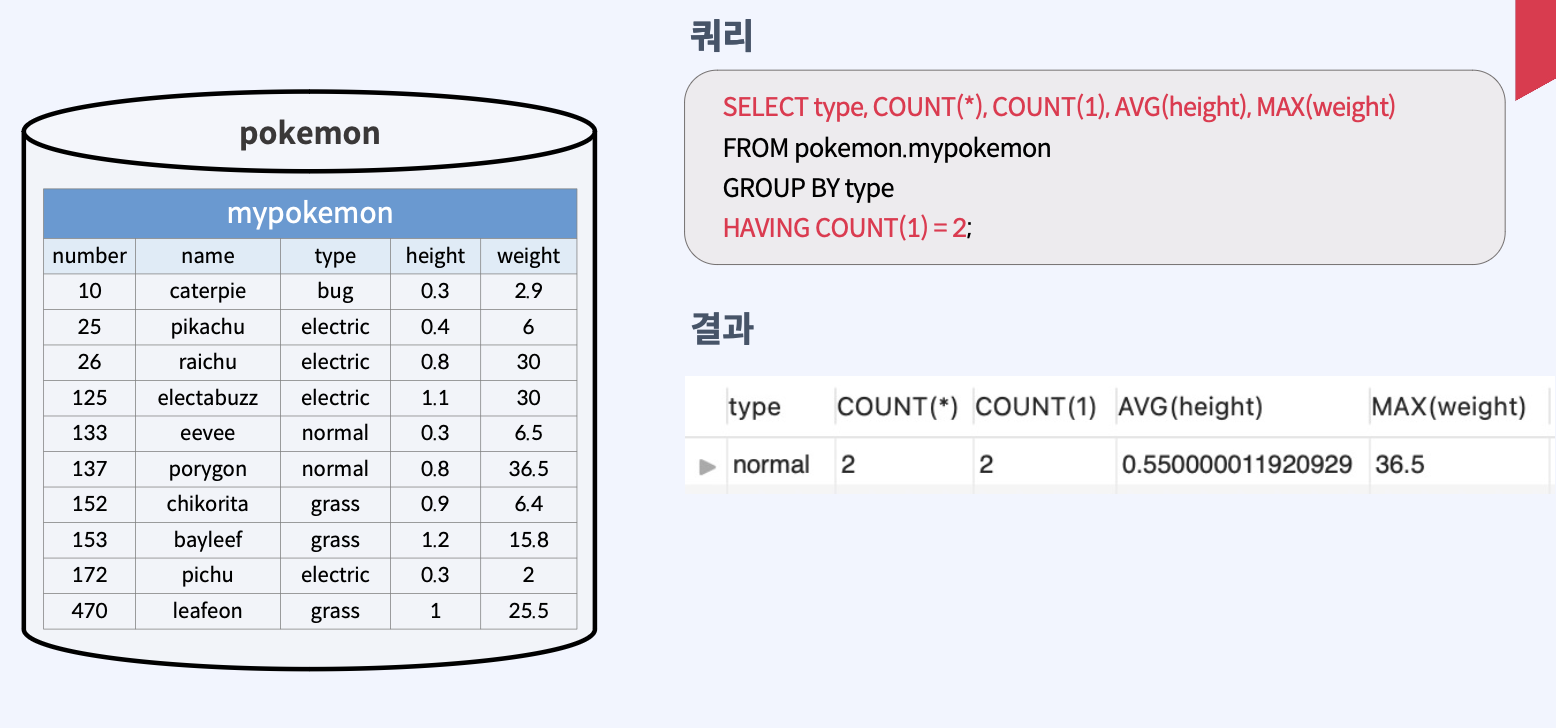
여기서 조건은 특정 'type'을 가진 포켓몬이 정확히 2마리인 경우이다. 쿼리의 각 부분은 다음과 같은 기능을 수행한다.
SELECT type, COUNT(*), COUNT(1), AVG(height), MAX(weight): 여기서는 포켓몬의 'type', 해당 타입의 포켓몬 수, 그 타입의 포켓몬들의 평균 키('height'), 그리고 그 타입의 포켓몬들 중 최대 무게('weight')를 선택한다.FROM pokemon.mypokemon: 이 부분은 데이터를 가져올 테이블을 지정한다. 여기서는 'pokemon' 데이터베이스의 'mypokemon' 테이블이다.GROUP BY type: 이 지시문은 결과를 'type' 필드의 값에 따라 그룹화하라는 것을 의미한다. 즉, 각각의 타입(예: 물, 불, 풀 등)에 대해 별도로 데이터를 집계한다.HAVING COUNT(1) = 2: 이 조건은 'HAVING' 절을 사용하여 특정 그룹에 대한 조건을 지정한다. 여기서는 각 타입별로 정확히 2마리의 포켓몬이 있는 그룹만을 결과에 포함시킨다. COUNT(1)은 해당 타입에 속하는 포켓몬의 수를 세며, 이 값이 2와 같은 그룹만 선택된다.
결과적으로 이 쿼리는 각 포켓몬 타입별로 포켓몬이 정확히 2마리인 경우에 대한, 그 타입의 포켓몬 수, 평균 키, 최대 무게 등의 요약 정보를 제공한다.
TIP) 쿼리 실행 순서


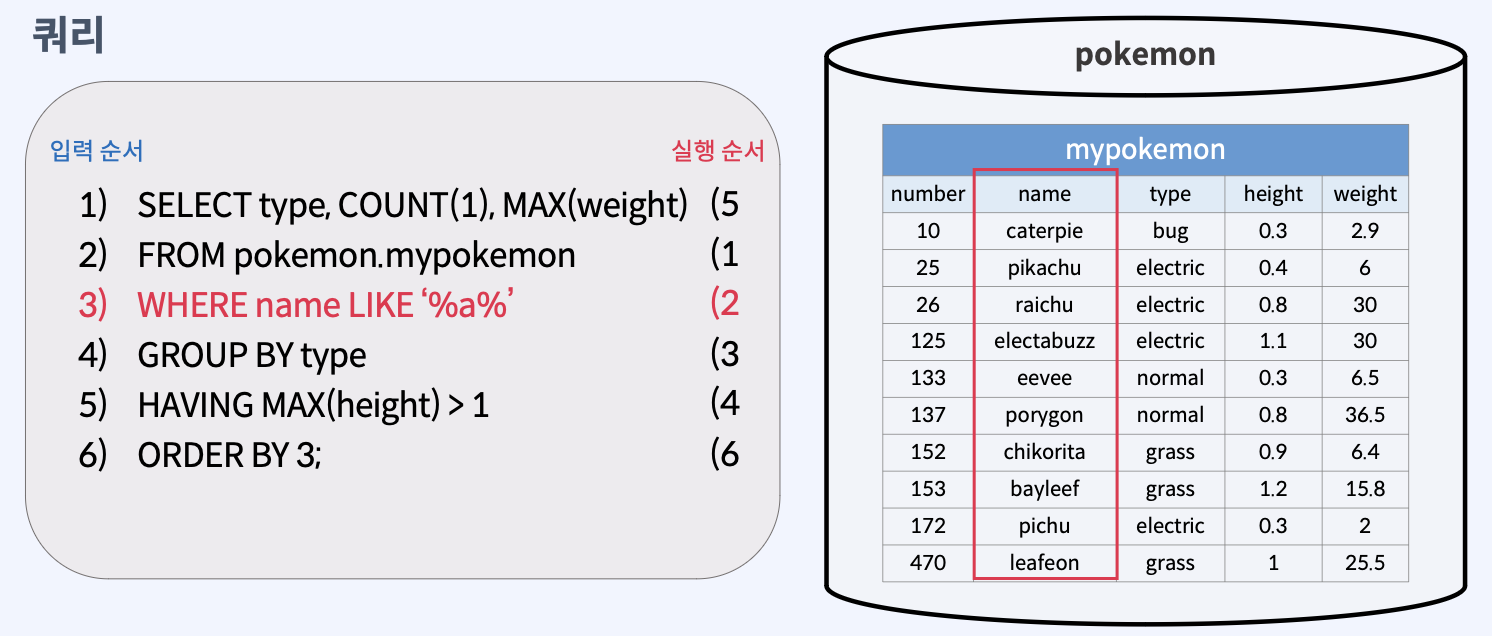

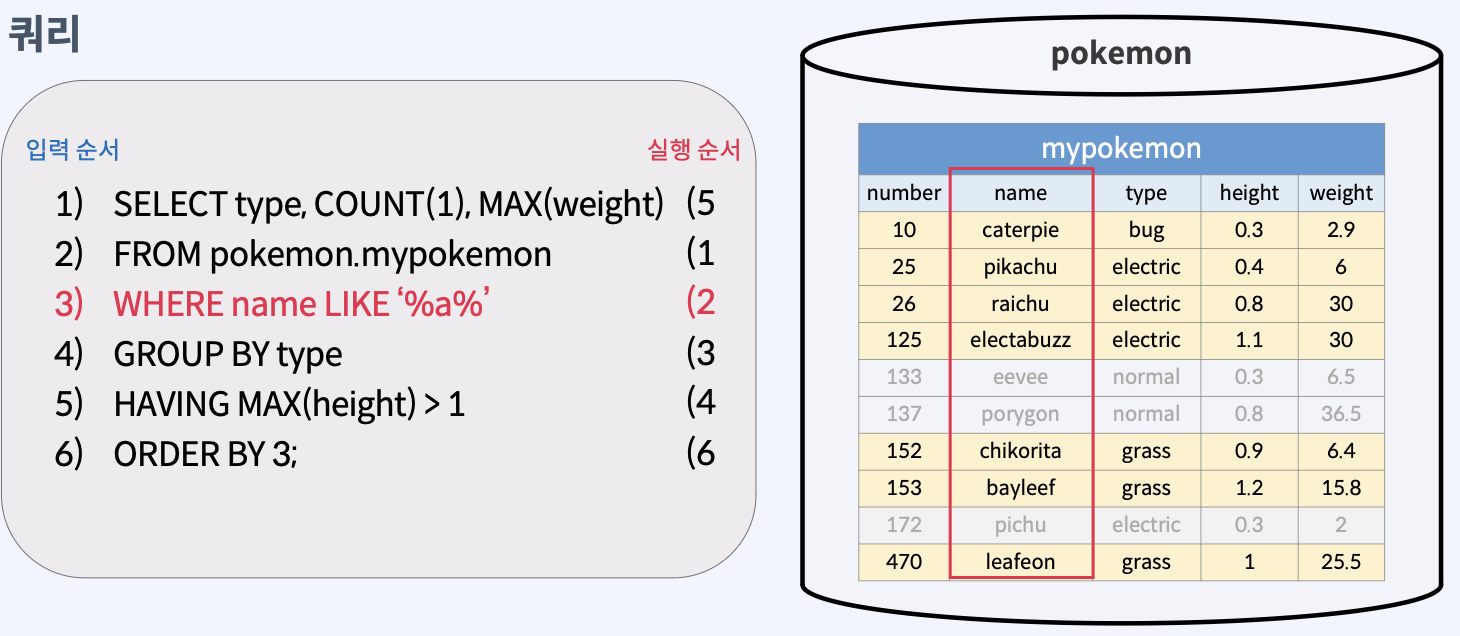




신입사원...