
Data Structure
데이터에 편리하게 접근하고, 변경하기 위해서 데이터를 저장하거나 조직하는 방법.
모든 목적에 맞는 자료구조는 없음.
데이터를 담고 있으면 자료구조라고 보면 됨 (example ; file)
-
Array [배열]
가장 자주 사용되는 자료구조중 하나
실제로 메모리상에 순서대로(차례대로) 저장이 됨.
ex>최신기사, 인기순위 리스트
동일 값 중복 저장 가능, 수정가능
해당 인덱스에 바로 접근 할 수 있는 장점이 있음 (몇번째인지 알았을때) -
장점
순차적(ordered)으로 데이터를 저장.
Array는 주로 서로 연결된 데이터들을 순차적 으로 저장할때 사용(순서 상관 없어도 됨).
데이터의 사이즈가 급변하게 자주 변하지 않을 때 사용하면 좋음
요소를 자주 삭제해야 하지 않을때도!
자료구조에 저장하는 데이터는 일반적으로 요소(element)라고 함 -
단점
공간확보가 필요함 (순차적으로 해야해서)
중간에 데이터가 빠질 경우 그 자리를 메꾸지 않기 때문에 배열이 듬성듬성 비는 경우가 생김. 그러면 순서를 이동시켜야 하는 데, 그럴 때 다른 자료구조에 비해 느려질 수 있음.
가령 내가 순차적으로 사용하고 있는데 급 다른사람이 중간에 끼어들 수 있음
그러면 순서가 꼬이고 내가 확보한 공간을 다 쓴다고 그다음 100개 막 이렇게 또 사용할 수가 없음
중간에 리사이징 할 수 있으나 이미 시스템 가동 중에 알 수밖에 없어서 시간소모가 생김
데이터 사이즈의 문제고 코드상으로 보이지 않아서 갑자기 느려져도 물음표 일 수 있음
cf.> O(n) ;big O notation
자료구조의 속도를 표현할 때 쓰는 표현
(n번까지 찾아가야하는, 해당 인덱스 번쨰를 모를때)
n은 사이즈에 따라 속도가 바뀐다 linear하게
-
Tuple
array와 흡사하지만 1~5개 정도의 요소를 넣을 때 사용 하지만 수정할 수 없음(immutable)
불필요한 코드 사용을 줄일 수 있음
그렇다면 왜 이걸 사용해야 하는 가?
좌표값을 이용할 떄 자주 사용
함수에서 리턴값 2개 만들고 싶을 떄도 사용가능...
두개정도 필요하고 안바뀌고 메모리 사용량도 적고! -
단점
불명확함이 있음 해당 좌표안에 무엇이 x고 y인지 알 수 없음
문맥상에서 짐작해야함. 필드이름이 없음. 그래서 named tuple이 생김
(클래스처럼 이름을 지어줄 수 있게)
Set
배열과 비슷하게 생겼지만 순서대로 저장 x.수정이 가능함.
해쉬값 기반으로 저장해서 look up이 빠름!(검색용이)
중복이 불가능한데 중복 입력하게되면 동일값이 치환된다(최신의 것으로)

hash ;
어떤 암호화된 값을 어느 1번 버켓에 담아 저장하고 두번째 암호화된 값도 2번 버켓에 담아 놓는데, 사실상 이건 순서대로 1번 2번을 해놓은 건 아니어서 set는 순서대로 담는 배열과 같다고 볼 수 없음 .
추가로, 1번에 담아놓았던 거 다시 암호화해서 버켓에 넣음으로써 치환 (중복불가능)
근데 해쉬값은 어떻게 버켓에 갈 수 있는 거지?
set는 어레이를 사용하기 때문에 룸확보를 할 수 있다.
값이 엄청 크게나오는데 그걸 인덱스처럼 사용할 수 있는 건 ,
그걸 백으로 나누고 남는 자리숫자의 값을 인덱스로 함.
그래서 버켓을 찾아갈 수 있는데 나머지값은 중복될 수 있어서 해쉬충돌이 일어난다
어레이(버켓)이 어느정도 차면 자동적으로 re-sizing됨
ex> 유니크한 정보를 담을 때 사용. 가령 전화번호, 중복된걸 어차피 제거하기때문에 그냥 찾아보면 됨. (가령, 배열은 for문 n제곱만큼 돌아야함. 다 찾아봐야하니까)
클래스가 다른경우 값이 동일하다고 생각이 되도 주소값이 다를 수 있기 때문에 내가 정의하기에 따라 다르기 때문에 최신의 값으로 치환됨
-
Dictionary (=object)
key & value 에 상응하는 정보를 담을 때 사용.
그래서 데이터베이스 처럼 키와 값을 묶어서 데이터를 표현해야 할때 유용
set과 동일하게 해쉬화 해서 넘어감 그래서 키값이 중복이 안됨(연산되는 과정은 동일)
set처럼 해쉬충돌이 일어날 수 있음. 수정 가능! -
Stack/ Queue
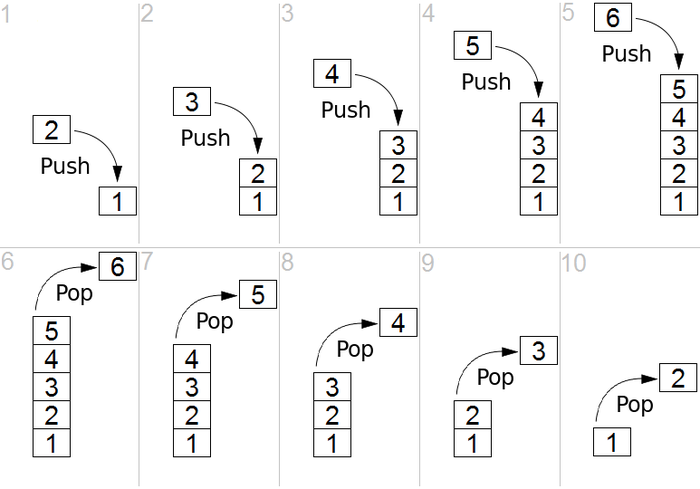
stack
LIFO(Last In First Out); 마지막으로 저장한 데이터가 처음으로 읽힌다는 뜻
ex> 설겆이 한 접시를 하나 하나 쌓아올리는 st..
data저장은 push, 읽는 건 pop (읽음과 동시에 stack에서 삭제됨)
최신 내역이 먼저 나올 때 사용
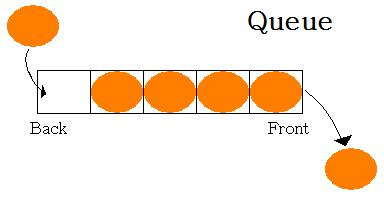
queue
FIFO(First In First Out) ; 처음에 들어온 데이터가 처음으로 읽힘.
먼저 push된 것이 먼저 pop!
맛집 예약 시스템 경우에 사용
Tree
데이터를 마치 나무(거꾸로된) 형태로 저장하는 자료 구조.
Tree 자료구조는 여러 유형 중 가장 기본은 binary tree(이진 트리).
이 구조는 데이터의 저장의 의미 보다는 저장된 데이터를 더 효과적으로 탐색 하기 위해서 사용 (검색 용이!)
Node;
트리 구조의 교점/기본 단위. Node가 데이터를 가지고 있고 또한 자식 노드를 가짐.
Root Node ;
트리 구조의 가장 위, 시작점이 되는 노드.
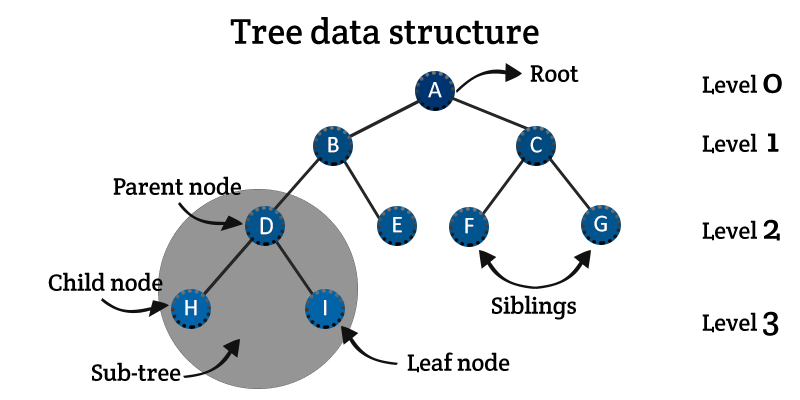
이진 트리는 각 노드가 최대 2개의 자식 노드를 갖고
각 각 left node/ right node라고 함.
left node는 부모 node의 값 보다 적은 값이 저장, right node는 같거나 큰 값을 저장.
