강의 복습내용
7. 통계학 맛보기
모수
유한한 개수의 데이터로 모집단의 확률 분포를 정확하게 추정하는 것은 불가하므로 근사적으로 확률 분포를 추정하게 된다.
- 모수적 방법론 (Parametric)
데이터가 특정 확률 분포를 따른다고 가정한 후 분포를 추정하는 방법 - 비모수적 방법론 (Nonparametric)
데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌는 방법
최대 가능도 추정법 (Max Likelihood Estimation)
이론적으로 가장 가능성이 높은 모수를 측정하는 방법
X가 독립적으로 추출되었을 때는 로그가능도를 최적화한다.
과제 수행과정/결과물 정리
선택과제 1
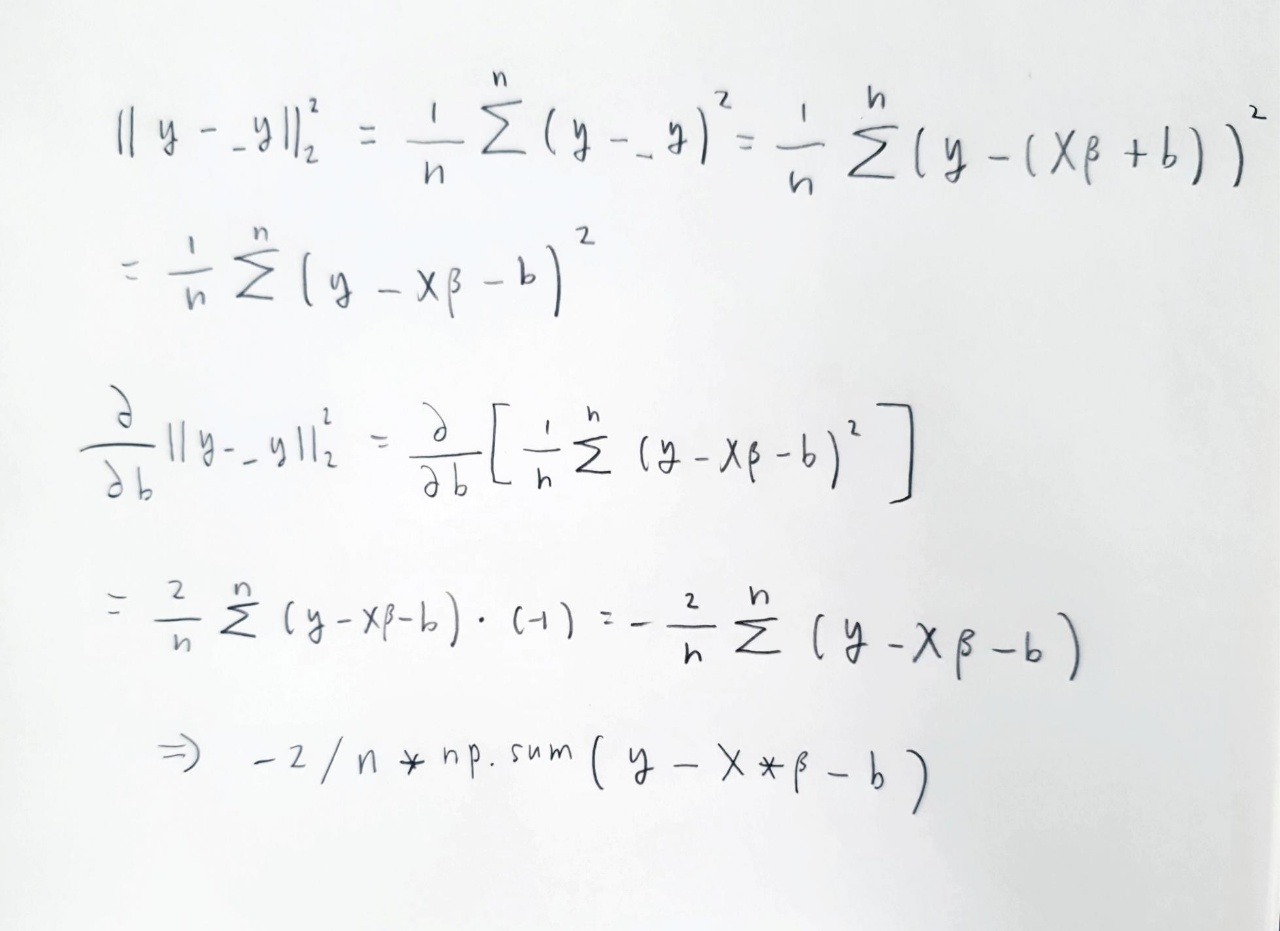
Bias인 b의 gradient를 구하는 부분에서 막혀서 수식으로 표현해보았다.
피어세션 정리
NLP 연구 동향
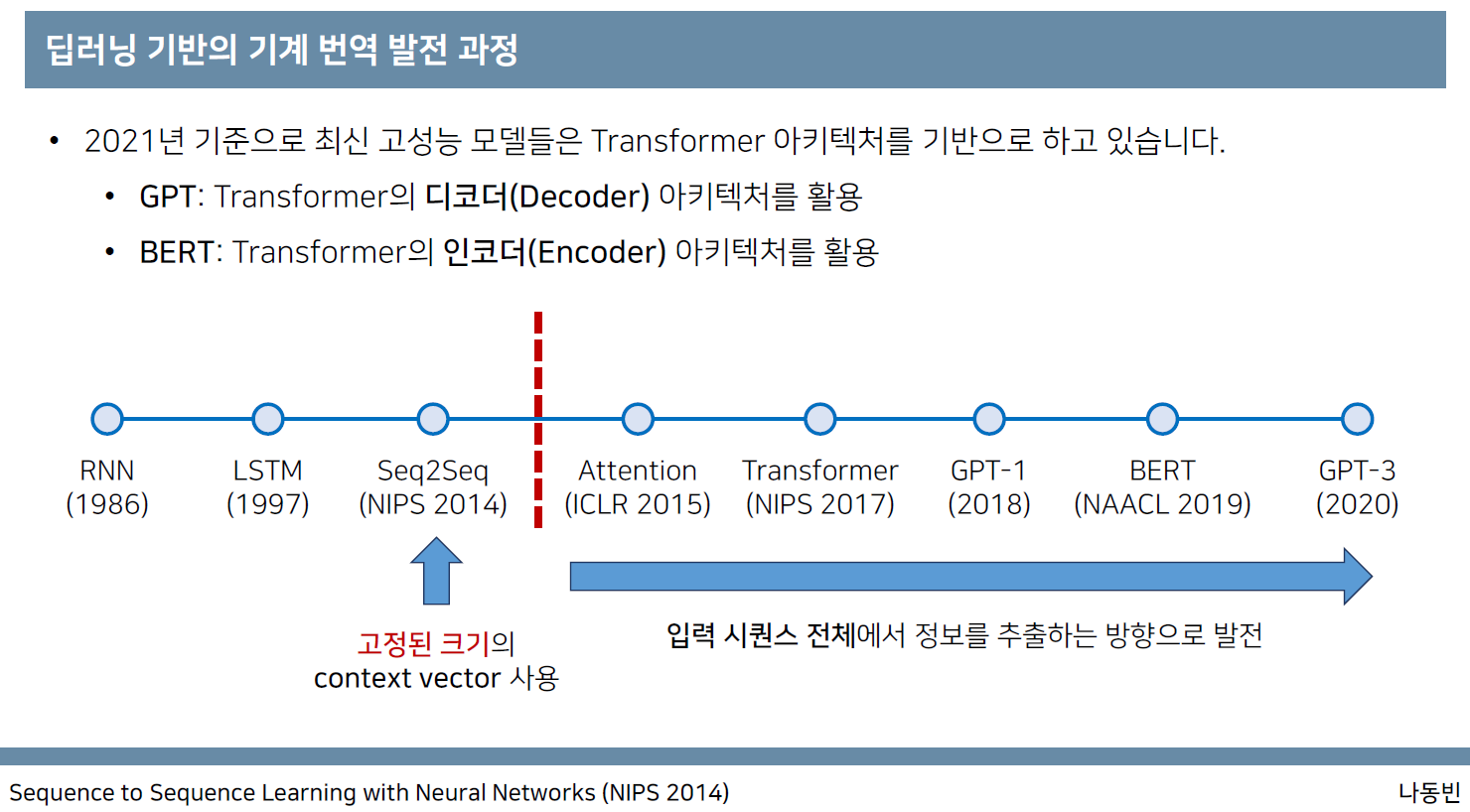
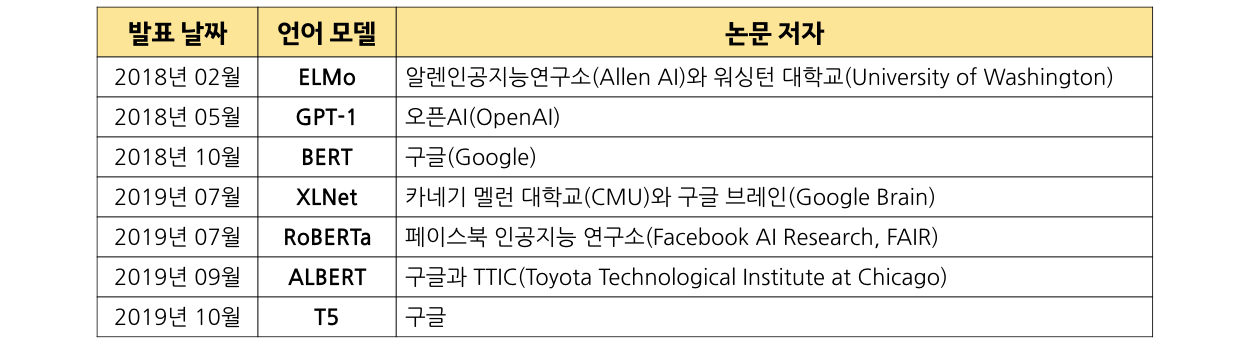
-
ELMo
방대한 텍스트 데이터를 훈련받은 대규모 언어 모델이 다양한 NLU 과제에서 최고의 성능을 낼 수 있음을 최초로 증명했다.
Bidirectional LSTM 아키텍처를 사용해서 주어진 단어 sequence 다음에 오는 단어 또는 앞에 오는 단어를 예측한다.
기존의 대표적인 단어 임베딩 방식인 Word2Vec과 비교해서 다의어를 문맥에 따라 다르게 표현할 수 있는 장점이 있다. -
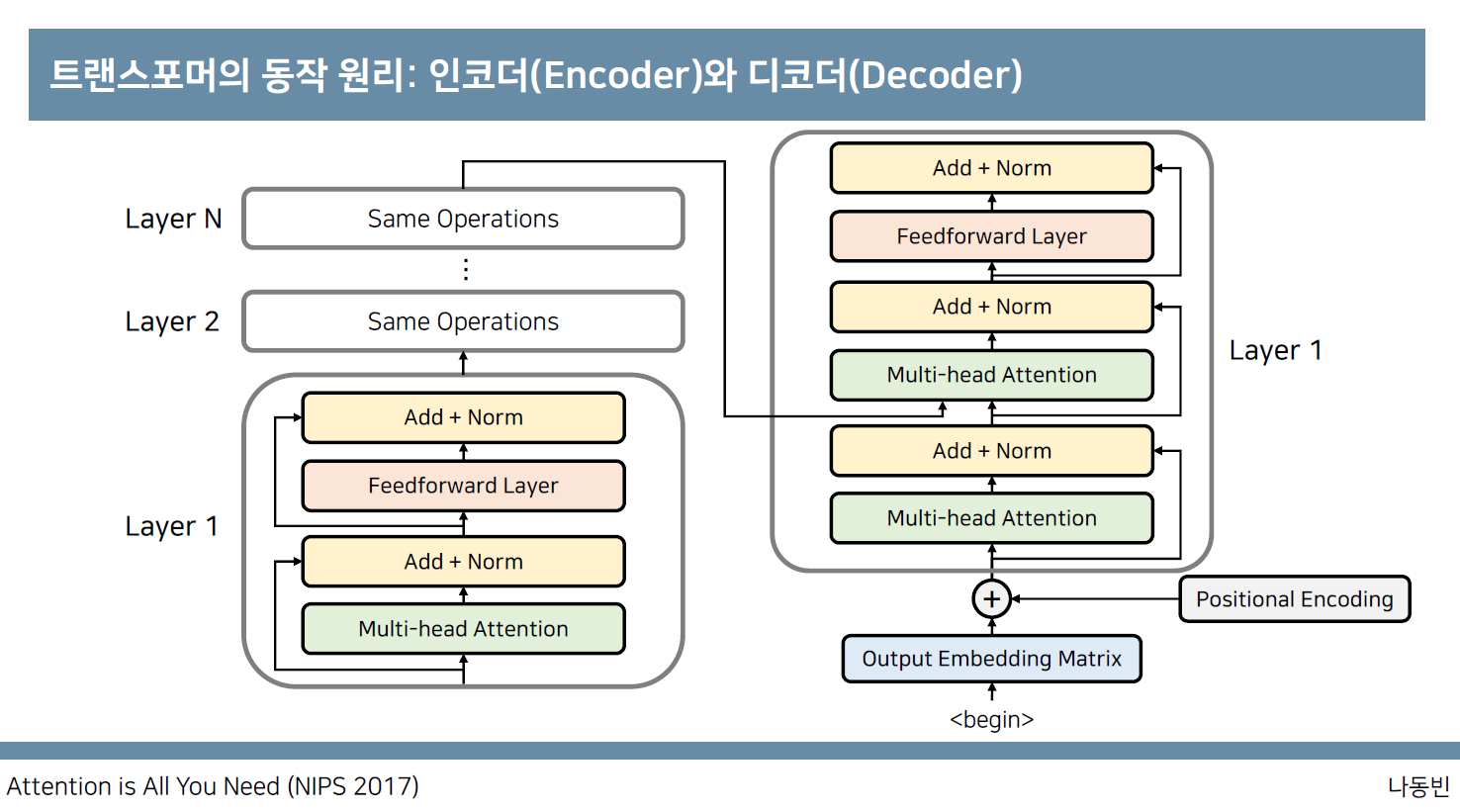
Attention is all you need(Transformer)
Transformer는 Seq2seq 모델에 attention을 추가한 구조이다.
Decoder는 encoder의 모든 출력을 참고한다. 에너지와 가중치를 사용해서 encoder의 출력 중 어떤 정보가 중요한지 계산한다.
RNN이나 CNN을 사용하지 않고 Positional Encoding을 활용한다.
-
GPT-1
Unlabeled data로 unsupervised learning을 통해서 pre-training을 실시한 후 labeled data를 이용해서 supervised learning을 통해 fine-tuning을 진행하는 semi-supervised learning을 선보였다.
자연어 처리에 성능이 좋은 transformer를 사용했으며 다양한 task에 적용될 수 있는 universal representation을 학습하는 것이 목표이다. -
BERT (Bidirectional Encoder Representations from Transformers)
대량 코퍼스로 BERT 언어모델을 적용하고, BERT언어모델 출력에 추가적인 모델(RNN, CNN 등의 머신러닝 모델)을 쌓아 원하는 Task를 수행
Transformer의 encoder를 이용한 완전 양방향 사전훈련 언어 모델(full-directional LM)을 구축하는데 집중했고 서로 인접한 두 문장 간의 관계를 예측하는 방법(next sentence prediction, NSP)도 학습했다. -
GPT-2
-
Transformer-XL
-
XLNet
-
RoBERTa
-
ALBERT
-
ELECTRA (SentenceBert)
Reference
동빈나 github
Kakaobrain NLU 동향
NLP 논문 읽기 팁
학습 회고
최대 가능도 추정은 추가적으로 더 검색해서 공부를 진행해야겠다.
