isinstance(h, torch.Tensor())
#Trueh가 torch.Tensor 자료형이면 True를 반환한다.
https://tutorials.pytorch.kr/intermediate/seq2seq_translation_tutorial.html
3_basic_rnn 실습
진행 과정
Data의 각 요소들을 max sequence length에 맞춰서 padding 처리
valid_seq = []
for idx, seq in enumerate(tqdm(data)):
valid_seq.append(seq)진행사항을 표시할 때 쓰는 tqdm
4_fancy_rnn 실습
필수과제 2 continue
output.shape
#torch.Size(35,20,ntoken)
targets.shape
#torch.Size(700)
output.view(-1,ntoken)
# torch.Size(700,ntoken)loss를 구하려면 두 개의 shape를 맞춰줘야하는데 이렇게 shape의 0번 index가 맞춰져서 비교가 가능해진다.
RNN and Language Model
Types of RNNs
- One to one
- One to many
- Image captioning
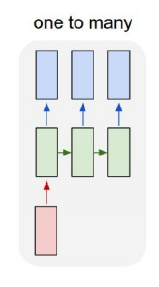
입력 시 input sequence가 output sequence 길이와 같아지도록 zero padding
- Many to one
- Sentimental Analysis
- Many to many (Sequence to Sequence)
- Machine translation
- Video classification on frame level
Language Model
-
Character-level Language Model
-
Back Propagation Through Time (BPTT)
-
Searching for Interpretable Cells
-
Vanishing/Exploding Gradient Problem in RNN
같은 parameter를 계속 곱해주는 형태라서 W가 1보다 크면 exploding, 1보다 작으면 vanishing이 발생한다.
LSTM & GRU
Further Question
- BPTT 이외에 RNN / LSTM / GRU의 구조를 유지하면서 gradient vanishing/exploding 문제를 완화할 수 있는 방법은?
- RNN / LSTM / GRU 기반의 Language Model에서 초반 time step의 정보를 전달하기 어려운 점을 완화할 수 있는 방법은?
Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU)
LSTM
-
Core Idea: Cell state
-
단기 기억을 길게 유지하기 위해 사용
-
Long short-term memory
-
Input gate
-
Forget gate
-
Output gate
-
Gate gate
Cell state - 전체적인 정보를 포함하고 있음
h_t - Cell state에서 현재 필요한 정보만 추출함
-
GRU
- Cell state가 없고 h_t만 존재한다.
- forget gate 대신 1- input gate를 사용한다.
- LSTM의 경량화된 모델

Speech Synthesis & Voice Cloning