Intro to NLP
Course
- Language Modeling
- Machine translation
- Question answering
- Document classification
- Dialog systems
NLP
- Low-level parsing
- Tokenization, stemming
- Word and phrase level
- Named entity recognition(NER), Part-Of-Speech(POS) tagging, Noun-phrase chunking, Dependency parsing, Coreference resolution
- Sentence level
- Sentiment analysis, Machine translation
- Multi-sentence and paragraph level
- Entailment prediction, Question answering, Dialog systems, Summarization
Text Mining
- Extract useful information from text and document
- Document clustering
- Highly related to computational social science
Information retrieval
- Highly related to computational social science
Trend of NLP
- Word embedding - Word2Vec, GloVe
- RNN-family models - LSTM, GRU
- Attention modules and Transformer models
- Self-supervised training setting - BERT, GPT-3
Word Embedding
- 벡터 요소들의 대부분이 0으로 이루어진 요소는 sparse vector이고 one-hot vector가 그 예시이다.
- sparse vector의 차원을 낮춘다면 대부분의 값이 실수로 변하고 dense vector가 된다.
- 단어를 dense vector 형태로 표현 하는 것이 word embedding이고 그 dense vector가 embedding vector가 된다.
- LSA, Word2Vec, GloVe 등의 방법들이 있다.
Word2Vec
- One-hot vector로는 단어 간의 유사도를 구할 수가 없고 단어의 의미를 벡터화 시켜주는 방법이 필요한데 그 방법 중 하나이다.
- 단어의 의미를 다차원 벡터에 벡터화하는 분산 표현의 기법 중 하나이다.
- 비슷한 위치에 존재하는 단어들은 의미가 비슷하다는 가정이 전제됨
- 입력층과 출력층 사이에 하나의 은닉층이 존재한다.
- 은닉층은 일반적인 은닉층과는 다르게 활성화 함수가 존재하지 않고 룩업테이블이라고도 부른다.
- CBOW 방식과 Skip-Gram 방식 두 가지로 나뉜다.
CBOW
- 주변에 있는 단어들로 중간에 있는 단어를 예측하는 방법
- 중심에 있는 단어를 예측하기 위해 앞뒤로 몇 개의 단어를 참고할지 결정해야하는데 그 범위를 window라고 한다.
ex) He studys Deep Learning in the lab - 중심단어 : Deep, window: 2
주변 단어: (He, studys) , (Learning, in) - 중심 단어를 바꿔가며 학습할 수 있는데 이 과정을 sliding window라고 한다.
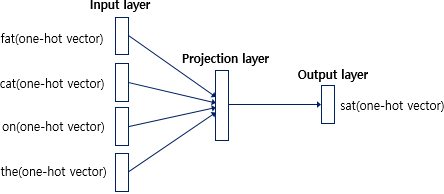
주변 단어들의 one-hot vector와 중심 단어의 one-hot vector를 이용해서 학습을 시킨다.
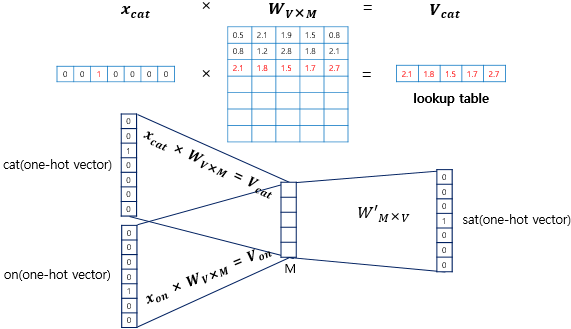
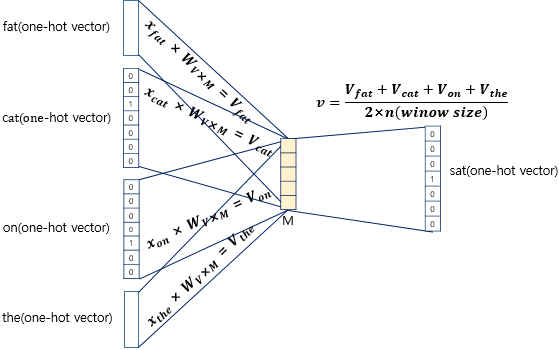
One-hot vector와 weight matrix를 곱해서 나온 V vector들의 평균을 구해서 v를 구한다.
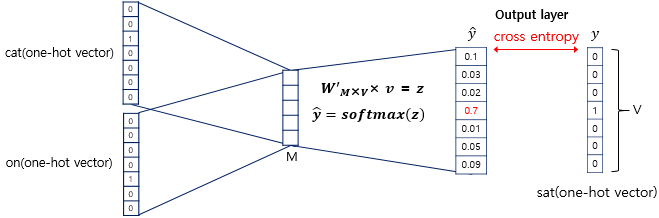
decoding weight matrix와 v를 곱하고 softmax를 취해줘서 최종적인 예측값이 나오게 된다.
Skip-Gram
- 중간에 있는 단어로 주변에 있는 단어를 예측하는 방법

Speech Synthesis & Voice Cloning