TTS_Paper_Review
1.Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis [ICML, 2018]
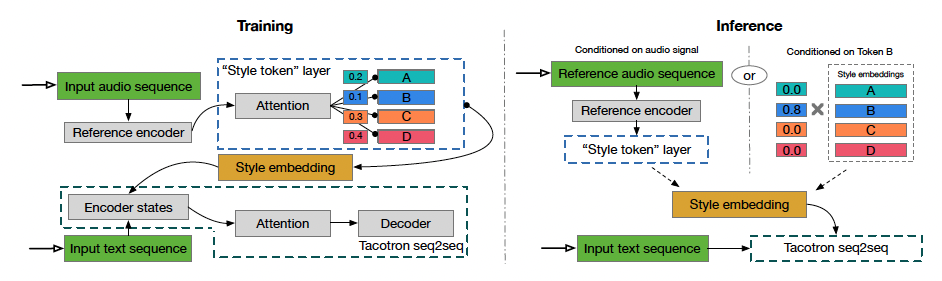
Reference Encoder와 Style Token Layer를 통해 얻어진 Style embedding을 Tacotron2에 추가한 감정 음성 합성 모델
2022년 7월 12일
2.FastSpeech: Fast, Robust and Controllable Text to Speech [NeurIPS, 2019]
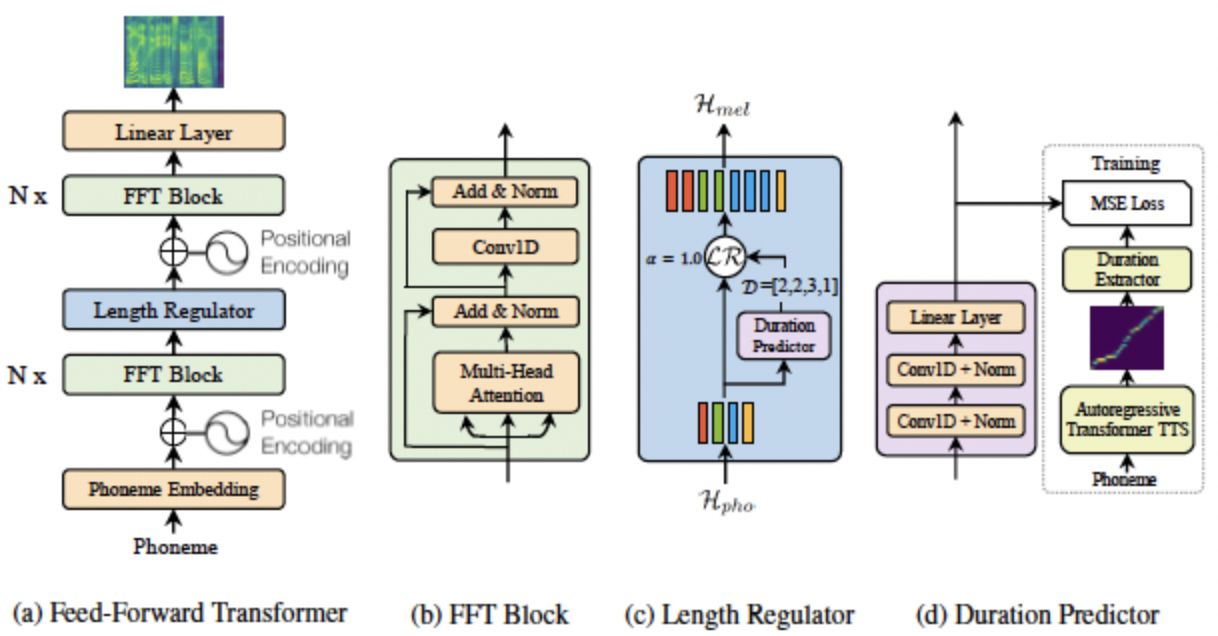
Transformer 기반의 non-autoregressive TTS 모델, Pre-trained attention alignment가 필요함
2022년 8월 24일