Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis [ICML, 2018]
TTS_Paper_Review
목록 보기
1/2
Abstract
- 타코트론 내부에서 공동으로 학습되는 임베딩을 쌓은 global style tokens를 제시한다.
- 임베딩들은 명백한 라벨 없이 학습되지만 큰 범위의 음향 표현을 모델링하는 것을 학습한다.
- GST가 생성하는 약간 해석이 가능한 라벨들은 텍스트에 관계없이 발화 속도와 스타일에 변화를 주는 새로운 방법의 합성을 제어하는 데 쓰인다.
- GST는 또한 발화 스타일을 변환하는 것과 긴 텍스트 corpus를 단일 오디오 클립의 발화 스타일을 따라하는 것 또한 가능하다.
- 라벨링이 되지 않은 노이즈가 있는 데이터로 학습된다면 GST는 노이즈와 화자 신원을 분리해서 확장 가능성하고 잡음에 강한 합성된 음성을 제공한다.
Conclusions and Discussions
- GSTs는 스타일을 모델링하는 강력한 E2E TTS 시스템이다.
- GSTs는 직관적이고 구현하기 쉬우며 명백한 라벨들 없이 학습이 가능하다.
- 표현이 풍부한 데이터로 학습시킬 때 GST 모델은 스타일을 제어하고 변환하는데 쓰이는 해석 가능한 임베딩들을 생성한다.
- 발화 스타일을 모델링하기 위해 고안되었지만 GSTs는 데이터 안의 latent variation를 포함하는 일반적인 기법이다.
- 라벨링되지 않은 노이즈있는 데이터를 통한 실험에서 GST 모델은 다양한 노이즈와 화자 요인들을 구분된 스타일 토큰들로 추출해낸다.
- 지금은 타코트론 모델에 대해서 적용되었지만 다른 E2E TTS 모델에도 적용될 것으로 예상
- 해석가능성, 제어가능도와 robustness로 인해서 다른 도메인의 문제들에도 적용될 것으로 예상한다. ex) Text-to-image, neural machine translation models
Introduction
- 운율은 준언어정보, 억양, 강세 및 스타일과 같은 언어의 여러 현상의 합류점이다.
- 이 논문에서는 style modeling에 초점을 두고 주어진 문맥에 대해 적절한 발화 스타일을 선택할 수 있는 모델을 제공하는 것이다.
- 간단하게 정의할 수는 없어도 스타일은 의도와 감정 그리고 화자의 선택에 따른 억양과 흐름에 영향을 받는 등 풍부한 정보를 가지고 있다.
- 적절한 스타일 표현은 전체적인 인식에 영향을 주고 오디오북이나 뉴스리더 같은 적용에서 중요하다.
- 스타일 모델링에서는 여러 가지 문제점을 가진다.
-
옳은 운율적 스타일에 대한 객관적인 측정법이 없다. → 모델링과 평가가 어렵다.
-
표현이 매우 역동적인 범위의 목소리는 모델링하기 힘들다.
→ 대부분의 TTS 모델은 end-to-end 시스템을 사용하고 있고 입력 데이터의 평균적인 운율적 분포를 학습하기 때문에 특히 긴 구절에 대해서는 표현을 적게 생성해낸다.
- GST는 운율 레이블 없이 훈련되지만 다양한 표현 스타일을 발견한다.
- 내부 구조는 해석 가능한 라벨들을 생성해서 다양한 스타일 제어와 스타일 전송 태스크에 쓰이도록한다. → 긴 표현 합성에 상당한 향상을 이끌었다.
- 잡음이 있고 라벨링이 되지 않은 발견된 데이터에도 적용이 가능하고 확장이 가능하지만 잡음에 강한 합성을 제공한다.
Model Architecture
- Grapheme이나 phoneme 입력으로부터 바로 멜 스펙트로그램을 예측하는 seq2seq 모델인 타코트론 기반 모델
- 멜 스펙트로그램들은 low-resource inversion algorithm(Griffin Lim)이나 WaveNet과 같은 뉴럴 보코더에 의해 음성 파형으로 변환
- 타코트론이 보코더의 선택이 seq2seq 모델에 의해 모델링된 운율에 영향을 주지 않는 점을 지적
- Reference encoder, style attention, style embedding, seq2seq model(Tacotron)으로 이루어진 GST 모델을 제안
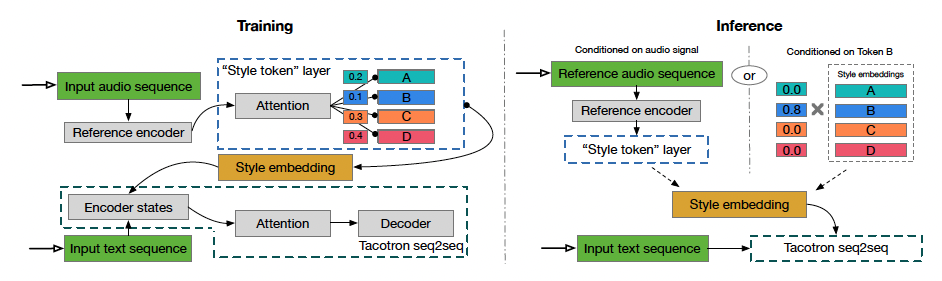
Train
- 학습 데이터의 log-mel spectrogram을 reference encoder와 style token layer에 입력
- Style token layer를 지나서 나온 style embedding은 타코트론의 텍스트 인코더 단계에서 조건으로 사용
Inference
- 임의의 reference 신호를 텍스트와 발화 스타일에 따라 합성하기 위해 입력할 수 있음
- Reference 인코더를 제거하고 학습된 해석 가능한 토큰들을 사용해 합성을 제어할 수 있음
Training
Reference encoder (Skerry-Ryan et al., 2018)
- 가변 길이의 오디오 신호의 운율을 고정된 길이의 벡터로 압축
- 고정된 길이의 벡터를 reference embedding이라고 함
- 학습하는 동안 reference 신호는 ground-truth 오디오
Style token layer
- Reference embedding은 style token layer의 attention module에서 query로 사용됨
- Style token layer의 attention은 alignment를 학습하는 것이 아닌 reference embedding과 무작위로 초기화된 임베딩 묶음의 각 토큰과의 유사도를 학습
- 임베딩들의 세트를 global style tokens (GSTs)나 token embedding이라고 부르고 모든 학습 sequence에 공유됨
- 어텐션 모듈은 인코딩된 reference embedding에 대한 각 style token의 기여도를 나타내는 weight 조합의 세트를 출력
- GST들의 weighted sum을 style embedding이라고 부르고 매 타임스텝마다 텍스트 인코더에 조건으로 통과됨
- 다른 나머지 모델들과 함께 학습되어 Tacotron 디코더에서 reconstruction loss로 운영이 됨
- 구체적인 Style이나 prosody label이 필요하지 않음
Inference
- GST 구조는 inference 모드에서의 강력하고 유연한 제어를 위해 설계됨
- 정보는 두 가지 방법 중 하나로 흐를 수 있음
-
특정 토큰들을 텍스트 인코더에 조건으로 직접 줄 수 있음
→ Reference 신호 없이 제어하고 조작할 수 있음
-
Style transfer를 위해 다른 오디오 신호를 입력할 수 있다 (Transcript와 생성할 텍스트가 같을 필요가 없음)
Model Details
Tacotron Architecture
- Phoneme 입력을 사용해서 학습 속도를 높이고 디코더의 GRU를 256 cell LSTMs 2 layer로 바꿈 → Zoneout 확률을 0.1로 주고 사용해서 정규화시킴
- 디코더는 선형 스펙트로그램을 출력하는 dilated convolution network를 통해 실행되는 80 채널 log-mel spectrogram 에너지를 한번에 두개의 프레임으로 출력
Style Token Architecture
Reference Encoder
- RNN이 따라오는 convolution stack으로 구성
- 입력은 log-mel spectrogram이고 처음으로 여섯 개의 2D convolutional layer stack을 지난다.
- 3x3 kernel, 2x2 stride, batch normalization, ReLU
- 6개의 convolution layer에 32,32,64,64,128,128 출력 채널을 가짐
- 결과 출력 텐서는 출력 시간 해상도를 보존하면서 3차원으로 재조정되어 128-unit unidirectional GRU single layer로 입력됨
- 마지막 GRU state가 reference embedding으로 제공되고 style token layer의 입력으로 들어감
Style Token Layer
- Style token embedding 적층과 어텐션 모듈로 구성
- 기본적으로 10개의 토큰을 사용하여 학습 데이터에서 작지만 풍부한 prosodic dimension을 보여줌
- 텍스트 인코더 상태가 tanh를 사용한 것과 비슷하게 GSTs에 tanh를 어텐션 모듈에 적용되어서 더 큰 토큰 다양성이 생기기 전에 적용
- Content-based tanh attention은 softmax activation을 사용해서 토큰들에 대해 가중치 조합의 세트를 출력 (조건으로 주어지는 데에 사용되는 GST들의 weighted combination)
- 여러 조합으로 조건을 다르게 주는 실험을 하였고 style embedding을 복제해서 매 텍스트 인코더 상태에 추가하는 것이 좋은 결과를 냄을 찾음
- 유사도 측정을 위해서 content-based attention을 사용하였지만 대체해도 크게 문제가 없음
- Dot-product, location-based 혹은 어텐션 메커니즘의 조합도 다른 형태의 style token들을 학습할 수 있음
- Multi-head attention을 사용하는 것이 상당히 style transfer 성능을 올림을 보여줌
- 단지 style token의 개수를 증가시키는 것보다 훨씬 효율적
- 개의 어텐션 헤드를 사용할 시 token embedding의 크기를 로 설정해 어텐션 출력과 연결함(마지막 style embedding size는 그대로 둠)
Model Interpretation
End-to-End Clustering/Quantization
- GST 모델은 reference embedding을 기저 벡터들의 세트나 soft clusters(style tokens)로 추출하는 end-to-end 방법으로 생각될 수 있음
- 각 스타일 토큰의 기여도가 어텐션 스코어로 나타나는데 원하는 유사도 측정 방법으로 바꿀 수 있음
- GST layer는 입력의 양자화된 표현을 학습하는 면에서 VQ-VAE encoder와 개념적으로 비슷함
- GST layer를 discrete한 VQ-like lookup table layer로 바꿔서 실험을 했으나 좋은 결과가 있지는 않음
- 분해 개념은 factorized variational latent model과 같은 다른 모델에서 일반화되어서 factorized hierarchical graphical model 안에서 음성 신호의 multi-scale 특성을 명백하게 계산하는 개념
- 시퀀스 의존적인 priors는 임베딩 테이블에 의해 계산 되며 GSTs와 attention-based clustering을 제외하면 비슷함
- GSTs는 샘플이 각 prior embedding을 학습해야하는 필요성을 줄이는데 사용됨
Memory-Augmented Neural Network
- GST 임베딩은 학습 데이터로부터 추출한 스타일 정보를 저장하는 외부 메모리로 볼 수 있음
- Reference 신호는 학습할 때 메모리 쓰기를 가이드하고 inference 할 때 메모리 읽기를 가이드함
- Memory-augmented network (Graves et al.,2014)를 사용해서 GST 학습을 향상시킴
Related Works
Experiments

Speech Synthesis & Voice Cloning