Abstract
- 전통적인 concatenative, statistical parametric 접근법과 비교해서 neural network 기반의 e2e 모델은 느린 inference 속도와 합성된 음성이 robust 하지 않고(몇 개의 단어가 생략되거나 반복됨) 제어하기 어렵다(발화 속도나 운율 제어)는 문제가 있음
- Feed-forward network 기반의 transformer를 멜 스펙트로그램을 병렬적으로 생성하는 모델을 제안
- Encoder-decoder 기반의 teacher 모델로부터 attention alignment를 추출해서 phoneme duration 예측을 함
- Phoneme duration은 length regulator에서 사용되어 source phoneme 시퀀스를 병렬 멜 스펙트로그램 생성을 위한 타겟 멜 스펙트로그램 시퀀스의 길이에 맞도록 확장함
- LJSpeech 데이터셋을 이용한 실험으로 autoregressive 모델의 품질을 따라가면서 단어의 생략 및 반복을 거의 제거하고 음성 속도를 부드럽게 조정할 수 있음을 보임
Introduction
- Autoregressive하게 멜 스펙트로그램을 생성하는 방법의 특성과 멜 스펙트로그램의 긴 시퀀스 때문에 여러 가지 문제가 발생
- 멜 스펙트로그램을 생성하는 inference 속도가 느림
- RNN 기반의 모델들보다 CNN과 Transformer 기반의 TTS가 더 빠른 속도로 학습을 하지만 이전에 생성된 멜 스펙트로그램을 조건으로 줘서 멜 스펙트로그램을 생성하는 방법은 inference 속도가 느림
- 합성된 음성이 robust하지 않음
- 에러 전파와 autoregressive 생성에서 틀린 텍스트와 음성의 attention alignment가 단어 생략과 반복이 발생함
- 합성된 음성을 제어하기가 어려움
- 이전 autoregressive 모델들은 명백한 텍스트와 음성 사이의 alignment를 이용하지 않고 멜 스펙트로그램을 하나하나 자동적으로 생성함 → 음성 속도와 운율을 autoregressive한 생성에서는 직접 제어하기 어려움
- 텍스트와 음성 사이의 monotonous alignment을 고려해서 phoneme 시퀀스를 입력해 멜 스펙트로그램을 non-autoregressive하게 생성하는 모델을 제시함
- Transformer의 self-attention에 기반한 feed-forward network와 1D convolution을 채택
- 멜 스펙트로그램 시퀀스가 그에 상응하는 phoneme 시퀀스보다 훨씬 길기 때문에 두 개의 시퀀스 사이의 길이 미일치 문제를 해결하기 위해 phoneme 시퀀스를 phoneme duration(각 phoneme에 일치하는 멜 스펙트로그램의 수)에 따라 up-sampling하는 length regulator를 채택해서 멜 스펙트로그램 시퀀스 길이에 맞춤
- Length regulator는 각 phoneme의 duration을 예측하는 phoneme duration predictor 안에 내재되어 있다
- FastSpeech는 세 가지 문제들을 다룸
- 병렬적으로 멜 스펙트로그램을 생성해서 합성 과정의 속도를 많이 높임
- Phoneme duration predictor는 phoneme과 멜 스펙트로그램 사이의 alignment를 단단하게 함 → Autoregressive 모델의 automatic attention alignment와는 다름
- 에러 전파와 틀린 attention alignment를 피해서 단어 생략과 반복의 비율을 줄임
- Length regulator는 음성 속도를 phoneme duration의 길이를 길게 하거나 짧게 해서 생성된 멜 스펙트로그램의 길이를 쉽게 조절할 수 있고 인접한 phoneme들 사이에 무음 구간을 추가해서 운율을 조절할수 있음
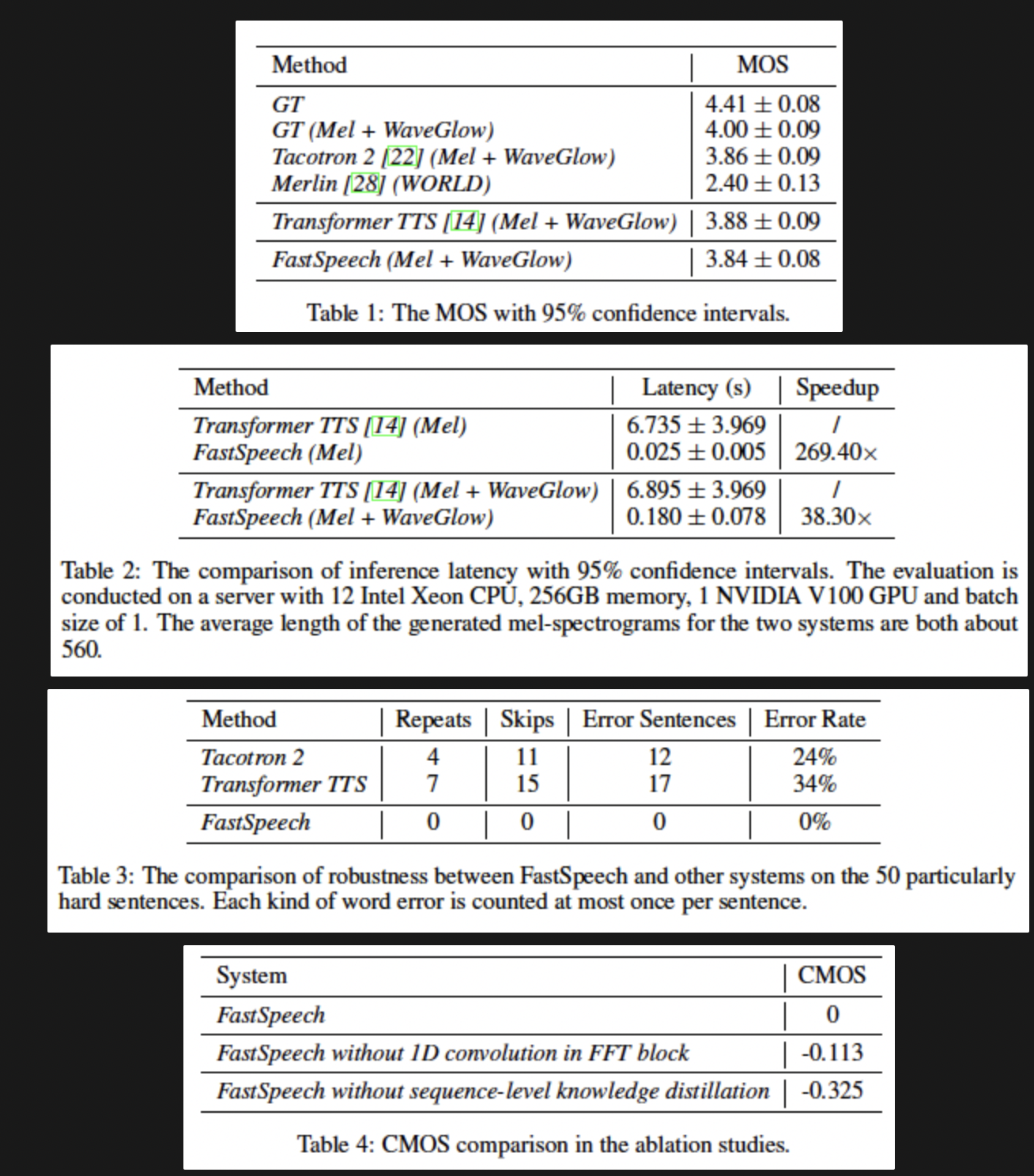
- LJSpeech 데이터셋으로 실험을 진행해서 음성 품질면에서 autoregressive Transformer 모델과 비슷한 결과를 냄
- 멜 스펙트로그램 생성 속도에서 270배 전체 음성 생성 속도에서 38배 빠른 결과를 얻음
- 단어의 생략과 반복을 대부분 제거했고 음성 속도를 쉽게 조절할 수 있음
Background
Text to Speech
- 뉴럴 네트워크 기반의 e2e TTS 모델은 텍스트를 멜 스펙트로그램과 같은 음향 특징으로 바꾼 뒤 멜 스펙트로그램을 오디오 샘플로 바꾼다.
- 하지만 대부분의 뉴럴TTS 시스템은 멜 스펙트로그램을 autoregressive하게 생성하고 inference 속도가 느리고 robustness가 부족하며 (word skipping, repeating), 제어하기 어려움(음성 속도나 운율 제어)
Sequence to Sequence Learning
- 인코더는 소스 시퀀스를 입력으로 받아서 표현의 집합을 생성함
- 디코더는 소스의 표현과 그 선행요소가 주어졌을 때 매 타겟 요소의 조건부 확률을 추정함
- 어텐션 메커니즘은 현재 요소를 예측할 떄 소스 표현의 어느 부분에 집중해야하는지 찾을 때 도입됨
- 기존의 인코더-어텐션-디코더 구조 대신 시퀀스를 병렬적으로 생성하기 위해 feed-forward network를 제안
Non-autoregressive sequence generation
- Autoregressive sequence generation과 다르게 non-autoregressive 모델은 시퀀스를 병렬적으로 생성함
- 이전 요소에 의존하는 것이 없어서 inference 과정을 빠르게 할 수 있음
FastSpeech가 이전의 non-autoregressive generation과 다른 점
- 이전 연구는 non-autoregressive 생성을 inference 속도 향상을 위해 뉴럴 기계 번역이나 오디오 합성에 사용했지만 FastSpeech는 inference 속도 증가와 robustness 증가 그리고 제어 가능도를 위해 도입
- 오디오 합성에는 병렬적으로 오디오를 생성하는 과정이 있지만 여전히 멜 스펙트로그램은 autoregressive하게 하고 있어서 fastspeech는 그런 문제를 고려하지 않아도 됨
FastSpeech
- 타겟 멜 스펙트로그램 시퀀스를 병렬적으로 생성하기 위해 새로운 feed-forward 구조를 설계해서 encoder-attention-decoder 기반의 구조를 대체함
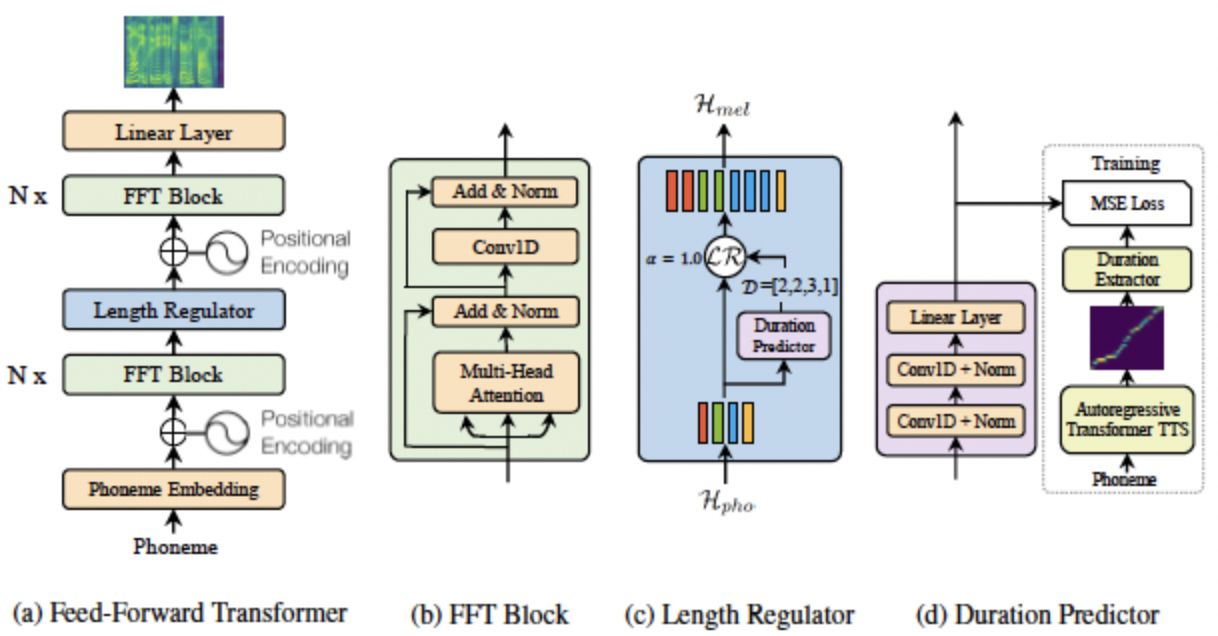
Feed-Forward Transformer
- FastSpeech는 Transformer의 self-attention 기반의 feed-forward 구조와 1D convolution으로 구성
- Fastspeech의 구조를 Feed-Forward Transformer (FFT)라고 부름
- Feed-Forward Transformer는 여러 개의 FFT 블록을 phoneme 쪽에 N개, 멜 스펙트로그램 쪽에 N개를 둠
- Phoneme과 멜 스펙트로그램 시퀀스의 길이의 차이를 연결하기 위해서 length regulator가 추가
- FFT 블럭은 self-attention과 1D conv로 이루어져 있으며 self-attention 네트워크는 cross-position 정보를 추출하기 위해 multi-head attention으로 구성됨
- Transformer의 2-layer dense network 대신 2-layer 1D convolution network와 ReLU를 사용
- 인접한 hidden state들이 character/phoneme과 멜 스펙트로그램 시퀀스에서 더 가깝게 연관되어있기 때문에
- Transformer를 따라 residual connection과 layer normalization, dropout이 self-attention 네트워크와 1D convolution 네트워크 뒤에 각각 추가됨
Length Regulator
- Feed-Forward Transformer에서 phoneme과 멜 스펙트로그램 시퀀스의 길이 차이를 해결하고 음성 속도와 운율의 일부를 제어하기 위해 사용됨
- Phoneme 시퀀스의 길이는 대개 멜 스펙트로그램의 길이보다 짧아서 각 phoneme이 여러개의 멜 스펙트로그램과 해당함
- 하나의 phoneme에 해당하는 멜스펙트로그램의 길이를 phoneme duration이라고 부름
- Phoneme duration d에 대해서 phoneme 시퀀스의 hidden state를 d배 확장하면 멜 스펙트로그램의 hidden state 길이와 일치
- : 시퀀스의 길이
- : 멜 스펙트로그램 시퀀스의 길이
- : 확장된 의 길이를 결정하는 hyperparameter
- 공백의 duration을 조절해 합성음성의 운율의 일부를 조절하도록 추가적으로 단어 사이의 공백을 제어할 수있음
Duration Predictor
- Phoneme duration 예측은 length regulator에서 중요함
- Duration predictor는 2 layer의 1D convolution과 ReLU로 구성되어 있고 layer norm과 dropout이 따라오며 스칼라 값을 출력하기 위해 linear layer가 추가되어 예측한 phoneme duration을 출력
- Duration predictor는 FFT 블럭의 phoneme 부분의 꼭대기에 쌓여서 FastSpeech 모델과 함께 MSE loss로 학습되어 각 phoneme에 대해 멜 스펙트로그램의 길이를 예측하도록 함
- 로그 도메인에서 멜 스펙트로그램의 길이를 예측해서 더 가우시안 분포를 따르고 학습하기 쉽도록 함 → 예측한 멜 스펙트로그램의 길이의 분포가 가우시안 분포가 따르게 한다?로 추측
- 학습된 duration predictor는 TTS inference 단계에서만 사용되며 학습 시에는 autoregressive teacher 모델에서 추출한 phoneme duration을 사용함
- Duration predictor를 학습시키기 위해서 autoregressive teacher TTS 모델에서 ground truth phoneme duration을 추출함
- 먼저 autoregressvie encoder-attention-decoder 기반의 Transformer TTS 모델을 학습
- 매 학습 시퀀스 쌍에 대해서 decoder-to-encoder alignment를 학습된 teacher 모델로부터 추출함
- 여러 어텐션 배열이 있음 multi-head self-attention 때문에
- 모든 어텐션 헤드가 diagonal property를 나타내진 않음
- Focus rate 를 통해서 어텐션 헤드가 얼마나 대각선에 가까운지 측정
- S: ground truth 멜 스펙트로그램 길이
- T: ground truth phoneme 길이
- : 어텐션 행렬의 s번 째 행, t번째 열 값
- 여러 개의 head 중에 focus rate F가 가장 큰 헤드를 고름
- 가장 diagonal 성분에 가까운 어텐션 헤드를 고르고 phoneme duration 시퀀스를 추출
- Phoneme의 duration은 선택된 어텐션 헤드에서 하나의 음소에 대해 집중되는 멜 스펙트로그램의 개수
Experimental Setup
Datasets
- LJSpeech dataset을 실험에 사용
- 13,100 영어 오디오 클립과 대응되는 텍스트 대본으로 약 24시간의 오디오로 학습
- 3개의 집합으로 나눠서 12500 샘플은 학습에 300개는 validation, 300개는 테스트에 사용
- 오발음 문제를 줄이기 위해서 텍스트 시퀀스를 음소 시퀀스로 바꿨고 자체적인 grapheme-to-phoneme 변환 도구를 사용
- Raw waveform을 멜 스펙트로그램으로 변환함
- frame size는 1024, hop size는 256으로 설정
Model Configuration
FastSpeech model
- 음소 부분과 멜 스펙트로그램 부분 각각 6개의 FFT 블럭으로 이루어져 있음
- 음소 사전의 크기는 51, 문장 부호를 포함
- 음소 임베딩과 self-attention의 hidden size, FFT 블록 안의 1D conv의 차원은 모두 384로 설정
- 어텐션 헤드의 개수는 두개, 2 layer conv net의 1D conv kernel size는 모두 3으로 설정
- 첫 번째 layer에서는 input 384, output 1536
- 두 번째 layer에서는 input 1536, output 384
- 출력 선형 layer는 384 차원을 80차원의 멜 스펙트로그램으로 변환
- Duration predictor의 1D conv kernel size는 3, input/output은 384/384
Autoregressive Transformer TTS model
- Duration predictor를 학습시키기 위한 타겟으로 사용할 phoneme duration을 추출
- 멜 스펙트로그램을 시퀀스 레벨의 knowledge distillation로 생성
- Li et al, 2018을 참고해서 6개 layer 인코더, 디코더를 사용하고 position-wise FFN 대신 1D conv를 사용
- Autoregressive Transformer TTS 모델은 4개 V100으로 학습, batch size는 16
- Adam optimizer
- 80k 스텝 동안 학습해서 수렴
- 텍스트와 음성 쌍을 학습 세트로 입력해고 인코더-디코더 어텐션 배열을 얻어서 duration predictor 학습에 사용
- 뉴럴 기계 번역에서 사용한 시퀀스 레벨의 knowledge distillation을 사용
- 텍스트와 autoregressive transformer TTS 모델에서 생성한 멜 스펙트로그램을 FastSpeech 모델 학습에 사용
- Fastspeech 모델과 duration predictor를 같이 학습했고 inference에서 얻은 멜 스펙트로그램은 pre-trained WaveGlow로 합성
Results
Conclusions
- 멜 스펙트로그램을 병렬적으로 생성하는 새로운 feed-forward 네트워크를 제안
- 몇 가지 주요 구성요소
- Feed-forward Transformer block, length regulator, duration predictor
- LJSpeech 데이터셋으로 실험을 진행해서 autoregressive Transformer TTS 모델과 음성 품질이 비슷했고 멜 스펙트로그램 생성 속도 면에서 270배, e2e 음성합성에서는 38배 빠른 속도를 보임
- 단어 생략과 반복 문제를 거의 제거하였고 음성 속도를 0.5배에서 1.5배까지 조절할 수 있음

Speech Synthesis & Voice Cloning