Apache Spark
Spark는 빅데이터 처리 프레임워크로 대용량 데이터 처리에 적합한 오픈소스 분산 컴퓨팅 시스템이다. 스파크는 메모리 내 처리를 통해 빠른 데이터 처리 속도를 제공하고, 스칼라로 개발되었기 때문에 스칼라와의 호환성이 매우 뛰어나다.
-
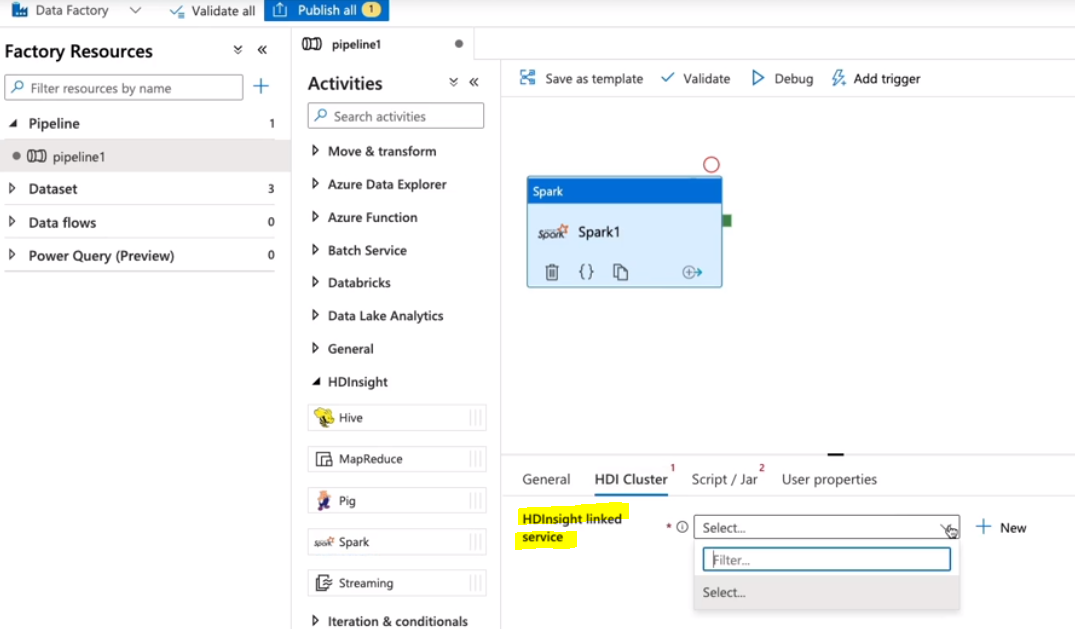
This activity executes a Spark program on either your own or on-demand HDInisght cluster.
- HDInsight : HDInsight는 Azure에서 제공하는 클라우드 기반의 서비스로, Hadoop, Spark와 같은 빅 데이터 분석 도구를 쉽게 사용할 수 있게 해준다.
-
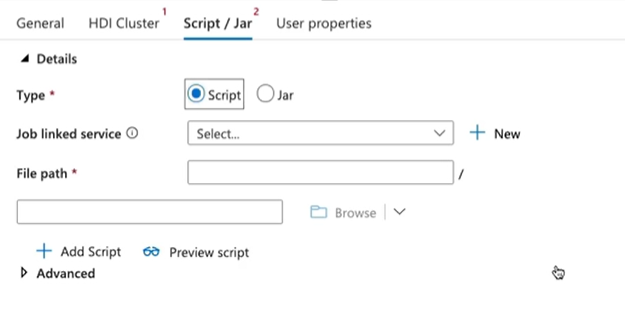
Spark jobs are more extensible, allowing you to provide multiple files such as Python scripts and jar packages.
-
Azure Data Factory를 사용하여 Spark 작업을 설정할 때, 해당 작업을 위해 필요한 Python 스크립트나 jar 파일 등을 Blob Storage에 올바른 폴더 구조로 배치해야 한다. 이러한 파일들은 런타임에 HDInsight Linked Service에 의해 참조되어 사용된다.
-
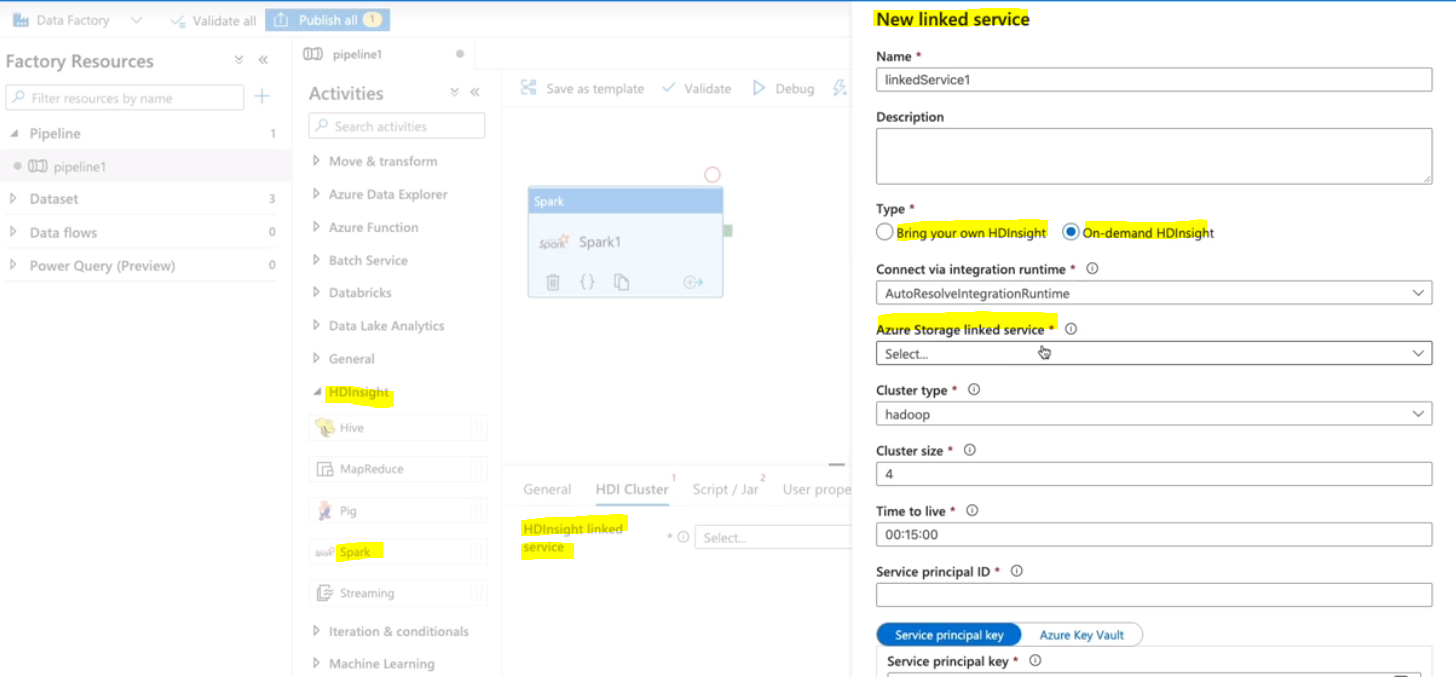
Linked Service는 Azure Data Factory에서 외부 데이터 소스나 계산 리소스를 참조하는 방법이다. 여기서 HDInsight Linked Service는 Spark 작업을 실행하기 위한 HDInsight Spark 클러스터를 참조한다.
-
Azure Blob Storage는 Azure에서 제공하는 클라우드 기반의 객체 스토리지 서비스이다. 데이터를 저장하는 공간이며, 여기서는 Spark 작업에 필요한 스크립트나 jar 파일 등을 저장하는 데 사용된다.
-
ADF는 데이터 통합 서비스로, 다양한 데이터 소스에서 데이터를 수집, 변환(ETL), 그리고 저장하는 데 사용된다. ADF에서는 HDInsight Linked Service를 통해 Spark 작업을 구성하고 실행할 수 있다.
-
-
Review
-
The Spark activity in Azure Data Factory allows you to execute Apache Spark programs on either your own or on-demand HDInsight cluster.
-
Spark job flexibility means you can provide multiple dependencies such as jar packages, Python scripts, and any other files.
