1. Azure의 데이터 엔지니어링 소개
1-1. 중요한 데이터 엔지니어링 개념
-
운영 및 분석 데이터
- 운영 : 애플리케이션에서 사용하는 트랜잭션 데이터
- 분석 : 분석 및 보고에 최적화
-
스트리밍 데이터
영구, 실시간 데이터 피드 -
데이터 파이프라인
- 데이터를 전환하고 변환하는 오케스트레이션된 활동이다.
- ETL(추출,변환,로드)/ELT(추출,로드,변환) 작업 구현에 사용된다.
-
데이터 레이크
- 파일에 저장된 분석 데이터
- 대규모 확장성을 위한 분산 스토리지
- MS에서 제공하는 데이터 레이크는 "ADLS Gen2 + Azure Synapse Analytics"
-
데이터 웨어하우스
- 관계형 데이터베이스에 저장된 분석 데이터
- 일반적으로 요약 분석을 최적화하기 위해 별모양 스키마로 모델링된다.
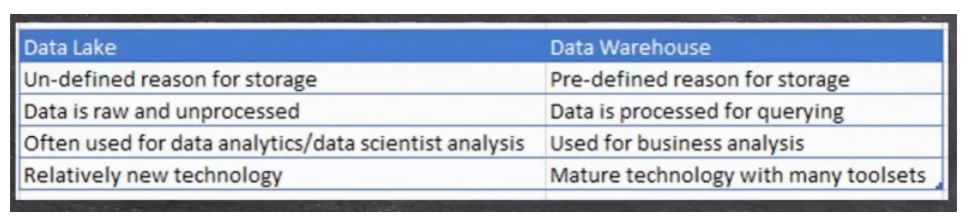
데이터 레이크와 데이터 웨어하우스의 차이
"Data Lake is NOT Data Warehouse"
-
아파치 스파크
분산 데이터 처리를 위한 오픈 소스 엔진
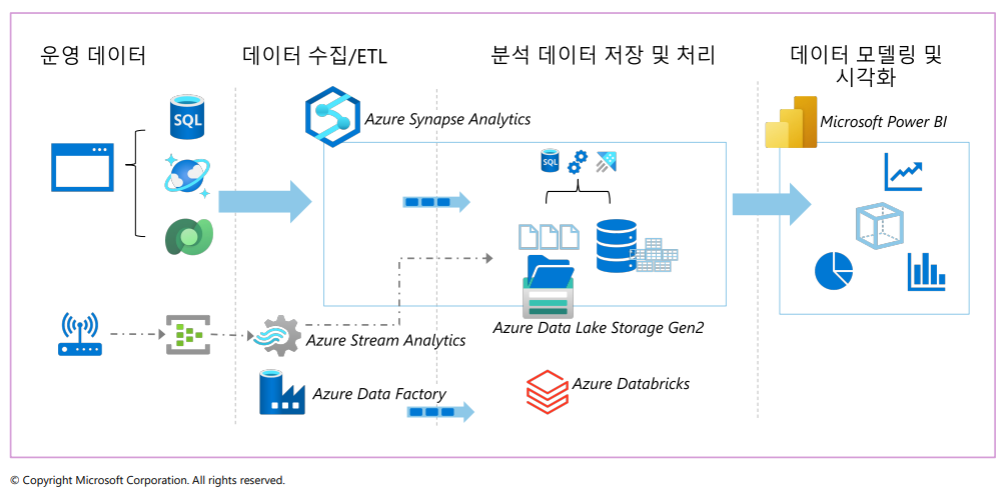
1-2. Azure의 데이터 엔지니어링
2. Azure Data Lake Storage Gen2
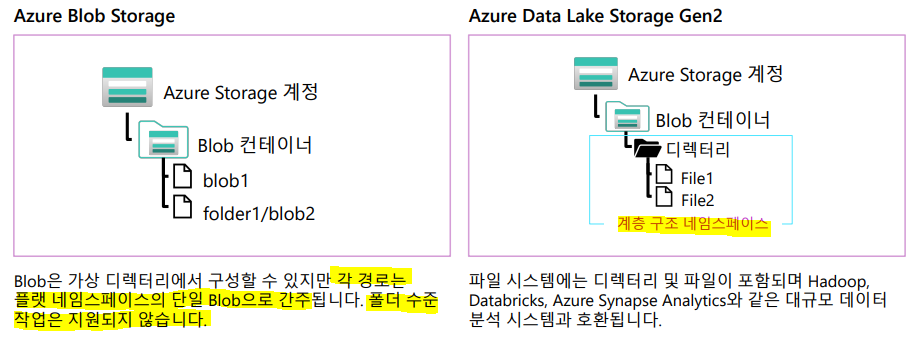
2-1. ADLS Gen2 와 Azure Blob Storage 비교
데이터 레이크용 분산 클라우드 스토리지로 Azure Blob Storage에서 "계층형 네임스페이스" 를 활성화하면 ADLS Gen2가 생성된다.
ADLS Gen2가 데이터를 저장하는 곳은 "Azure Blob Storage에서 호스트되는 HDFS 호환 파일 시스템" 이다.
3. Azure Synapse Analytics

3-1. 서비스 구성
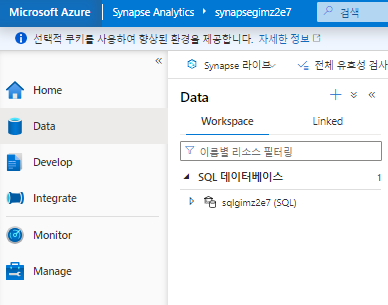
Data 허브
- Workspace 탭 : 작업 공간에 정의된 데이터베이스를 포함하는 탭(전용 SQL 데이터베이스 및 데이터 탐색기 데이터베이스 포함)
- Linked 탭 : Azure Data Lake Storage를 포함하여 workspace에 연결된 데이터 원본이 포함되는 탭
Develop 허브
데이터 처리(data processing) 솔루션을 개발하는 데 사용되는 스크립트 및 기타 자산(assets)을 정의할 수 있다.
Integrate 허브
이 허브를 사용하여 데이터 수집(data ingestion) 및 통합 자산(integration assets)을 관리한다. 데이터 소스 간에 데이터를 전송하고 변환하는 파이프라인과 같은 것이다.
Monitor 허브
you can observe data processing jobs as they run and view their history.
Manage 허브
여기에서 Azure Synapse workspace에서 사용되는 풀, 런타임 및 기타 자산을 관리합니다. Analytics pools 섹션에서 각 탭을 보고 workspace에 다음 풀이 포함되어 있는지 확인합니다.
1) Analytics pools > SQL pools
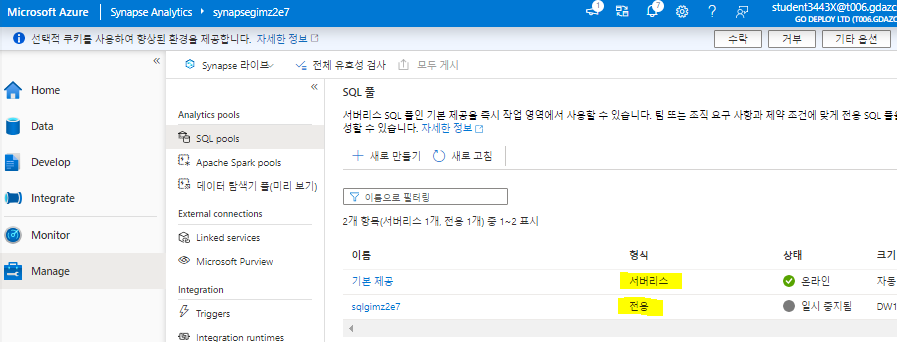
-
Built-in: A serverless SQL pool
you can use on-demand to explore or process data in a data lake by using SQL commands.
데이터를 쿼리하는 가장 일반적인 방법 중 하나는 SQL을 사용하는 것이며, Synapse Analytics에서는 서버리스 SQL 풀을 사용하여 데이터 레이크의 데이터에 대해 SQL 코드를 실행할 수 있다.
-
A dedicated SQL pool
that hosts a relational data warehouse database.
지금까지 데이터 레이크에서 파일 기반 데이터를 탐색하고 처리하는 기술을 살펴보았습니다. 많은 경우, 엔터프라이즈 분석 솔루션은
-
데이터 레이크를 사용하여 비정형 데이터를 저장하고 준비한 다음
-
BI(비즈니스 인텔리전스) 워크로드를 지원하기 위해 관계형 데이터 웨어하우스에 로드할 수 있습니다.
Azure Synapse Analytics에서 이러한 데이터 웨어하우스는 전용 SQL 풀로 구현할 수 있다.
-
2) Analytics pools > Apache Spark pools
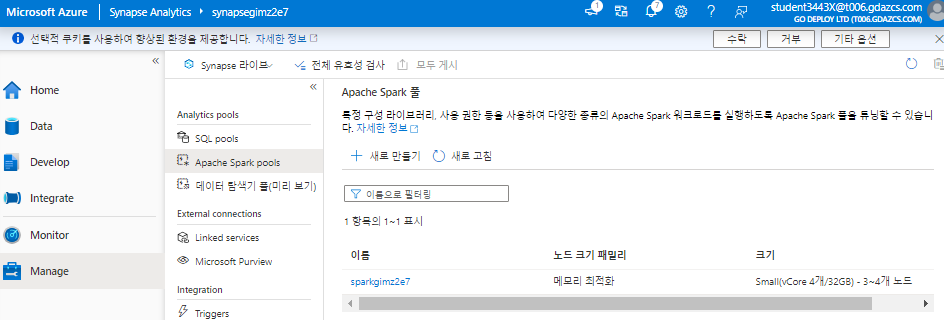
that you can use on-demand to explore or process data in a data lake by using programming languages like Scala or Python.
Synapse Analytics에서는 SPARK 풀 에서 Python(및 기타) 코드를 실행할 수 있다. Apache Spark를 기반으로 하는 분산 데이터 처리 엔진을 사용한다.
3) Analytics pools > Data Explorer pools
KQL(Kusto Query Language)을 사용하여 데이터를 분석하는 데 사용할 수 있는 데이터 Explorer풀
