
Structured vs. Unstructured Data
| SQL | NoSQL |
|---|---|
| Relational | Non-Relational |
| Fixed Schema | Dynamic |
| Complex Queries | Not for Complex Queries |
| Vertical Scaling 수직 확장 (RAM, CPU 추가) | Horizontal Scaling 수평적 확장 |
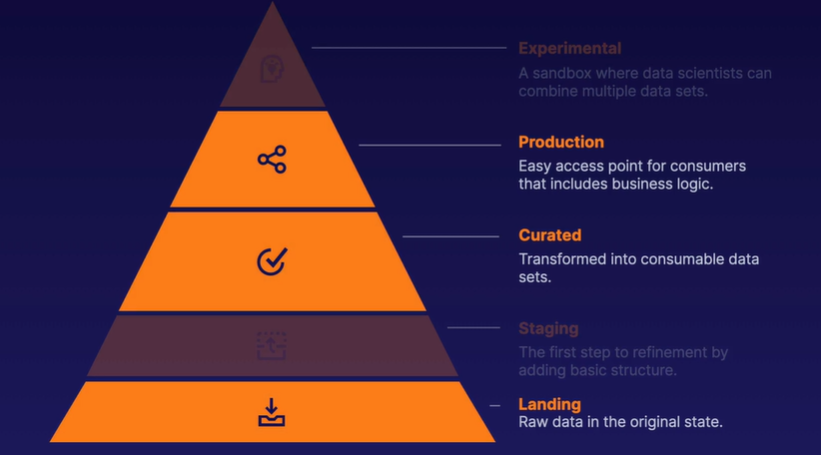
Data Warehouse, Data Lake, Data Mart
Data Warehouse 와 Data Mart
데이터 소스
--ETL-->데이터 웨어하우스 (장기 보존용으로 정리한 테이블)--ETL-->데이터 마트 (분석용으로 일부를 추출한 테이블)
데이터 파이프라인 기본형
데이터 웨어하우스는 일반적인 RDB와는 달리 '대량의 데이터를 장기 보존하는 것' 에 최적화되어 있다. 정리된 데이터를 한 번에 전송하는 것은 뛰어나지만, 소량의 데이터를 자주 읽고 쓰는 데는 적합하지 않다.
데이터 분석과 같은 목적에 사용하는 경우에는 '데이터 웨어하우스에서 필요한 데이터만을 추출하여 데이터 마트를 구축'한다.
데이터 웨어하우스와 데이터 마트 모두 SQL로 데이터를 집계한다. 따라서, 먼저 테이블 설계를 제대로 정한 후에 데이터를 투입한다. 그렇기에 데이터 웨어하우스를 중심으로 하는 파이프라인에서는 테이블 설계와 ETL 프로세스가 중요하다.
Data Lake 와 Data Mart
데이터를 그대로 축적
빅데이터의 시대가 되면 모든 데이터가 데이터 웨어하우스를 가정해서 만들어지지는 않는다. 우선 데이터가 있고, 나중에 테이블을 설계하는 것이 빅데이터다.
모든 데이터를 원래의 형태로 축적해두고 나중에 그것을 필요에 따라 가공하는 구조가 필요하다. 이러한 데이터의 축적 장소를 '데이터 레이크'라고 한다. 구체적으로는 임의의 데이터를 저장할 수 있는 분산 스토리지가 데이터 레이크로 이용된다.
데이터 레이크와 데이터 마트 (필요한 데이터는 데이터 마트에 정리)
데이터 레이크는 단순한 스토리지이며, 그것만으로는 데이터를 가공할 수 없다. 그래서 사용되는 것이 MapReduce 등의 분산 데이터 처리 기술이다.
데이터 분석에 필요한 데이터를 가공, 집계하고 이것을 데이터 마트로 추출한 후에는 데이터 웨어하우스의 경우처럼 데이터 분석을 진행할 수 있다.
Data Lake Zones 와 Folder Structure 전략
Data Lake Zone and Folder Structure help represent various level of data transformation.
Data Lake Zone 구조를 갖게 되면, 그 안에 Folder 구조를 개발하기 시작한다.
Data Lake Zone
Folder Structure 전략
Folder Structure can affect query performance, security, data pruning and administrative maintenance.
- Naming convention should be human-readable, easily understood, and self-documenting.
- 불필요한 유지 관리 오버 헤드를 발생시키지 않으면서, 효과적인 권한 부여를 위해 적절하게 세분화되어 설계되어야 한다.
- 작업 중인 Zone의 목적에 맞는 Partition 전략
- 유사한 항목들을 그룹화, Folders should contain files of the same schema and format.
Available File Types
데이터 레이크는 모든 유형의 데이터를 저장할 수 있지만, 대용량 데이터 처리를 위해 빅데이터 처리를 위해 디자인된 유형을 사용하는 것이 좋다.
row-based (Avro) 또는 columnar storage (Parquet / ORC) 가 필요한지 여부에 따라 결정하게 된다.
Option 1 : Avro
Avro는 데이터 직렬화 시스템으로, 데이터를 직렬화하고 역직렬화하는 데 사용됩니다. 또한 스키마를 통해 데이터의 구조를 정의하고 전송합니다.
*데이터 직렬화 : 데이터 직렬화는 데이터를 특정 형식으로 변환하여 전송이나 저장에 용이하게 만드는 프로세스를 나타냅니다. 이는 메모리에 있는 객체나 데이터를 파일에 쓰거나 네트워크를 통해 전송할 때 사용됩니다. 직렬화된 데이터는 이후에 역직렬화하여 다시 원래의 형태로 복원할 수 있습니다.

-
Row-Based Storage
All record data is stored together. -
Schema Stored in JSON
Easy for humans to read. -
Data Stored in Binary
Easy for computers to read.
Benefits of Avro
-
Easily handles schema changes
JSON 형식의 스키마를 가지고 있기 때문에 스키마를 쉽게 변경할 수 있다. -
Great for write-heavy workloads
Row-Based(행 기반) 이기 때문에 쓰기 중심의 작업에 아주 적합하다. -
Great for ETL operations that need all columns
Avro가 ETL 작업에 유용하다. Avro의 특징 중 하나는 스키마에 모든 열 정보를 포함할 수 있다는 것이다. 따라서 ETL 작업에서 모든 열의 데이터를 효율적으로 처리하고 전송하기에 적합하다.
Option 2 : Parquet
Parquet은 데이터 저장 포맷으로, 컬럼 지향 방식을 사용하여 대량의 데이터를 효율적으로 저장하고 처리할 수 있도록 설계되었습니다.
*데이터 저장 포맷 : 데이터 저장 포맷은 데이터를 파일이나 메모리에 저장하는 방식을 나타냅니다. 특정 데이터 구조를 따르고, 읽고 쓰기가 효율적인 형식으로 데이터를 저장합니다. 이러한 형식은 데이터베이스, 파일 시스템, 분산 시스템 등에서 사용됩니다.

-
Columnar Storage
Values of each column type are stored together.
데이터를 컬럼 단위로 저장합니다. 이는 쿼리에서 필요한 열만 읽어오기 때문에 읽기 성능이 향상되고, 필요한 데이터만 읽어오는 효율성이 증가합니다. -
Nested Data Structure (중첩된 데이터 구조)
Nested fields can also be read individually. 중첩된 데이터를 사용하면 데이터의 계층 구조를 유지하면서 필요한 부분만 효율적으로 읽고 쓸 수 있다.중첩된 데이터 구조는 데이터의 한 부분이 다른 부분 안에 중첩되어 있는 경우를 의미합니다. 예를 들어, 리스트 안에 또 다른 리스트가 있는 경우, 그리고 그 안에 또 다른 데이터 구조가 있다면 이는 중첩된 데이터 구조입니다.
예시: user.parquet
name age address contacts John 30 {street: '123 Main St', [{type: 'email', value: 'john@example.com'}, city: 'Anytown', {type: 'phone', value: '555-1234'}] zipcode: '12345'} user라는 레코드가 있고, 그 안에 address와 contacts라는 중첩된 필드가 있다. 이것은 가독성을 위한 표현이며, Parquet 파일 자체는 이진 형식으로 되어 있다.
-
Data Stored in Binary
Easy for computers to read.
Benefits of Parquet
- Gread for wide-column queries
- Efficient for read-heavy workloads
일반적으로 분석을 위한 훌륭한 선택이다. 특히 읽기 성능이 중요한 Curated Zone에서 더욱 그렇다. - Easily queries a subset of columns or nested data
Option 3 : ORC (Optimized Row Columnar)
- Columnar Storage & Stripes
Collections of rows that contain row data in columnar foramat. (Parquet 처럼 열 기반 저장을 사용하지만, Stripe를 사용하므로 열 형식의 행 데이터를 포함하는 행들의 집합이다.) - Data Stored in Binary
Easy for computers to read.
Benefits of ORC
-
ACID 속성을 지원한다.
ACID는 *트랜잭션을 정의하는 4가지 중대한 속성을 가리키는 약어입니다. 즉 원자성(Atomicity), 일관성(Consistency), 격리성(Isolation), 영속성(Durability)을 의미합니다.*트랜잭션
데이터베이스와 데이터 스토리지 시스템이라는 맥락에서 트랜잭션이란 한 단위의 작업으로 취급되는 모든 작업을 말합니다. 트랜잭션은 완전히 완료되기도 하고 전혀 완료되지 않을 수도 있으며, 스토리지 시스템을 한결같은 상태로 둡니다. 트랜잭션의 전형적인 예는 은행 계좌에서 현금을 인출할 때 일어나는 일입니다. 현금이 계좌에서 인출되거나, 인출되지 않거나 둘 중의 하나일 뿐 그 중간 어딘가의 상태란 없습니다.
-
Compress more efficiently
-
Stripe enable large, efficient read
Comparing the Options
| Avro | Parquet | ORC | |
|---|---|---|---|
| Analytical Query | O | O | |
| Write Operations | O | ||
| Nested Data | O | ||
| ACID | O | ||
| Schema Evolution | O |
Avro vs. Parquet
Avro는 데이터 직렬화에 중점을 둔 반면, Parquet은 데이터를 저장하고 처리하는 데 특화된 형식입니다. 두 기술은 대체로 함께 사용되는 경우가 많아서 헷갈릴 수 있습니다.
예를 들어, Apache Spark와 같은 분산 데이터 처리 시스템에서는 Avro나 Parquet과 같은 형식을 사용하여 데이터를 효과적으로 다룹니다.
Parquet vs. ORC
Parquet과 ORC 모두 columnar storage를 사용한다. 하지만, Parquet은 단순히 컬럼 기반으로 물리적으로 나뉜 블록만 존재하는 반면, ORC는 더 큰 단위인 Stripe를 도입하여 데이터를 조직하고 관리한다. 블록은 특정 컬럼에 해당하는 값들을 함께 저장하는 단위로 사용된다.
Stripe는 같은 row에 해당하는 여러 컬럼의 값을 함께 묶는 논리적인 단위로 사용된다. 즉, ORC 파일은 블록과 Stripe를 함께 사용하여 데이터를 효과적으로 구성한다. 그러나 Parquet에서는 ORC의 Stripe와 같은 명시적인 논리적인 블록이 없다.
