Distributing Data
Data Distribution 이란
Data Distribution, 데이터 분산은 주로 물리적인 데이터의 저장 및 처리를 여러 노드 또는 서버에 분산시키는 것을 의미한다. 이것은 데이터에 대한 처리 부하를 분산하고 성능을 향상시키기 위한 목적으로 사용된다.
Azure Synapse는 데이터를 60개의 기본 데이터베이스 또는 distributions 에 분산시킨다. 이것은 대규모 병렬 처리 시스템의 일부로 자동으로 수행되며, 관리하거나 접근할 수 없는 것이다.
목표
The goal is to distribute in such a way that data movement is minimized.
Distribution의 목표는 데이터 이동(data movement)을 최소화하면서 동시에 데이터를 균등하게 분산시키는 것이다.
데이터 이동(data movement) 란
데이터 이동(data movement)이 의미하는 것은 데이터를 섞고, 쿼리의 결과를 만족시키기 위해 네트워크를 통해 다른 Distribution에서 데이터를 가져오는 것이다. 이는 조인과 같은 쿼리가 해당된다. 이를 제대로 처리하지 못하면 네트워크 비효율성, 증가된 I/O, 느린 쿼리 등의 부정적인 효과를 초래할 수 있다.
Partitioning 과 차이점
Data Distributions은 파티셔닝과는 다르다. 파티셔닝은 유사한 데이터를 함께 접근하기 위해 그룹화하는 것에 더 초점을 맞추고 있다. 반면 Distribution는 하드웨어 저장 개념으로 더 많이 생각될 수 있다.
| 파티셔닝 | 분산 |
|---|---|
| 데이터베이스 또는 테이블을 더 작은 단위로 분할하는 프로세스 | 데이터를 여러 컴퓨터 또는 노드 간에 물리적으로 분배하는 것을 의미 |
| 주로 단일 데이터베이스 시스템 내에서 데이터를 조직화하는 데 사용됨 | 주로 데이터베이스나 파일시스템의 확장성과 가용성을 향상시키기 위해 사용됨 |
| 데이터를 물리적으로 분리하지만, 모든 파티션은 여전히 같은 데이터베이스 관리 시스템(DBMS) 내에서 관리됨 | 데이터를 여러 서버에 걸쳐 저장하며, 단일 서버의 부하를 줄이고, 시스템의 장애 허용량(fault tolerance)을 증가시키며, 데이터 액세스 속도를 향상시킬 수 있음 |
차이점
| 파티셔닝 | 분산 | |
|---|---|---|
| 목적과 범위 | 데이터베이스 안에서 데이터 관리와 쿼리 성능 최적화 | 데이터의 확장성, 가용성 및 장애 허용 능력을 향상시키기 위해 여러 서버 또는 위치에 데이터를 분배 |
| 물리적 위치 | 단일 시스템 내에서 데이터를 분할 | 데이터를 여러 물리적 위치에 걸쳐 저장 |
그렇다면, 파티셔닝과 데이터 분산은 어떤 식으로 함께 작동하는 걸까,
두 전략은 종종 함께 사용되어 데이터베이스나 데이터 레이크의 성능, 확장성 및 관리 효율성을 극대화한다.
예를 들어, 대규모 데이터베이스 시스템에서는 파티셔닝을 통해 관련된 데이터를 동일한 노드나 서버에 논리적으로 그룹화할 수 있다. 이것은 데이터를 논리적으로 관리하고 효율적으로 접근하기 위한 목적으로 수행된다.
동시에, 데이터 분산은 이러한 그룹화된 데이터를 여러 노드에 효과적으로 물리적으로 분산하여 전체 시스템의 성능을 향상시킨다. 데이터 분산은 데이터를 여러 서버 또는 노드에 분산하여 전체 시스템에서 성능을 향상시키는 것을 목표로 한다.
일반적으로 단일 노드 내에서 파티셔닝을 수행하고, 그 후에 데이터 분산이나 샤딩과 같은 메커니즘을 사용하여 데이터를 여러 노드로 물리적으로 분산시킬 수 있다.
또한, 파티셔닝과 데이터 분산은 데이터베이스 쿼리 성능을 향상시키는 데 도움이 된다. 관련된 데이터를 함께 처리하고, 분산된 데이터를 병렬로 처리함으로써 전반적인 시스템 성능을 향상시킬 수 있다.
3 Types of Distribution
- Round-Robin Distributed : 데이터가 무작위로 고르게 분산
- Hash Distributed : 데이터가 hash function에 의해 분산
- Replicated : A full copy of the table is replicated to every Compute Node
1) Round-Robin (기본 옵션)
Data is distributed evenly in a random fashion.
-
Even Distribution Across Databases, 데이터베이스 전체에 걸쳐 균등한 분포이다.
The assignment of row is random.
처음에는 행을 무작위로 할당하고, 그 다음부터는 순차적으로 할당한다.
이는 특정 분포에 있는 데이터가 그곳에 있는 다른 데이터와 관련이 없을 수도 있다는 것을 의미한다.
-
Loads(적재)에 대한 빠른 성능을 얻을 수 있다.
Row assignment can be performed quickly.
따라서, 데이터를 가능한 빨리 로드하고 싶은 스테이징 테이블 같은 것들에 Round-Robin 방식이 좋다.
스테이징 테이블은 데이터를 임시로 저장하고 처리하는 공간으로 사용된다. Round-Robin 방식을 통해 데이터를 스테이징 테이블에 분산시키면, 데이터 적재 과정에서 발생할 수 있는 병목 현상을 줄이고, 전체적인 데이터 처리 속도를 향상시킬 수 있다. 이는 대량의 데이터를 빠르게 처리해야 하는 ETL 작업이나 데이터 마이그레이션, 데이터 통합 작업에서 특히 유용하다.
-
Reads(읽기) 성능이 느려질 수 있다.
데이터가 논리적인 그룹으로 배치되지 않았기 때문에 data movement가 발생할 가능성이 크다. 즉, 쿼리를 수행하기 위해 여러 분포에서 정보를 추출해야 할 가능성이 크다.
Round-Robin 이 적합한 경우는
- distribution key가 명확하지 않을 때
Hash Distributed 에 잘 작동하는 것이 없다면 Round-Robin은 좋은 선택이다. - 다른 테이블과 자주 발생하는 join이 없어서, 다른 영역에서 데이터를 가져오지 않을 때
- 균일한 분포(uniform distribution)을 원할 때
- 임시 staging table : 정보를 빠르게 로드하여 필요한 곳에 무작위로 배치하기 때문
- Distribution을 처음 시작하기 위해 단순한 시작점이 필요할 때
2) Hash
Data is distributed deterministially by using a hash function.
-
Distribution is Deterministic, 데이터가 열의 해시 값에 따라 분배된다는 것을 의미한다.
Data is distributed by the hash value of a column.
해시 키에 대한 같은 데이터 값과 데이터 유형을 가진 행은 해시 값이 동일하기 때문에 항상 같은 distribution에 할당된다.
-
The Distribution Column Cannot Be Changed
The Distribution Column 을 변경하려면 테이블을 다시 생성해야 한다.
해시 키를 만들 적합한 컬럼을 선택하는 방법
-
Has many unique values
행들을 많은 distributions에 퍼뜨리는 데 도움이 된다. -
NULL 값이 거의 없거나 전혀 없는 것
NULL 값들은 모두 동일한 해시 값으로 평가되므로 모두 같은 버킷에 들어가게 되면서 매우 불균형하게 분포된 행들이 나타날 수 있다. -
날짜 컬럼이 아닌 것
하루에 많은 양의 데이터가 있고 다른 날에는 데이터가 없는 경우 마찬가지로 매우 불균등하게 분포될 것이다. 그래서 날짜 열을 피하는 것이 아마 가장 좋을 것이다.
Hash 가 적합한 경우는
-
Large Table
Large 라는 말은 디스크 상의 테이블 크기가 2GB보다 크다는 것을 의미한다.
(예. Large Fact Tables, Historical Transactions Tables, Large Dimension Tables)
-
INSERT, UPDATE, DELETE 가 자주 발생하는 테이블
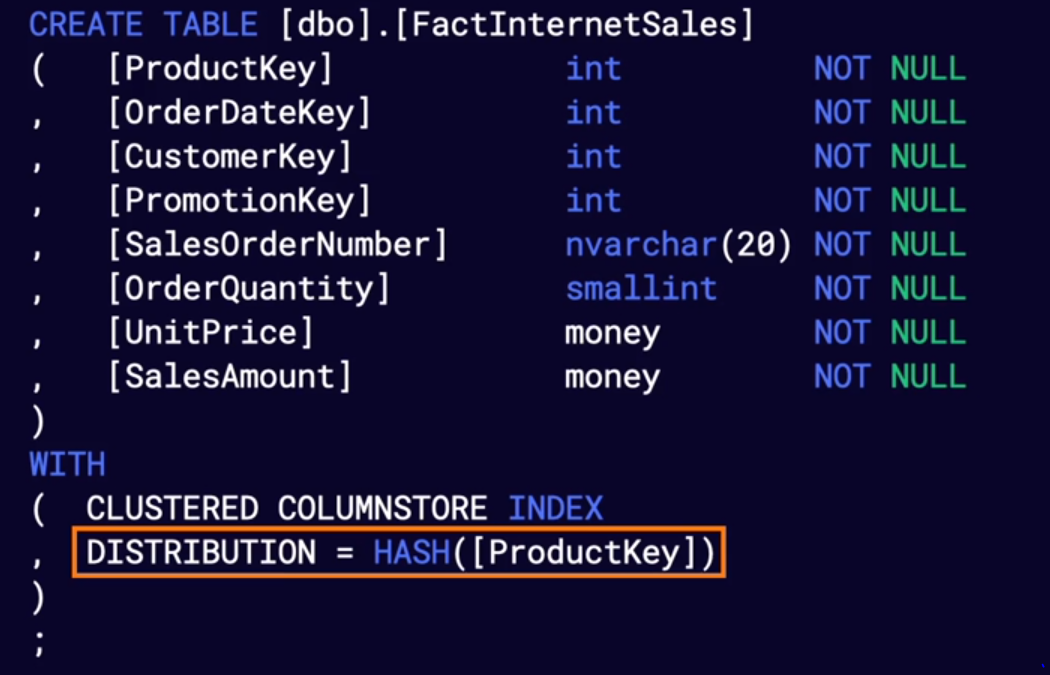
HASH 테이블 생성 예시
3) Replicated
A full copy of the table is replicated to every Compute Node.
-
모든 Node로 Full Table 을 복사한다.
Elimnates the need to transfer this data for queries.
쿼리를 위해 데이터를 전송할 필요를 제거한다.
-
저장 공간에 영향을 미친다.
This option requires extra storage and incurs overhead for wirtes.
모든 Node에 복사하기 때문에 추가적인 저장 공간을 차지하고, 쓰기에 대한 오버헤드를 초래한다.
-
일반적으로 Replicated 는 다른 방법들과 함께 사용된다.
Replicated 가 적합한 경우는
-
Small lookup or dimension tables that are frequently joined with larger tables.
큰 테이블과 자주 조인되는 작은 dimension(차원) 또는 lookup(조회) 테이블
Review
-
Azure Synapes는 자동으로 데이터에 대해 60개의 distributions(분포)를 생성하고 관리한다.
-
일반적으로 라운드 로빈과 해시 중에서 선택하게 된다.
You will normally choose between round-robin, which distributes randomly, or hashed, which distributes deterministically.
-
Replicated 는 큰 테이블과 자주 조인되는 작은 양의 정보에 유용할 수 있다.
Replicated tables can be useful for small amounts for information that are frequently joined with larger tables.
