Partitioning in Azure Synapse
How Partitioning Works
-
Azure Synapse 는 Massively Parallel Processing (대규모 병렬 처리 시스템) 이다.
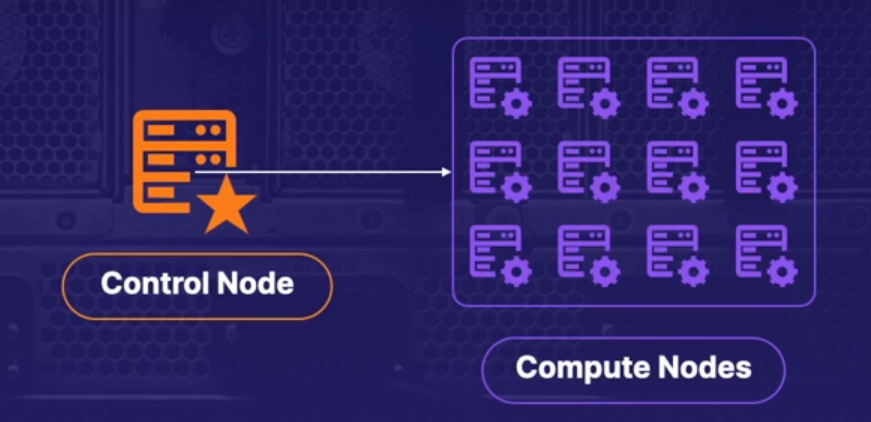
Clients connect to a Control node, which passes the distributed query to Compute nodes. Those execute the work in parallel.클라이언트들을 Control node에 연결하고 , 컨트롤 노드가 쿼리를 최적화하고 그것을 여러 Compute node에 전달하며, 그 노드들이 병렬로 작업을 실행한다는 의미다.
-
Azure Synapse는 기본적으로 분산되어 있다. (distributed by default)
The data is automatically distributed across 60 underlying databases or distributions. 따라서, 수행되는 모든 파티셔닝은 이러한 기본 분포에 추가되는 것이기 때문에 데이터를 너무 얇게 퍼뜨리지 않도록 신경 써야 한다.예를 들어, 만약 100개의 파티션을 생성하기로 결정했다면, 실제로 그것을 60개의 분포로 곱해야 하므로 총 6,000개의 파티션을 얻게 된다.

Best Practices
-
Scope queries to as few partitions as possible.
데이터 쿼리를 수행할 때 가능한 한 적은 수의 파티션을 대상으로 하라.쿼리가 적은 수의 파티션에만 접근하면, 쿼리 실행 시 필요한 데이터 양이 줄어들고, 결과적으로 쿼리 성능이 향상된다. 예를 들어, 특정 날짜 범위에 해당하는 데이터만 쿼리하는 경우, 해당 기간에 해당하는 파티션에만 접근하도록 쿼리를 조정함으로써 불필요한 데이터 스캔을 줄일 수 있다.
-
Avoid cross-partition joins or transactions.
파티션 간 조인(join)이나 트랜잭션(transaction)을 가능한 피하라.파티션 간 조인이나 트랜잭션은 다수의 파티션에 걸쳐 데이터를 검색하고 처리해야 하므로, 이는 처리해야 할 데이터의 양을 크게 증가시키고, 네트워크 트래픽을 증가시키며, 전반적인 성능 저하를 초래할 수 있다. 따라서, 설계 단계에서 이러한 상황을 피하기 위해 데이터 모델을 최적화하고, 필요한 경우 데이터를 미리 집계하여 쿼리가 단일 파티션 내에서 완결될 수 있도록 하는 것이 좋다.
-
Utilize Partition Operations
Insert, Update 또는 Delete 대신 partiton switching, merging, deletion 을 사용하여 파티션을 최대한 활용할 것 -
과도하게 파티션을 나누지 말 것
Review
-
파티션을 생성할 때 Azure Synapse 에는 이미 60개의 distributions이 포함되어 있다는 것을 기억해야 한다.
-
Partiton switching, merging, deletion을 활용하라
-
Crossing Partitions 으로 인해 발생하는 성능상의 함정을 피해야 한다.
