NLP 전처리에 대한 논문이다. 정확히는 부족한 데이터셋을 채울 수 있는 데이터증감에 대한 논문이다.
따라서 EDA를 사용하면 EDA -> Embedding -> model training -> ... 의 순서로 적용될 것 같다.
1. Introduction
EDA는 4개의 operation을 가지고 있다.
- Synonym replacement
- random insertion
- random swap
- random deletion
EDA는 특히 작은 dataset에서 좋은 효과를 보여준다.
해당 논문은 EDA라 일컺는 단순하면서도 보편적인 NLP 데이터증감 방법을 제시한다.
2. EDA
EDA는 Computer Vision에서의 증감방식에서 영감을 얻었다.
1. Synonym Replacement (SR) :
문장에서 "stop word"가 아닌 단어를 n개 고른다.
각 단어를 무작위로 선택된 동의어로 교체한다.
( stop word : is, a, the 처럼 빈번히 등장하지만 문맥적으로 중요하지 않아 일반적으로 전처리 과정에서 제거되거나 무시되는 단어. )
2. Random Insertion (RI) :
문장 내에서 "stop word"가 아닌 단어를 무작위로 고른다.
그것의 동의어를 무작위로 선정한다.
선정된 동의어를 문장 내에 무작위로 배치한다.
해당 과정을 n회 반복한다.
3. Random Swap (RS) :
문장 내의 두 단어를 무작위로 고르고 둘의 위치를 교환한다.
이것을 n회 반복한다.
4. Random Deletion (RD) :
문장 속 무작위로 지정된 단어를 p의 확률로 제거한다.
문장이 길수록 단어가 더 많기에 원래의 class label을 유지하며 더 많은 noise를 흡수할 수 있다.
이를 보상하기 위해, n의 값을 다양하게 바꿔준다.
SR, RI, RS에 대해서 "n = al"이다.
(a: 문장의 단어가 몇 % 변경되었는지를 나타내는 매개변수, l: 문장의 길이)
더 나아가, 각 Original Sentence에 대해 n_aug개의 증감된 문장을 생성한다.
3. Experimental Setup
EDA의 성능 평가를 위해 5개의 benchmark test classification task와 2개의 network architecture를 준비한다.
3.1 Benchmark Dataset
준비된 5개의 dataset은 다음과 같다.
(1). SST-2: Stanford Sentiment Treebank
(2). CR: Customer Review
(3). SUBJ: Subjectively/Objectively dataset
(4). TREC: Question type dataset
(5). PC: Pro-Con dataset
+) Paper는 EDA가 작은 dataset에서 더 효과적일 것이라 가정했기에 dataset의 크기를 다양하게 준비했다.
3.2 Text Classification Models
준비된 2개의 모델은 다음과 같다.
1. LSTM-RNN
2. CNN
4. Results
4.1 EDA Makes Gains

Dataset이 작을수록 EDA가 더 효과적임을 알 수 있다.
Augmentation이 부족한 양의 Dataset을 채우는 용도이기 때문에 그런 결과가 나왔다고 생각한다.
4.2 Training Set Sizing
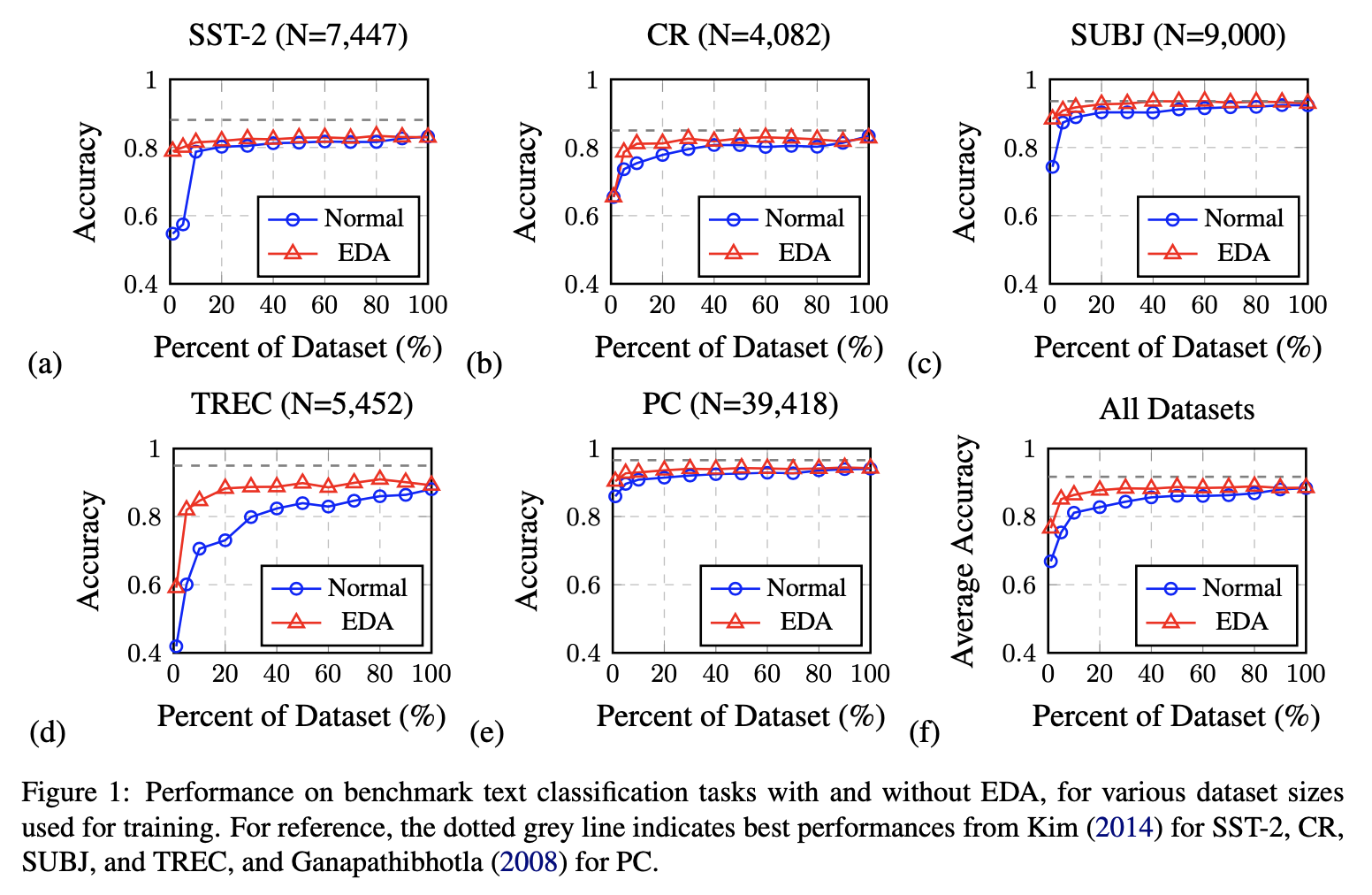
마찬가지로 Original Dataset이 작을수록 EDA가 효과적이였다.
4.3 Does EDA Conserve True Labels?
Augmentation 과정에서 문장이 너무 바뀌면, Original Class Label이 더 이상 유효하지 않을 수 있다.
우리는 시각화를 통해 EDA가 Original Class Label의 유효성을 훼손하는지 검사하도록 한다.
과정은 다음과 같다.
1. Pro-Con Classification (PC) task에 RNN model을 훈련시킨다.
2. n_aug = 9인 EDA를 testset에 적용시킨다. (이는 Original sentence와 함께 RNN에 들어간다.)
3. 마지막 dense layer의 output을 extract한다.
4. 3의 출력 vector에 t-SNE를 적용, 2D representation으로 시각화한다.

산점도를 보니 큰 변동없이 label이 겹쳐진다.
즉, EDA가 true label을 보존하는 것을 알 수 있다.
4.4 Ablation Study
(Ablation study: 주로 머신러닝이나 딥 러닝에서 모델의 구성 요소가 결과에 미치는 영향을 평가하기 위해 사용되는 실험적인 방법)
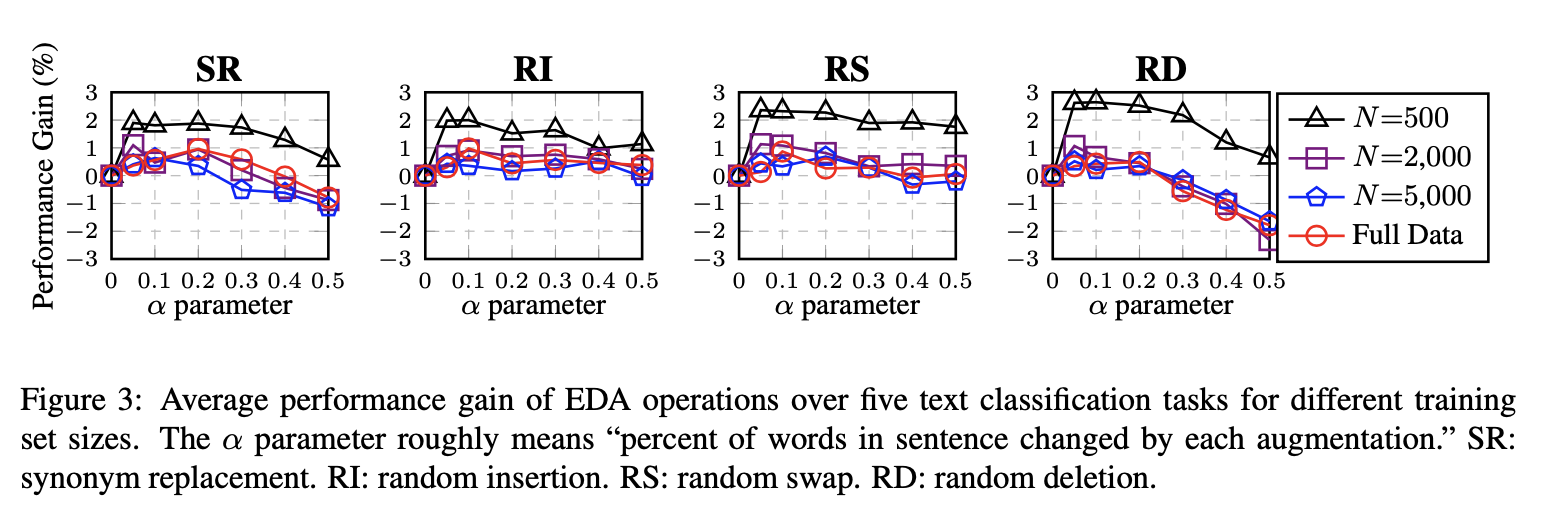
small dataset에서 RD > RS 순으로 가장 큰 성능을 보였으며 SR과 RI는 비슷한 성능을 보여줬다.
large dataset에서는 RS > RI > SR > RD 순이나 큰 변동성은 없어보인다.
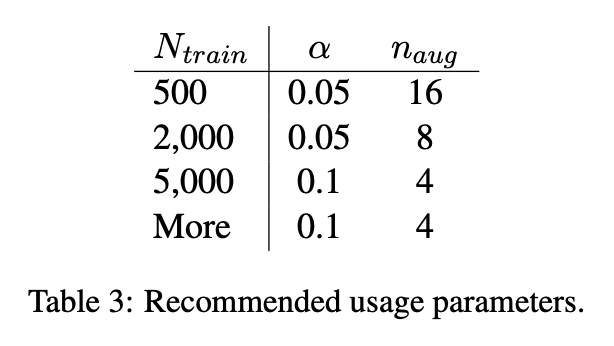
위는 각 규모의 dataset에서 추천되는 파라미터이다.
4.5 How much Augmentation?
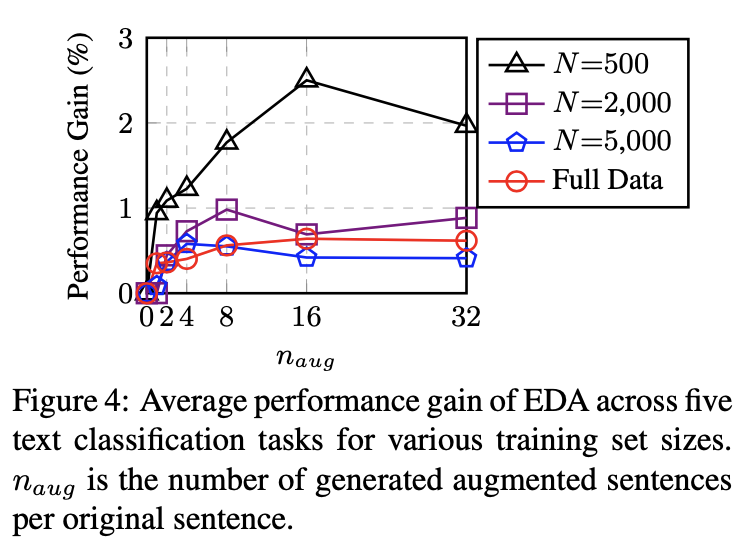
각 데이터셋의 규모당 어느정도의 증감을 수행해야할지를 나타난 그래프이다.
5. Comparison with Related Work
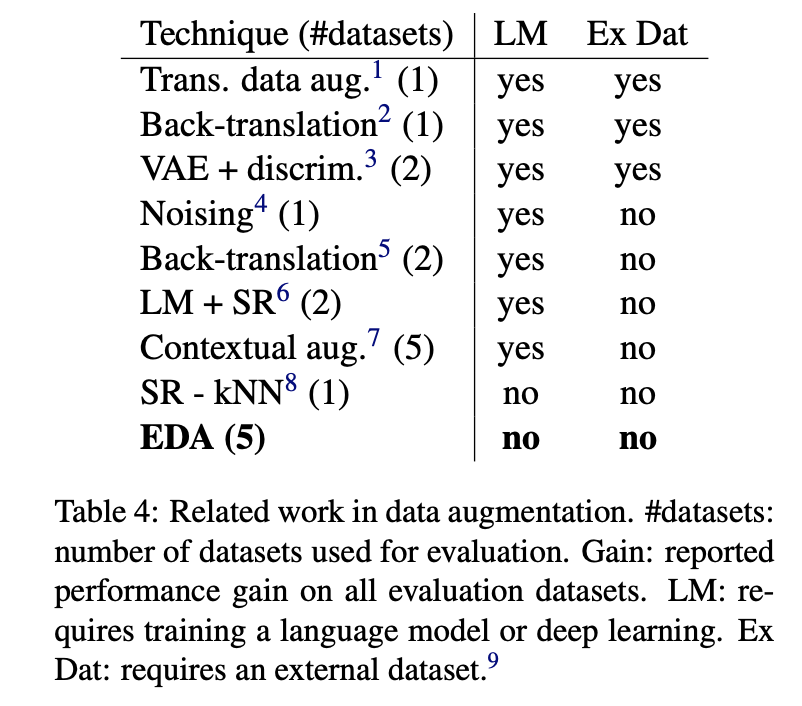
EDA 외 다른 증감 방법과 EDA를 비교하였다.
별도의 Language Model (LM) 이 필요한지, 외부 데이터셋 (Ex Dat)이 필요한지의 여부를 비교한다.
EDA는 별도의 조치 없이도 성능을 낼 수 있는 증감 방법이다.
6. Discussion and Limitations
EDA는 훌륭한 데이터 증감 방법이다.
그러나 다음과 같은 2가지 한계점이 있다.
1. Data 양이 충분하다면 EDA의 효과는 미미하다.
(data augmentation이 부족한 양의 데이터를 채우는 용도이기에 어찌보면 당연하다고 생각된다. augmentation만으로 드라마틱한 개선이 보장되지 않는다는 점으로 해석될 수도 있다고 생각한다.)
2. 사전 훈련 된 모델 (Ex. ULMFit, ELMO, BERT 등)을 사용할 때, EDA의 효과는 미미하다.
(BERT 등을 사용할 때, EDA도 사용하는 전략은 지양해야겠다.)
이번 논문은 분량이 굉장히 짧다.
그럼에도 불구하고 NLP에서의 증감을 배우며 유의미한 결과를 얻을 수 있었다.
