대부분의 ConvNet 기반 모델은 한정된 자원 내에서 처음 설계되었다가 사용 가능한 자원이 늘어나면 그에 맞춰 모델 규모도 증가한다. 이를 "Model Scaling"이라고 한다.
본 논문은 model scaling에 대해 연구하고 네트워크의 깊이, 넓이 그리고 해상도를 조정하며 모델의 성능을 개선하는 방법에 대해 다룬다.
또한 기존 SOTA보다 8.4배 작고 6.1배 빠른 성능으로 SOTA를 달성한 모델인 EfficientNet을 제시한다.
1. Introduction
Scaling up은 모델의 깊이, 넓이, 입력 이미지의 해상도 등을 확장하여 모델의 규모를 커지게 하는 방법이다.
ResNet-18을 ResNet-200으로 Scale Up 한 것이 그것의 예시이다.
이를 통해 모델의 Accuracy를 개선할 수 있다.
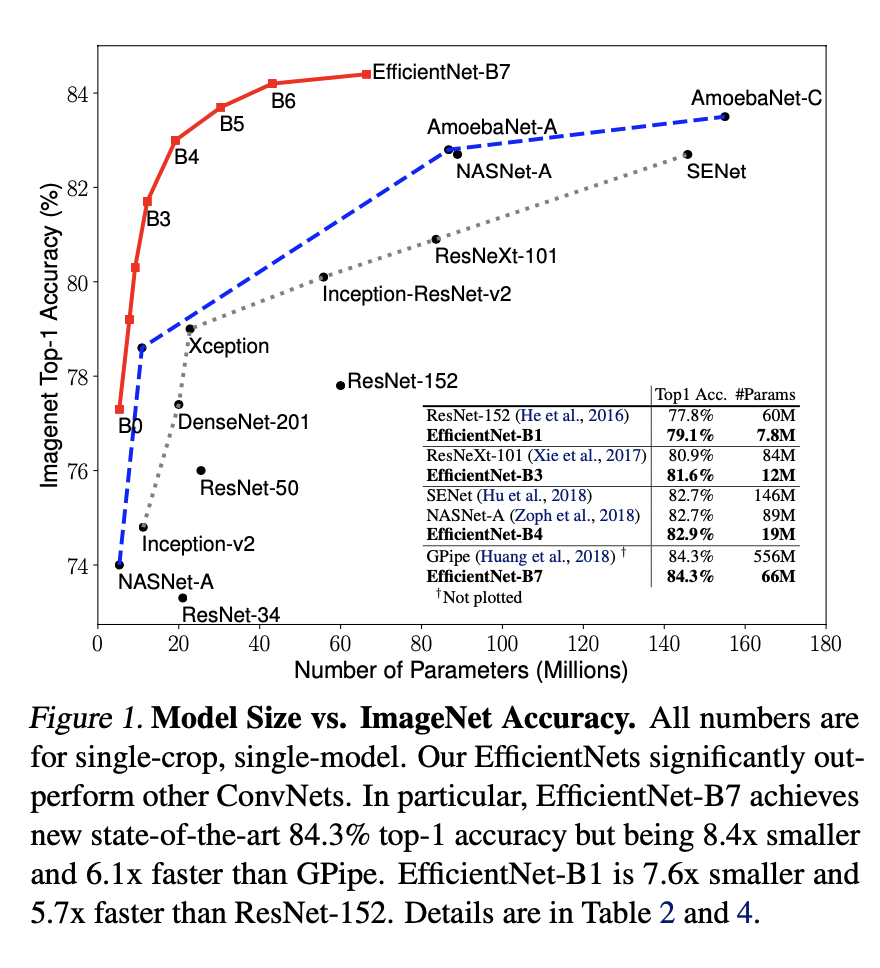
Scale Up을 수행하는 가장 보편적인 방법은 ConvNet의 "깊이", "넓이"를 키우는 것이다.
또 다른 방법은 "이미지 해상도"를 증가시킴으로서 Scale Up을 수행하는 것이다.
본 논문은 기존 Scaling 방법을 재고한다.
기존 방법으로 깊이, 넓이, 해상도를 임의로 증가시킬 수 있으나 이는 지루한 수동 조정이 필요하며 여전히 최적의 정확도, 효율성을 얻지 못할 수 있다.
경험론적 연구에 따라 네트워크의 (깊이, 넓이, 해상도)의 모든 차원을 균형 있게 설정하는 것이 중요하다는 것이 밝혀졌으며 이들을 일정 비율을 유지하며 높잏는 것이 중요하다.
예를 들어 Computational resource가 2^N배 증가한다면, 깊이는 a^N배, 넓이는 b^N배, 이미지 해상도는 r^N배 증가해야 한다.
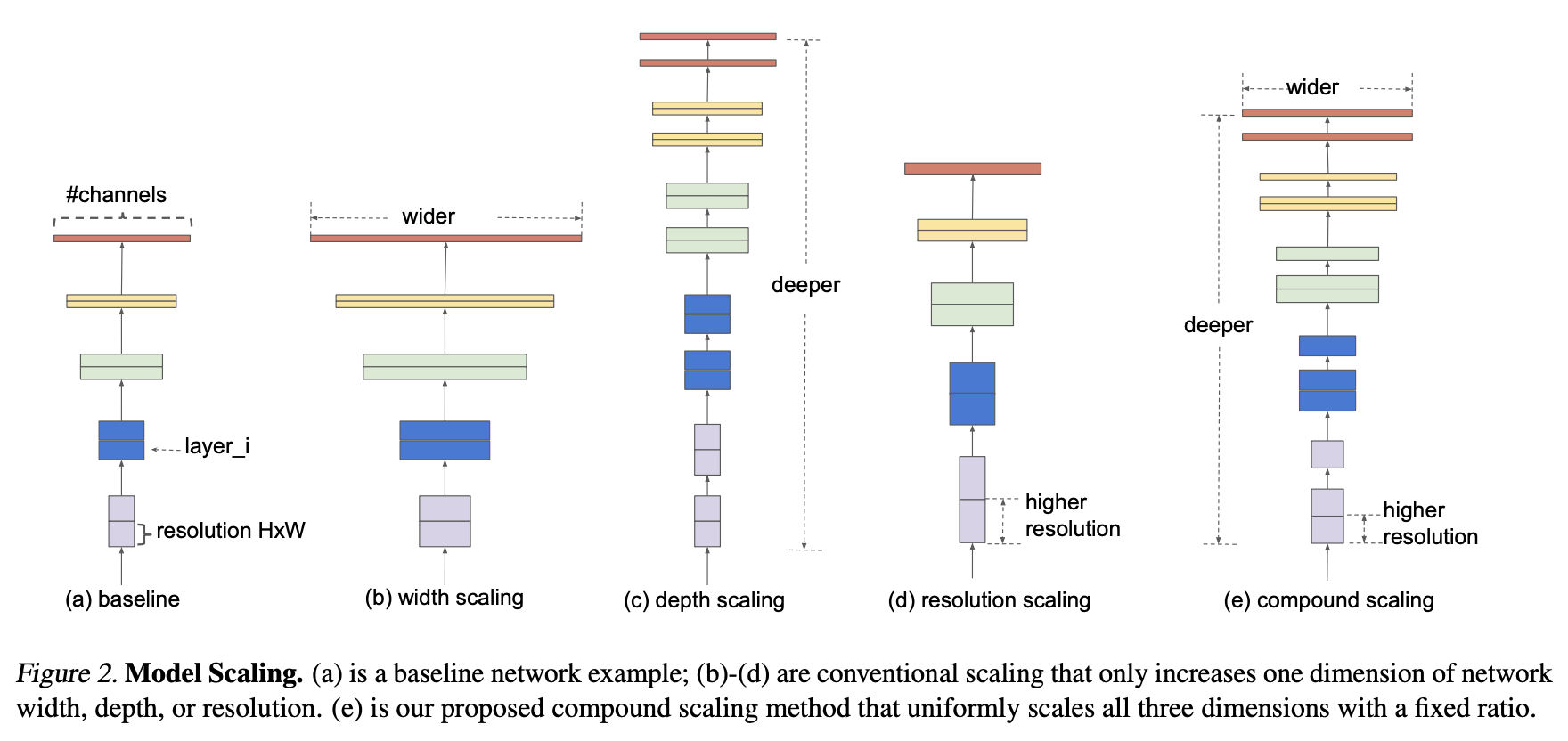
위는 각각의 Scaling 방법을 표현한 그림이다.
주목할 점은, model scaling의 효과가 baseline network에 큰 영향을 받는다는 사실이다.
논문은 Zoph & Le, 2017; Ten et al., 2019를 새 baseline model을 찾는데 사용하였다.
2. Related Work
2.1 ConvNet Accuracy
기존 ConvNet 모델들의 성능에 대한 내용이다.
논문의 원문을 넣어보겠다.

2.2 ConvNet Efficiency
Deep ConvNet은 종종 파라미터가 너무 많아 Model Compression Han et al., 2016; He et al., 2018; Yang et al., 2018 을 사용하기도 한다.
(Model Compression : model size를 줄여 accuracy를 조금 낮추는 대신 efficiency를 높여주는 방법. ex: MobileNets, SqueezeNets, ShuffleNets)
최근엔 mobile-size ConvNet 제작시에 "neural architecture search"가 굉장히 유명해졌다.
2.3 Model Scaling
모델을 깊게, 넓게 혹은 이미지를 크게 만들어 accuracy를 높이는 방법이다.
그러나 얼마나 깊고, 넓고 크게 할지는 지정된 규칙이 없다. 본 논문에서 이를 제시한다.
3. Compound Model Scaling
Scaling problem을 공식화하여 여러 접근법을 공부, 새로운 Scaling Method를 제시한다.
3.1 Problem Formulation
ConvNet Layer i -> Y_i = F_i(X_i), tensor shape -> <H_i, W_i, C_i>
이다.
이때, H_i, W_i는 Spatial dimension, C_i는 channel dimension이다.
ConvNet N : 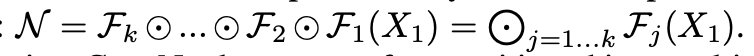
으로 정의 할 수 있다.
각 ConvNet은 같은 architecture를 공유하기에 다음으로 정의가 가능하다.
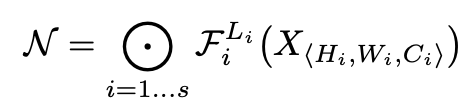
Model Scaling은 Fi를 수정하지 않고 network length(Li), Width(Ci) 그리고 해상도 (Hi, Wi)를 확장시키는 것이다.
Fi를 고정함으로서 model scaling은 새로운 자원 제약에 대한 설계 문제를 단순화하지만, 여전히 레이어마다 Li, Ci, Hi, Wi를 탐색하기 위한 큰 설계 공간이 남아있다.
그렇기에, 설계공간을 더 줄이기 위해, 모든 Layer가 일정한 비율로 균일하게 스케일링 되어야 한다는 제한을 둔다.
우리의 목표는 주어진 자원 제한 내에서 model accuracy를 최대화 하는 것이다.
이를 공식화하면...
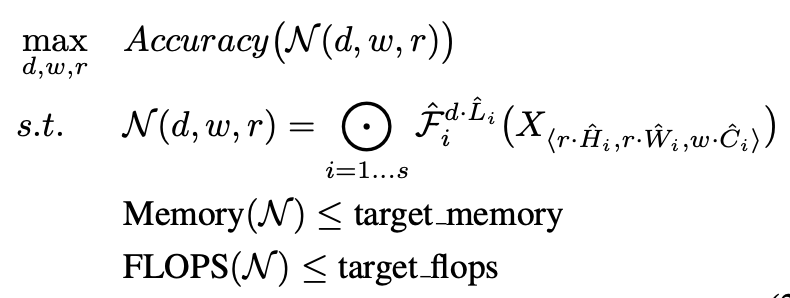
이다.
w, d, r은 scaling network의 width, depth, resolution 계수이며 F_i hat, L_i hat, H_i hat, W_i hat, C_i hat은 baseline network의 미리 정의된 매개변수이다.
3.2 Scaling Dimensions
최적의 d, w, r을 도출하는 것이 어렵기에 (제약조건 및 다른 매개변수가 많기에) 보편적인 방식은 그것들 중 하나의 차원을 optimize하는 것이였다.
Depth(d)
ConvNet이 깊을수록 더 많고 복잡한 특징들을 추출할 수 있습니다.
그러나, vanishing gradient problem 또한 발생하여 Train하기 어렵습니다.
skip connection, batch normalization 등으로 어느정도 이를 모면할 수 있습니다.
그러나 depth의 확장도 한계가 존재합니다. 그 예시가 ResNet-1000과 ResNet-101입니다.
그 둘은 성능의 차이가 깊이의 차이만큼 크지 않습니다..
Width(w)
Width로 Scale up하는 것은 작은 크기의 모델에 대해 많이 사용되는 방법입니다.
더 넓은 네트워크는 세밀한 특징을 추출할 수 있으며 훈련하기에 더 쉽습니다.
그러나 너무 넓고 얇은 네트워크는 그만큼의 효율을 보유주지는 않습니다.
Resolution(r)
고해상도 image data를 통해 ConvNet은 더 많은 세밀한 특징을 추출할 수 있습니다.
그러나 고해상도 이미지를 받쳐줄만큼 깊고 넓은 네트워크가 없다면 제대로 된 feature capture를 할 수 없습니다. 먹기만하고 운동을 하지 않는다면 제대로 된 벌크업이 될 수 없는 것과 같은 이치입니다.
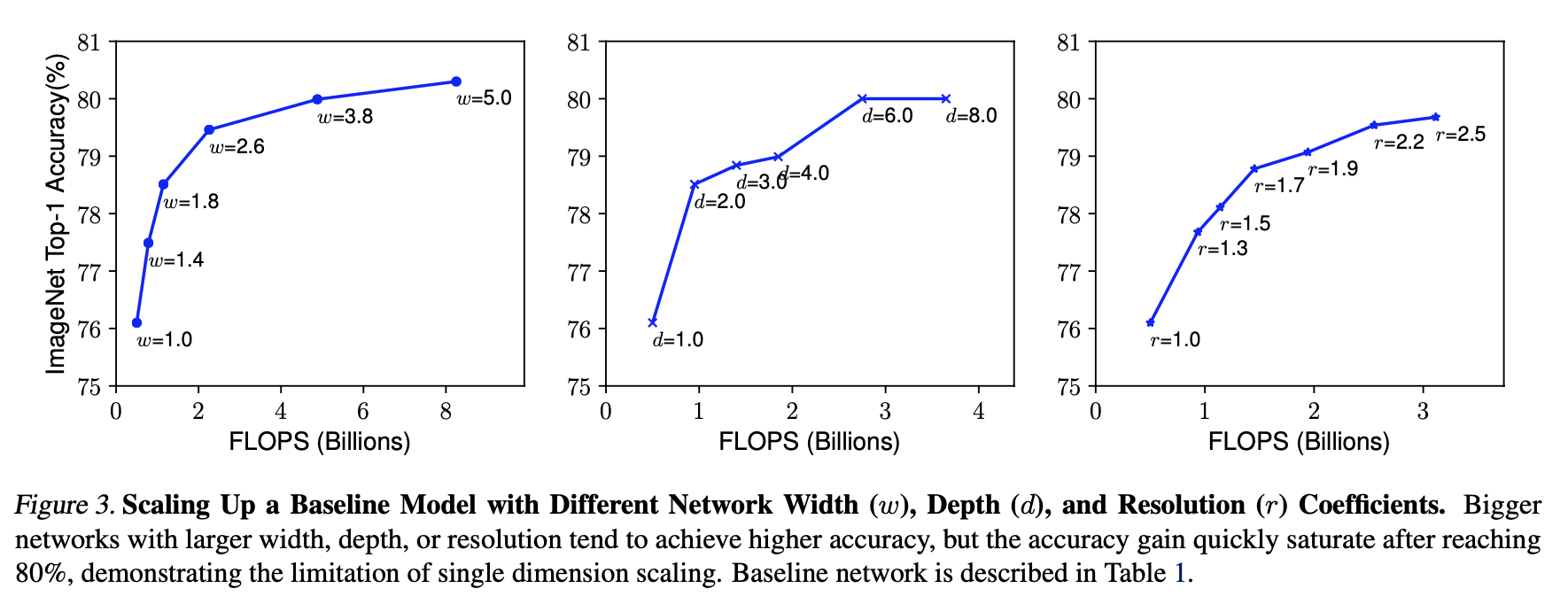
Observation 1.
w, d, r 어느 한 쪽으로나 Scale up을 해도 성능은 개선됩니다.
그러나, 더 큰 모델에서는 accuracy가 점점 줄어듭니다.
3.3 Compound Scaling
경험론적으로 w, d, r 차원을 scale up 하는 것은 서로 독립적이지 않습니다.
r을 증가시키면 이를 감당할 w, d도 증가시켜야 합니다.
각 차원이 서로 협응하며 증가해야 합니다.
Observation 2.
각 차원 w, d, r을 증가시킬 때, 더 나은 accuracy와 efficiency를 위해서는 차원 증가의 balance를 맞춰야 합니다. 어느 한 차원만 증가시키면 기대한만큼의 성능이 나오지 않습니다.
지금까지 우리는 그 balance를 "임의로" 맞춰왔습니다.
해당 논문에서는 적절한 balance 비율을 formulate하여 제시합니다.
이때, Compound 계수 Θ를 이용하여 w, d, r를 한결같이 Scale Up 합니다.
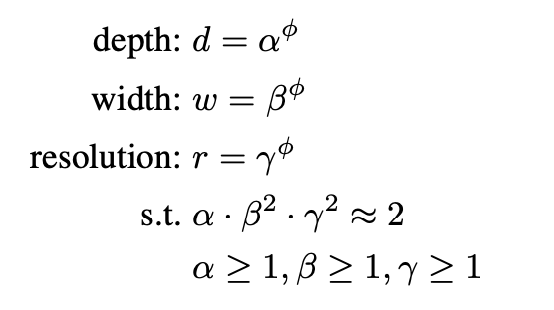
alpha, beta, gamma 는 small grid search로 얻을 수 있는 상수입니다.
이 상수들을 통해 네트워크의 depth, width, resolution에 추가 자원을 분배할지 결정합니다.
Θ는 얼마나 더 많은 자원을 사용할 수 있는지 조절할 수 있는 user-specified constant입니다.
depth가 2배가 되면 모델의 FLOP(초당 부동 소수점 연산량)이 2배가 됩니다.
width나 resolution이 2배가 되면 FLOP은 4배가 됩니다.
논문에서는 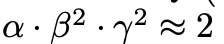
라는 제한을 걸었습니다. 이때, total FLOP은 2^Θ만큼 증가합니다.
4. EfficientNet Architecture
model scaling이 baseline network의 layer operator F_i hat을 바꾸지 않기에 처음부터 좋은 baseline network를 갖는 것은 매우 중요합니다.
EfficientNet은 Scale up의 효율성을 보기 위한 mobile-size baseline network입니다.
EfficientNet's Optimization Goal = ACC(m)x[FLOPS(m)/T]^w
이때,
Acc(m) -> model's accuracy
FLOPS(m) -> model's FLOPS
T -> target FLOP
w = -0.07 -> ACC와 FLOP의 trade-off를 control하는 parameter이다.
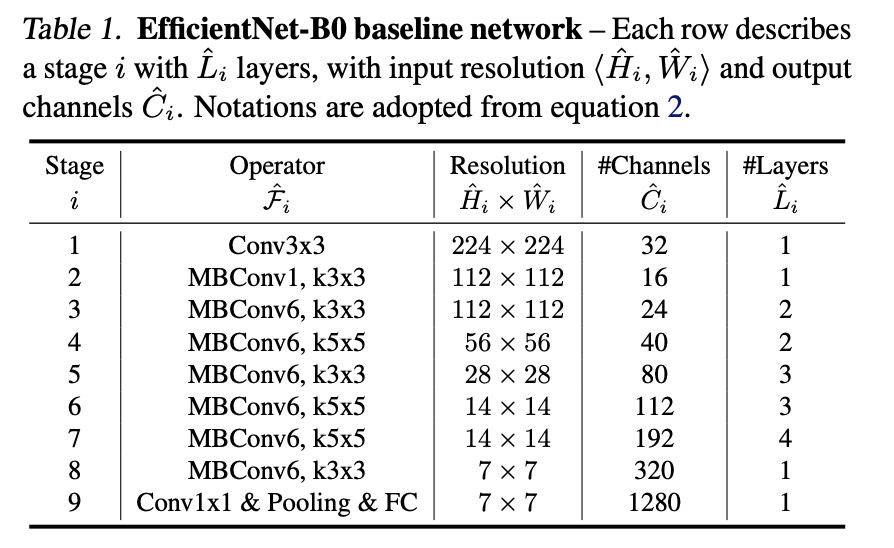
위 표는 EfficientNet의 모델 구조이다.
해당 모델을 Scale Up 하는 방법은 다음과 같다.
Scale Up EfficientNet-B0
Step 1: 2배의 extra resource를 사용할 수 있다고 가정합니다. Θ = 1.
Equation 2, 3에 기반해 small grid search를 시행, alpha=1.2, beta=1.1, gamma=1.15임을 도출합니다.
Step 2: alpha, beta, gamma를 상수로 고정시키고 Equation 3에 기반해 Θ를 수정해가며 network를 Scale Up 한다.
5. Experiments
5.1 Scaling Up mobileNets and ResNets
우선 mobileNet, ResNet을 대상으로 실험을 진행합니다.
이를 통해 논문에서 제시한 방법론이 다른 모델에도 효과가 있음을 보여줍니다.
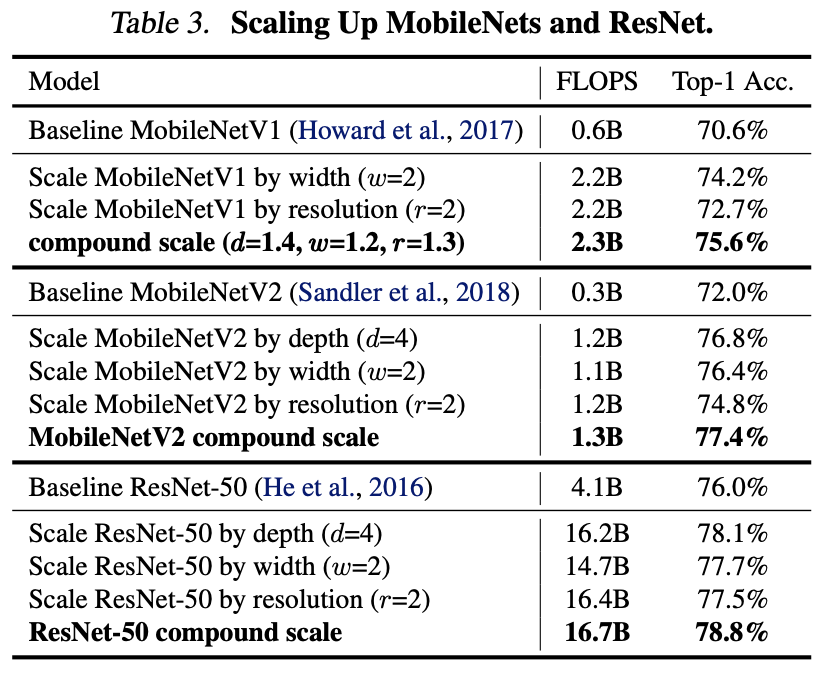
scale up이 진행됨에 따라 성능이 개선됨을 알 수 있습니다.
5.2 ImageNet Results for EfficientNet
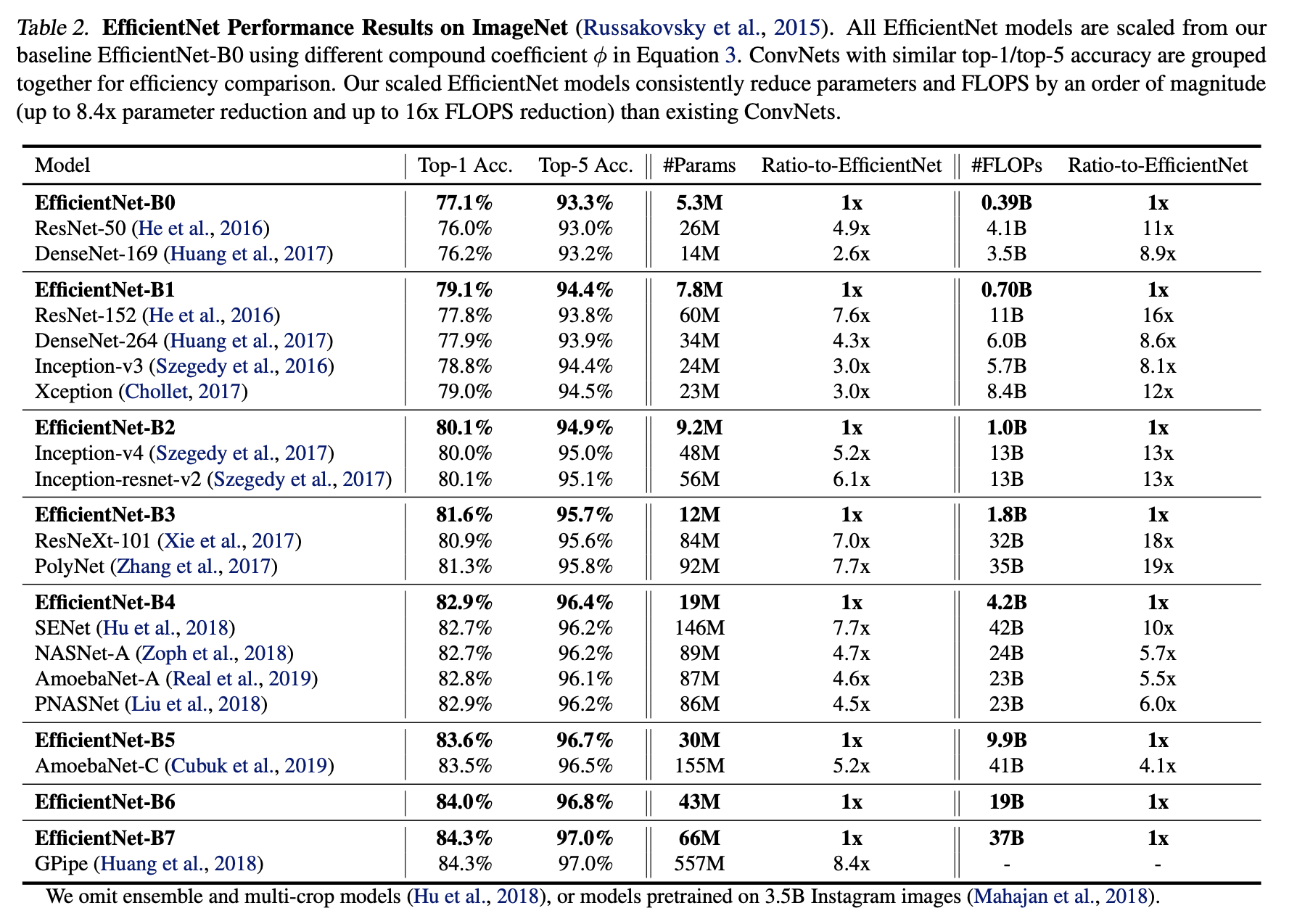
ImageNet에서 EfficientNet 자체와 Scale up을 통해 높은 성능을 보여주었음을 알 수 있습니다.

기존 SOTA보다 더 빠르고 정확함을 볼 수 있습니다.
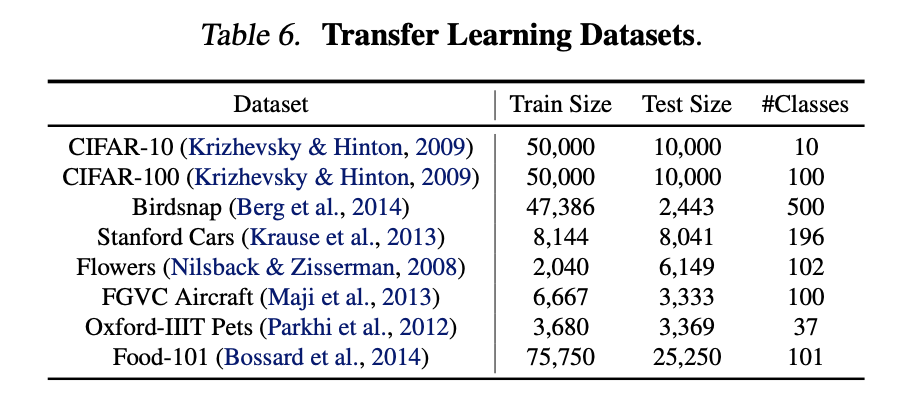
5.3 Transfer learning Results for EfficientNet
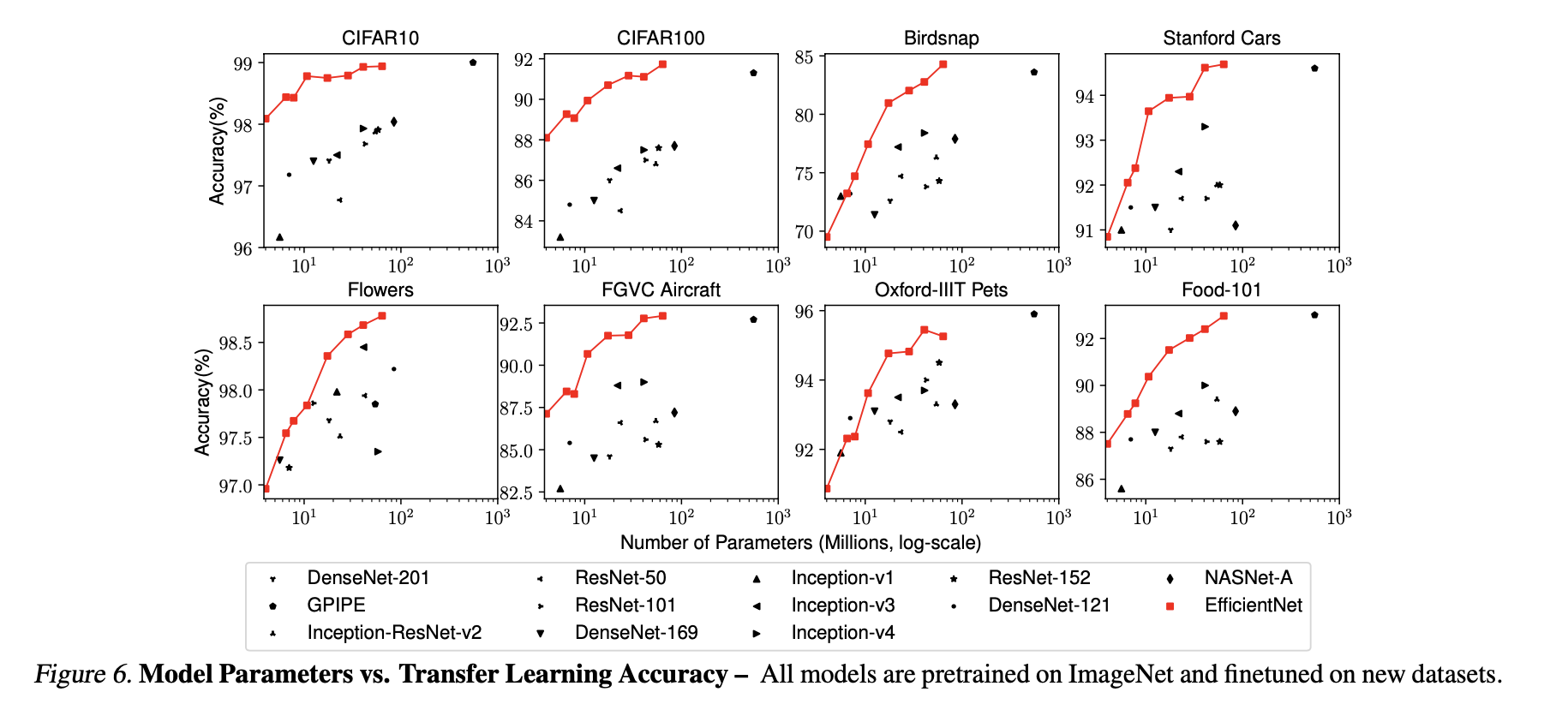
전이학습을 실행하였을때에도 Accuracy가 높음을 볼 수 있습니다.
6. Discussion
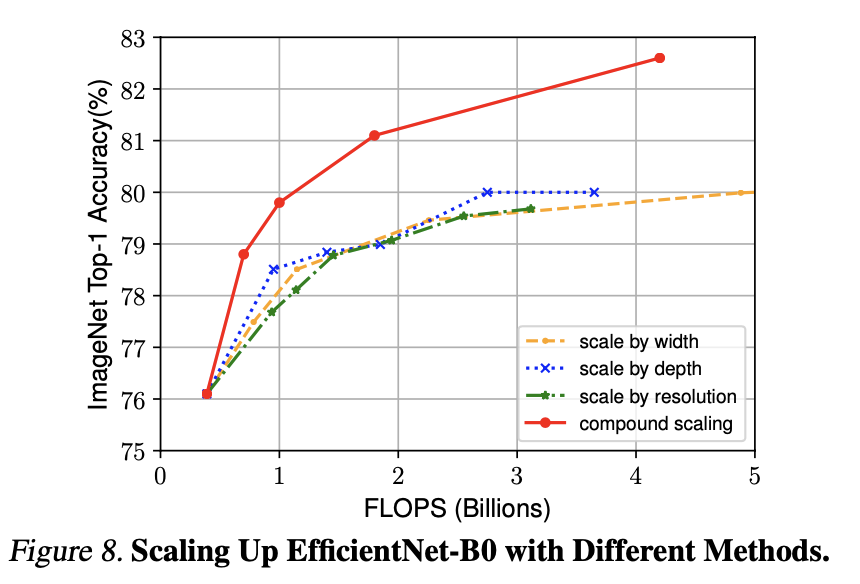
기존 방법 vs Compound Scaling Method의 Scaling 성능 비교입니다.
같은 FLOP에 대해서도 Compund Scaling 방식이 훨씬 좋은 성능을 보여줍니다.
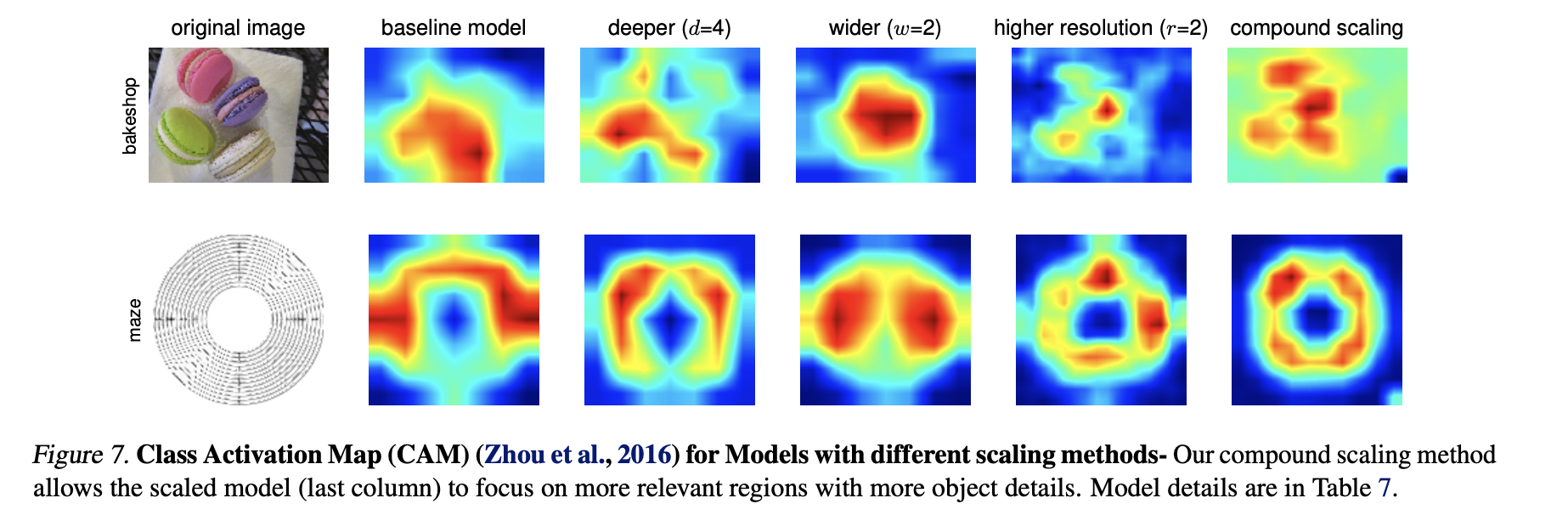
Activation Map을 봅니다.
기존 방법에 비해 Compund 방법을 수행하였을 때, 더 골고루 활성화됨을 볼 수 있습니다.
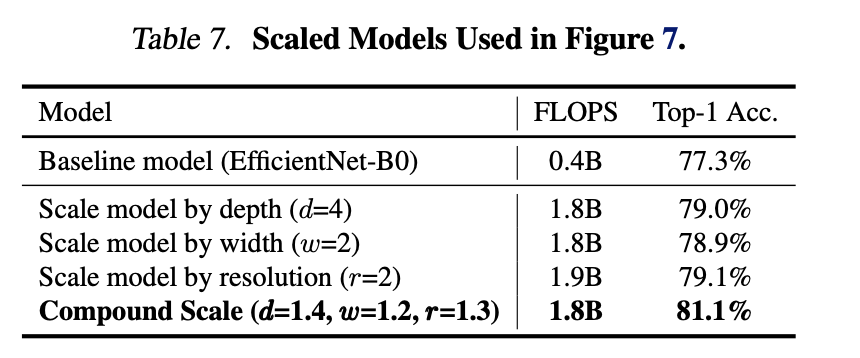
이를 비교한 표입니다.
해당 논문을 통해 어떻게하면 모델을 더 효율적으로 Scale Up 할 수 있을지에 대해 다뤄봤습니다.
기존 방법에 비해 Compound 방법을 사용함으로써 더 효율적인 성능개선이 가능함을 알 수 있습니다.
