지금부터 조금 어려운 개념들이 나와서
조금씩 써보면서 공부해보려고한다.
피처 엔지니어링 : 원본 데이터로부터 도메인 지식(특정주제나 전문 분야)등을 바탕으로 문제를 해결하는데 도움이 되는
Feature를 생성, 변환하고 이를 머신러닝 모델에 적합한 형식으로 변환하는 작업
Feature : 특징
pandas group by aggregation을 이용한feature engineering
원본 데이터에서 주어진 feature에 고객 ID 기반으로 pandas Group By Agreegation 함수를 적용해서 새로운 Feature 생성
약 20가지 넘는 Feature 들이 존재한다.
Cross Validation Out of Fold 예측:
모델Traning시Cross Validation을 적용해서Out of Fold Validation성능 측정 및Test데이터 예측을 통해 성능 향상
데이터를 여러개로 나눠서 데이터의 성능을 예측한다.
캐글같은 경진대회는 대부분이 방법을 적용하고있다.
LightGBM Early Stopping:
마이크로 소프트에서 개발한 경량화된 그래디언트 부스팅 프레임워크. 여러개의 결정트리를 조합하여 강력한 예측모델을 만드는 방법결정트리 : 데이터를 분류, 회귀분석하기 위한 트리구조의 모델.:Iteration가중치를 업데이트하면서 반복적으로 모델을 훈련하는 단어을 통해 반복학습이 가능한 머신러닝 모델에서 validation성능 측정을 통해 성능이 가장좋은 하이퍼파라미터모델 학습전에 사전에 설정되어야 하는 매개변수. 구조나 학습과정에 영향을 미치는 값을 의미 예) 트리의 깊이, 트리의 개수, 학습률, 학습횟수 등등에서 학습을 조기종료하는 Regularization복잡성을 조절하여 과적합을 방지하고 일반화 성능을 향상시킬때 쓰는 정규화방법
예) Boosting 트리모델트리개수, 딥러닝의 Epoch모델이 한번 전파되는 수수
피쳐 중요도 : 타겟변수를 예측하는 데 얼마나 유용한 지에 따라 피처에 점수를 할당해서 중요도를 측정하는 방법
크게 두가지로 나뉜다.
Model-specific vs Model-agnostic
- 모델 자체에서 피처 중요도 계산이 가능하면
specific - 모델 제공기능에 의존하지않고 따로 피처 중요도를 계산 하는 방법은
agnostic
LightGBM 모델은 피처 중요도를 계산해주는 기능(feature_importance)을 제공한다.
XGBoost 도 피처 중요도 함수(get_score)를 제공한다.
CatBosst 모델클래스에 get_feature_importance함수로 계산 기능 제공
Permutation 피처 중요도란?
피처에 있는값들을 랜덤하게 셔플링하고 만약 피처가 중요하다면 에러가 굉장히 커질것이고, 랜덤하게 섞어도 에러가 안난다면 별로 중요하지않은것이다.
피처를 하나하나 순차적으로 셔플링해서 기존과 에러가 얼마나 발생하나 에러차이를 어떤모델이던지 측정해보는 agnostic한 방법이다.
꽤나 신뢰할만한 피처 중요도라고 생각해서 실제에서도 많이 쓴다.
from sklearn.inspection import permutation_importance여러번 refeats=10 등으로 반복하면서 피처 중요도를 적용해볼수있다.
피처 선택(Feature Selection)이란?
- 피처 선택
머신러닝 모델에서 사용할 피처를 선택하는과정.
머신러닝 모델이 타겟변수를 예측하는데 유용한 피처와 유용하지 않은 피처를 구분해서 선택한다.
피처 선택을 통해 모델복잡도를 낮춤으로써 오버피팅 방지 및 모델의 속도 향상 가능 - 피처 선택방법
- Filter Method
- Wrapper Method
- Embedded Method
Filter Method
- 특징을 기반으로한 측정을 사용하여 피처를 선택하는 방법. 상관관계를 알아내기 좋고, 속도가 빨라 전처리때 많이 사용한다.
Wrapper Method
- 실제 모델을 사용하여 하위집합을 만들고 성능에 따라 피처를 추가,제거하는 방식으로 피처를 선택한다.
Embedded Method
- 일부 모델은 내부적으로 중요도를 고려하여 학습하고, 중요하지 않은것은 무시하거나 제거 한다.
위 세가지 메소드를 혼합하여 사용하기도 한다.
머신러닝 기본 용어 간단정리
-
입력인자
함수가 받는 입력값들을 나타낸다. -
범주형 피쳐
머신러닝에서는 수치형(숫자), 범주형(문자열,이산적값)을 나타낸다.
예를들면 성별(남자,여자), 학력수준(고졸,대졸)등이 있다. -
레이블 인코딩
범주형 데이터를 수치형 데이터로 변환하는 과정. '남자','여자'가있다면 이걸 0과1로 인코딩하는것이 예시. -
결측치
값이 비어있는 경우 -
중위값
데이터의 중앙에 위치한 값으로, 데이터를 크기순으로 정렬했을때 가운데에 위치한 값
lightGBM
lightGBM에 따라 안의 parameter들이 바꿔진다. 특히 4.2.0 이 되니 verbose_eval이 num_boost_round로 바뀌었다. 평소에 버전에 맞게 파라미터를 사용하는것을 숙지하자.
피처 엔지니어링 방법
1. Early Stopping : 모델학습을 하다가 성능이 하락하면 일찍 중단해서 과적합을 방지한다.
2. Cross Validation : 데이터를 여러개의 부분 집합으로 나누어 모델을 여러번 학습 및 검증하는 방법. 신뢰할수있게 평가하거나 하이퍼파라미터 튜닝에 사용.
3. Scaling : 피처 값의 범위를 일정하게 조정하는 과정. 피처간의 크기를 줄이고 수렴속도를 향상시킬때(1.0~1.3이면 점점줄여서 1.12이렇게 찾게)
4. cumsum : 누적합을 계산하는 함수. 주어진 지점에서 누적합계를 계산해서 어떤 지점까지 합을 현재지점에 누적한다. 시계열데이터, 순서데이터의 특성을 나타내는데 유용하다. (일간 판매량,일별 매출, 누적판매량 등등 전반적인 시간에 따른 특성을 캡처할 수 있음)
하이퍼 파라미터 튜닝
하이퍼 파라미터 : 학습과정에서 컨트롤하는 파라미터 밸류(모델이 학습하기전에 사람이 미리 설정해줘야하는 파라미터)
- 하이퍼 파라미터 튜닝 : 이런 파라미터를 조절하는 방법
- 하이퍼 파라미터 튜닝 방법
-
Manual Search : 자동화 툴을 사용하지않고 수작업으로 하나씩 바꿔가며 테스트
-
Grid Search : 사전정의된 값들을 조합하여 모든조합에 대해 테스트하는 방법. 공간이 크면 계산비용이 높지면 적으면 효과적이다.
-
Random Search : 사전 정의된 값중에 무작위로 몇개의 파라미터 조합을 선택하여 테스트한다.
-
은근 효율적인 방식이라고한다.
-
Bayesian optimization : 기존의 테스트결과를 기반으로 다음에 시도할 하이퍼 파라미터 조합을 선택한다. 계산비용이 높은모델에서 유용하다. 목적 함수의 효과적인 모델링이 필요하다
-
처음엔 랜덤하게 보다가 이전성능이 잘나온 하이퍼 파라미터를 집중적으로 선택한다.
Optuna
오픈소스 하이퍼 파라미터 튜닝 프레임 워크 :
주요기능 : 최적화된 하이퍼 파라미터를 자동화로 찾는 여러가지 방법을 제공
- Eager search spaces
- State-of-the-art algorithms
- Easy parallelization
trial.sugget_uniform -> 옵튜나에서 시도하는 함수 호출
LightGBM 에도 적용할수있음.
param = {
'lambda_11': trial.sugget_loguniform('lambda_11', 1e-8,10.0)
}이런식으로 파라미터의 특정 value를 optuna의 trial함수로 선언가능.
하이퍼 파라미터 저장 기능
- 무한정 결과를 돌리기는 힘드니까 100번정도 돌리고 그 결과를 저장하고,
다시 storage API를 사용해서 더 탐색 할 수있다.
storage = optuna.storages.RDBStorage(url=...,engine_kwargs={...)등으로
study = optuna.create_study(storage=storage)선언하여 저장 할 수 있다.
하이퍼 파라미터 Visualization
- optuna.visualization.plot_param_importances(study)
- optuna.visualization.plot_optimization_history(study)
- optuna.visualization.plot_slice(study,params=["x","y"])
- optuna.visualization.plot_contour(study,params=["x","y"])
(여러개의 하이퍼 파라미터를 볼수있는 컨투어)
- optuna.visualization.plot_parallel_coordinate(study,params=["x","y"])
( 선으로 나타내지는 비주얼라이제이션)등으로 다양한 방법으로 확인 할 수 있다.
앙상블
앙상블러닝 : 여러개의 결정트리(Decision Tree)를 결합하여 하나의 결정 트리 보다 더 좋은 성능을 내는 머신러닝 기법.
앙상블 알고리즘은 단일알고리즘을 여러개 조합해서 사용한다. 좋은 알고리즘 하나보다 평범한 알고리즘 여러개를 써서 좋은값을 찾는 방법
하나의 좋은 알고리즘보다 한가지 이상의 보통 알고리즘을 사용하는게 좋은 insight를 얻을 수 있다 (집단지성!)
- 여러개의 약분류기를 결합하여 강 분류기를 만드는 과정.
장점 : 성능을 분산시키기때문에 과적합(Overfitting) 감소 효과
모델의 성능이 안나올때도 사용한다.
앙상블 러닝의 기법
1.Bagging - Boostrap Aggregation(샘플을 다양하게 생성)
-
Bootstrap Aggregation의 약자. 훈련 세트에서 중복을 허용하여 샘플링 하는 방식
-
Pasting 방식으로 중복을 허용하지 않는 방법도 있다(자주안씀)
2.Voting(투표) - 투표를 통해 결과 도출
- 배깅은 데이터 샘플. Voting 은 알고리즘을 선택하는 투표다.
여러개 알고리즘을 선택해서 Voting을 진행한다.
hard vote : 다수결 원칙과 비슷
soft vote : 분류기 들의 레이블 값 결정 확률을 더하여(힘쌘 알고리즘에다가는 1.3배) 이중 가장 높은 레이블 값을 최종 보팅 결과값으로 선정.
분류기들의 결정 확률을 모두 더하고 이를 평균내어 가장 확률이 높은 값을 결과로 선정
일반적으로 소프트보팅을 적용한다.
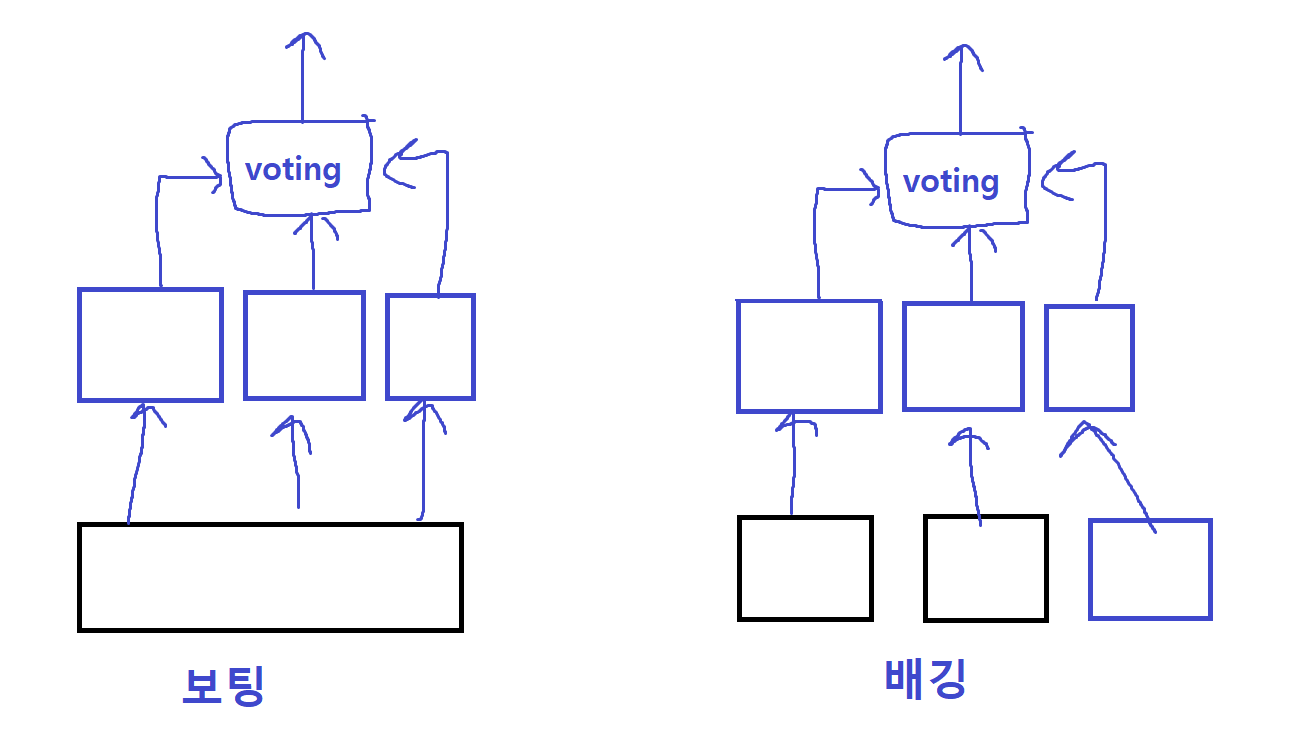
보팅 방식은 Data Set은 그대로고
Bagging은 사용한 Sample Data set1, set2, set3 각 Decision Tree번호에 맞게 입력하여 Voting 하여 종합한다고 보자.
3. Boosting - 이전의 오차를 보완하며 가중치 부여
- 여러개의 분류기가 순차적으로 학습을 시작한다.
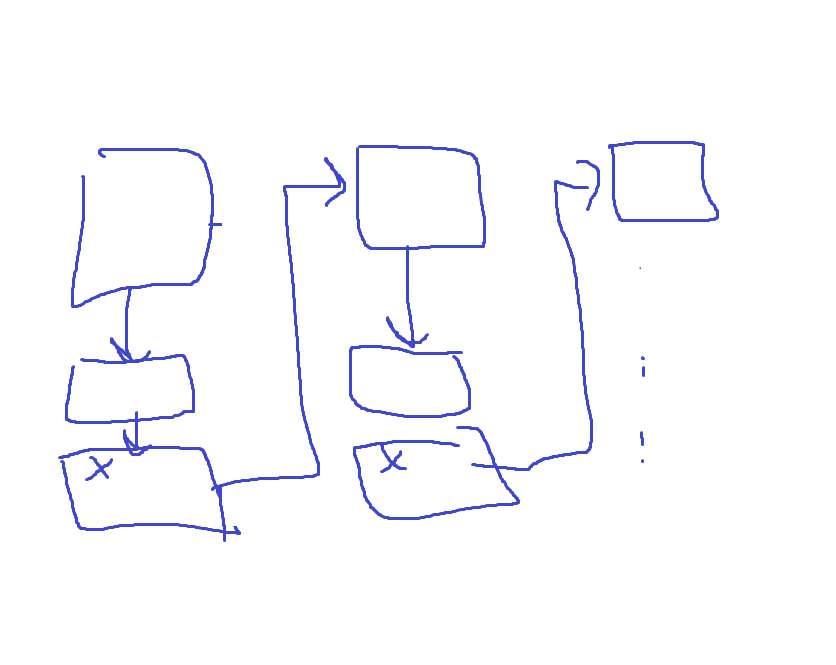
시퀀셜(순차적)으로 구동하기에, Overfitting 문제가 있을수있어 가중치를 잘 부여하며 사용한다. 일반적으로 많이 사용한다.
에러에 가중치를 추가하여 계속 Classifier (분류기) 에 넣는다.
4. Stacking - 여러 모델을 기반으로 (meta 모델)
- 여러 모델들을 활용해 각각의 예측결과를 도출 한 뒤 그 예측 결과를 결합해 최종 결과를 만들어 내는 것.
단점 : 오버피팅 문제
장점 : 단일모델보다 확연히 성능이 향상된다.
캐글같은 경진대회에서 마지막으로 쥐어짜낼 때 사용한다.
요즘에는 캐글에서는 잘 안사용하는 추세.
Decision Tree
Impurity
- 해당 노드안에서 섞여있는 정도가 높을수록 복잡성이 높고, 덜 섞여 있을수록 복잡성이 낮다.
- Imputiry를 측정하는 측도에는 다양한 종류가 있는데, Entropy와 Gini에 대해서만 알아보자.
Gini Index
- 불순도를 측정하는 지표로써 데이터의 통계적 분산정도를 정량화 해서 표현한 값
- 낮을 수록 불순도가 낮다.
Graphviz
- 트리의 그림을 제작해서 보여주면서 Gini Index를 보여준다.
XGBoost
Gradient Boosting 에 Regularization term을 추가한 알고리즘
다양한 Loss function을 지원해 task에 따른 유연한 튜닝이 가능하다는 장점이 있음.
LightGBM
-
XGBoost의 단점을 개선한 모델.
하이퍼 파라미터 개수가 많은데 이를 좀 줄였다.
OverFitting이 발생하기 쉽다. -
GOSS (Gradient-based One-Side Sampling
기울기가 큰 데이터 개체 정보 획득에 있어 더욱 큰 역할을 한다는 아이디어에 입각해 만들어진 테크닉, 작은 기울기를 갖는 데이터 개체들은 일정 확률에 의해 랜덤하게 제거
Catboost
- 순서형 원칙을 제시한다.
TabNet (구글사람들이 만듦)
-
정형 데이터를 위한 딥러닝 모델
-
TabNet은 전처리 과정이 필요하지 않음.(알아서 다함)
다른 Decision tree-based gradient boosting(xgboost,lgbm,catboost)와 같은 모델에 비해 신경망 모델은 아직 성능이 안정적이지 못함. 두 구조의 장점을 모두 갖는 신경망 모델. -
Feature selection
특정선택다차원의 데이터에서 가장 중요한 특성들을 선택하는 과정, interpretability(local, global)해석 가능성내부적으로 해석이 가능하여 의사결정의 근거를 제공하고 어떻게 모델의 예측이 형성되었는지 이해 할 수있다.가 가능한 신경망 모델, 설명 가능한 모델 -
feature 값을 예측하는 Unsupervised pretrain
비지도 사전훈련레이블이 달린 데이터 없이 모델을 사전에 훈련시키는 과정, 주로 특정 작업에 대한 데이터가 제한적이거나 부족한 경우, 모델이 데이터의 구조를 학습하고 일반적인 특징을 추출하도록 돕는데 사용된다.단계를 적용하여 상당한 성능 향상을 보여줌. -
태브넷은 순차적인 어텐션을 사용하여 각 의사 결정 단계에서 추론할 특징을 선택하여 학습능력이 가장 두드러진 특징을 사용한다.
-
특징 선택이 이루어 지므로 어떠한 특징이 중요한지 설명이가능함
-
기존의 머신러닝 방법은 특징선택, 모델학습과정이 나뉘어져있지만 tabnet은 한번에 이루어 진다.
-
파라미터가 좀많아서 파라미터 탐색하는데 시간이 걸릴 수 있다.