Regularization
- 규제를 건다
학습을 방해하는게 목적이다.
학습데이터 뿐만아니라, 테스트 데이터에도 잘 동작 할수 있도록 만드는것.
Early stopping
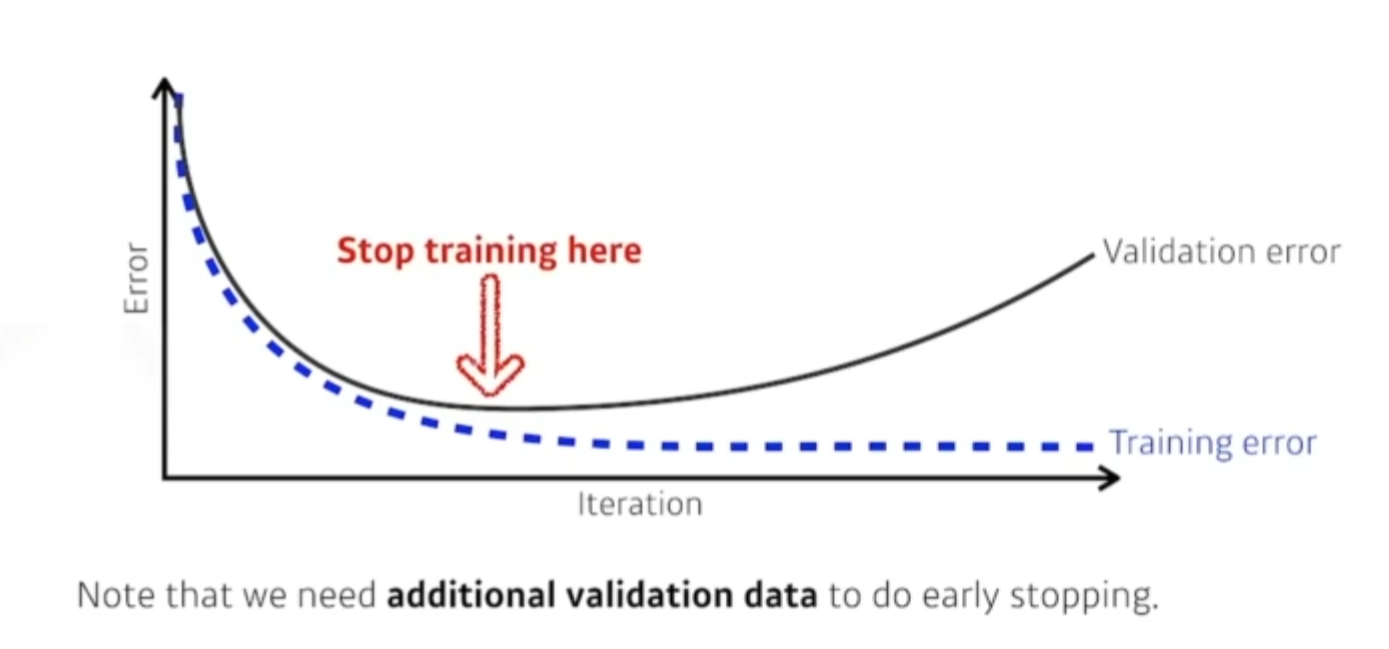
- 잘되고 있을때 멈추는 것. 너무 반복해서 Loss가 커지기전에.
Parameter norm penalty
- 뉴럴네트워크 파라미터가 너무 커지지 않게 하는것.
- 네트워크 파라미터들을 다 제곱해서 더하면 큰숫자가 나오는데 그걸 같이 줄이는것이다.
- 이왕이면 네트워크 숫자들이 작으면 작을수록 좋다.(크기관점, -포함)
이 의미는 function space 뉴럴네트워크가 만들어내는 함수의 공간속에서 최대한 부드러운 함수로 보자
Data augmentation

- 가장 중요한것은 데이터다.
- 아무리 좋아도 데이터 셋이 적으면 딥러닝이 잘안될 가능성이 많다.
- 데이터가 한정적이니까 데이터를 늘리는 행위다.
- 데이터 자체를 지지고 볶아서 데이터셋을 올림.

- 레이블이 변환되지않는 선에서 데이터 어규멘테이션을 한다.
Noise robustness

-
좀더 실험적인 결과다. 노이즈를 넣으니 잘되더라 !
-
왜잘되는지는 모른다. 입력데이터에 일부러 노이즈를 넣는다.
Label smoothing
-
데이터 두개를 뽑아서 이 두개를 섞어주는것.
-
일반적으로 분류문제는 decision 바운더리를 찾고싶은것임.
-
분류가 일어나는 결정하는 공간을 부드럽게 만들어준다.

-
cutout - 특정 영역을 빼버림.
-
Mixup - 강아지와 고양이 두개의 이미지를 고르고 라벨도 포함해서 50대50으로 섞는다.
왜잘되는지 설명보단 이런 방법론을 사용하면 성능이 올라간다.
- 코드자체도 굉장히 간단하고 들인 노력에 비해 성능을 많이 올릴 수 있는 방법론이다!
Dropout

- 어떤 뉴런을 0으로 바꾸는 것이다.
Batch normalization

-
논란이 많은 논문이다.
-
원래의 값들이 100으로 가지면 다 0으로 줄여버린다.
-
Internal Covariate Shift를 줄인다. 그러므로 네트워크가 잘 학습이된다.
-
뒤에 나온 논문들이 이 내용을 동의 하지 않는다.
일반 적으로 네트워크가 쌓아져있는 상태에서 Batch Normalization 을 사용하면 성능이 올라간다.

각각 노말라이제이션에 관한 방법들.
- 역시 이걸 해석하기 보다는 간단한 분류문제를 풀때 Batch Norm을 쓰는게 성능이 올라간다고 알려져있다.
비전공자 + 타업계 경력2년의 IT 개발자 도전기~