언어란 오해의 시작이다.
Gradient Descent
- 반복적으로 최적화, 첫번째 미분을 계속 진행해서 최소값을 찾으러 간다.
Optimization
- 최적화에 대한 용어를 먼저 정리하겠다.
Generalization
일반화 성능
- 많은 경우 일반화 성능을 높이는게 목적이다.
그렇다면 일반화 성능이 뭘까?
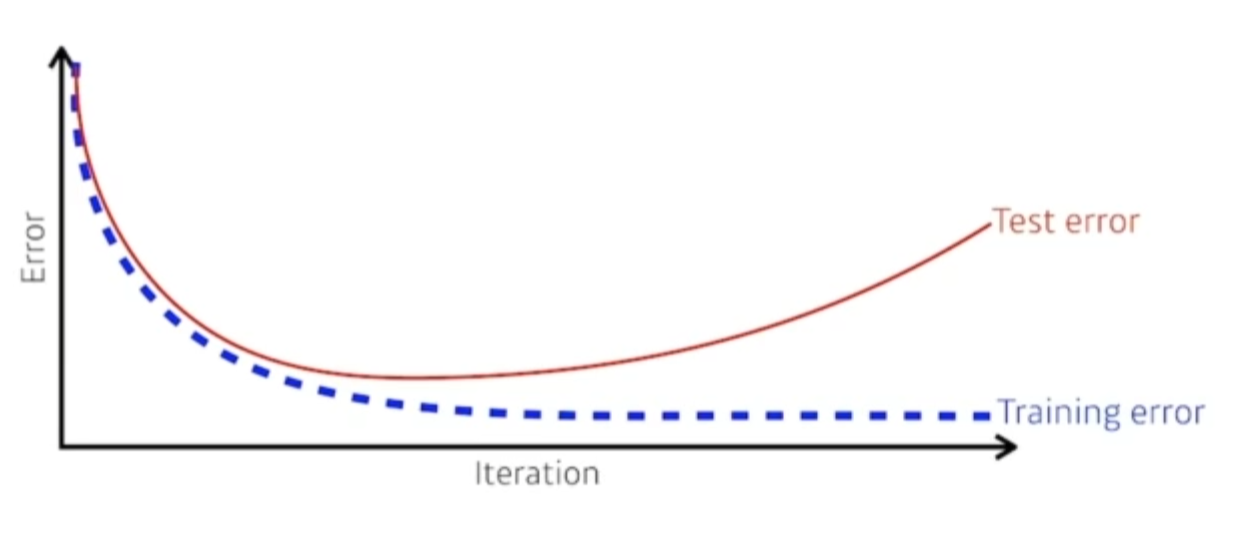
일반적으로 우린 학습을 시키면 학습데이터에 대한 트레이닝 에러율은 줄어들게 된다.
우리가 트레이닝 에러가 0이 됐다고 해서, Test 에러에서 0이 된다는 보장은 없다.
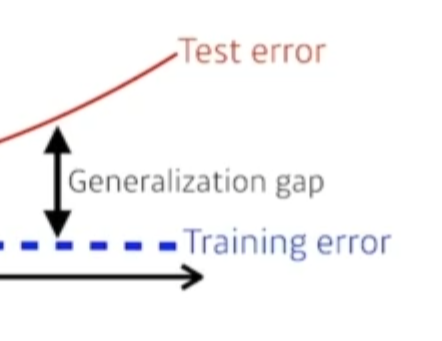
즉, 이 네트워크 성능이 학습데이터와 비슷하게 나올것이다 라는 말이다.
그래서 제네럴라이제이션이 좋다라는건 테스트데이터와 학습데이터에서의 갭이 적다는 말이다.
Under-fitting vs over-fitting
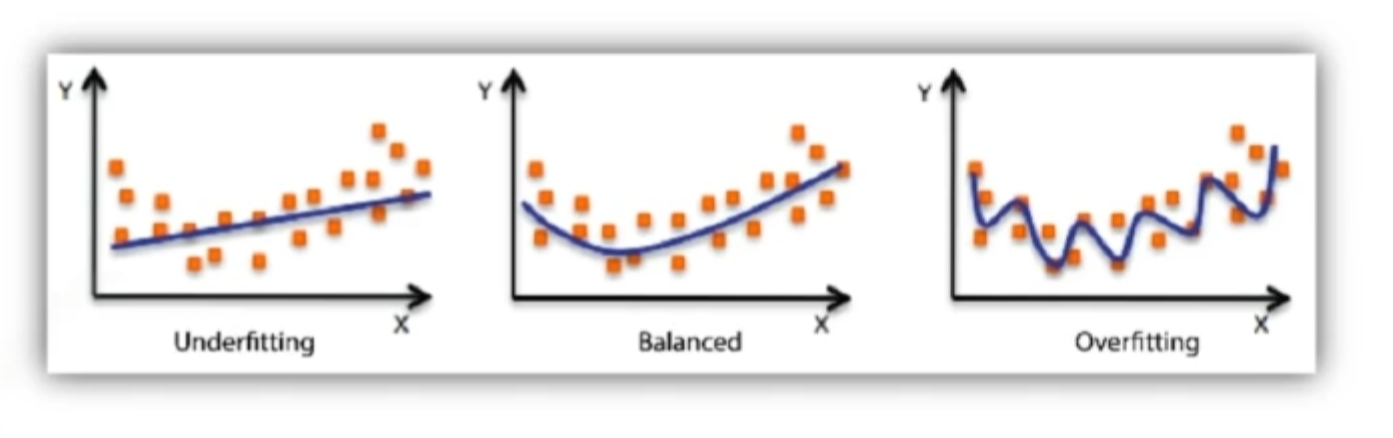
네트워크가 너무 간단하거나 너무 과하게 형성되어있을때 사용한다.
Cross validation
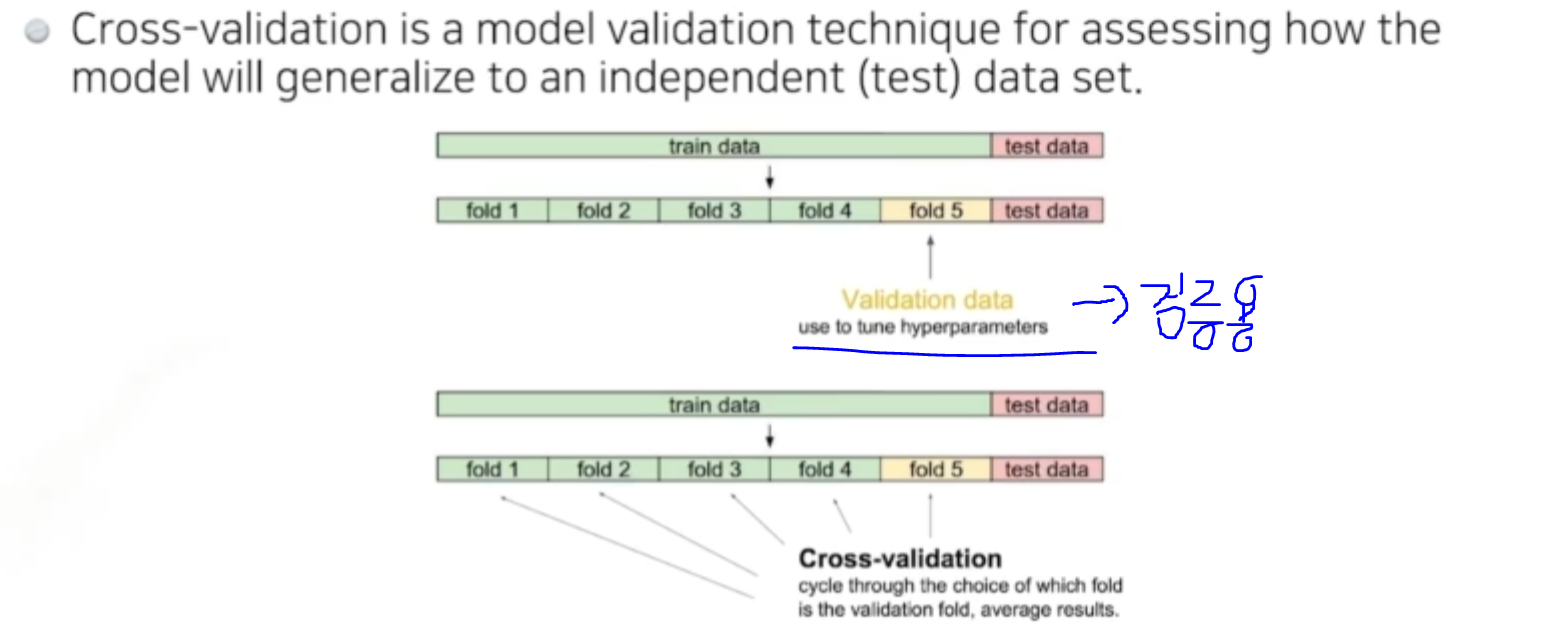
트레이닝 데이터와 validation data를 나눠서 주는경우가 있다.
이 validation data학습때 사용되지 않은 데이터를 얼마를 가지고 나누면 좋을까?
사실상 학습 데이터가 너무 적기때문에 K-fold validation라고도 부른다. 학습데이터를 k개로 나누는것이다.
만약 데이터가 10만개면 8만개로 학습시키고 2만개로 확인해본다.
일반적으로는 사용되는경우는 뉴럴 네트워크 학습시킬때 하이퍼 파라미터내가 정하는값 ex. 러닝레이트, 로스펑션 등가 필요하다.
어떤 하이퍼파리미터가 좋은지 모르니 cross validation을 사용해서 하이퍼 파라미터를 찾고 그다음 한다.
Test data를 절대로 학습데이터로 사용하면안된다. (cheating의 영역)
Bias-variance tradeoff
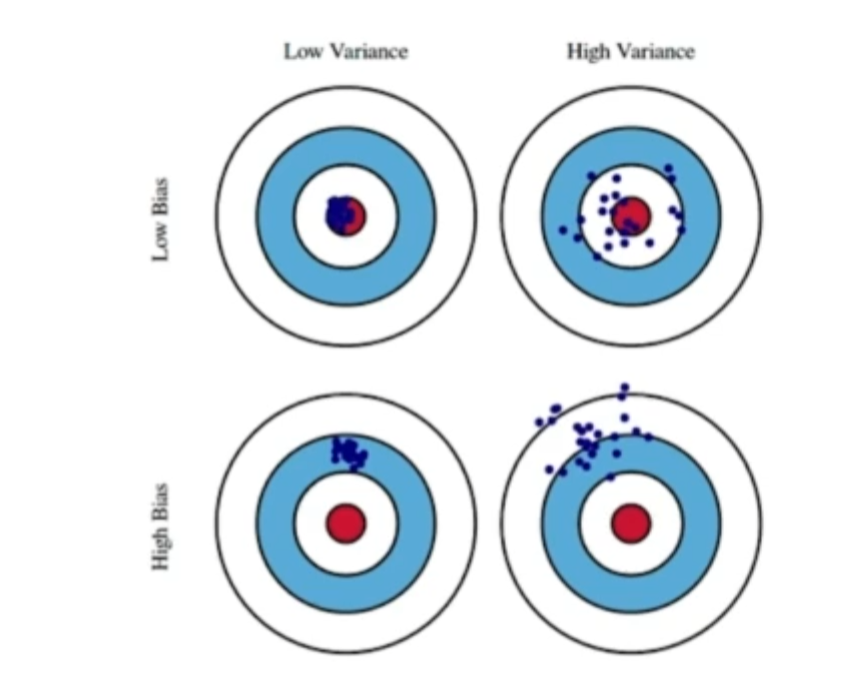
총을 쏠때 탄착군 형성을 생각해보자.
variance : 집합의 데이터가 얼마나 퍼져있는지 측정하는 통계적 측도
variance가 높을수록 데이터가 많이 흩어져있다 라는 뜻이다.
내학습데이터에 noise가 껴있다고 가정했을때 t라는건 true target의 노이즈가 꼇다는 이야기.

위 세가지 관계가 bias를 줄이면 variance, noise가 올라가거나 하면서
서로 상호보완하는 관계를 가진다.
Bootstrapping
신발끈을 들어서 하늘로 날겠다 ?
- 학습데이터가 100개가 있으면 내가 100개중에 몇개만 활용을 하고
80개 모델, 80개 모델, 등등.. 해서 여러개 모델을 만든다.
이 하나의 입력에서 각각 모델이 모두 같은값을 예측하거나 다른값을 예측할 수 있다.
이 모델들이 예측하는 값들의 일치,불일치를 확인하고자할때 부트스트래핑을 사용한다.
- 학습데이터가 고정되어있을때 sub 샘플링 데이터를 여러개를 만들고 그와 가지고 여러 matric, 모델을 만들어서 확인하겠다라는 방법론.
Bagging and boosting
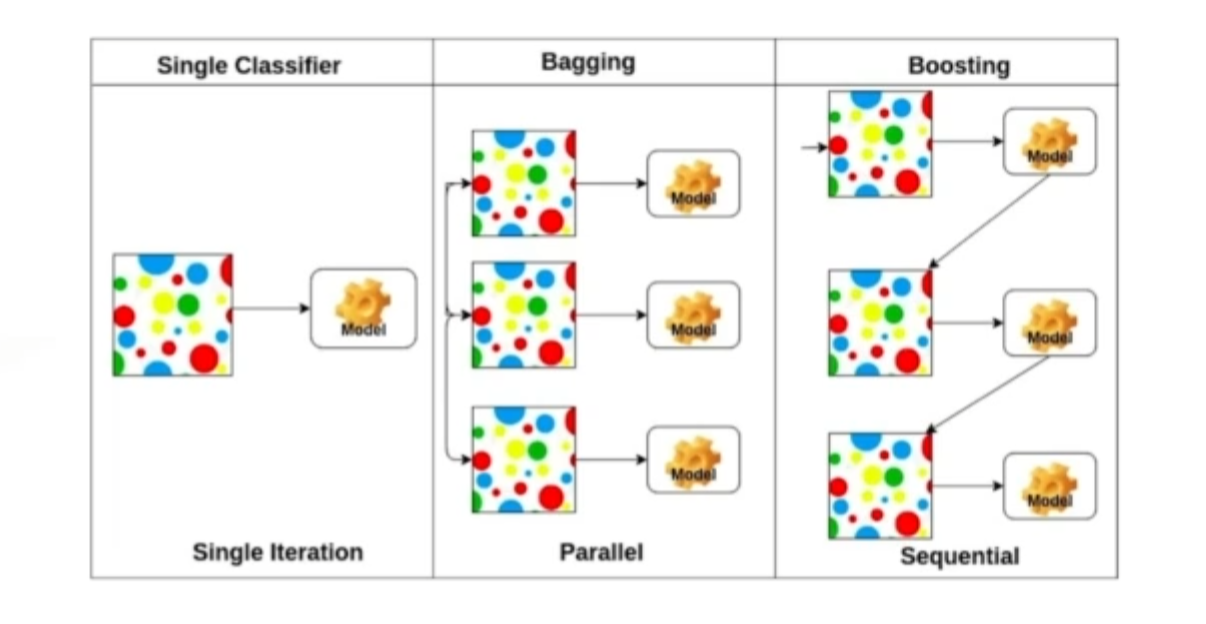
- Bagging (Bootstrapping aggregating)
- 학습데이터가 10만개로 고정돼있으면 얘로 다 학습해서 결과를 내는게 좋아보이지만, 80% 데이터로 n개의 모델로 만든 다음에 이 n개의 모델을 모두 돌려보고 돌려본 값들의 평균, 보팅을한 값을 찾는게 더 좋은 성능을 내는 경우가 많다.
- Boosting
- 학습데이터가 100개가있으면 이중 시퀀셜하게 바라봐서 모델하나를 만들고 학습데이터에 돌려본다. 80개의 데이터에 대해 잘 예측을햇지만, 20개는 예측 못할수가있다. 그래서 모델을 하나 더 만드는데 이 20개의 데이터에만 잘 동작 하는 모델을 만들고 여러개의 모델을 다 합친다.
- n개의 독립적인 모델로 보는게 아니라 이 weak 러너들을 하나로 합쳐서 strong 러너를 만드는.(haarcascade Adaboost?와같은방식같은데..)