Segmantic Segmentation
Semantic Segmentation(시멘틱 세그멘테이션)은 직역하자면 '의미론적인 분할'
어떤 이미지가 있을때 각 이미지를 픽셀별로 사물을 분류해 내는것.
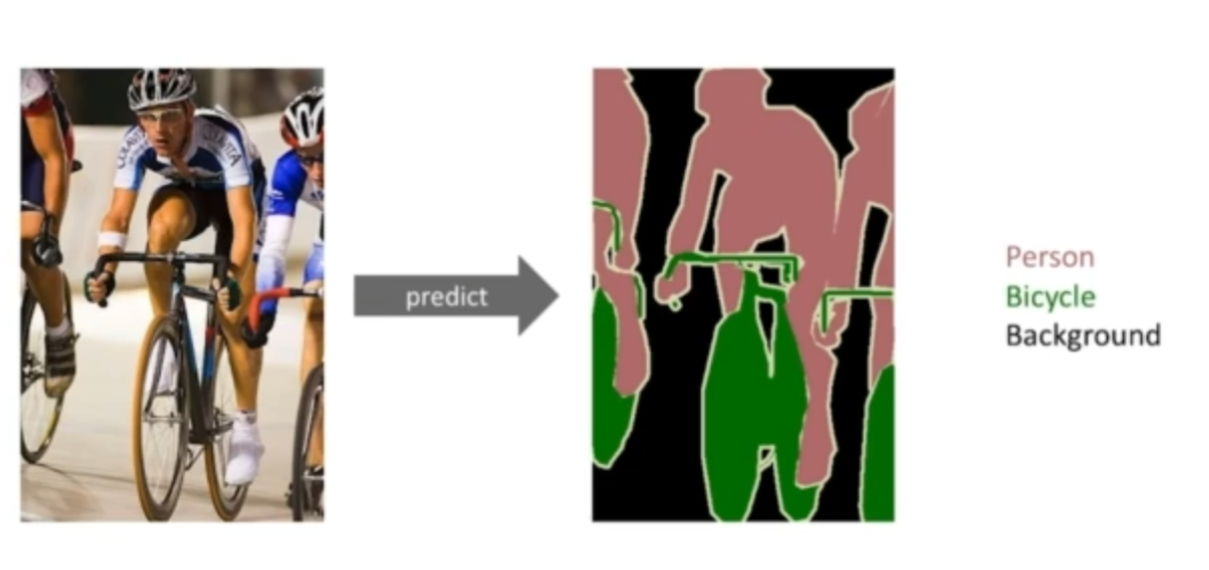
이미지의 모든 픽셀이 어떤 라벨에 속하는지 보고싶다.

자율주행 문제에 많이 활용된다.
- 라이다와같은 센서를 활용하지않은 이미지만 활용할때는 매우매우 중요한 분류방법이다.
Fully Convolutional Network

-
이게 fully convolutional network다.
-
일반적으로 CNN은 다시 컨볼루션 통과하게 하고 flat해서 채널을 피고 dense해서 label을 나오게 만든다.
Convolutionalization

Fully connected layer는 입력 데이터를 평탄화(flatten)하여 처리하므로, 입력의 공간 구조를 고려하지 않습니다.
-
하지만 우리는 Dense레이어를 없애고 싶다. output이 1000단이 나오면 이걸 convolution layer로 바꾸자는 것이다.
-
dense 레이어를 없애자는게 컨볼루셔널라이제이션이다.
-
앞의 구조와 input, output구조로 봤을땐 똑같다.
-
컨볼루셔널라이제이션을 하면 FCL과 달리 위치정보나, Class에 대한정보(2차원정보)를 잃어 버리지 않을 수 있게 된다.
20x20x1000 짜리 필터 커널을 만들어서 이걸 1x1x1000짜리 컨볼루션을 만든다?
다시 말하면, Flat -> Dense 의 과정을 한개의 컨볼루션 레이어로 만들겠다는 말이다.
- 파라미터
Left : 4x4x16x10 = 2560 개
Right : 4x4x16x10 = 2560 개
그냥 내가 한줄로 펴서 옆으로 돌리냐? 컨볼루션을 돌리냐?
똑같은 연산이다.
이런게 convolutionalization 이다.
왜이걸 할까?

- 첫번째
- Input space demension이 더큰 이미지에서 상관없이 돌아간다.
- Input 의 크기에 따라 뒤의 Output의 크기가 커지게된다.
- 분류만 했던 네트워크가, 히트맵으로 나올 수 있는 가능성이 생긴다.
- 해당이미지에 고양이가 어디에있는지 히트맵이 나오게된다.
Deconvolution

-
컨볼루션 트랜스 포즈(conv transpose)
-
컨볼루션의 역 연산.
-
stride 를 2를 주면 30x30 -> 15x15로 줄어드는데 이걸 역으로 시전해주는거다.
-
하지만 이걸 역으로 복원하는것은 불가능하다. 예를 들면, 10을 가지고 2와 8 을 복원한다거나. 엄밀히 말하면 컨볼루션의 역은 아니다.

-
2x2를 컨볼루션하고 여기에 패딩을 많이줘서 결과론적으로 원하는 2x2를 얻는다.
-
엄밀히 말하면 역은 아니지만, 컨볼루션의 역의 개념과 비슷하다.
-

- 결과물이 이렇게 나온다.
Detection

R-CNN
- 이미지 안에서 2000개의 리전을 뽑아낸다. (region)
- 얘를 그냥 똑같은 크기로 맞춘다.
- 그리고 분류를 시작한다.
- 분류는 alexaNet이나 등으로 분류를한다.
- 이 바운딩박스는 어떻게 정해주는게 좋냐 등의 테크닉이 쓰인다.

딱봐도 뭔가 무식하고 오래걸려보인다.
정확하지 않고 완벽하지는 않지만, 이렇게 detection문제를 풀고자 하는 시도가 있었다.
SPPNet
- R-CNN의 문제는 바운딩박스 2000개를 뽑으면 CNN을 다 통과시켜야하는 문제가 있었다. CPU는 하나의 이미지를 처리하는데 1분이 걸리는 문제가 발생.
- 이미지안에서 CNN을 한번만 돌리자!
- 이미지 전체에 대해 컨볼루션 피쳐맵을 만들고 컨볼루션 feature 맵의 해당하는 tensor만 가져오자.
- spatial pyramid pooling 이라고 불림.
- 많이 쓰이지는 않음.
Fast R-CNN

- 바운딩 박스에 해당하는 tensor를 뜯어와서 CNN을 돌려야 하기 때문에 SPPNet의 개념과 동일한걸 가져온다. 미리 이미지 기반의 피쳐를 뽑아놓는다.
- 각각의 Region에 대헤 다 돌린다.
Faster R-CNN

- 바운딩 박스를 뽑아내는 리전 프로포잘도 학습을 하자. 라는 개념.
- candidate(지원자)를 뽑는것도 학습해서 뽑아버리자!
RPN(Region Proposal Network)

RPN 이 해주는건 간단하다.
이미지가 있으면, 해당 바운딩 박스가 의미가 있을지를 찾아주는것.
박스 안에 물체가 있을지 확인해 주는것.
- anchor boxes 는 이미 정해놓은 크기의 바운딩 박스의 정보를 미리 알고있는 것이다.(강아지,고양이,돼지,버스,사람,자동차 등등)
- 궁극적으로 이 템플릿을 고정해 놓는게 RPN의 가장 큰 특징이다.
여기서도 FCN 이 쓰인다.
해당하는 영역의 이미지가 물체가 들어있을지 안들어있을지 FCN이 가지고 있게 된다.

위와 같이 비율과 region 사이즈를 미리 정해놓는다.
총 54만큼의 컨볼루션 채널이 나온다.
이걸 잘 뜯어보면, 해당 영역에서 어떤 바운딩박스를 사용할지 말지를 정할 수 있다.

결과가 조금더 잘 나오게 된다.
스키도 잘잡고 작은 사람들도 잘 잡는다.
YOLO(you only look once)
-
YOLOv1 - 엄청빠른 물체감지 알고리즘이다.

-
컨볼루션의 서브스탠셜을 분류하는게 아니라 바로 이미지를 찍어서 나올수있게 만들었다.
-
faster-R-CNN 은 바운딩 박스 를 차지하는 리전 프로포절 네트워크가 있고 또 판단하는 네트워크가 따로있엇는데 이건 그 두개를 한번에 하는것이다.

- 이미지가 들어오면 SxS grid 모양으로 나눈다.
- 각자 B개의 바운딩 박스를 예측한다. (5개 정도)
- 그 바운딩 박스가 쓸모있는지 없는지 체크한다.
- 그다음 이 중점에 있는 어떤 오브젝트가 어떤 class 인지 예측하기 시작한다.
- 원래 바운딩 박스를 찾고 클래스를 찾앗다면,
- 얘는 그 두개가 동시에 이뤄진다.
- 결론적으로 tensor가 SxSx(B*5+c)개의 텐서 채널을 가지게 된다.

유독 유쾌한 알고리즘이다.
faster R-CNN에서
바운딩 박스를 찾는것과 클래스를 동시에 진행한다.
뒤로갈수록 real-time을 유지한채 좋은성능을 보여준다.