RNN은?
주어지는 입력이 시퀀셜 입력이다.(연속입력)
Sequential Model
- Naive Sequence model
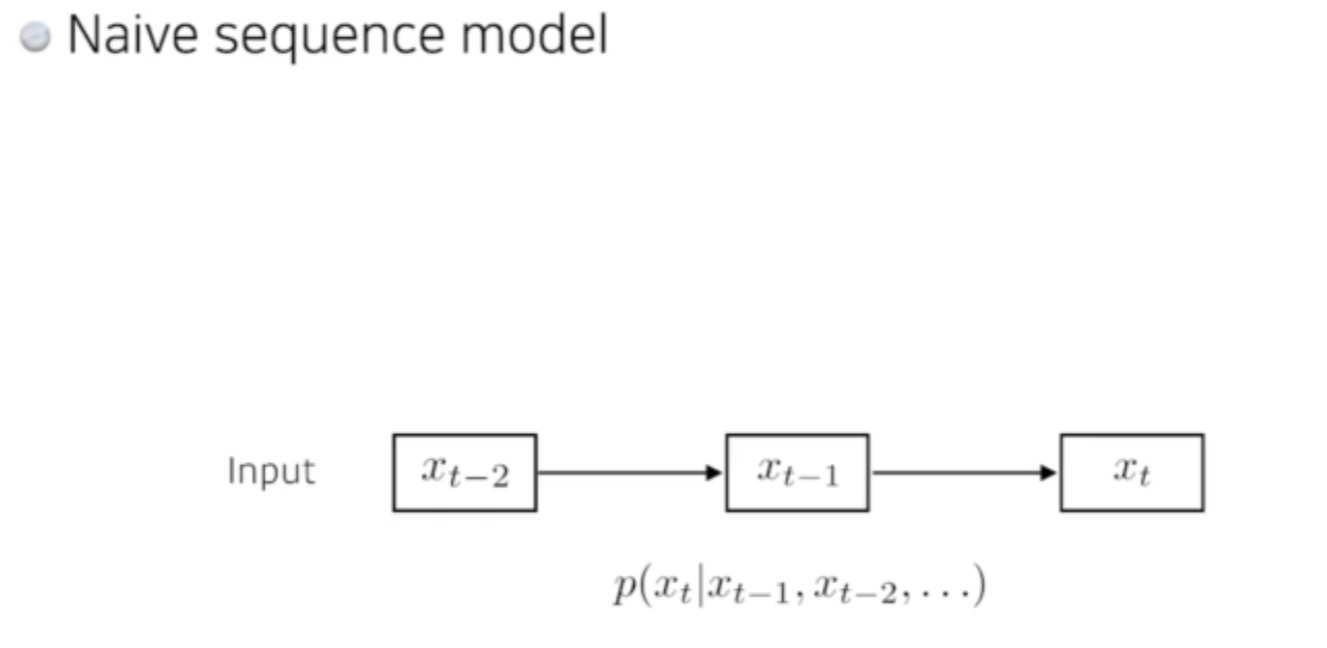
일상생활하며 접하는 대부분의 데이터는 연속된 데이터이다.
연속된 데이터가 들어오기 때문에 FNC 를 사용할 수없는것임.
몇개의 데이터가 들어오는지 모르기 때문.
그래서 입력이 들어왔을때 다음 데이터가 어떤것일지 예측을 하는것이다.
이걸 가장 간단히 만드는 방법은
Fix the past timespan = 과거의 데이터 개수(예:5개)를 본다.
Markov Model(First-order autoregressive model)
- 과거데이터 기반 예측의 가장 쉬운모델이다.
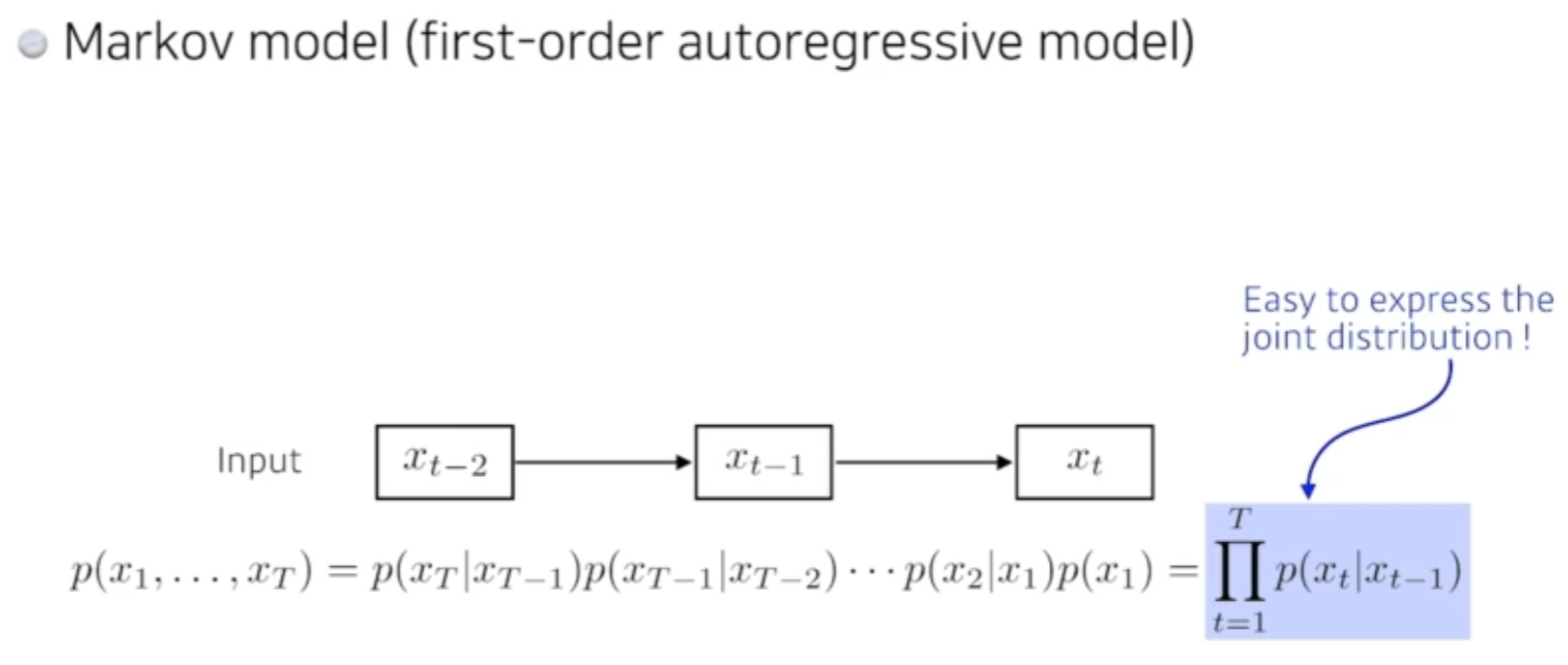
-
가장큰 특징 : 내가 가정하기에, 나의 현재는 과거에만 dependent 하다 !
-
예: 전날 공부한 것에만 dependent 하다.
그렇기 때문에 많은 정보를 버리게 된다. -
가장 큰 장점은 joint distribution 을 하기 쉽다! ( 다음 수업때 나옴 )
Latent autoregressive model
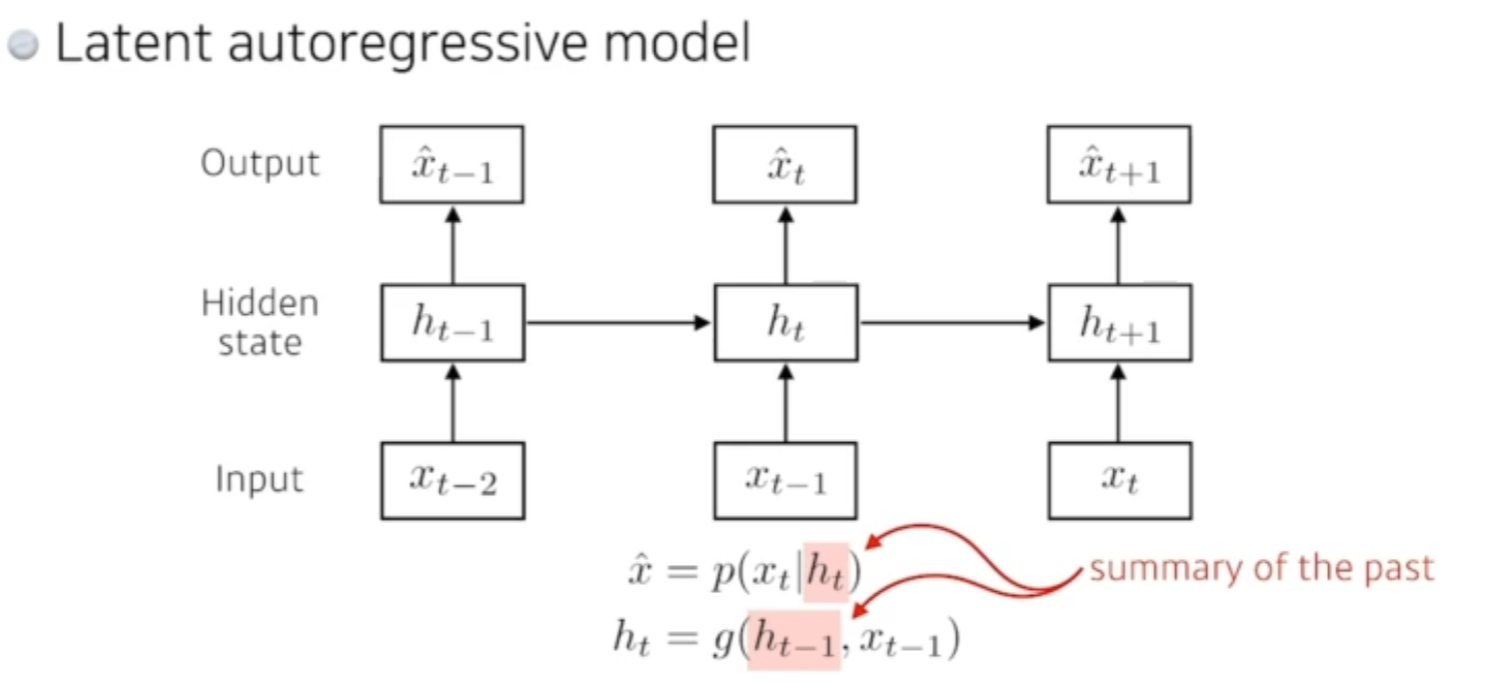
- 과거의 정보를 고려해야하는데 과거의 데이터가 너무 많다
- 하나의 과거와 이전의 정보를 요약하는 hidden state 를 만들어 사용한다.
- 얘가 과거 정보를 summerize 한다고 생각하자.
Recurrent Neural network
이런 컨셉들을 쉽게 구현한 방법이다.
다른점은 자기 자신으로 돌아오는 구조가 있다.
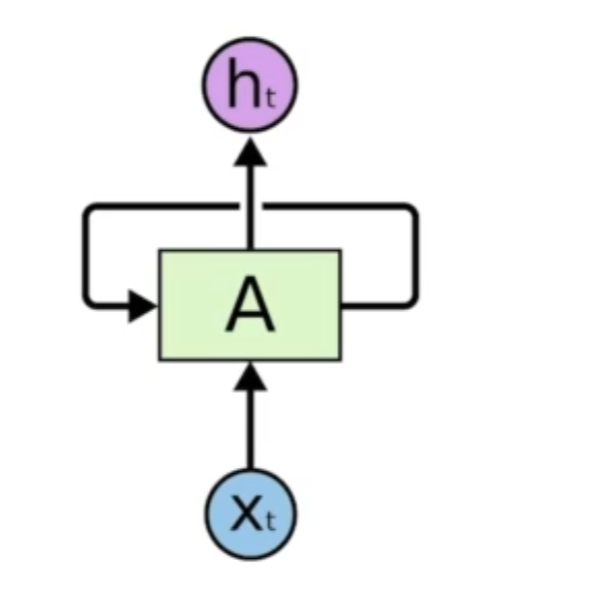
RNN 은 시간순으로 푼다고 말한다.
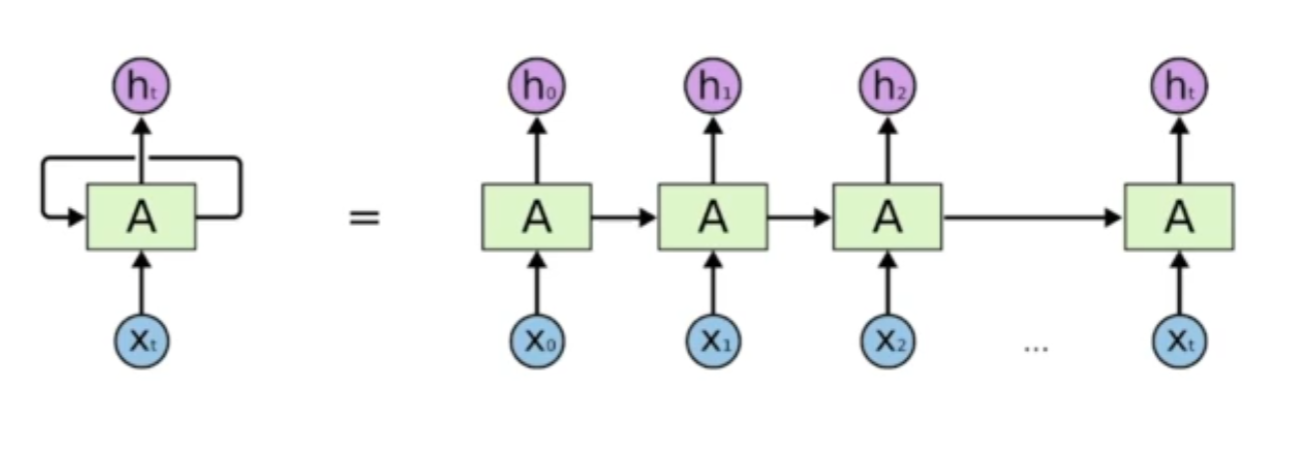
여기서 중요한 사실은 시간순으로 전부 풀게된다면, 각각 네트워크가 쉐어하는 굉장히 분포 위치가 큰 네트워크가 된다.
단점
- Short-term dependencies
- 매우 과거의 정보가 현재까지 살아남기가 힘들다.
- 만약 음성인식을 통해 긴 문장을 인식중이라면, 5초전에 했던 말을 까먹어버리면 문제가 발생한다.
- long-term dependencies
RNN 이 어려운 이유는?
아까 처럼 네트워크를 전부 쭉 풀면 굉장히 커지게 되는데
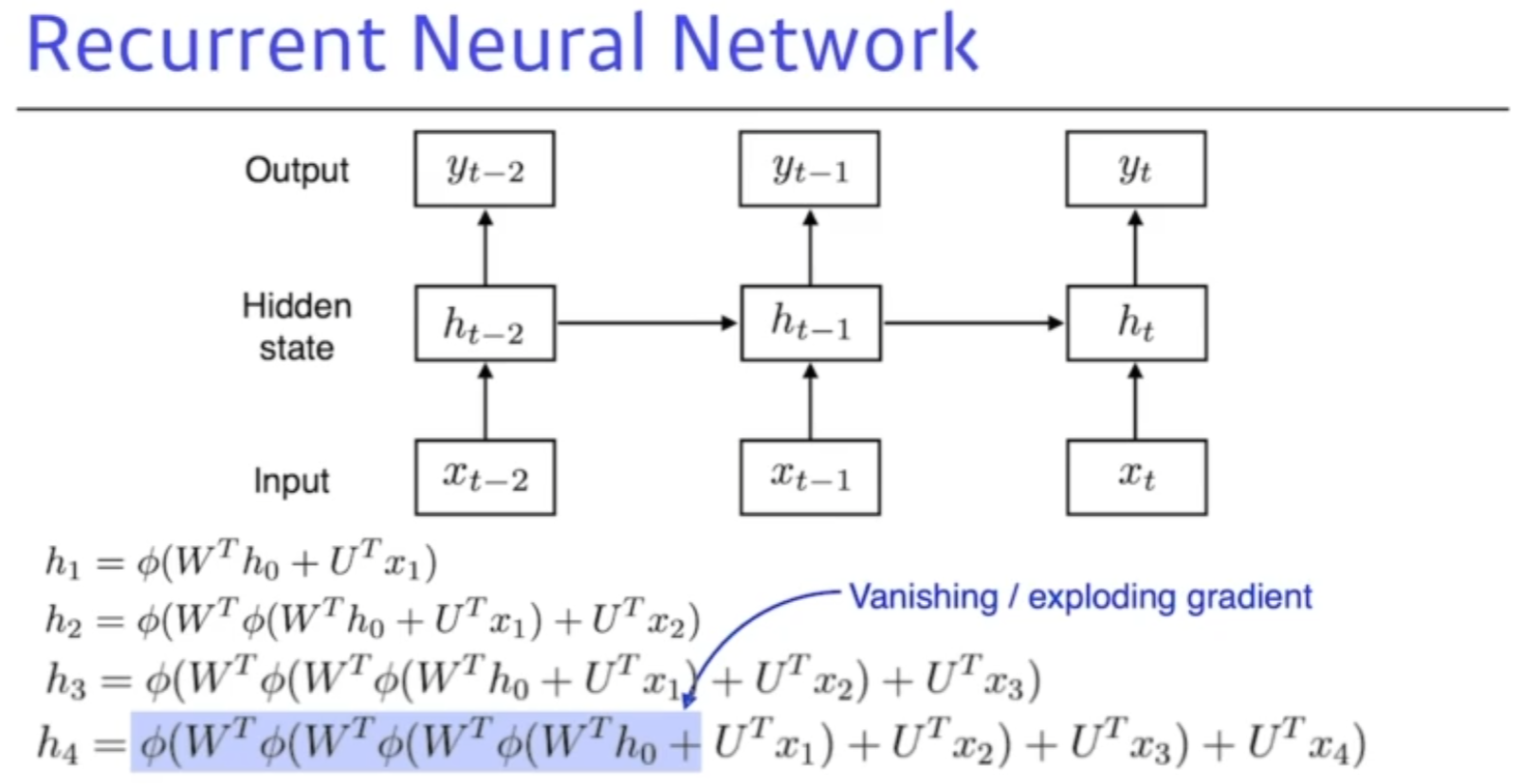
sigmoid - 0~1로 값을 줄여버린다고 치면, 계속해서 값을 활성화 함수에 넣어버리면 값이 점점 작아지고 의미가 없는 숫자로 변해버린다.
vanishing gradient 문제가 발생하거나 exploding 네트워크가 폭팔해버려서 학습이 안된다.
LSTM (Long Short Term Memory)
기존의 바닐라 RNN과 비교
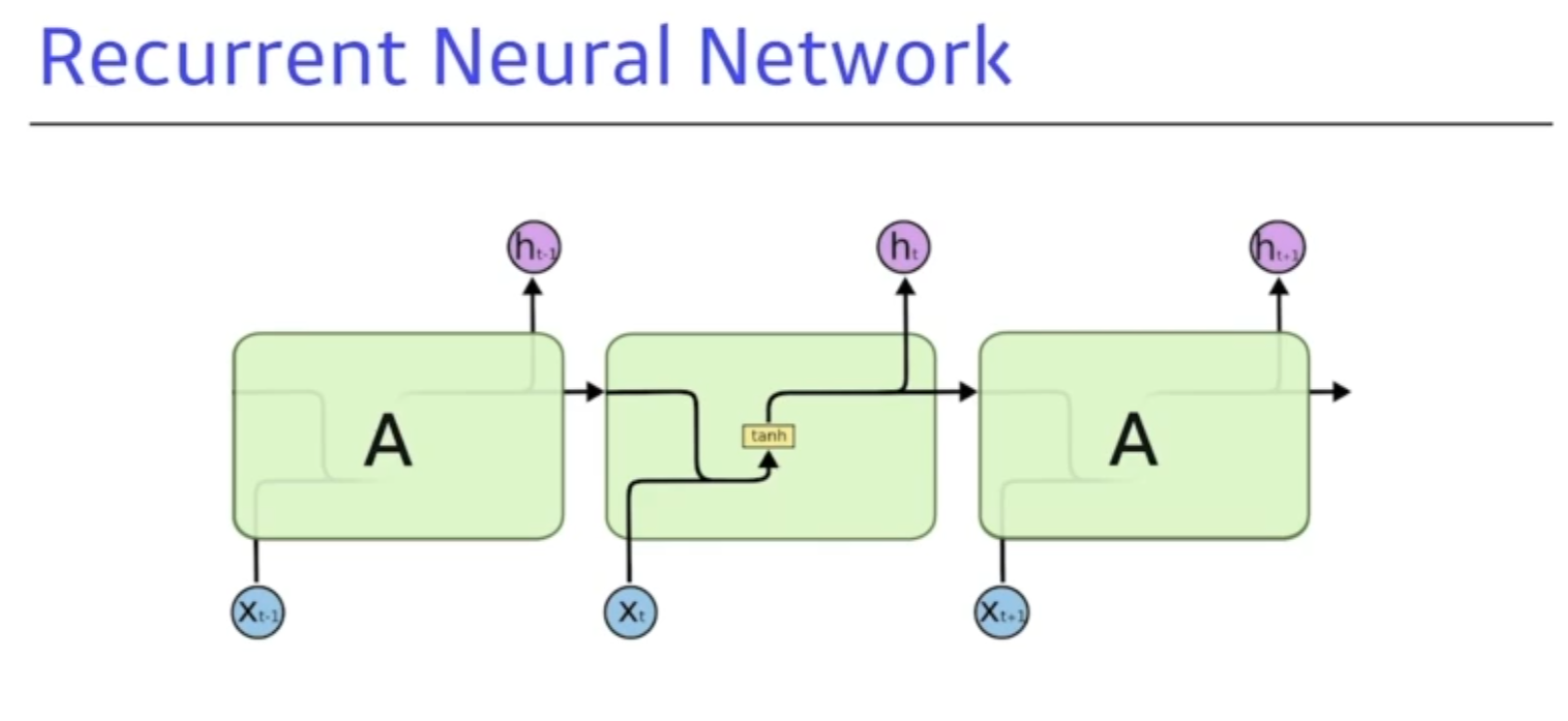
일반적인 바닐라 RNN - 탄젠트 하이퍼 볼릭을 사용
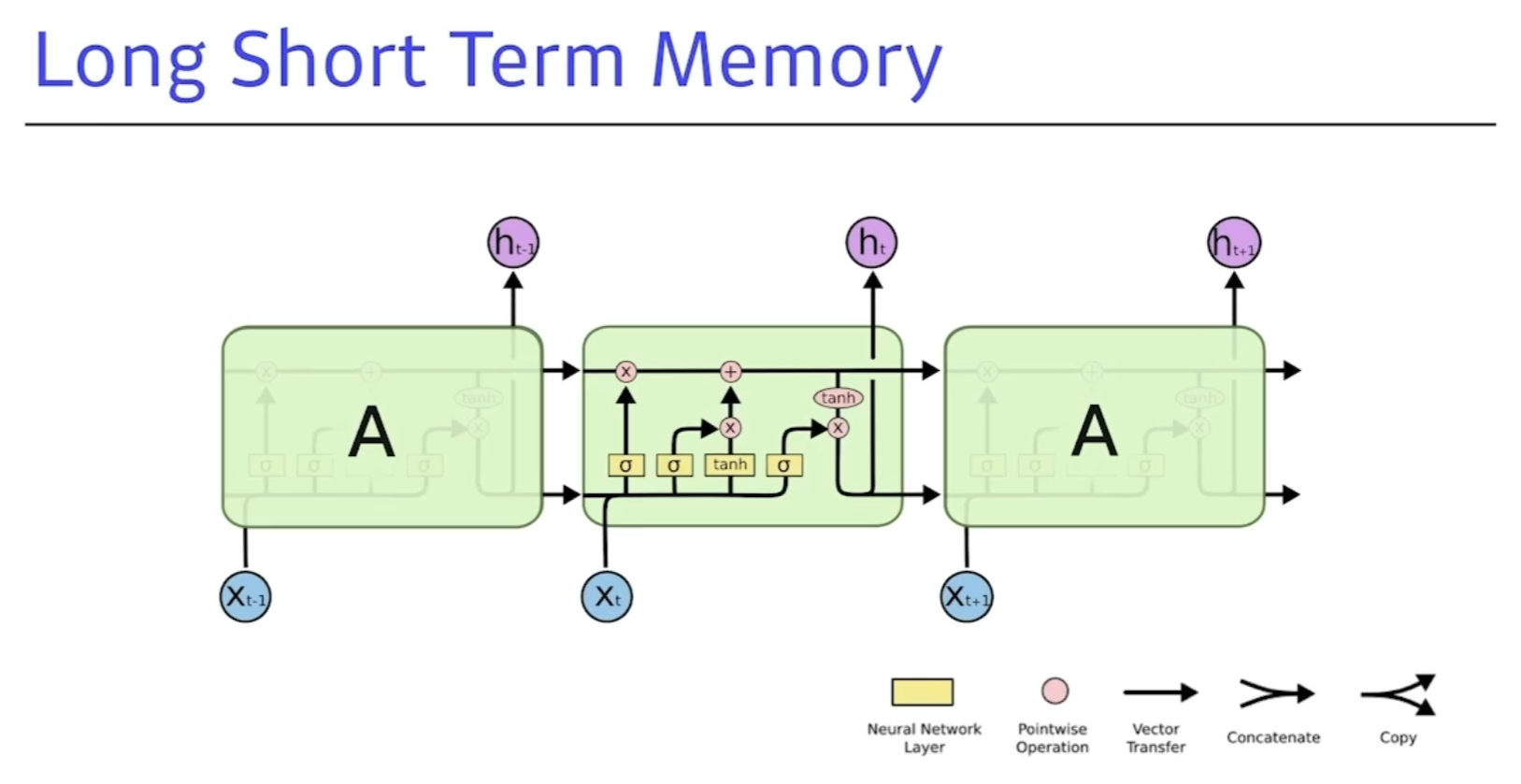
LSTM 의 구조
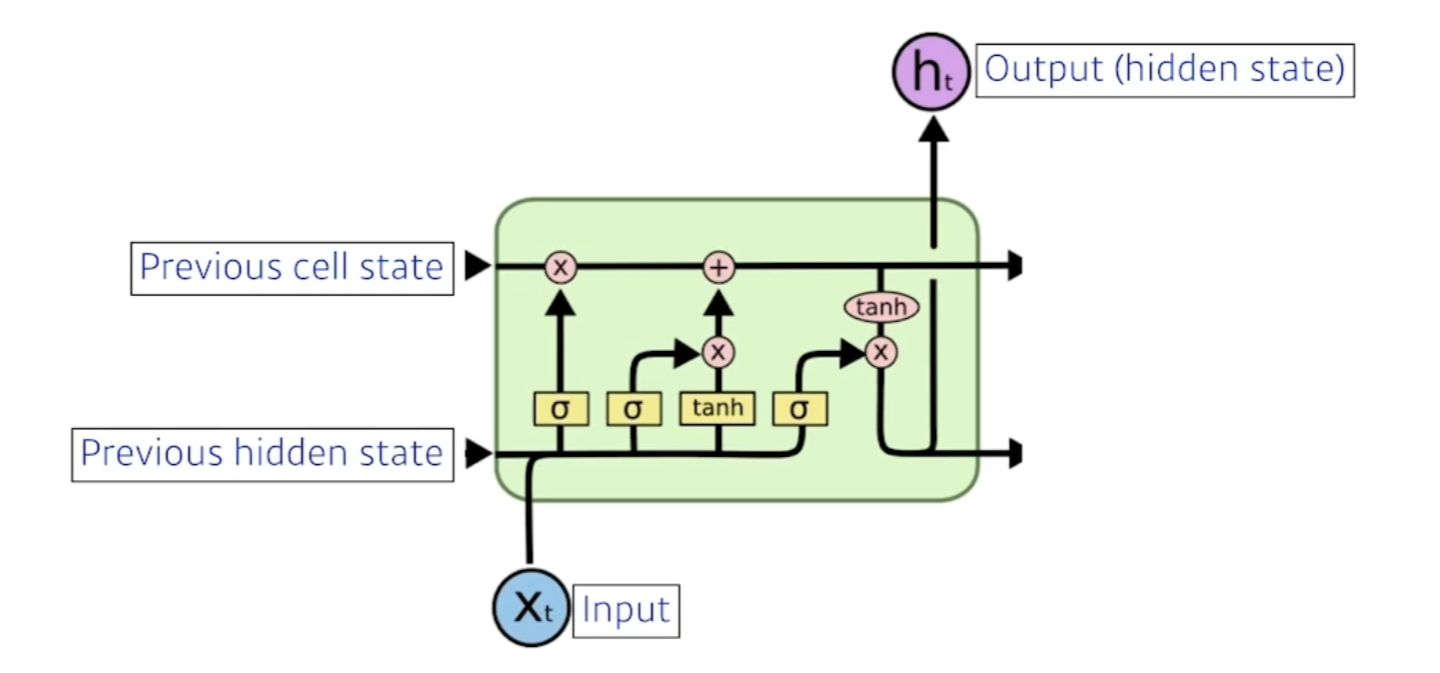
- X는 입력 (랭귀지모델),H는 Output(Hidden state)
- Previous cell state : 내부에서만 흘러가고 결과론적으론 모든정보를 취합해주고 summerize해주는 역할. (0부터 t까지의 정보를)
- Previous hidden state : 이전의 출력값 (Next hidden state로 나감)
Core idea
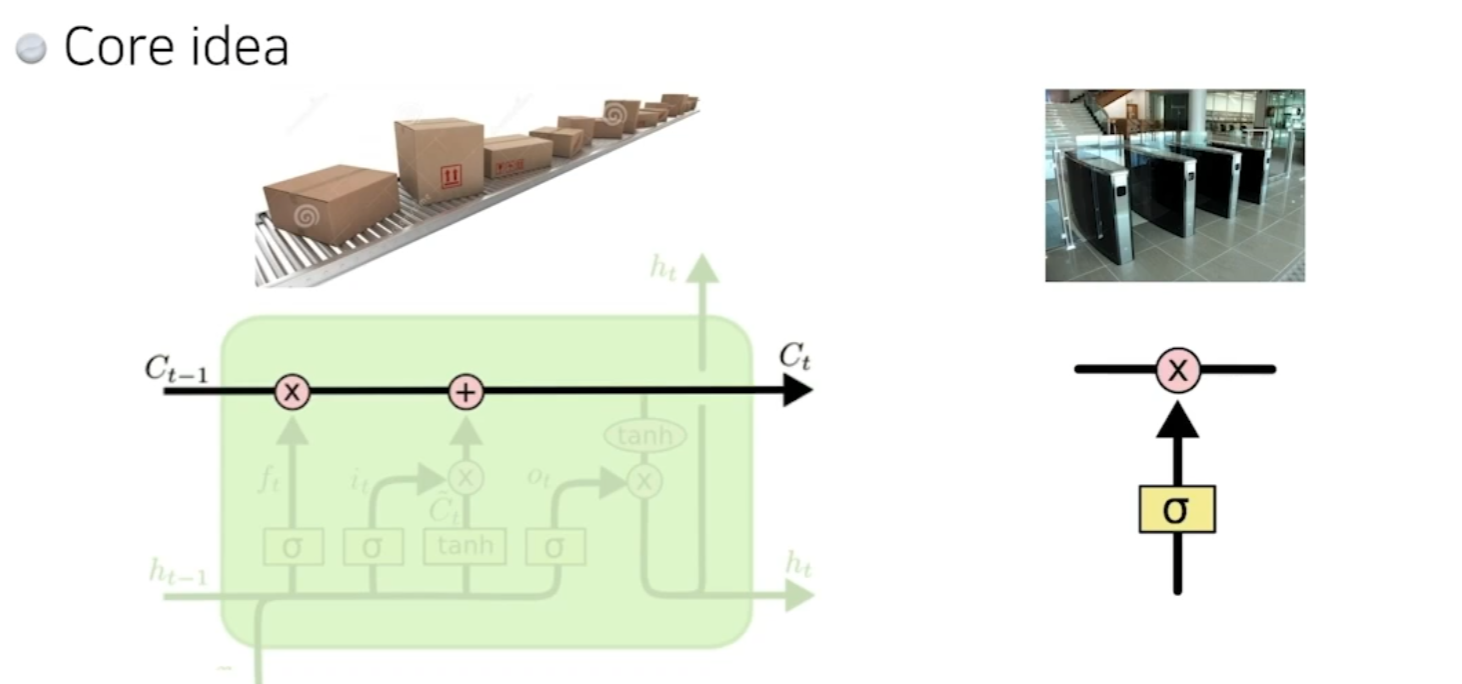
- 마치 컨베이어 벨트 처럼 중간에 흘러가는 cell state가 중요하다.
- 지금까지의 정보를 요약하는 역할을 하고 이 흘러가는 정보를 잘 조작해서 어떤 정보가 유용한지를 판단해서 다음으로 넘겨준다.
- 이걸 잘 판단하는게 게이트이다.
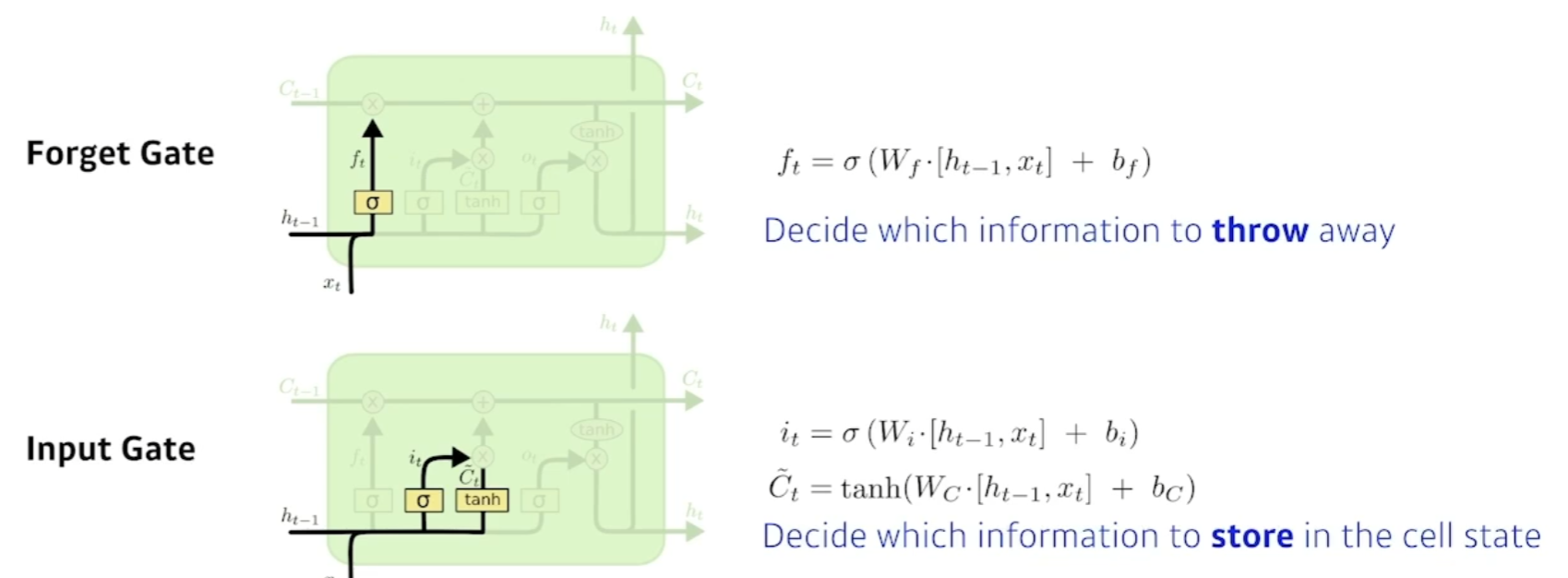
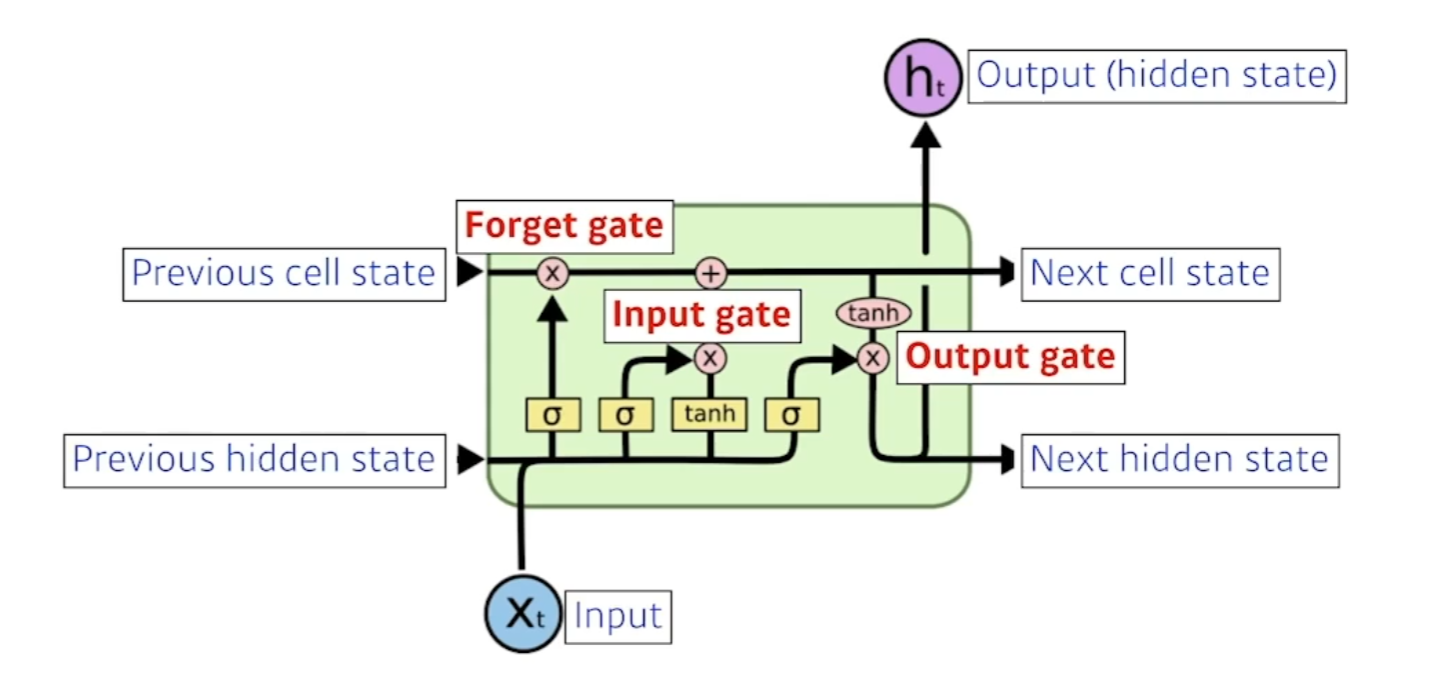
- Forget Gate : 어떤걸 버릴지 정한다 ( sigmoid 를 통과하기에 0~1까지의 값을 가진다.) 이전의 cell state에서 넘어온 정보중에서 버릴것을 정한다.
- Input Gate : 입력으로 들어온값을 무작정올리는게 아니라 이전의 previous hidden state와 x값 입력에서 딥러닝 모델연산을 통해 Ct(씨 틸다) 라는 값을 만든다.
그다음 셀스테이트 캔디데이트를
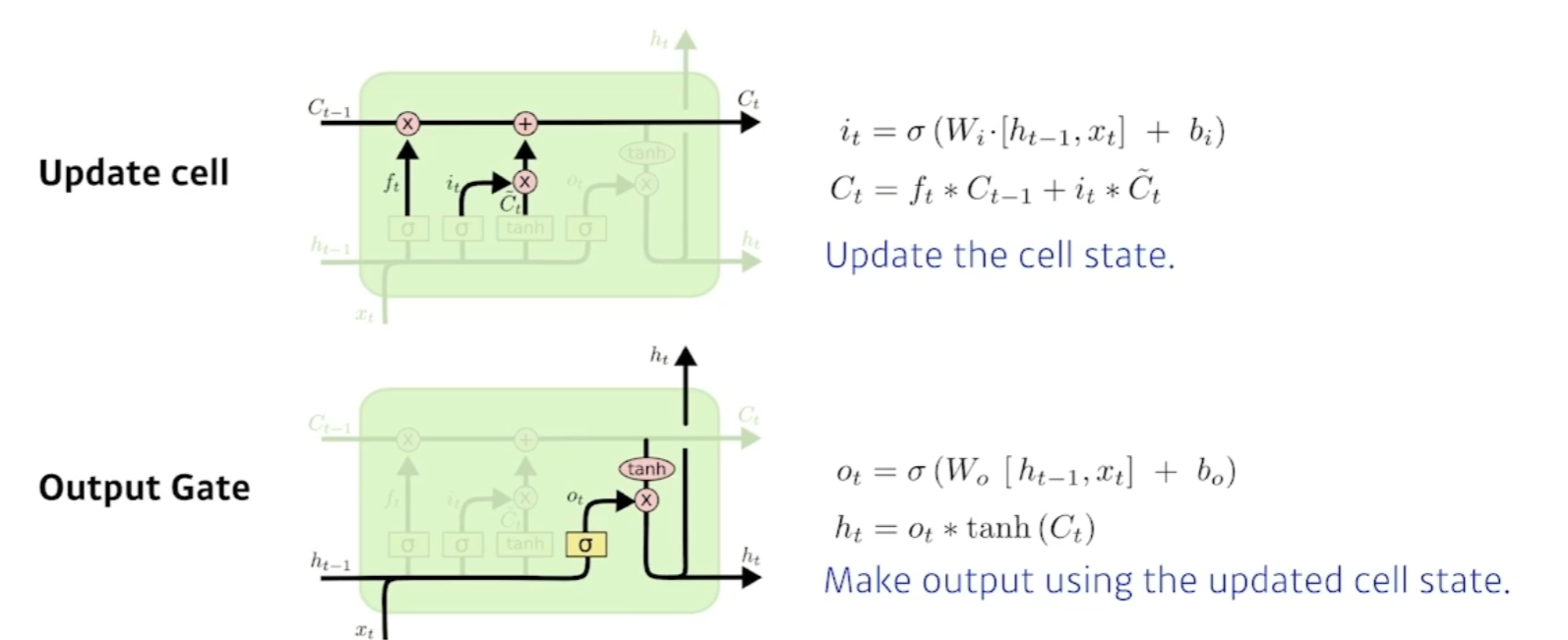
-
Update cell : C틸다 값과 forget gate를 통해 합ㅊ빈다.
-
Output Gate : Next hidden state와 output으로 출력해주는역할.
-
현재 입력으로 어떻게 취합할지, 어떤 값을 밖으로 빼낼지를 정하는것이 output Gate이다.
GRU (Gated Recurrent Unit)
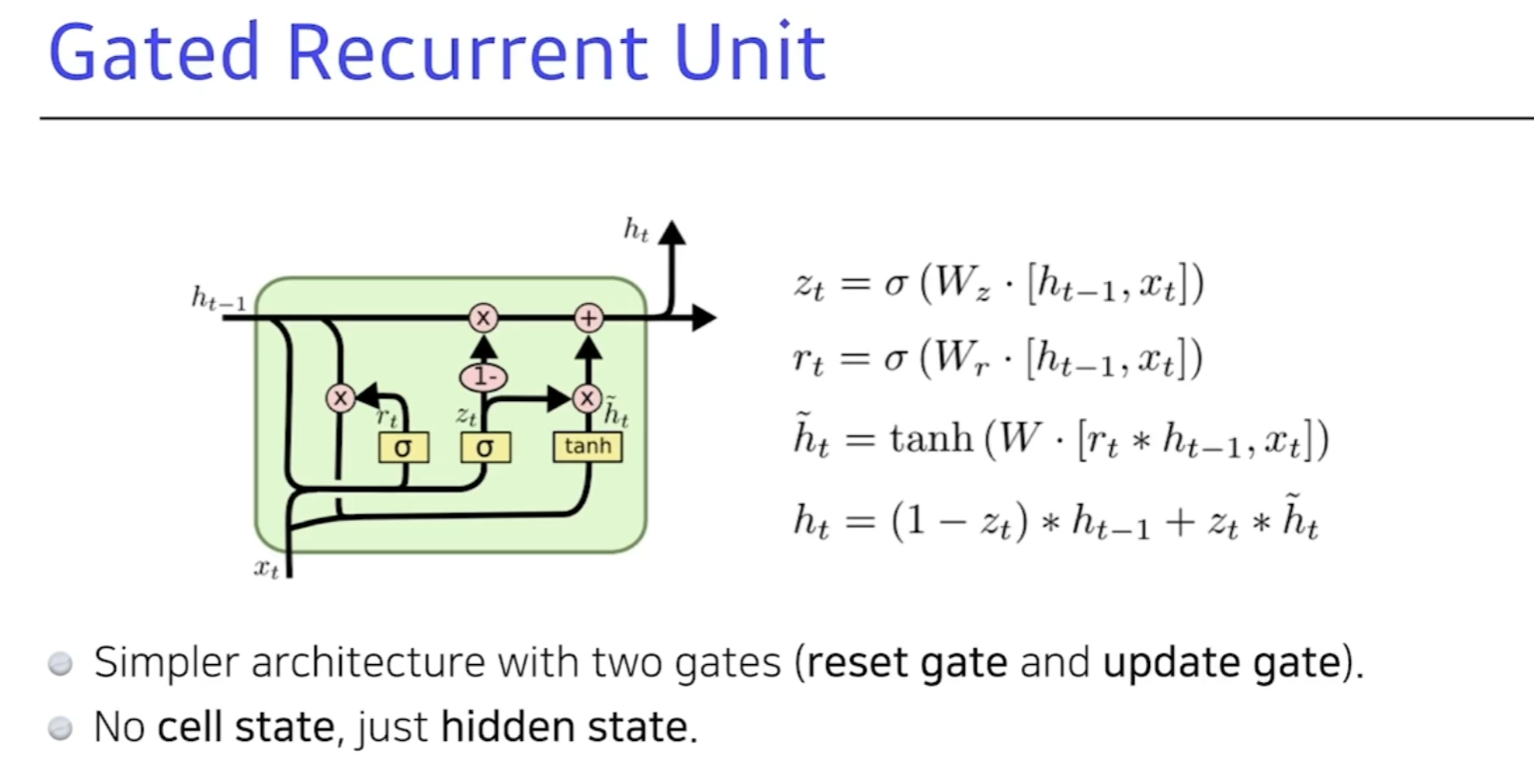
- 게이트가 2개 밖에 없다.
- 앞에는 게이트가 3개였다.
- Reset gate, update gate가 존재. 여기는 hidden state가 곧 output이다.
- reset 게이트는 forget과 유사하다.
- 똑같은 랭귀지모델에 대해 LSTM을 사용할때보다 GRU를 활용할때 성능이 올라갈때가 보인다.(파라미터가 적기때문)
요즘에는 LSTM이나 GRU던 잘 활용하지않는다. 새로운 기술이 등장해서..
- RNN이 가진 단점이 long-term 디펜던시를 잘 해결해야한다.
- 그래서 GRU를 쓰면 많이 좋아지는 양상을 보였다.