Sequential Model
- 연속적인 데이터를 다루는 모델이다.
- 이전 시간에서 배운 RNN의 lSTM 과는 살짝 다르다.
시퀀셜 모델이 어려운이유
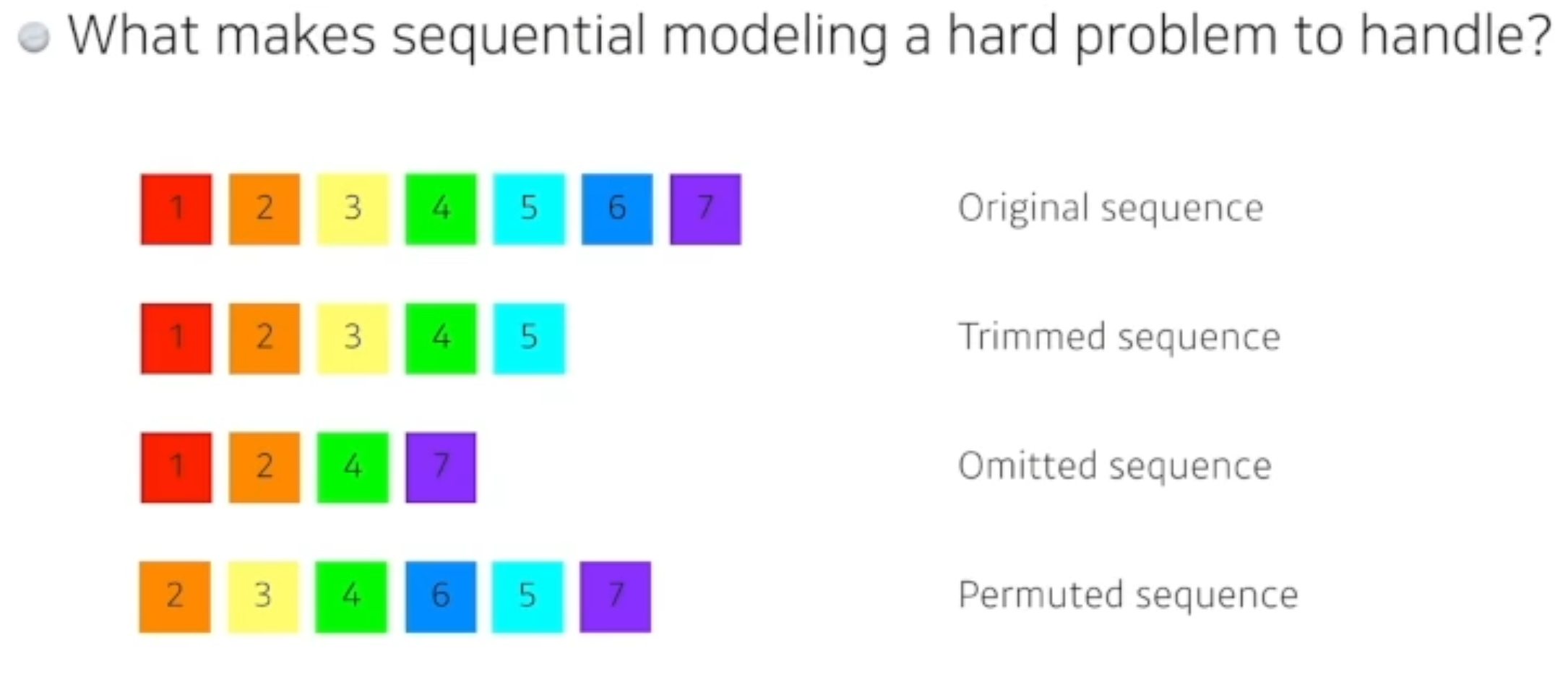
- 말로 문장을 말한다고 하면, 중간에 단어가 빠질수도있고, 중간 어순이 달라질 수도 있고 완벽한 대응구조가 아닐 수도 있다.
Transformer
구현시 자주 사용하는 라이브러리 - huggingface
HuggingFace는 매우 인기있는 Transformers 라이브러리를 구축하고 유지하는 회사입니다.
이 라이브러리를 통해 오늘날 사용 가능한 대부분의 크고 최첨단 transformer 모델을 사용하여 쉽게 시작할 수 있습니다.
-
트랜스포머는 RNN의 재귀적인 반복과는 달리, attention이라 불리우는 구조를 활용하는 시퀀스를 사용한다.

-
기계어 번역문제에 transformer가 어떻게 적용되었는지 설명하겠다.
-
이 방법론은 시퀀셜한 데이터를 처리하고 인코딩하는 방법이라 이미지분류, DALLI(OpenAi 문장이 주어지면 그에 맞는 이미지를 생성)등에 활용된다.
-
실습에서 transformer를 다룰 것이다.(Attention 구조)

- 기본적으로 시퀀셜 to 시퀀셜 모델이다.

- 입력은 3개의 단어라고 보고 출력은 4개가 나왔다.
- 입력 시퀀스의 도메인과 출력 시퀀스의 도메인이 다를 수 있다.
- 동일한 구조를 같지만 인코더와 디코더가 stack되어있는 구조를 가지고 있다.
1.그러면 n개의 단어가 어떻게 한번에 처리되나?
2.encoder와 decoder사이에 어떤정보를 주고받나?
3.decoder가 어떻게 generate 해야하는가?
Self - Attention

-이 트랜스포머가 왜 잘되게 되는지 나타낸다.
- Feed Forward Neural Network 는 우리가 앞서 배웠던 MLP(멀티레이어 펄셉션)와 동일하다.
예시

-
입력으로 3개의 벡터가 들어간다고 한다.
-

-
하나의 벡터 X1이 Z1으로 넘어갈때 X1의 정보를 활용하는게 아니라, X2,X3 의 정보도 활용한다.

- 그래서 self-attention은 의존성(디펜던스)이 존재한다.
- Feed forward 에서 딥러닝 연산이 이루어 진다.
The animal didn't cross the street because it was too tired

- 이 문장을 번역할때 다른 단어들과의 관계를 학습하기 시작한다.
기본적으로 3가지 벡터를 만들어 내는데

- Queries
- Keys
- Values
를 만들어 낸다.
이 3개의 벡터를 통해 X1이라 불리우는 임베딩 벡터라 불리우는걸 새로운 벡터로 바꿔줄 것이다.

-
각각의 단어마다 생성된 쿼리,키,밸류 벡터를 통해 Score 벡터를 계산해준다.
-
내가 인코딩을 하고자 하는 쿼리 벡터와 나머지 모든 n개의 키벡터를 구한다.
-
그 두개를 내적을 한다.
-
이 두벡터가 얼마나 align이 잘 되어있는지 의미.
-
I번째 단어가 n개의 단어와 얼마나 관련이 있는지를 확인한다.
-
내가 인코딩을 하고자 하는 쿼리 벡터와 나머지 벡터들의 key벡터들을 구하고 그 두개 사이를 내적을 한다.
-
내가 Thinking 의 단어를 인코딩할때 다른 단어와 어떻게 관계형성되나를 중점으로 봐야한다. (Thinking 을 잊으면 안됨)

- 그다음 attention weights 가중치를 softmax를 통해 구해준다.

-
임베딩 벡터가 주어지면 각 임베딩 벡터를 기준으로 쿼리,키,밸류를 만들고
-
그리고 나서 나오는 키벡터와 밸류벡터의 내적으로 score벡터를 만듦.
-
걔를 softmax 취한다음에
-
각각 단어에서 나오는 value벡터들의 weight들의 sum이 된다.
-
결국 value 벡터들의 weight를 구하는 과정이 normalize하고 softmax취하고 구해준다.
-
최종적으로 Thinking이라는 벡터에 Encoding된 벡터가 나오게 된다.
주의 : 쿼리와 키벡터는 크기가 같아야함.
하지만 value는 달라도 됨(weight sum을 하기만 하면됨)
최종적으로 나오는 Thinking에 인코딩된 벡터의 차원은 encoding벡터와 차원이 같다.
행렬을 통해 활용해보기
- 위 과정을 행렬을 통해 쉽게 구현할 수 있다.

위 과정이 위 수식으로 한번에 요약 가능하다.
- MLP(멀티레벨펄셉션) 보다는 좀더 플렉서블하다.
- 입력이 고정돼도 출력이 달라 질 수 있다.(트랜스머 모델의 특징. 이러기 때문에 컴퓨테이션이 더 필요할 수 있다.)
- NxM 짜리 RNN은 1000개가 있으면 1000번 돌리면 된다. 오래걸리긴 하지만 결국 단어를다 처리 할 수있다.
- 하지만 트랜스 포머는 length가 길어지면 처리할수 있는 한계가 존재한다.(1000개를 제곱하는 경우로 가기 때문)
- 하지만 더 다양하게 표현할 수 있게 된다.
MHA ( Multi - headed attention )

- n개의 attention을 반복하면 n개의 인코딩된 벡터가 나오게 된다.

-
고려해야 될 것 :
- 인코딩이 다음번으로 넘어가야한다.
- 입력과 출력의 차원을 맞춰야함.
- n개의 output이 나오니까 learnable linear map인 80x10짜리 행렬을 곱해서 10차원으로 줄여버린다.

- 실제 구조는 이렇게 만들어져 있지 않다.(코드상)
- 100디멘션의 10개 헤드를 사용한다고 하면 100디멘션을 10개로 나누고, 실제로는 10디멘션에서 key,value,query 벡터를 만든다.
position encoding
트랜스포머 구조를 잘 생각해보면,
연속된 정보는 이 안에 포함되어 있지 않다.
A,B,C,D 를 넣거나 B,C,D를 넣거나, B,D,A 를 넣어도 인코딩 되는 값이 달라질 수가 없다.
order 에 인디펜던트하다.(독립적이다.)
어떤 단어가 먼저나왓고, 이런게 중요하지 않다. 이미지도 마찬가지.
그래서 position encoding이 필요하다.
특정 방법으로 벡터를 만들게 되고 각자 단어에 해당하는 값을 그대로 더해준다.

특정 값을 미리 만들어진걸 그대로 더해준다.
-> 왜 Transformer 구조는 인풋 오더에 독립적일지 생각해보자.
Self - attention 2
-
계속해서 feed-forward를 반복하고 인코딩된 벡터에 대해서 독립적으로 동작하는걸 반복하게 된다.

-
그림으로는 점선으로 표현되어있지만, 실제론 key와 value를 보내게 된다.
-
I번째 단어의 쿼리벡터와 나머지 단어의 key벡터를 구해서 attention을 만들고 value벡터를 weight sum을 하게 된다.
-
그렇기 때문에 input 에 해당하는 key,value벡터가 필요하다.

-
이 self-attention구조가 번역에서만 사용됐었는데
-
이미지도메인 관련해서도 사용되고 있다.

-
DALL-E Open AI 에서 나온 API도 Transformer 의 decoder만 활용을 했으며 16x16 정도 그리드를 나눠서 시퀀스에 집어넣고 새로운 문장이 주어졌을때 문장에 대한 이미지를 만들수 있는 방법론을 제안했다.
- MHA(multi-headed Attention) 을 앞으로 실제 실습코드에서 사용하게 될것이다.