1. Intro to Generative Models
인식 vs. 생성 및 변환
인식 태스크(Classification, Regression)
정보 : 범주형(Categorical) / 연속형
Input Image : 64x64x3(W x H x Channel)
범주형 - 남자/여자
연속형 - 25세, 36세
Semantic segmentation, Object detection, Facial Detection, Facial Landmark detection(localization), Pose estimation, etc
생성 태스크(Generation Tasks)
Latent Code(128-dimensional vector) -> Image(64x64x3)
Latent Code ~ N(0,1):Gaussian Distribution sampling
변환 태스크 - 조건부 생성 모델의 한 형태
갈색말 -> 얼룩말
여름 -> 겨울
VAE의 이해
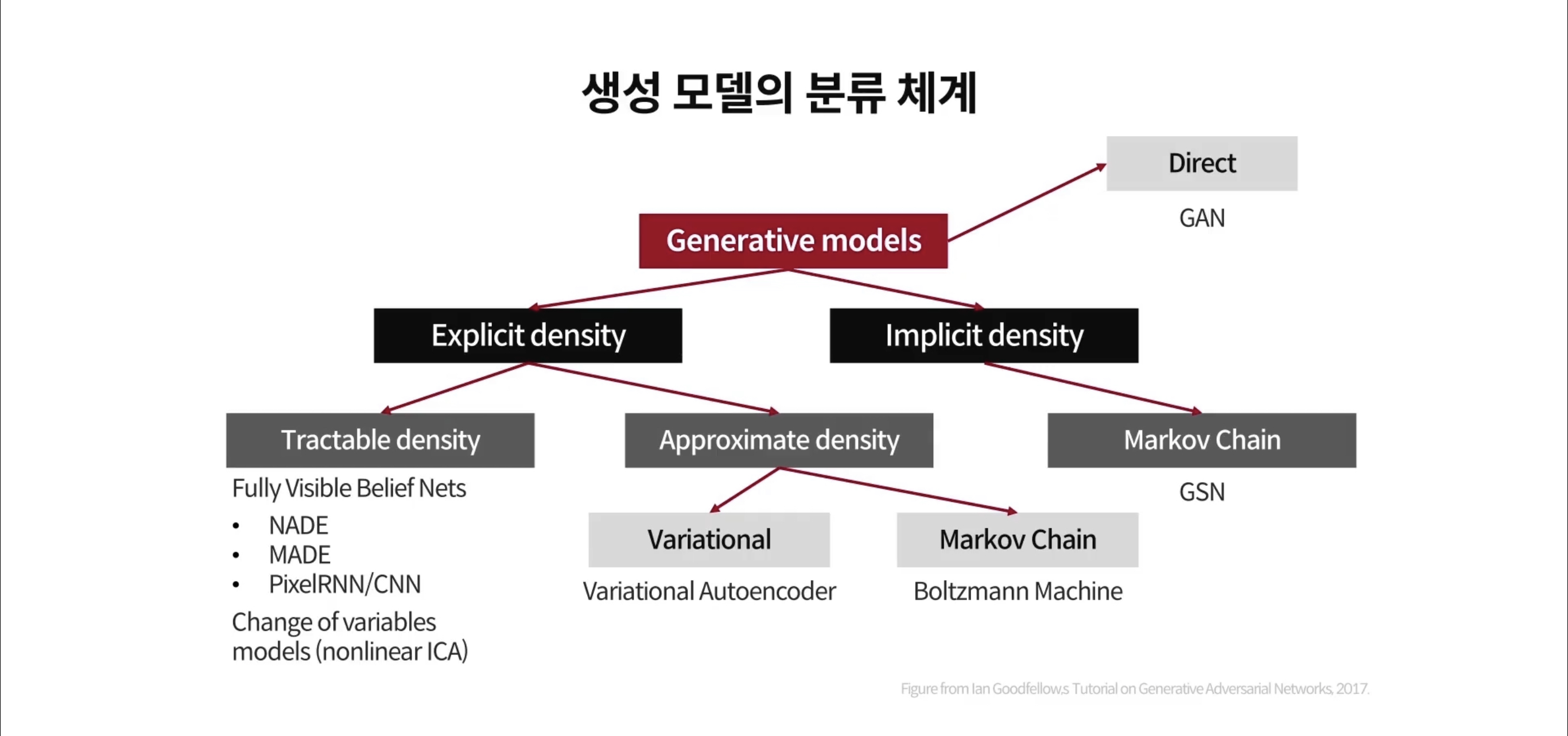
<생성모델의 분류>

Auto Encoder란?
auto(자기 자신) Nx1 벡터로 표현하게 되면 고차원 input이 되는데 이를 압축한 뒤(encode) 다시 원래의 크기로 복원(decode)하는 과정
압축하는 과정에서 여러 input들이 공통으로 갖는 특징을 위주로 추출하여 decoding 과정에서 사용
VAE(Variational Auto-Encoder)

- Encoder의 output(압축 vector)을 확률변수로 모델링하여 sampling 후 추출하여 decoder의 input이 됨
- Encoder의 input vector(3-dimension) 원소 각각은 Normal Distribution 따르는데 분포의 평균과 분산을 Encoder network가 추정하여 산출
- Encoder는 6-dimension vector를 생성: 처음 3개는 각각의 평균, 나중 3개는 각각의 편차를 계산
- Decoder에서는 각각의 Normal Distibution으로부터 랜덤하게 샘플링하여 input으로 넣게 됨
학습 프로세스가 간단하면서 안정적이다
순수 생성을 위한 목적으로 사용될 수 있다
가끔은 흐릿한 이미지를 생성한다
VAE 학습 과정

얻게된 Loss값을 back propagation하여 train을 하고자 할 때, sampling 단계때문에 gradient update가 어려워진다.
이를 해결하고자 Reparametrization trick을 사용
Affine Transformation y = Ax + B
2. Generative Adversarial Networks(GAN)
Generator and Discriminator
복잡하고 고차원적인 학습분포로부터 데이터를 샘플링하고자 하나, 직접적으로는 불가능 -> 간단한 분포 이용, NN 사용
각 sample z 가 어떤 학습 이미지로 매핑이 되는지 알 수 없음(학습 이미지를 복원하는 것으로는 학습이 불가능) -> Discriminator Network 사용하여 생성 이미지가 데이터 분포 내에 속하는지 판단
Discriminator Network <-> Generator Network

Objective Function
"Mini-Max의 최적화"
Discriminator :
real, fake data를 입력받아 각각 1,0의 binary classification을 하도록 학습(with BCELoss), 최소화 하고자하는 것은 negative log likelihood
Generator :
1-D(G(z)): negative class라고 맞출 likelihood
 -> 왜냐하면 X~pdata(x) : real data not from G(z)
-> 왜냐하면 X~pdata(x) : real data not from G(z)
min(D) : gradient descent를 통해서 D를 업데이트
max(G) : gradient ascent를 통해서 G를 업데이트
min,max를 통해서 saddle point로 수렴하게끔 움직임

한가지 문제가 발생하는데, Generator과정이 오래 걸리기도 하고 초반에는 안 좋은 퀄리티의 이미지가 생성되기 때문에 real data와 discriminator의 과정이 비교적 쉬워지게 된다. 초기에 발견되는 gradient를 바탕으로 back propagation
3. GAN 모델의 학습 안정화
GAN의 학습 안정화를 위한 기법
1. LSGAN(Least Squares Generative Adversarial Networks

Discriminator 학습에 binary cross entropy loss대신 least squares loss를 사용.
Sigmoid layer를 삭제하고 직접적으로 loss function의 input으로 간다.
-∞ < D(x) < ∞
- BCELoss 에서 vanishing gradients 문제발생
- 생성 이미지들의 품질이 향상
- gradient vanishing 문제 해결
- b=c=1 적용하여 D의 결과가 1에 가깝도록 학습하게 된다.
- mode-collapsing 없이 안정적인 학습이 가능
mode-collapsing : 임의의 2차원 벡터를 사용하여 GAN을 학습시켰을 때, 원래의 분포와 비슷한 분포를 갖게끔 생성되는가를 test할 때, 학습시키려는 모형이 실제 데이터의 분포를 모두 커버하지 못하고 다양성을 잃어버리는 현상
collapse 된다면 한가지 유형으로 치우쳐 학습하게 될 수 있다.
2. Improved Wasserstein GAN(WGAN-GP)
WGAN with gradient penalty(regularization)
[본 포스팅은 주재걸 교수님의 이미지/영상 생성 클래스 강의를 수강하며 요약한 내용입니다.]
