Dataset Distillation_paper
[Abstract]
Knowledge distillation과는 다르게 모델을 고정시키고 large training dataset의 knowledge를 작은 dataset으로 distill하는 새로운 데이터셋 압축 방법을 제시한다.
압축이라기보다는 데이터셋을 오리지널 데이터에 가깝게 '합성'하는 것에 가깝다.
Introduction
MNIST와 CIFAR100 dataset을 대상으로 dataset distillation을 진행하면 다음과 같이 된다.
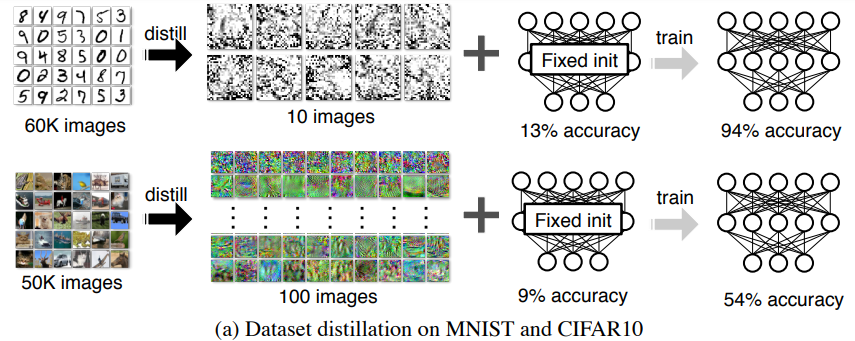
Key Question : 데이터셋을 작은 합성 데이터셋으로 압축하는 것이 가능한가?
=> 합성된 트레이닝셋은 오리지널 데이터셋의 분포를 따르지 않을 것이기에 불가능했지만 gradient update를 통해 가능한 알고리즘을 제안
모델의 가중치를 업데이트하여 최적화하는 것 대신에 distill될 이미지들의 픽셀값을 최적화한다.
Related Work
Knowledge Distillation KD는 여러 개의 네트워크의 지식을 하나의 네트워크로 distill하는 것이 목적이지만 DD에서는 전체 데이터셋의 knowledge를 적은 숫자의 합성된 트레이닝 데이터에 distill하는 것이 목적이다.
Dataset pruningn, core-set construction, instance selection KD 이외에 knowledge를 distill하는 방법에는 전체 데이터셋을 모델 학습을 통해 얻어진 요약적인 작은 부분 데이터셋으로 만드는 것이 있다. 또한 Core-set construction, instance selection method도 있다. Core-set construction의 예시로는 퍼셉트론, SVM가 있다. 하지만 이렇게 subset을 만드는 방법들은 카테고리당 많은 숫자의 sample이 필요하게 되어 비교적 비효율적일 수 있다.
Gradient-based hyperparameter optimization gradient backpropagation update를 통해 parameter를 최적화하는 것이 아니라 synthetic training data 를 최적화하는 것이 목적이다.
Approach
- Gradient Descent step
- Randomly initialized weights, distributions
- Linear netwrok
- Iterations(epochs)
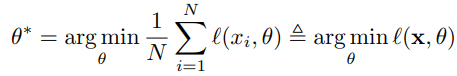
x : original dataset, l(x,θ) : loss function
θ*: optimal parameter space
OPTIMIZING DISTILLED DATA
각 에폭마다 다음과 같이 parameter를 update하게 된다.
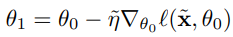
θ가 수렴하기 위해서는 엄청나게 많은 반복이 필요하기 때문에 다음과 같이 초기화 한 후, M << N인 M 크기의 training data를 합성하게끔 한다.
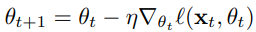
적은 수의 데이터만으로도 전체 데이터를 학습한 것과 동일한 효과를 내기위해서 다음과 같이 식을 도출한다.
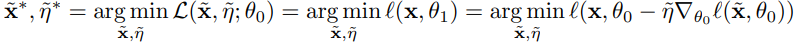
DISTILLATION FOR RANDOM INITIALIZATIONS
Training dataset 과 θ0를 encode 하다보니 distilled data가 random noise처럼 보이는 경향이 있다. 이것을 해결하기 위해 다음과 같은 식을 도입하게 되었다.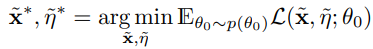
θ0를 분포 p(θ0) 로부터 랜덤하게 sampling한다.
ANALYSIS OF A SIMPLE LINEAR CASE
: Formulation in simple linear regression problem with quadratic loss
Distilled data의 사이즈에 lower bound를 설정해야한다.
OG data의 크기를 N, D dimension이라고 할 때
d = N x D vector, t= N x 1 target vector
MSE는 다음 식과 같이 된다.
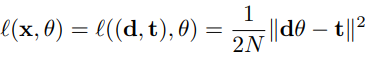
실제 전체 데이터의 손실 함수의 값과 압축 데이터의 손실 함수의 값이 동일하게 감소하도록 모델을 훈련한다.

한 번의 Gradient Descent update후 paremeter는 다음과 같이 update된다.
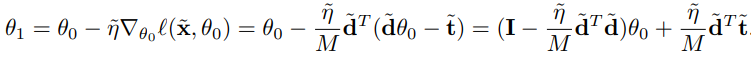
MULTIPLE GRADIENT DESCENT STEPS AND MULTIPLE EPOCHS
↓Backpropagate updating steps
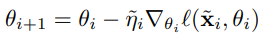
순전히 grdadient를 계산하기에는 메모리 사용량, 계산량이 상당하기 때문에 back-gradient optimization을 적용한다.(Hessian-vector product)
DISTILLATION WITH DIFFERENT INITIALIZATIONS
1. Random initialization
2. Fixed initialization
3. Random pre-trained weights
4. Fixed pre-trained weights
Experiments
MNIST, CIFAR10, PASCAL-VOC, and
CUB-200를 대상으로 실험을 진행
↓ Fixed Inintialization

↓ Random Initialization
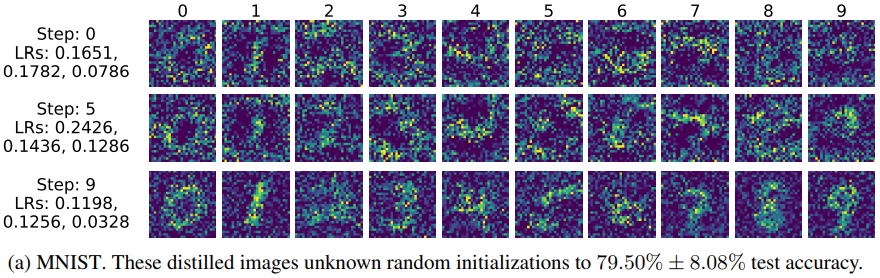
MNIST 학습 결과 93.76% accuracy를 얻었고 CIFAR10 학습 결과 54.03% accuracy를 얻었다. MNIST와 다르게 CIFAR10 은 형체를 알아보기 어려워 정확도를 높이는 것이 사람의 입장에선 상식적으로 어려워보인다.
