이 포스트에서 다룰 것
- 정규표현식 테스트 사이트를 적극 이용하여,
- 정규표현식의 문법을 정리하고 몇 가지 예제를 풀어본다.
- 자주 쓰이는 정규식을 작성해 본다.
- 자바스크립트와 php에서의 활용 예시를 알아본다.
들어가며
2년동안 미뤄 둔 정규표현식을 드디어 공부한다. 공부해야지 생각만 하며 외계어 같고 어려워 보여서 미뤄뒀는데, 코딩테스트에서 문자열을 처리할 때 뿐만 아니라 실무에서도 정말 많이 쓰인다는 걸 깨달았다. 특히 회원가입 같은 기능을 만들 때, 이메일이나 전화번호를 sanitize할때는 무조건 쓰인다는 걸 업무 하면서 알게 되었다.
이게 뭐라고 2년이나 미뤄서 한심하지만 지금이라도 공부하는 내가 대견하다고 스스로에게 비난과 칭찬을 동시에 하며 포스팅을 시작한다.
정규표현식이란
Regex(Regular Expression)이라고도 불리는 정규표현식은, 텍스트에서 우리가 원하는 특정한 패턴을 찾을 때 유용하게 쓰이는 형식 언어이다.
예를 들면, 아래와 같은 많은 텍스트 중에서 전화번호(000-0000-0000)만을 추출해야 한다거나, 웹사이트 주소 형태(https://velog.io/@hyun)의 패턴을 찾아야 한다고 가정해 보자. 정규식을 이용하면 이런 작업들이 아주 간단해진다.
Contrary to popular belief, Lorem Ipsum is not simply random text. It has roots in a piece of classical Latin literature from 45 BC, making it over 2000 years old. Richard McClintock, a Latin professor at Hampden-Sydney College in Virginia, looked up one of the more obscure Latin words, consectetur, from a Lorem Ipsum passage, and going through the cites of the word 010-1234-5678 in classical literature, discovered the undoubtable source. Lorem Ipsum comes from sections 1.10.32 and 1.10.33 of "de Finibus Bonorum et Malorum" (The Extremes of Good and Evil) by Cicero, written in 45 BC. https://velog.io/@hyun This book is a treatise on the theory of ethics, very popular during the Renaissance. The first line of Lorem Ipsum, "Lorem ipsum dolor sit amet..", comes from a line in section 1.10.32.
또는, 회원가입을 할 때 비밀번호는 대문자+소문자+특수문자를 포함해야 한다는 등의 특정 조건을 걸거나 이메일이 올바른 형식인지 유효성을 검사할 때도 사용된다.
정규식 사용법
/regex/i정규식의 형식은 위와 같다. 슬래쉬(/)를 이용해서 정규식임을 알리고, 그 안에서 원하는 패턴을 작성해 주면 된다. 마지막 i는 어떤 옵션을 사용해서 검색할 것인지를 정하는 플래그이다.
정규식 문법
이제 본격적으로 정규식의 문법에 대해 공부할 것이다. 4가지 카테고리로 나누어서 알아볼 것이다.
Group and Ranges
|또는()그룹[]문자셋, 괄호 안에 어떤 문자든[^]부정 문자셋, 괄호 안에 어떤 문자가 아닐 때(?:)찾지만 기억하지는 않음
텍스트 검색
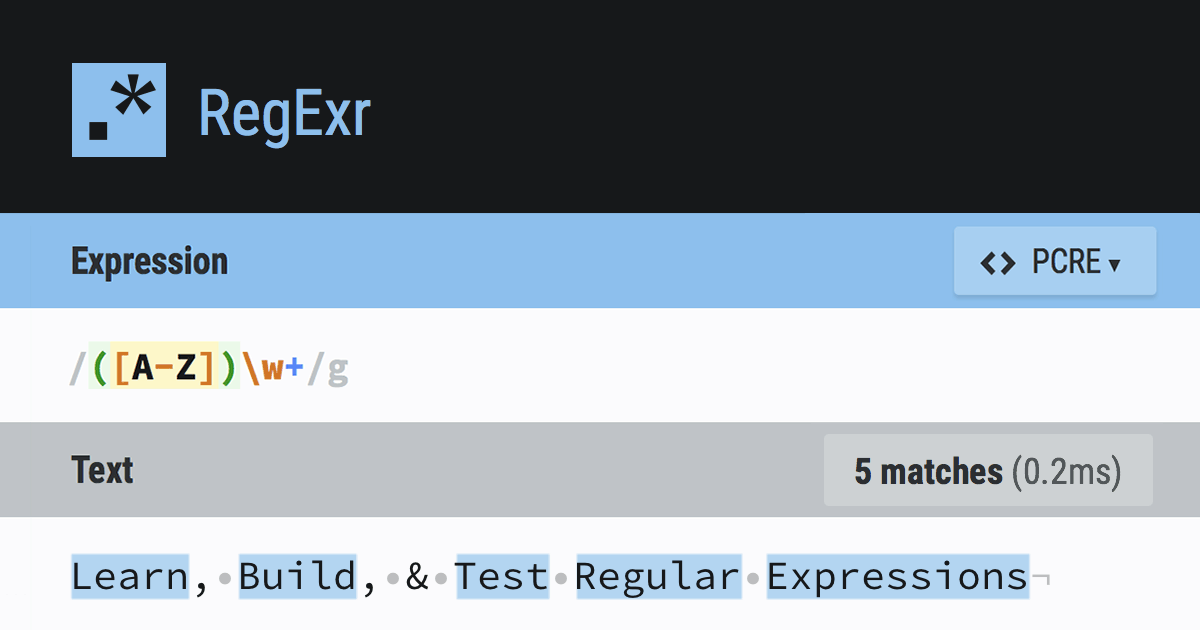
 정규표현식에서도 위와 같이 일반적인 텍스트를 검사할 수 있다.
정규표현식에서도 위와 같이 일반적인 텍스트를 검사할 수 있다.
or 연산자 |
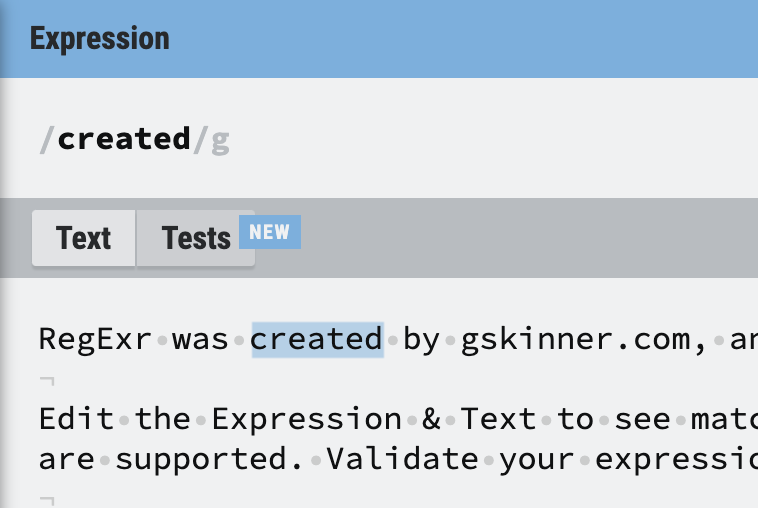
 프로그래밍 언어에서 사용하는
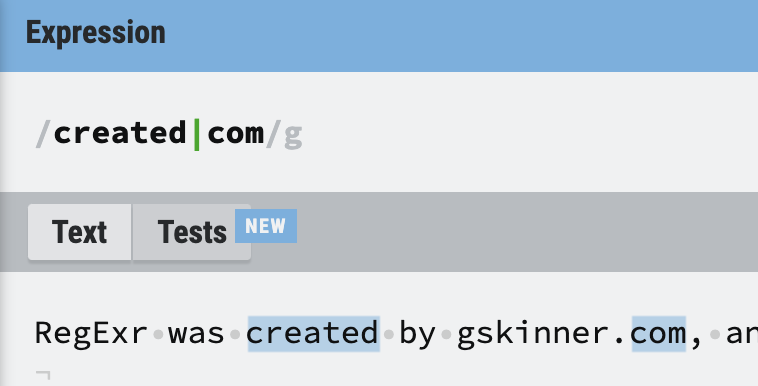
프로그래밍 언어에서 사용하는 |를 정규식에서도 똑같이 사용할 수 있다. 위와 같이 정규식을 입력하면 crated 또는 com이 매칭된 것을 확인할 수 있다.
그룹 지정 ()
소괄호()를 이용해 그룹을 지정할 수도 있다.
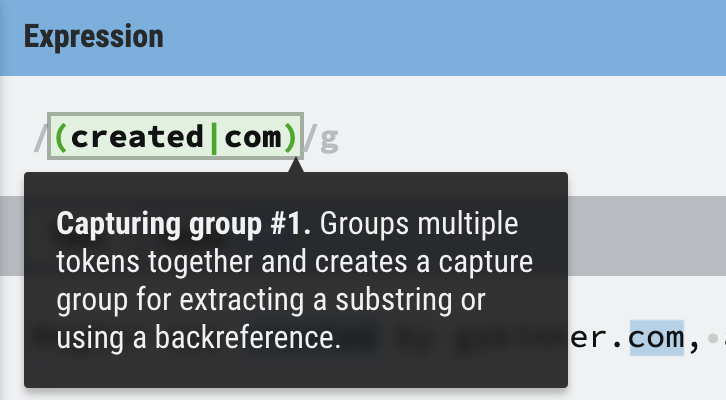 소괄호를 사용해 감싸주게 되면 매치가 되는 동시에 created와 com이 하나의 그룹으로 묶이게 된다.
소괄호를 사용해 감싸주게 되면 매치가 되는 동시에 created와 com이 하나의 그룹으로 묶이게 된다. 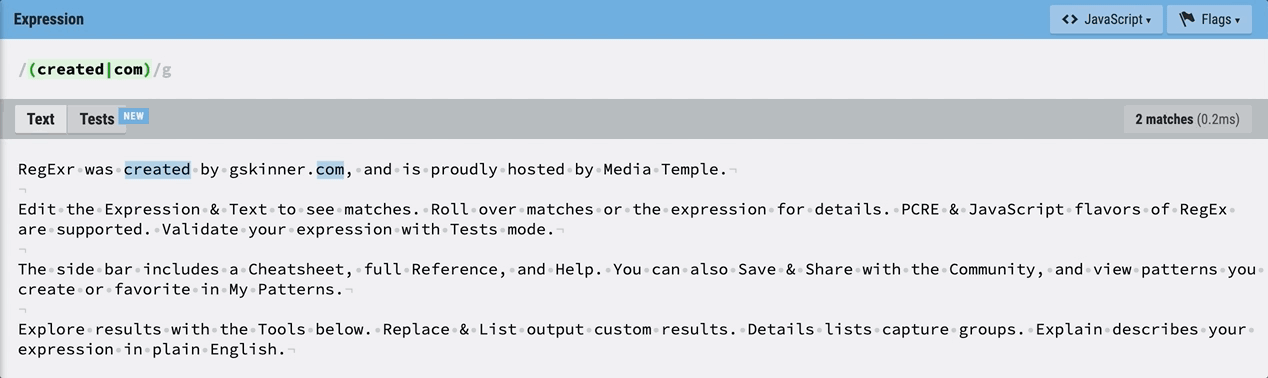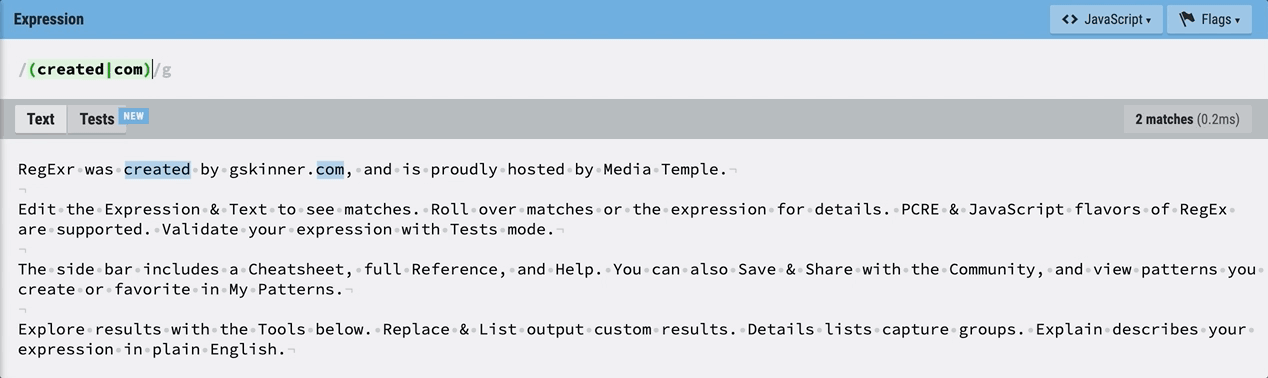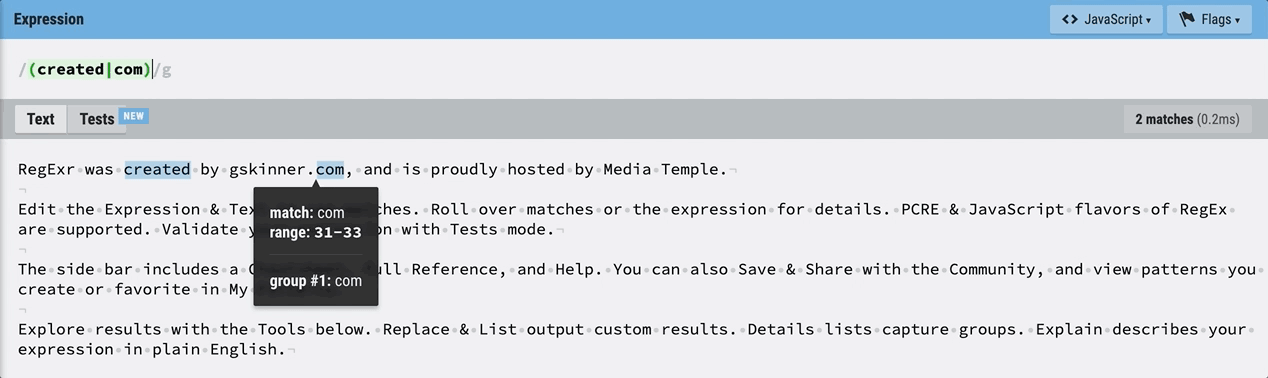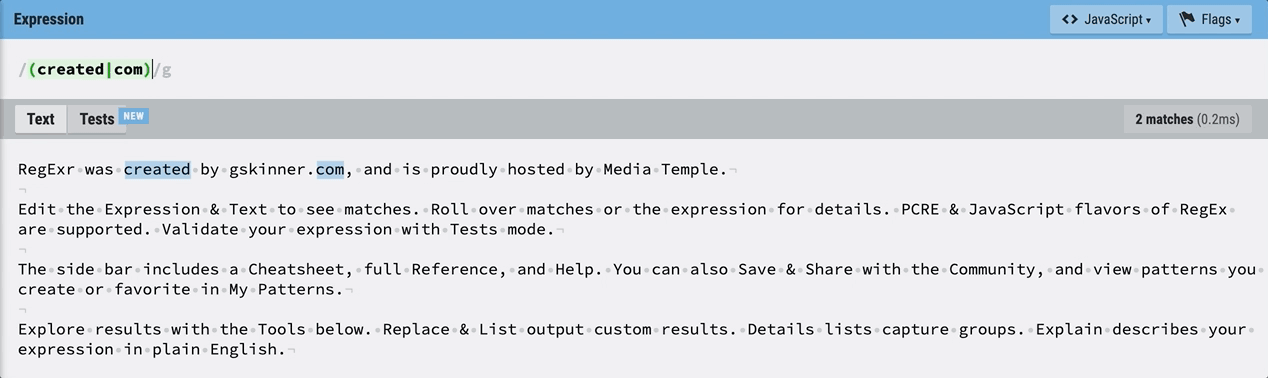 마우스를 올리면 그룹으로 지정되어 있는 것을 확인할 수 있다.
마우스를 올리면 그룹으로 지정되어 있는 것을 확인할 수 있다.
/(created|com)|(and)/이렇게 새로운 그룹을 지정할 수도 있다. 이 정규식은 created 또는 com의 그룹, 또는 and의 그룹을 찾는다.
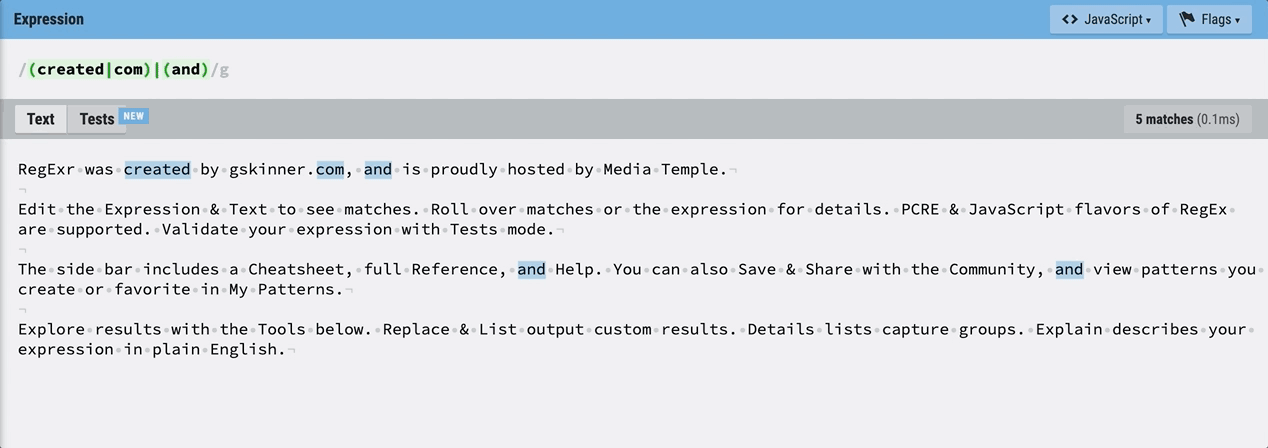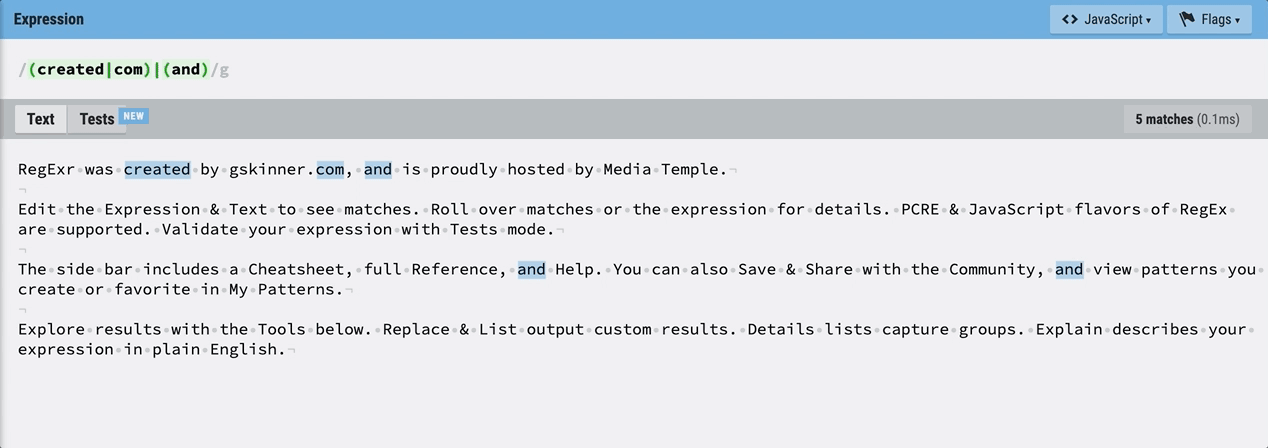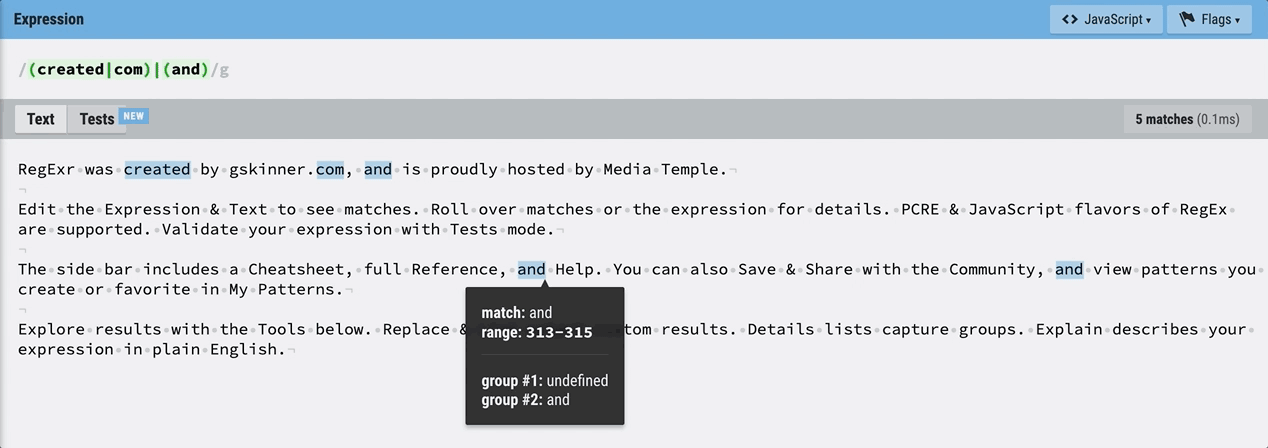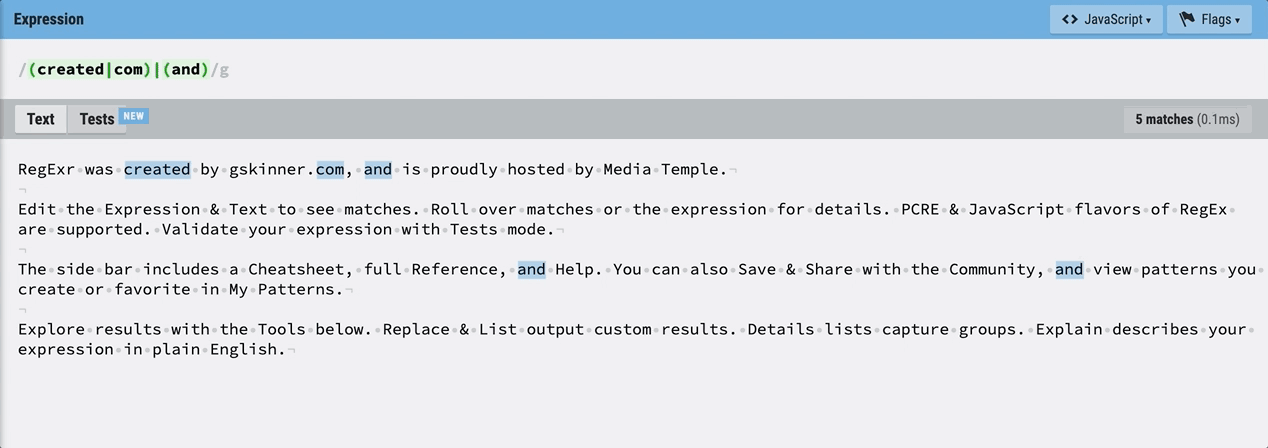 역시 마우스를 올려 보면, 각 그룹에 해당되는 텍스트가 아닌 경우 undefined가 뜬다. and는 그룹 2이므로 그룹 1은 undefined라고 나온다.
역시 마우스를 올려 보면, 각 그룹에 해당되는 텍스트가 아닌 경우 undefined가 뜬다. and는 그룹 2이므로 그룹 1은 undefined라고 나온다.
 그룹을 이용해서 이런 식으로 정규식을 작성해 볼 수도 있다. gr로 시작하면서, e 또는 a를 가지고 있고, y로 끝나는 문자열을 찾는 정규식이다.
그룹을 이용해서 이런 식으로 정규식을 작성해 볼 수도 있다. gr로 시작하면서, e 또는 a를 가지고 있고, y로 끝나는 문자열을 찾는 정규식이다.
찾지만 기억하지는 않는 (?:)
 찾기만 하고, 그룹으로 저장할 필요가 없는 경우
찾기만 하고, 그룹으로 저장할 필요가 없는 경우 (?:)를 이용한다. 위의 정규식 그룹에 (?:)를 붙였더니 그룹이 지정되지 않은 것을 볼 수 있다.
문자셋 []
gr로 시작하고 y로 끝나지만, 사이에 a,b,c,d,e,f,g가 들어간 문자열을 찾으려면 어떻게 해야 할까?
/gr(a|b|c|d|e|f|g)y/or연산자를 사용하면 이렇게 작성할 수 있을 것이다. 이것을 좀 더 쉽게 하려면 문자셋 대괄호 []를 사용하자. 대괄호 안에 있는 문자열은 모두 매칭이 된다.

범위를 지정할 수 있는 -
또는 아래와 같이, -를 이용해서 a부터 g까지라는 뜻으로 더 간결하게 작성할 수도 있다. 결과는 동일하다. 
그러면 -를 이용해서 아래와 같은 것도 찾아낼 수 있다.
- 숫자 0부터 9까지
- 소문자 a부터 z까지
- 대문자 A부터 Z까지

부정 문자셋 [^]
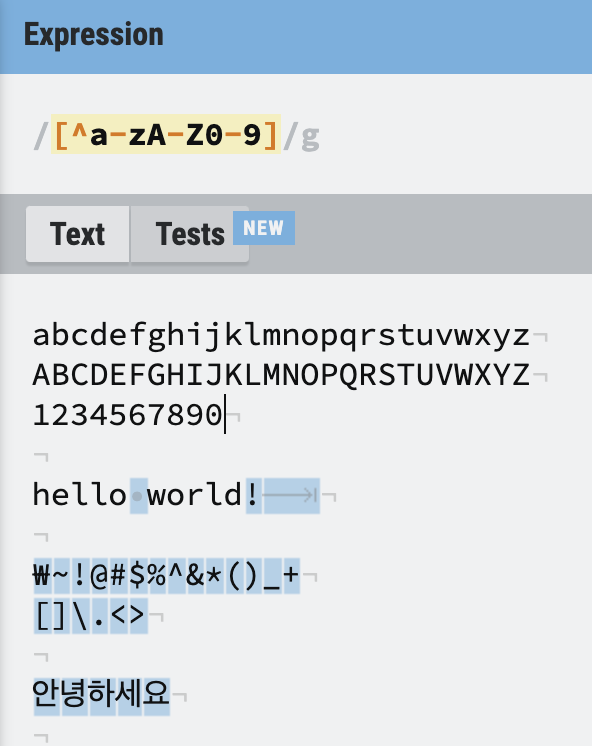
대괄호 맨 앞에 꺽쇠 ^를 붙이면, 대괄호 안에 있는 문자를 제외한 나머지를 전부 찾는다.
Quantifiers
수량에 관련된 Quantifiers에 대해서 알아본다.
?있거나 없거나 (zero or one)*없거나 있거나 많거나 (zero or more)+하나 혹은 많이 (one or more){n}n번 반복{min,}최소{min,max}최소, 최대
있거나 없거나 ?
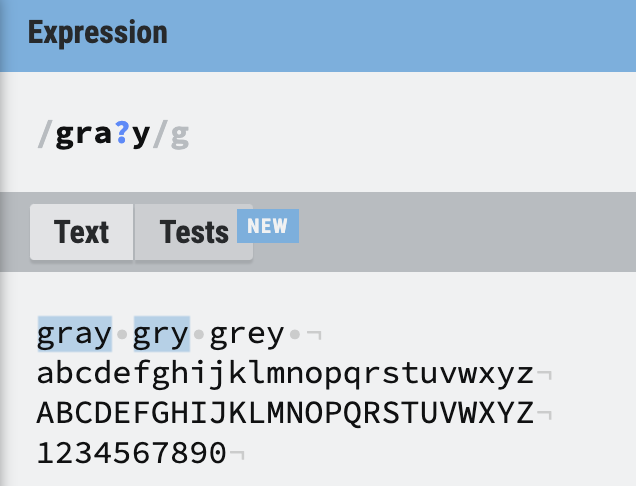
특정한 문자열 다음에 ? 를 넣어주게 되면 없거나 있거나이다. 예를 들어
/gra?y/와 같은 정규식이라면 gr로 시작하고 y로 끝나는데, a가 있거나 없는 문자열을 찾게 된다.
없거나 있거나 많거나 *
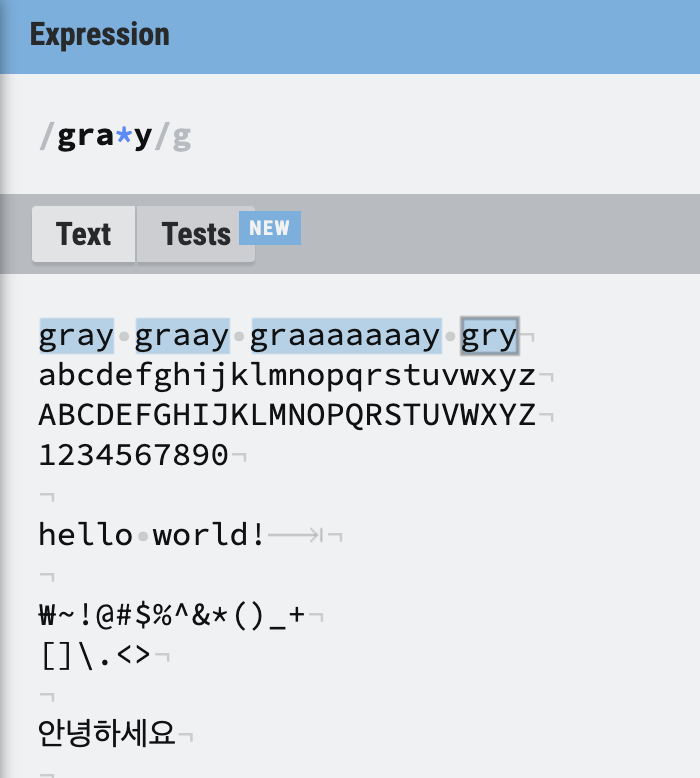 별표
별표 *는 없거나, 있거나, 많이 있는 경우까지 포함한다.
하나 혹은 많이 +
 플러스표
플러스표 +는 하나 있거나 많이 있는 경우를 선택한다. 없는 경우는 선택하지 않는다.
n번 반복 {n}
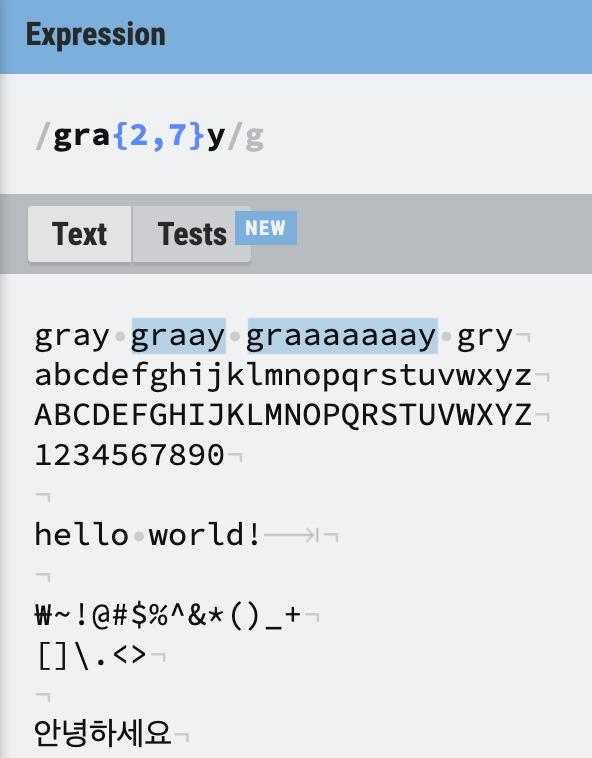 정확하게 수량을 지정하고 싶을 때 중괄호와 숫자를 사용한다. 최소값과 최대값을 지정해 줄 수 있다. 위의 예시의 경우 a가 2개에서 7개까지를 허용하므로 gray는 선택되지 않았다.
정확하게 수량을 지정하고 싶을 때 중괄호와 숫자를 사용한다. 최소값과 최대값을 지정해 줄 수 있다. 위의 예시의 경우 a가 2개에서 7개까지를 허용하므로 gray는 선택되지 않았다. /gra{2,}y/와 같이 최소만 지정하는 것도 가능하다.
Boundary Type
\b단어 경계\B단어 경계가 아님^문장의 시작$문장의 끝
단어 경계 \b
단어 앞/뒤 경계에서 쓰이는 문자열만 선택하고 싶다면, \b를 사용할 수 있다.
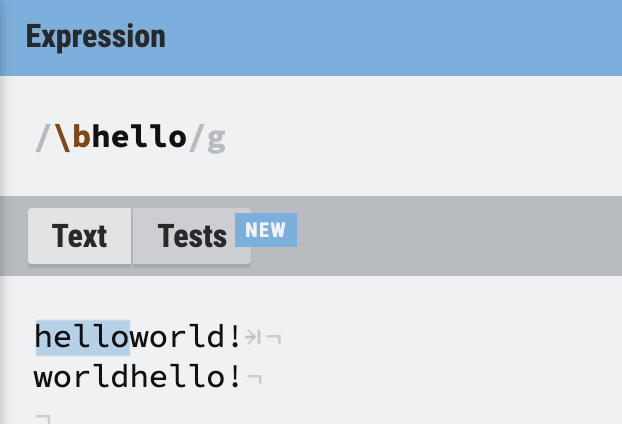 위의 정규식
위의 정규식 /\bhello/는 단어의 앞에 hello가 있는 경우만 찾는다.
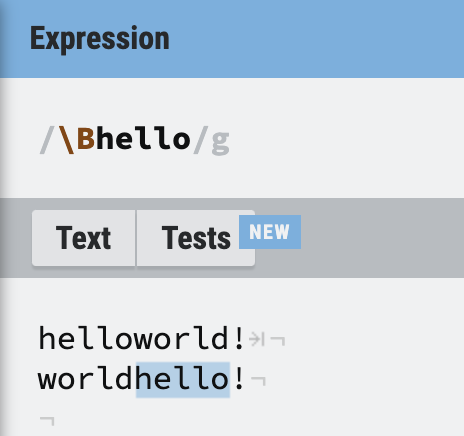
\b의 반대인 \B
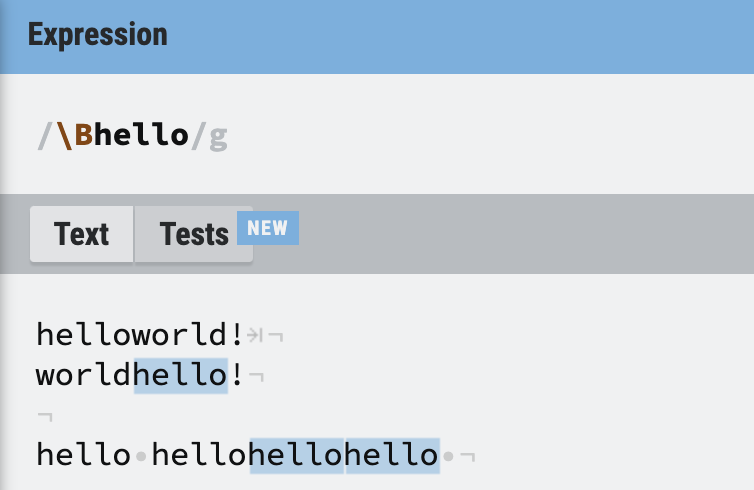
\b를 대문자로 한 \B는 반대라고 생각하면 된다. 예를 들어 /\Bhello/라는 정규식이 있다면, 단어 앞에서 쓰이지 않는 hello만 찾게 된다.
hello 하나는 hello로 시작하는 단어이므로 찾지 않고, hellohellohello의 경우 앞에서 시작하지 않는 중간과 뒤의 hello만 찾게 된다.
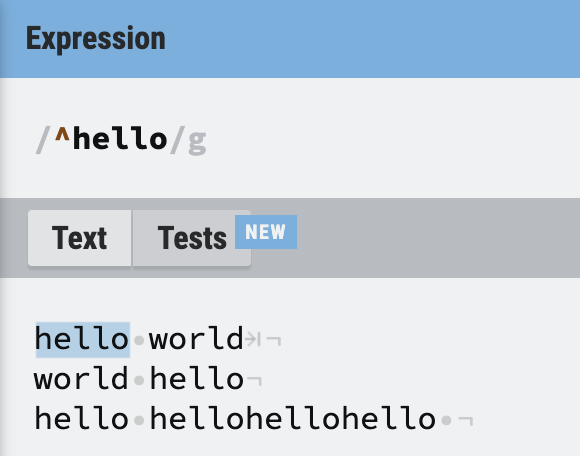
문장의 시작 ^
^는 단어가 아닌 문장 버전이라고 보면 된다. 꺽쇠 기호를 쓰게 되면 문장에서 시작하는 단어를 찾게 된다.
문장의 끝 $
 꺽쇠
꺽쇠 ^와는 반대로, 달러 표시$는 문장의 끝에 있는 단어를 찾게 된다. 이 때 flag를 multiline으로 지정해줘야 각 줄을 문장으로 인식한다. flag를 설정하지 않으면 텍스트 창에 있는 모든 글자를 한 문장으로 인식한다.
Character Classes
\특수 문자가 아닌 문자.어떤 글자 (줄바꿈 문자 제외)\ddigit 숫자\Ddigit 숫자 아님\wword 문자\Wword 문자 아님\sspace 공백\Sspace 공백 아님
어떤 글자 (줄바꿈 문자 제외) .
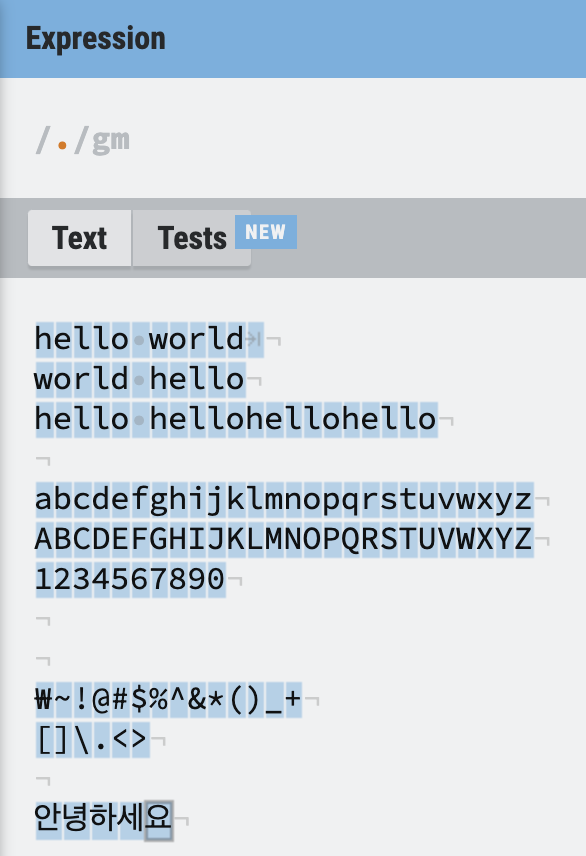 모든 문자를 선택하고 싶으면 마침표
모든 문자를 선택하고 싶으면 마침표 .를 이용하면 된다. 줄바꿈 문자는 제외한다.
특수 문자가 아닌 문자 \
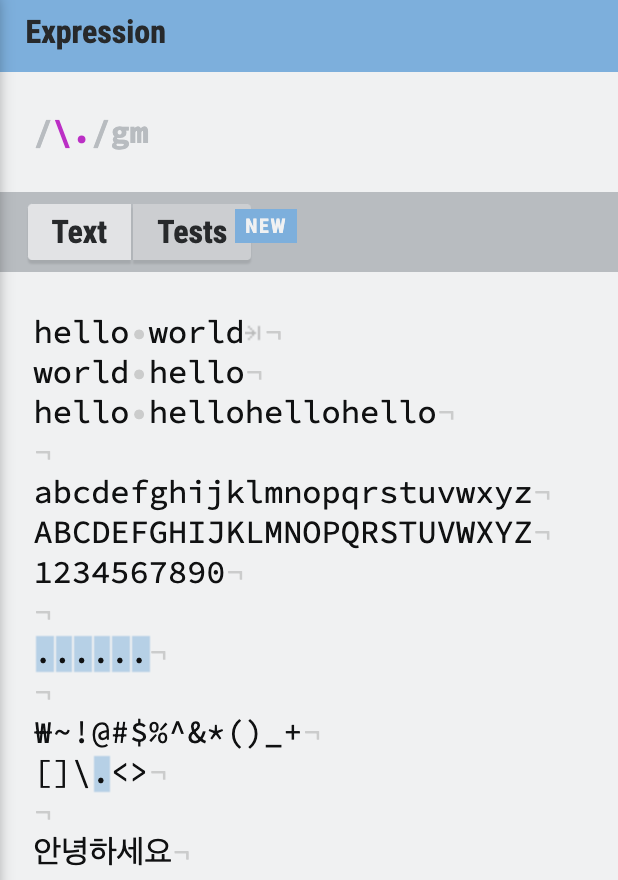 진짜 "."를 검색하고 싶거나, 정규표현식에서 사용하는 특수 문자열 자체를 검색하고 싶을 때는
진짜 "."를 검색하고 싶거나, 정규표현식에서 사용하는 특수 문자열 자체를 검색하고 싶을 때는 \를 이용해서 찾아야 한다. 예를 들어 []를 검색하려면 정규식을 /\[\]/ 이렇게 작성해야 한다.
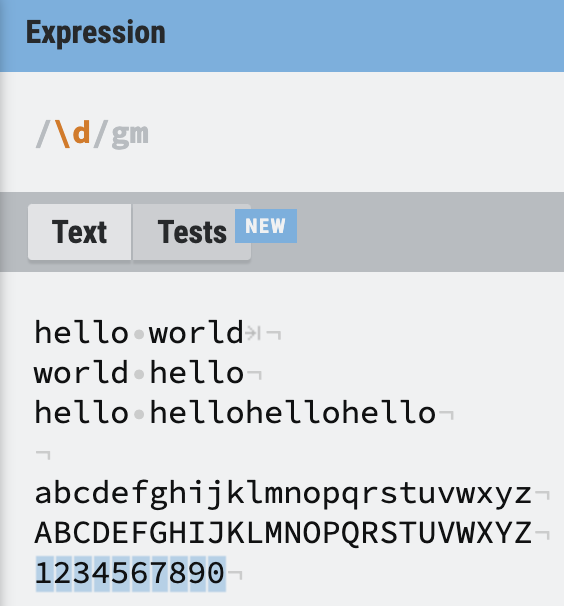
숫자 \d
숫자가 아닌 \D
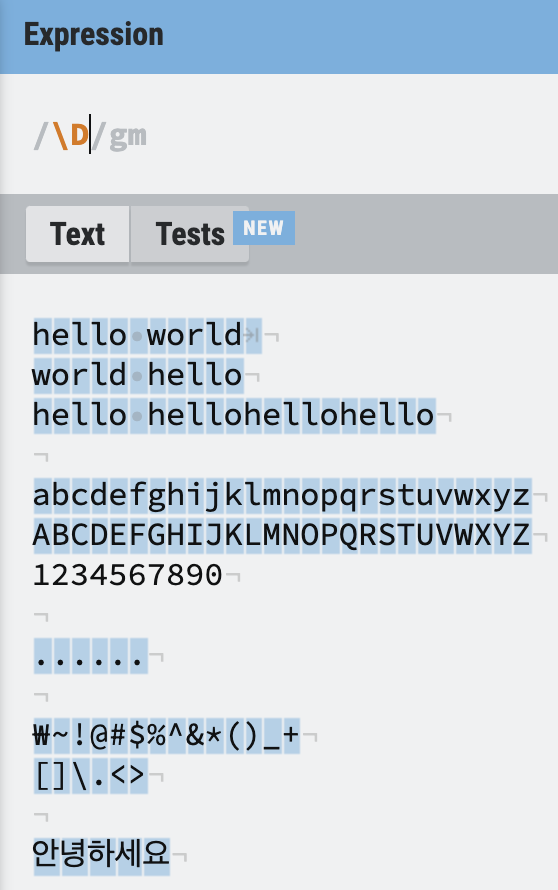 반대로 숫자가 아닌 것을 찾으려면 대문자
반대로 숫자가 아닌 것을 찾으려면 대문자 \D를 이용한다.
문자 \w
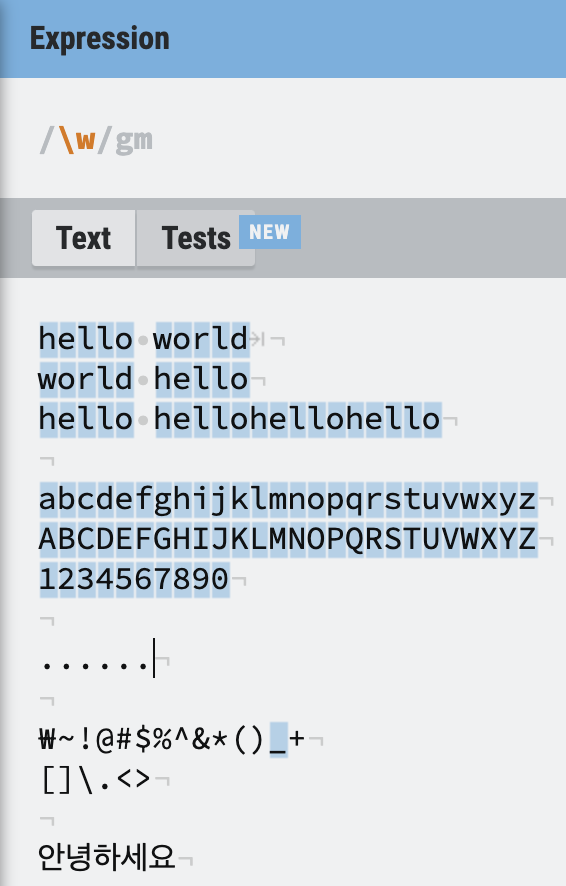
\w는 모든 문자를 찾는다.
문자가 아닌 \W
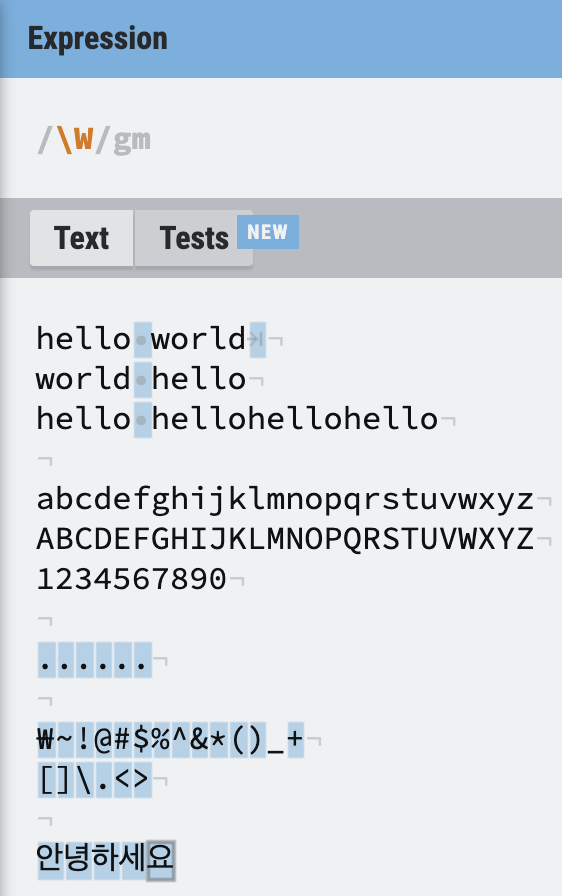 반대로 대문자
반대로 대문자 \W는 문자가 아닌 모든 것을 선택하게 된다.
공백 \s
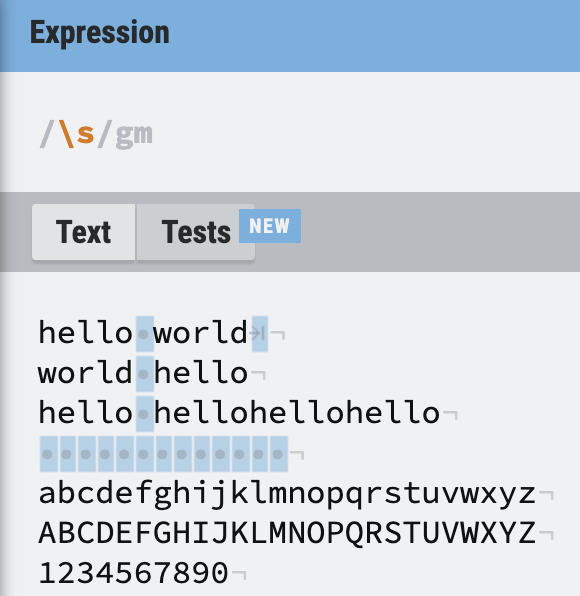 space의 약자인
space의 약자인 \s는 공백만 찾는다.
공백이 아닌 \S
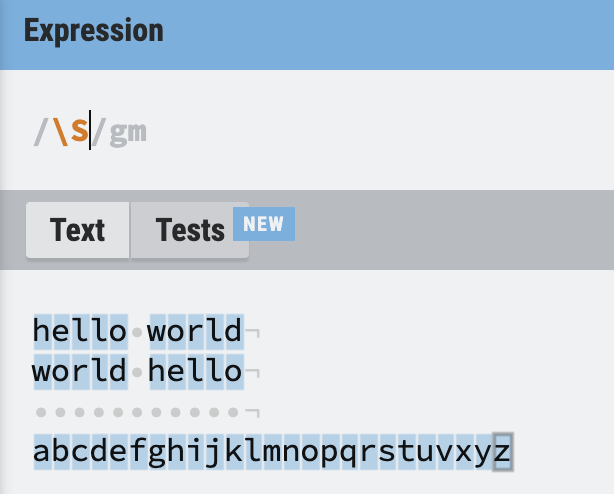
\S는 반대로 띄어쓰기가 아닌 모든 것을 찾는다.
문법 총정리
Group and Ranges
|또는()그룹[]문자셋, 괄호 안에 어떤 문자든[^]부정 문자셋, 괄호 안에 어떤 문자가 아닐 때(?:)찾지만 기억하지는 않음
Quantifiers
수량에 관련된 Quantifiers에 대해서 알아본다.
?있거나 없거나 (zero or one)*없거나 있거나 많거나 (zero or more)+하나 혹은 많이 (one or more){n}n번 반복{min,}최소{min,max}최소, 최대
Boundary Type
\b단어 경계\B단어 경계가 아님^문장의 시작$문장의 끝
Character Classes
\특수 문자가 아닌 문자.어떤 글자 (줄바꿈 문자 제외)\ddigit 숫자\Ddigit 숫자 아님\wword 문자\Wword 문자 아님\sspace 공백\Sspace 공백 아님
예제
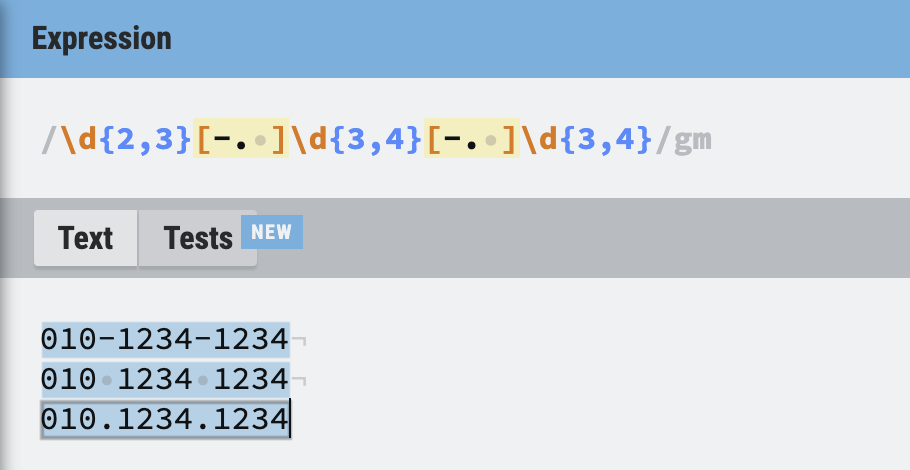
전화번호 선택하기
아래의 조건을 만족하는 전화번호만 검색하는 정규식을 작성해보자.
- 지역번호는 2글자 또는 3글자
- 중간, 뒷번호는 3글자 또는 4글자
- 000-1234-5678 대시로 구분되어 있는 전화번호
- 000 1234 5678 띄어쓰기로 구분되어 있는 전화번호
- 000.1234.5678 점으로 구분되어 있는 전화번호
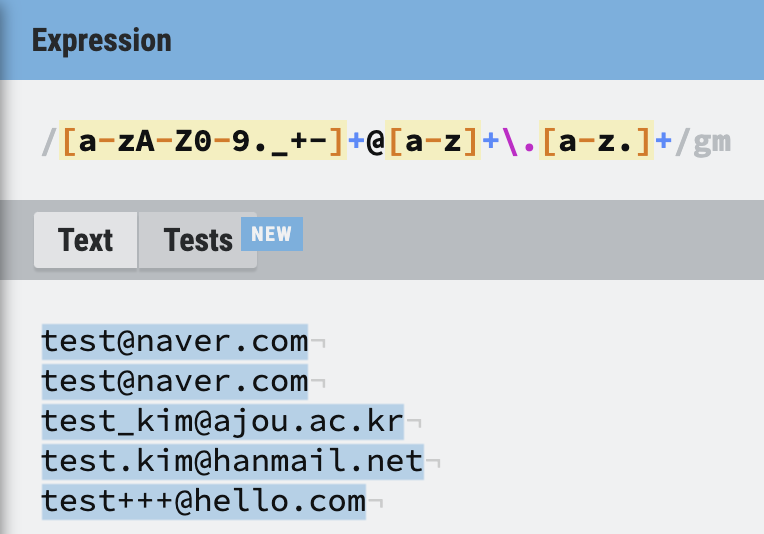
이메일 선택하기
- 아이디는 영어 대소문자, 숫자,
.,_,+,-만 허용된다. - 아이디가 없는 경우는 없다. (예를 들어
@naver.com과 같은 경우) @로 아이디와 주소를 구분한다.- 주소는 영어 소문자로와
.으로만 구성되어 있다. - 주소에서
.이 여러 번 나올 수 있다.
유튜브 주소 선택하기
https://는 있어도 되고 없어도 된다.www.는 있어도 되고 없어도 된다.youtu.be/비디오ID의 형태이다.- 비디오ID는 영어 대소문자와 숫자로 구성되어 있으며, 11자리이다.
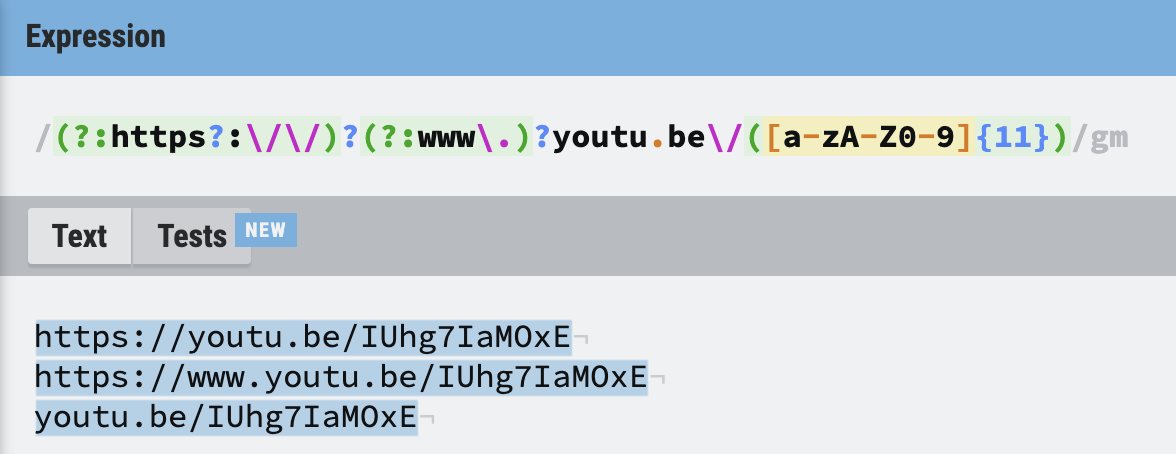
우리가 나중에 중요하게 다룰 가능성이 있는 건 비디오ID 뿐이므로, https://나 www.의 그룹은 ?:처리를 했다. 이렇게 한 이유는 자바스크립트 활용방법에서 알 수 있다.
자바스크립트에서의 활용 방법
const regex = /(?:https?:\/\/)?(?:www\.)?youtu.be\/([a-zA-Z0-9]{11})/;
const url = 'https://www.youtu.be/IUhg7IaMOxE';
const reuslt = url.match(regex);자바스크립트에서 정규식을 지정해주고 match함수의 인자로 넣어주면 배열을 리턴하는데, 첫 번째 원소에는 매칭된 문자열 전체가 들어 있고, 그 다음에는 매칭되는 그룹의 데이터가 들어 있다.
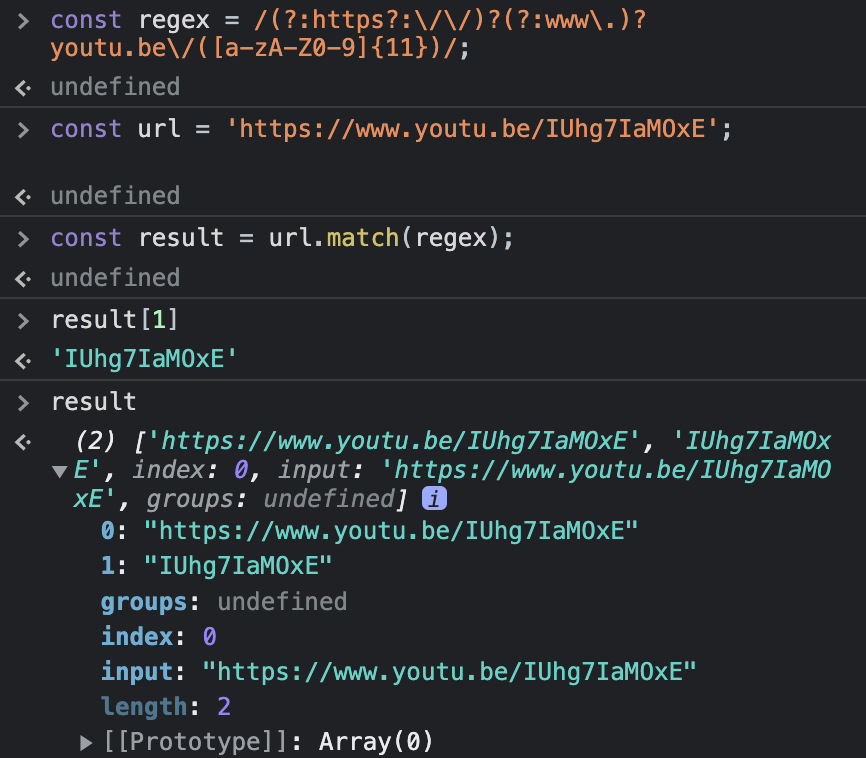 우리는 아까
우리는 아까 https://나 www.을 그룹으로 지정하지 않았기 때문에 비디오 ID만 리턴된 배열의 요소로 들어있는 것을 확인할 수 있다.
나가며
내용이 길지만 사용법만 손에 익게 되면 유용하게 사용할 수 있을 것이다. 실제 지금 하는 업무에서도 정규식을 이용한 이메일 필터링을 하고 있다. 실무에서도 자주 쓰이고, 코딩테스트에서도 유용한 정규식! 공부하지 않을 이유가 없다.
갑자기 반성
 이거 잘 안 쓸것 같은데, 어려워 보이는데, 지금 필요 없을 것 같은데, 등등 조건 재지 말고 그냥 하자. 막상 해보니 별로 어렵지도 않은 걸 2년이나 모르고 살았던 세월이 통탄스럽다.
이거 잘 안 쓸것 같은데, 어려워 보이는데, 지금 필요 없을 것 같은데, 등등 조건 재지 말고 그냥 하자. 막상 해보니 별로 어렵지도 않은 걸 2년이나 모르고 살았던 세월이 통탄스럽다.
