GPT-1: Introduction
🔍Background
- 기존 NLP 모델들은 대체로 지도학습(Supervised Learning) 방식에 의존해, 모델을 훈련시키기 위해 각 태스크에 대한 대량의 라벨링 데이터가 필요했음
- 현실적으로 많은 NLP 태스크에서 고품질의 라벨링 데이터를 확보하는 것은 어려움
- 이를 극복하기 위해 openAI에서 GPT-1(Generative Pre-trained Transformer) 개발
- 자연어 이해를 향상시키이 위해 사전학습(pre-traning)과 미세 조정(fine-tuning)의 두 가지 단계 활용
💡논문의 핵심 어이디어:
- 대량의 텍스트 데이터를 이용해 비지도 학습(Unsupervised Learning) 방식으로 사전학습을 진행해, 모델이 일반적인 언어 구조와 패턴을 학습하도록 함
- 이후, 특정 태스크에 맞게 지도학습(Supervised Learning) 방식으로 미세 조정하여 성능 향상
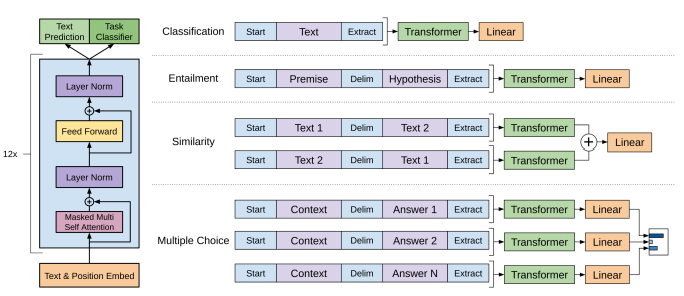
GPT-1: Model Architecture
💡 GPT-1은 Transformer의 디코더(Decoder) 부분만 활용
- 트랜스포머의 Masked Self-Attention 기법을 적용하여, 다음 단어를 예측할 때 미래 단어를 참고하지 못하도록 제한
사전학습(Pre-training)
- GPT-1은 비지도 학습 방식으로 대량의 텍스트 데이터를 학습
- 특정 NLP 태스크와 무관하게 일반적인 언어 모델(Language Model)로 훈련
- 이전 단어들을 기반으로 다음 단어를 예측하는 방식으로 훈련
미세조정(Fine-tuning)
- 사전 학습이 완료된 후, 모델을 특정 NLP 태스크에 맞춰 미세 조정
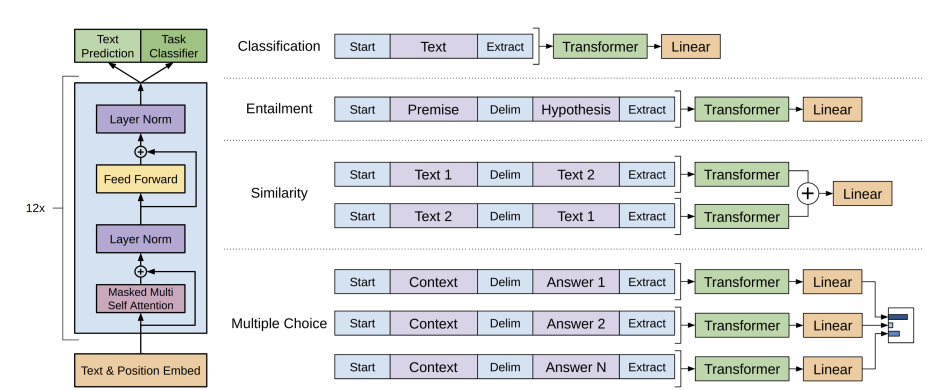
- 미세 조정 단계에서는 사전 학습된 모델의 가중치를 초기화한 후, 태스크 별 데이터를 이용해 추가적인 학습을 수행
GPT-1: 한계점
- 컨텍스트 길이 제한: 트랜스포머 기반 모델은 입력 길이가 제하되어 긴 문맥을 고려하기 어려움
- 비효율적인 훈련 비용: 대규모 트랜스포머 모델을 학습하는 데 많은 자원이 필요함
- 양방향(Bidirectional) 정보 부족: GPT-1은 단방향(Left-to-Right) 모델이므로, BERT처럼 양방향 정보를 활용하지 못함

데이터분석/데이터사이언스/코딩