Transformer: Introduction
- 자연어 처리(NLP)는 오랜 시간동안 순환신경망(RNN, LSTM)을 기반으로 발전함
- 이러한 모델들은 (1) 긴 문장에서 정보를 잃어버리고(Long-Term Dependency Problem), (2) 병렬 연산이 어렵다는 단점 존재
- 2017년, Google에서 "Attention is All You Need"가 나옴
- 이 논문은 Self-Attention을 기반으로 한 Transformer 모델을 제안하면서, RNN 없이도 최고의 성능을 달성할 수 있음을 증명함
💡논문의 핵심 기여:
- 기존 RNN 기반 모델보다 학습 속도가 훨씬 빠름
- 병렬 연산이 가능해 대규모 데이터에서도 효율적으로 동작
- 번역 성능에서 기존 모델을 뛰어넘음
- 즉, "Attention만으로 충분하다" 라는 논문
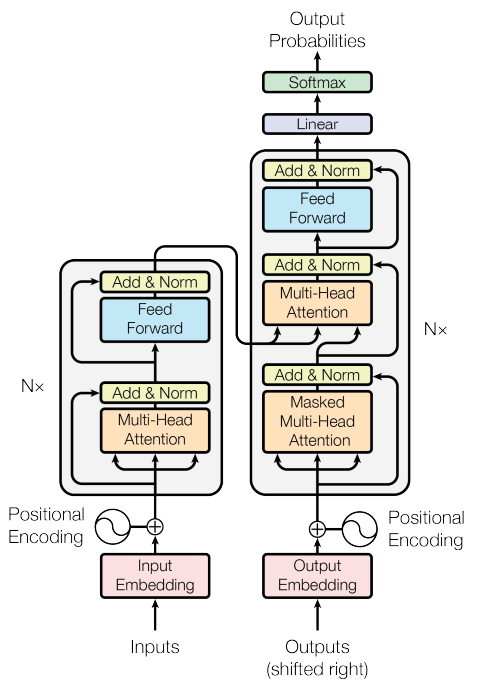
Transformer: Model Architecture
🗝️핵심 개념
1. Self-Attention
- Transformer의 핵심은 Self-Attention 메커니즘
- 기존 RNN 모델은 단어를 순차적으로 처리하지만, Self-Attention은 문장 전체를 한번에 보고 단어들 간의 관계를 학습할 수 있음
- 즉, 문장의 모든 단어가 서로를 참조할 수 있도록 만드는 것
✅ Self-Attention의 원리:
- 각 단어는 문장 내 단어들과 얼마나 관련이 있는지(가중치)를 계산
- 이를 위해 Query(Q), Key(K), Value(V) 세가지 벡터를 사용
- Q, K, V는 같은 입력 데이터에서 생성하지만, 각기 다른 역할을 함
- 같은 입력에서만 나오지만, 다른 가중치 행렬을 통해 변환되기 때문에 각기 다른 역할을 함

- Query(Q): 현재 단어가 다른 단어를 찾을 때 사용하는 벡터
- Key(K): 다른 단어들이 현재 단어를 찾을 때 사용하는 벡터
- Value(V): 단어가 실제로 가지고 있는 의미 정보를 담는 벡터
- 수식
QK^T: Query와 Key 내적을 구해 각 단어가 다른 단어와 얼마나 관련 있는지 계산softmax: 가중치를 확률 값으로 변환V: 가중치를 적용한 최종 값- RNN 없이도 문맥을 반영한 단어표현을 만들 수 있음
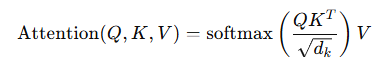
2. Multi-Head Attention
- 단어 간 관계를 한 가지 Attention으로만 보면 정보가 부족하여 Multi-Head Attention을 도입함
- Self-Attention을 여러 개 적용해 다양한 관점에서 단어 간 관계를 학습
- 단어의 의미를 더 풍부하게 표현할 수 있음
- 이렇게 하면, 같은 문장이라도 다양한 차원에서 의미를 파악할 수 있음
3. Positional Encoding
- Self-Attention은 순서를 고려하지 못함
- RNN은 순차적으로 학습하여 순서를 반영하지만, Transformer는 이를 보완하기 위해 Positional Encoding을 사용
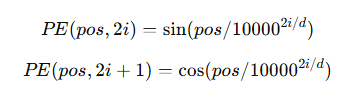
- 홀수는 사인(sin), 짝수는 코사인(cos)함수를 사용해 각 단어에 고유한 위치 정보를 부여
🔎Transformer 구조
Encoder
1️⃣ Input Embedding: 입력 단어를 벡터로 변환하여 모델이 이해할 수 있는 형식으로 변환
2️⃣ Positional Encoding:
- Self-Attention은 순서를 고려하지 않으므로, 사인(sin), 코사인(cos) 함수를 활용해 단어 순서 정보를 추가
3️⃣ Multi-Head Attention:
- Self-Attention을 활용하여 입력 문장의 모든 단어 간 관계를 학습
- 여러 개의 Attention Head를 병렬로 사용하여 다양한 문맥을 반영
4️⃣ Add & Norm (잔여 연결 및 정규화)
- Residual Connection: 깊은 네트워크에서 정보 손실 방지, 기울기 흐름 원활화 → 기울기 소실 문제 해결
- Layer Normalization: 가중치 값 분포를 일정하게 유지하여 훈련 속도를 증가시키고 과적합 방지
5️⃣ Feed-Forward Network (FFN)
- 개별 단어의 표현을 비선형적으로 변환하여 더 풍부한 의미를 학습 (ReLU 활성화 함수 사용)
- 각 단어가 독립적으로 처리되므로 병렬 연산 가능
6️⃣ Layer Stacking:
- 여러 개의 Encoder 블록을 쌓아 고차원적인 패턴 학습
- 문장 내 단어 간의 복잡한 관계를 깊이 있게 학습
Decoder
1️⃣ Input Embedding: 디코더의 입력을 벡터화하여 처리 가능하도록 변환
2️⃣ Positional Encoding: 단어 순서를 고려할 수 있도록 추가 정보 제공
3️⃣ Masked Multi-Head Attention:
- Look-ahead Mask를 적용하여 미래 단어를 참조하지 않도록 함 → 올바른 문장 생성 가능
- Decoder가 이미 생성된 단어만 활용하여 다음 단어를 예측하도록 유도
4️⃣ Encoder-Decoder Attention:
- Encoder에서 생성된 정보와 Decoder의 정보를 결합하여 적절한 출력을 생성
- 입력 문장과 출력 문장이 어떻게 연결되는지 학습
5️⃣ Add & Norm (잔여 연결 및 정규화)
- Residual Connection을 통해 정보 손실을 방지하고, Layer Normalization으로 안정적인 학습 유도
6️⃣ Feed-Forward Network (FFN)
- 단어의 특징을 강화하고, 복잡한 변환을 수행하여 더 나은 표현 학습
7️⃣ Output Layer (Softmax & Linear Projection)
- 최종적으로 Softmax를 적용하여 다음 단어를 생성할 확률 분포를 계산
8️⃣ Layer Stacking:
- Encoder와 마찬가지로 여러 개의 Decoder 블록을 쌓아서 정교한 문장 생성 가능
💡 즉, Encoder는 문장을 이해하고, Decoder는 이를 바탕으로 번역을 생성하는 역할
Transformer 한계점 및 현재
한계점
- 연산량 문제: Self-Attention의 복잡도가 O(n^2)이라 긴 문장을 처리할 때 비용이 큼
- 데이터 의존성: 대량의 데이터가 필요하며, 작은 데이터에서는 성능이 낮아질 수 있음
현재(2025년 1월 기준)
- 2017년 논문 하나가 NLP 패러다임을 완전히 바꿔 놓음
- 기존 RNN/LSTM의 한계를 극복하고, Self-Attention 기반 아키텍처가 표준이 됨
- 현재 OpenAI의 GPT, Google's BERT, Meta의 LLaMA 등 거대 언어 모델(LLM) 들이 모두 Transformer 기반
📑Transformer 자료

데이터분석/데이터사이언스/코딩