arxiv: https://arxiv.org/abs/1909.11942
date: 06/06/2022

Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942.
Abstract
-
natural language representation을 pretrain 시킬 때 모델 사이즈를 키우는 것은 task의 성능을 향상시킴
-
다만 이에 대한 tradeoff로 모델을 계속해서 키우면 computationally expensive !
(GPU/TPU memory limitation - 학습시간 증가)→ 이에 대한 solution으로 BERT에 대한 두 개의 parameter reduction techniques를 제안한다 !
+ 문장 간 응집성 모델링에 초점을 맞춘 self-supervised loss 도입 → multi-sentence input을 수반하는 task에 탁월한 성능 → 우리 모델, BERT-large에 비해 적은 parameter을 가지는 한편 좋은 성능을 냄 !
Introduction
- NLP 분야에서 pretrained models은 중대한 발견 → 성능의 비약적 발전을 낳음
- 큰 pretrained model을 정제해서 task에 맞춰 좁혀나가는 것이 일반적인 관례가 되었음
- 따라서 pretrained models가 좋은 성능을 내기 위해서 큰 사이즈의 network를 구축하는 것은 매우 중요
- 더 좋은 NLP모델을 만드는 것이 큰 사이즈의 모델을 만드는 것 만큼 쉬울까?
- 현실적으로 하드웨어의 제한으로 인해 성능 비교가 어려움(메모리 제한, 분산 학습을 하더라도 속도 저하를 막을 수 없음)
- 현재 NLP 모델들 규모가 굉장히 커졌기 때문(10억개 남짓한 파라미터들...)
- 우리는 기존의 너무 비대해진 모델들로 인한 문제를 모두 해결한 A Lite BERT(ALBERT)를 제안한다!
-
ALBERT
-
두 가지 parameter reduction techniques 결합
-
factorized embedding parameterization
- 하나의 큰 단어 임베딩 matrix를 두개의 작은 matrix로 분해 → hidden layer의 size를 나눔
- 단어 임베딩들의 parameter 수를 많이 늘리지 않고도 hidden layer의 size를 키울 수 있음
-
cross-layer parameter sharing
- 네트워크가 깊어지더라도 parameter 수가 많이 늘어나지 않도록 함
-
두 technique를 결합한 결과, ALBERT, BERT_large에 비해 18배 적은 parameter를 가지게 되었고 training 속도가 1.7배 줄어듦
- 두 technique, parameter reduction 뿐 아니라 일종의 정규화 기능도 수행 → 학습을 안정화시키고 generalization하는데 도움을 줌
-
-
self-supervised loss가 도입된 SOP(sentence-order prediction)
- SOP, 문장 간 응집성 모델링에 초점을 맞춤
- 기존 BERT의 NSP(next sentence prediction) loss 보다 효율적
-
이렇게 디자인 된 ALBERT는 BERT_large에 비해 parameter 수는 적지만 성능은 뛰어남 !
-
Related Work
-
SCALING UP REPRESENTATION LEARNING FOR NATURAL LANGUAGE
- 모델 사이즈가 커지면 성능도 좋아진다 ! (using larger hidden size, more hidden layers, and more attention heads)
- 하지만 모델 사이즈가 커지면 커질수록 computationally expensive 해짐
- 이를 극복하기 위해 gradient checkpointing이라는 방법과 intermediate activation을 저장하지 않아도 되는 방식이 제안되었음. 해당 방식들은 메모리 소비량를 줄였지만 속도가 느리다는 한계가 있음
- 우리의 parmeter 감축 방식은 메모리 소비량을 줄이는 한편 속도도 빠름
-
CROSS-LAYER PARAMETER SHARING
- cross-layer parameter sharing이 언어모델링과 주-서 호응하는 데 있어 기존의 transformer보다 성능이 좋다는 연구 존재 → 본 논문 저자들은 아니라고 주장
- 최근 DQE(Deep Equilibrium Model)이 제안되어 특정 layer의 input - output embedding이 equilibrium point에 도달할 수 있음을 보여줌 → 본 논문 저자들은 아니라고 주장. 수렴하기보다는 발산하던데?
- parameter-sharing transformer를 standard transformer과 결합, standard transformer보다 더 높은 성능을 달성한 연구도 존재
-
SENTENCE ORDERING OBJECTIVES
- 다른 연구들과 달리, ALBERT는 문장 단위가 아니라 segments를 단위로 봄(두 개의 연결되는 segments들의 순서를 예측하여 pre-train loss로 사용)
- SOP는 더 복잡한 pretraining 방식이며, 특정 task들에서 뛰어난 성능을 보임
The Elements of ALBERT
: design decisions for ALBERT
- MODEL ARCHITECTURE CHOICES
→ ALBERT의 근간은 BERT와 같음. (Transformer encoder / GELU nonlinearities를 씀)
* 다만 BERT와 구분되는 지점 세 가지 !
-
Factorized embedding parameterization
-
BERT 계열 연구들(XLNet, RoBERTa 등), vocabulary embedding size E = hidden layer size H (E=H)
→ 이는 모델링 차원, 실무적인 차원에 있어 바람직하지 않음- 모델링 차원에서 vocabulary embedding, context-independent representation과 연관. hidden layer embedding이 context-dependent representation과 연관된 것과 구분.
- BERT 계열의 힘은 context-dependent representation을 학습하는데서 옴
→ 따라서 vocabulary embedding과 hidden layer size를 별개로 생각하는 것은 모델링의 효율성을 높여준다고 볼 수 있음. hidden layer size H를 크게 만들면 성능이 향상된다 !
-
NLP 모델링 시 vocabulary size V가 크면 클수록 좋음그런데 이 때 E=H라면 H를 키우면 embedding matrix의 크기도 커짐 (V x E) → parameter 수가 급격히 늘어남
-
Factorized embedding
- ALBERT에서는 embedding matrix를 두개로 나눔
- one-hot vector를 H 크기의 vector로 바로 projection하지 않고 E 크기의 저차원 embedding vector 거쳐 projection하는 것
- (V × E + E × H)
- H > E 일 때 parameter가 급격히 감소
- O(V × H) → O(V × E + E × H) 로의 이행
-
-
Cross-layer parameter sharing
: layer 간 모든 parameter를 공유 (parameter efficiency를 위한 방법)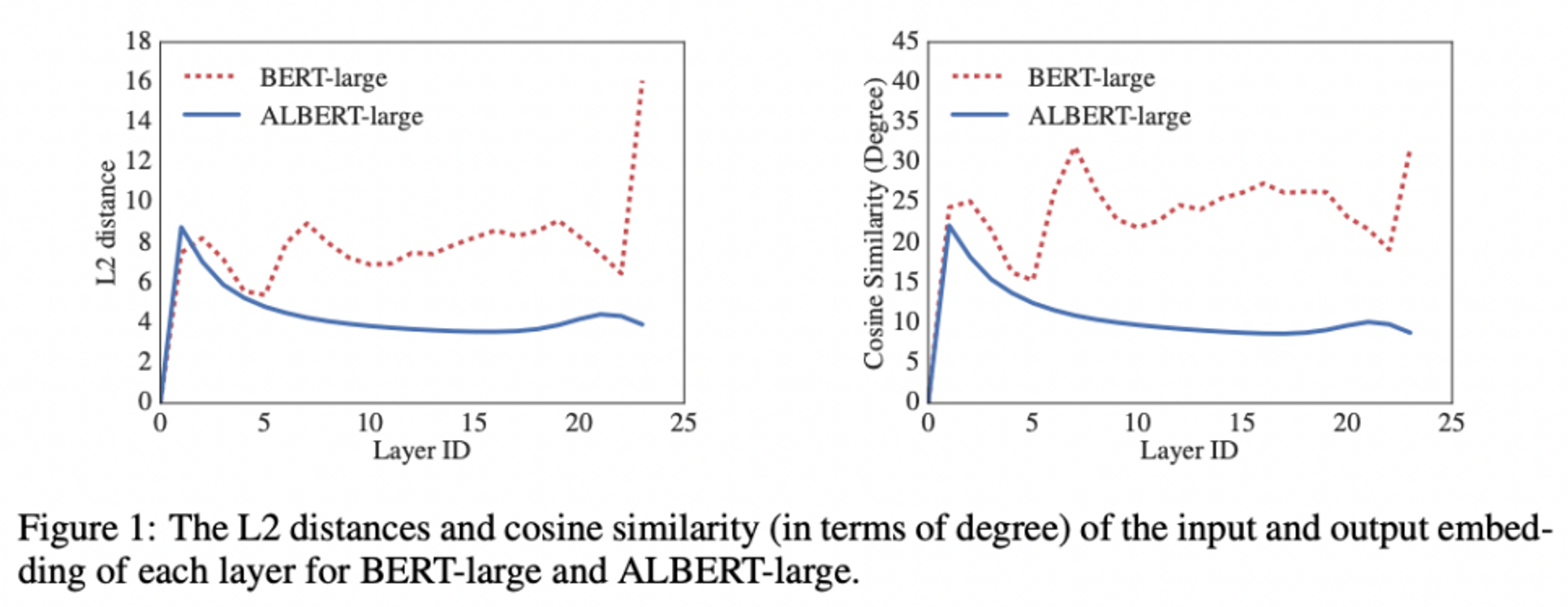
- layer간 transition이 smoother ! → weight sharing, network parameter 안정화에 기여
-
Inter-sentence coherence loss
- BERT에서는 성능 개선을 위해 NSP loss를 사용하나, 이게 별 효과가 없다는 연구가 존재
- 본 연구에서는 NSP loss가 너무 쉬운 task이기 때문에 효과가 없는 것이라고 판단, 문장 간 응집성에 초점을 맞춘 더 어려운 task인 SOP 제안한다 !
- positive sample / negative sample NSP랑 유사하나, segment 단위를 사용한다는 점에서 차이가 있음
→ 실제 multi-sentence encoding task에 좋은 성능을 보임
- positive sample / negative sample NSP랑 유사하나, segment 단위를 사용한다는 점에서 차이가 있음
-
MODEL SETUP
- BERT 와 ALBERT의 hyperparameter settings

- ALBERT model의 parameter 수가 BERT에 비해 적다 !
- ALBERT design의 가장 중요한 장점 = parameter efficiency
- BERT 와 ALBERT의 hyperparameter settings
Experimental Results
-
EXPERIMENTAL SETUP
- setup
- BERT-based
- corpora : BOOKCORPUS (Zhu et al., 2015) & English Wikipedia (Devlin et al., 2019)
- input
- limit the maximum input length to 512
- randomly generate input sequences shorter than 512 with a probability of 10%
- vocabulary size of 30,000
- generate masked inputs for the MLM targets using n-gram masking with the length of each n-gram mask selected randomly (cf. max length of n = 3)
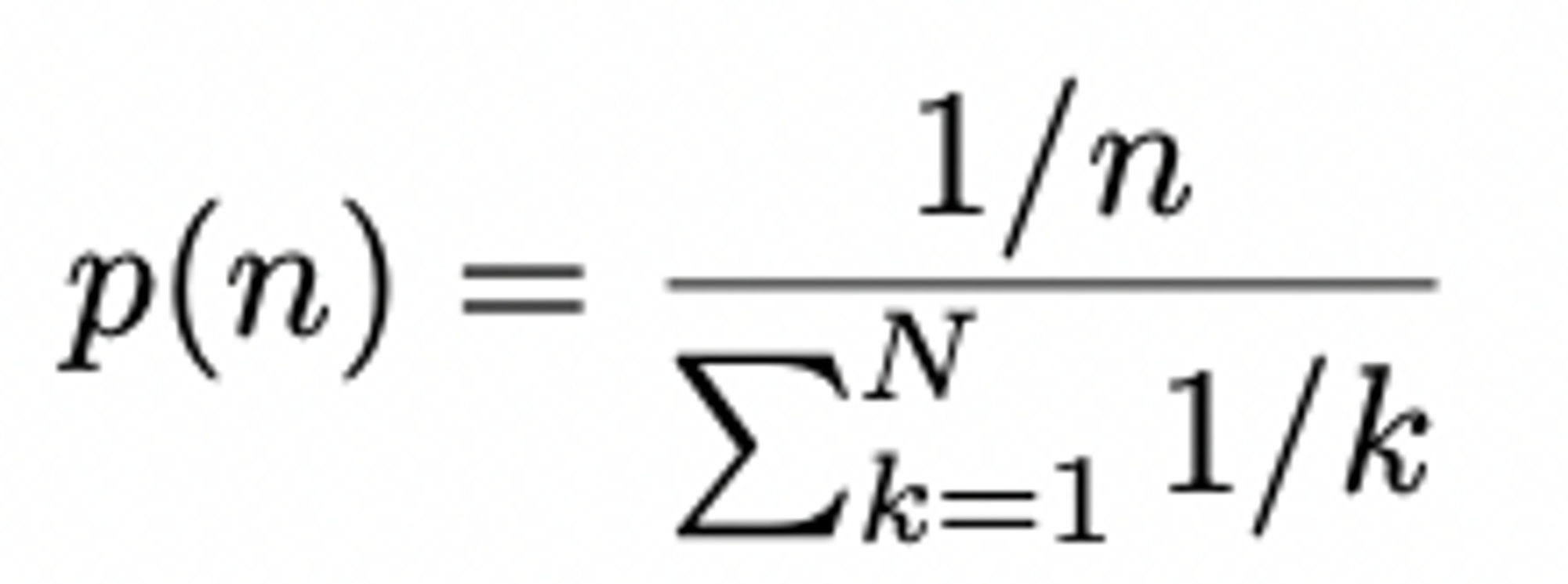 ( The probability for the length n )
( The probability for the length n )
batch size of 4096
LAMB optimizer
learning rate 0.00176
train all models for 125,000 steps
- BERT-based
- setup
-
Result
- OVERALL COMPARISON BETWEEN BERT AND ALBERT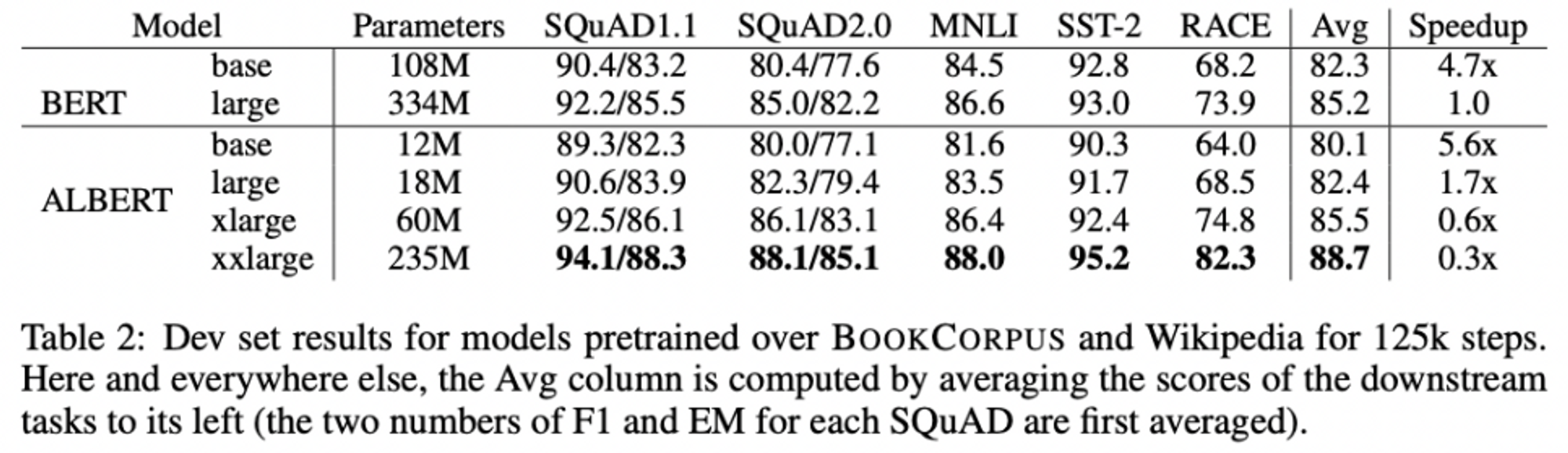
- ALBERT design choice의 가장 큰 장점 = parameter efficiency !
- ALBERT_xxlarge, BERT_large의 70%정도의 parameter로 더 좋은 성능을 냄
- 더 빠른 data throughput
- less communication, fewer computation → ALBERT, BERT보다 higher data throughput
- ALBERT_large, BERT_large보다 1.7배 빨랐음-
FACTORIZED EMBEDDING PARAMETERIZATION
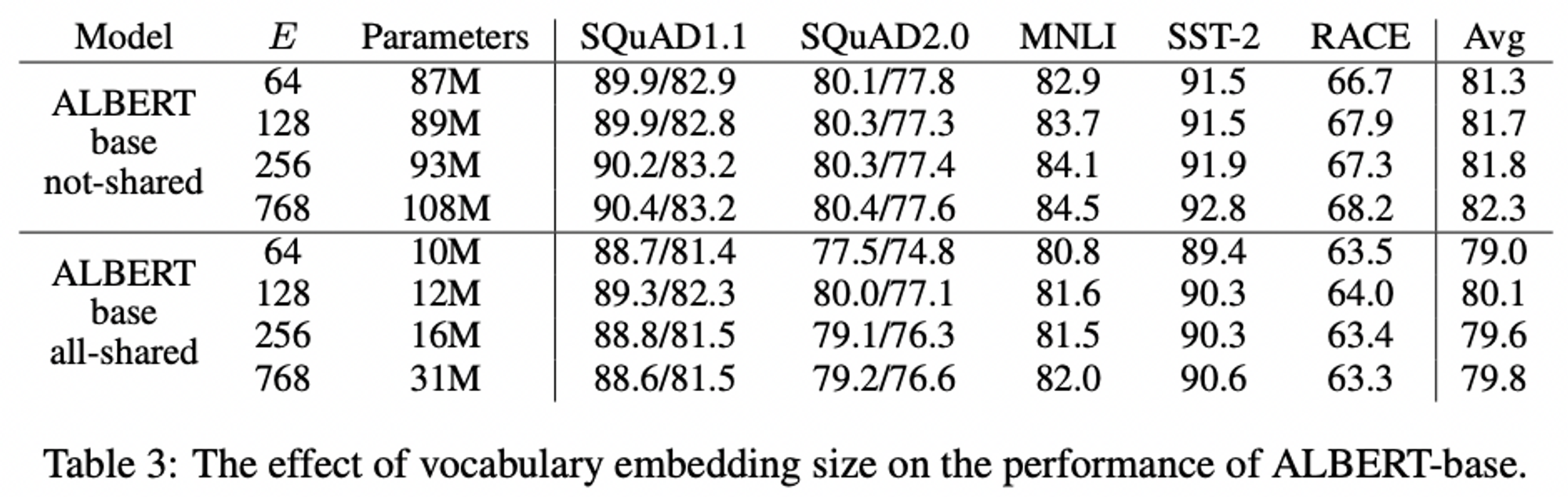
- vocabulary embedding size E의 영향
- 기존 BERT style, E가 클수록 더 나은 성능(상승폭이 크진 않음)
- ALBERT, E = 128일 때 최고의 성능
- vocabulary embedding size E의 영향
-
CROSS-LAYER PARAMETER SHARING
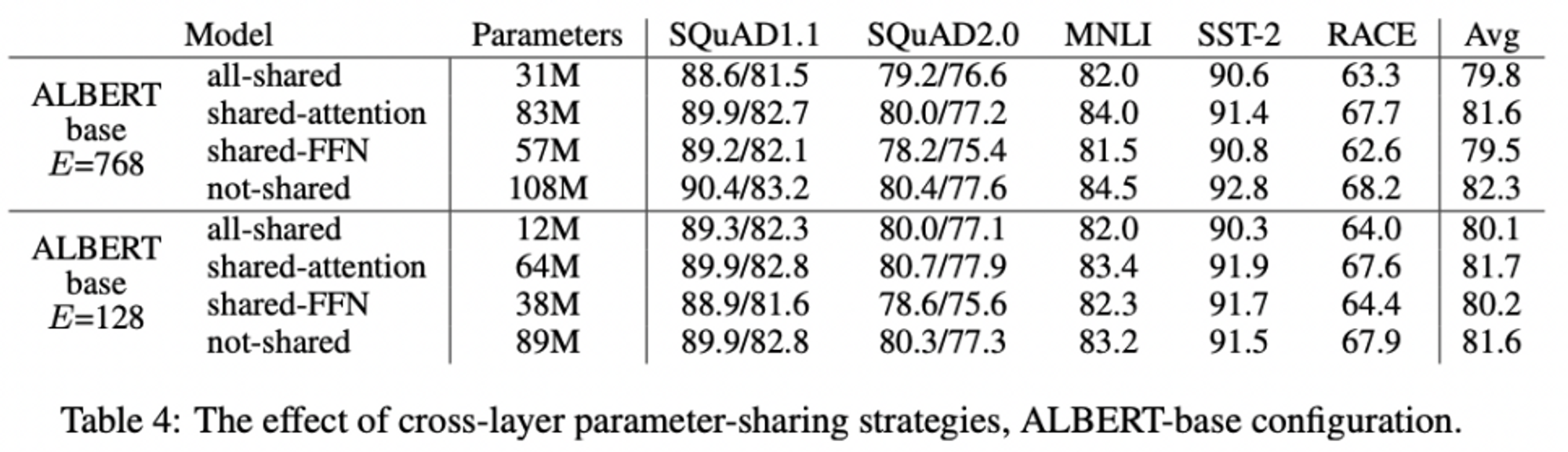
- 두 embedding size(768, 128)을 가진 ALBERT configuration 사용,
- all-shared(ALBERT) / shared-attention(Only Attention parameters) / shared-FFN(Only FFN parameters) / not shared(BERT) 로 나누어 실험
- all-shared strategy 를 사용하였을 때 성능 저하 발생(E=128일 때 E=768일 때보다 덜 저하)
- shared-FNN의 경우 성능저하가 가장 심했고, shared-attention에 대해서는 성능저하가 거의 없거나 미미했음
-
SENTENCE ORDER PREDICTION (SOP)

- NSP / SOP / X을 각각 채택했을 때 내부적 task( MLM, NSP, and SOP tasks)과 실무적 task의 성능에 어떤 영향을 미치는지를 실험
- NSP loss가 SOP task에 이점이 없다 (52.0% = none과 비슷한 정확도)
→ NSP는 topic shift 만 modeling한다! - SOP, NSP task를 비교적 잘 해결함(78.9% 정확도) + SOP task 더 잘 해결(86.5% 정확도)
- SOP, multi-sentence encoding task에 대한 실무적 task 성능이 더 높았음
- NSP loss가 SOP task에 이점이 없다 (52.0% = none과 비슷한 정확도)
- NSP / SOP / X을 각각 채택했을 때 내부적 task( MLM, NSP, and SOP tasks)과 실무적 task의 성능에 어떤 영향을 미치는지를 실험
-
WHAT IF WE TRAIN FOR THE SAME AMOUNT OF TIME?

- 오랫동안 training하면 대체로 성능 향상됨 → 학습 시간에 제약을 두고 실험을 진행해보자 !
→ 동일 시간동안 training한 결과, ALBERT-xxlarge의 성능이 BERT-large보다 평균에서는 1.5% 좋았고, RACE에서는 5.2% 좋았음
- 오랫동안 training하면 대체로 성능 향상됨 → 학습 시간에 제약을 두고 실험을 진행해보자 !
-
ADDITIONAL TRAINING DATA AND DROPOUT EFFECTS

- 지금까지는 Wikipedia and BOOKCORPUS datasets 만 사용해왔음 → 다른 데이터셋을 training dataset에 추가하면 어떻게 될까?
→ALBERT, 데이터셋이 추가되었을 때 성능이 향상됨
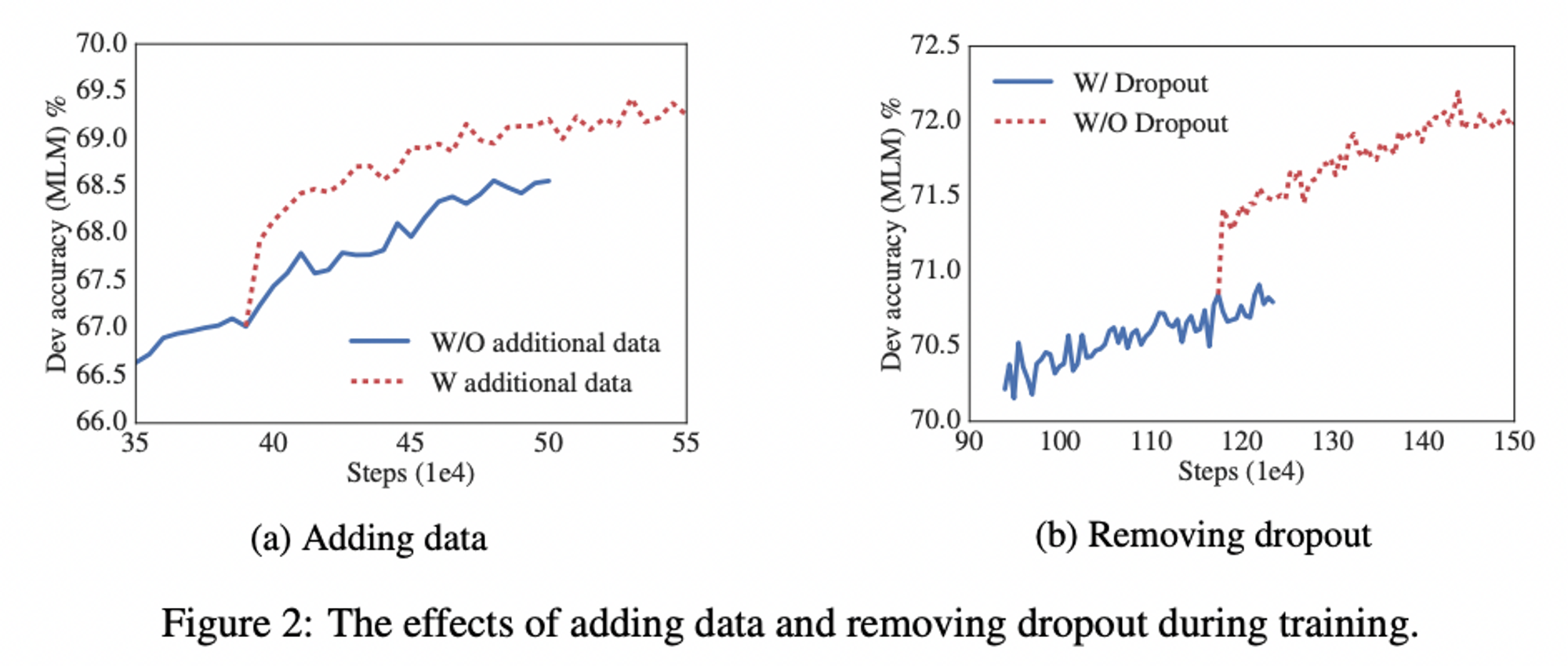
- 지금까지는 Wikipedia and BOOKCORPUS datasets 만 사용해왔음 → 다른 데이터셋을 training dataset에 추가하면 어떻게 될까?
-
성능을 보다 향상시키기 위해 dropout 제거 (1M step만큼 model training했는데 overfitting 일어나지 않았기에-)
→ dropout 제거 시 MLM 정확도 상당히 향상

-
실무 task에 대해서도 dropout 제거했을 때 성능이 향상되었음
- 원래 transformer 기반 모델들에서 dropout 제거했을 때 성능 저하된다는 것이 기존의 정설이었는데, ALBERT는 예외였음.
→ 다른 transformer 기반 architecture은 어떤지에 대한 후속 연구가 필요할 것으로 판단됨
- 원래 transformer 기반 모델들에서 dropout 제거했을 때 성능 저하된다는 것이 기존의 정설이었는데, ALBERT는 예외였음.
-
-
CURRENT STATE-OF-THE-ART ON NLU TASKS
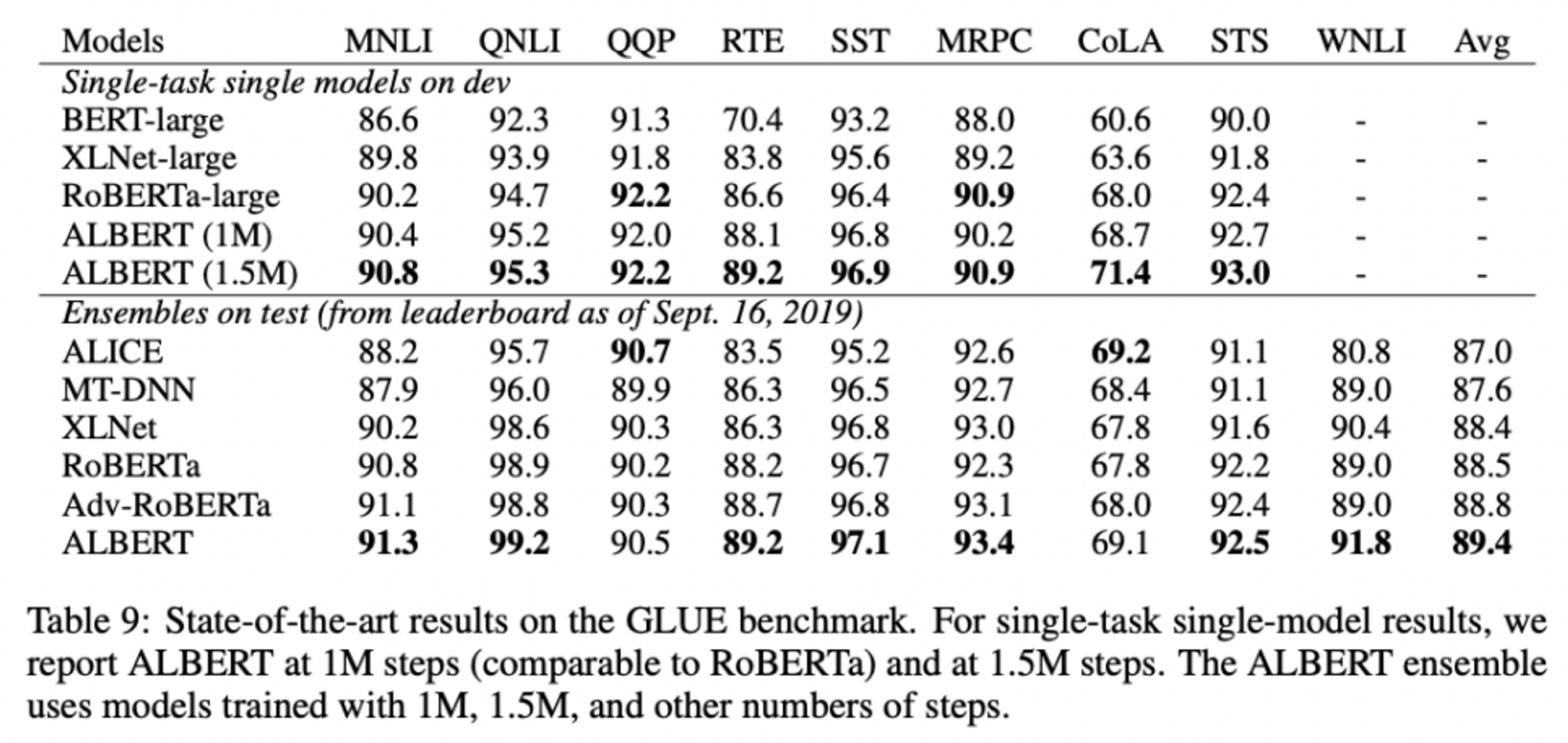
ALBERT, State-of-the-art results on the GLUE benchmark에서도 좋은 성능을 보였고,
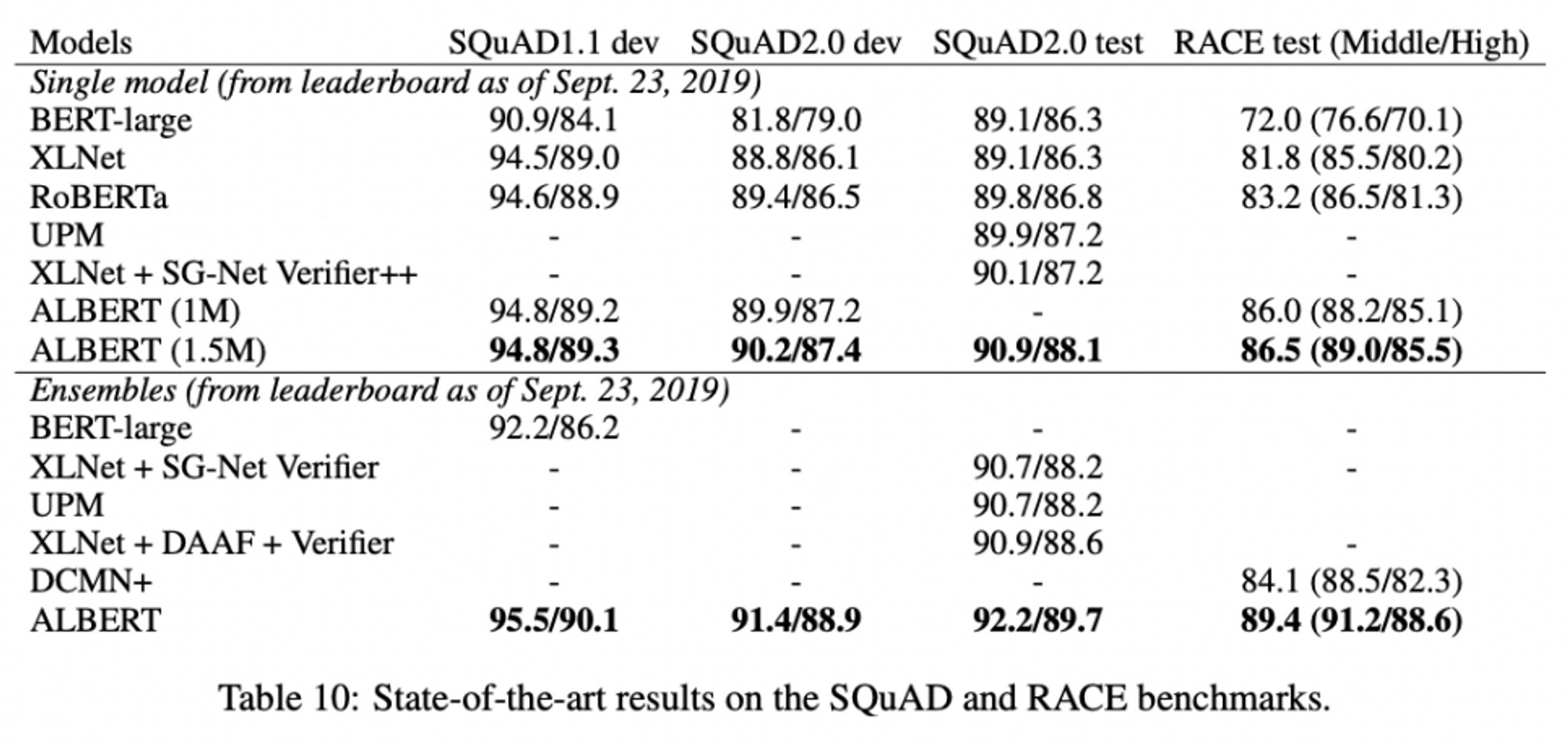
State-of-the-art results on the SQuAD and RACE benchmarks에서도 좋은 성능을 보였다.
Conclusion
-
ALBERT의 design choice
: Factorized embedding parameterization, Cross-layer parameter sharing, Inter-sentence coherence loss -
ALBERT의 design choice에 대한 실험 결과
- ALBERT, parameter efficiency가 높음 (ALBERT_xxlarge, BERT_large의 70%정도의 parameter로 더 좋은 성능을 냄)
- BERT보다 higher data throughput(less communication, fewer computation. 속도 증대)
- ALBERT에서 도입한 cross-layer parameter sharing, parameter 수는 현저히 감소하였으나 그에 비해 성능 저하는 미미했음
- ALBERT에서 도입한 SOP, NSP task를 비교적 잘 해결, SOP task 더 잘 해결, multi-sentence encoding task에 대한 실무적 task 성능 월등히 높음
- 동일 시간 training 했을 때 BERT 보다 성능 높음
- 데이터셋이 추가되었을 때 성능이 향상
- dropout 제거 시 MLM 정확도와 실무 task에 대한 성능 향상
- 현재의 state-of-the-art on NLU tasks에 대해서도 성능이 좋았음
→ ALBERT의 design choice, parameter을 줄이고 학습 속도를 개선함과 동시에 모델의 성능도 향상시켰다 !
Reference
- Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942.
