arxiv: https://arxiv.org/abs/1910.13461
date: 09/05/2022

Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., ... & Zettlemoyer, L. (2019). Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
Abstract
- BART, denoising autoencoder for pretraining seq2seq models
- Architecture Overview
- 기존의 Transformer-based neural machine translation architecture을 generalize한 형태
(BERT와 GPT의 방식을 합친 형태라고 봐도 무방할 듯)
- 기존의 Transformer-based neural machine translation architecture을 generalize한 형태
- Training BART
- 임의의 noising function으로 텍스트를 손상시킴
- 모델이 원문 텍스트를 복구하도록 학습
- BART’s noising approaches
- 원문 문장의 순서를 랜덤하게 뒤바꿈
- in-filling scheme : 다양한 길이의 텍스트를 하나의 mask token으로 대체
- BART’s significance
- text generation task로 fine-tune된 경우 좋은 성능 + comprehension task에 대해서도 좋은 성능
- abstractive dialogue / question answering / summarization task 등에서 SOTA 달성
Introduction
- Background
- Self-supervised method
- NLP task 전반에 있어 굉장히 좋은 성능을 보임
- masked language models = denoising autoencoder
: 랜덤한 길이의 텍스트를 mask한 후, denoising autoencoder로 하여금 mask된 텍스트를 복구하게끔 학습하는 방식
→ 성능 🫶 - 최근 연구들, masked token의 분포 개선 / masked token이 예측되는 순서 / masked token을 대체하는 맥락적인 요인들에 집중하는 경향
→ 특정 task에만 적합하다는 한계. 범용성 ↓
- Self-supervised method
- BART의 차별성
- Model Structure
: Bidirectional Transformer와 Auto-Regressive Transformer을 합친 형태의 모델
(cf. BERT = Bidirectional Transformer / GPT = Auto-Regressive Transformer)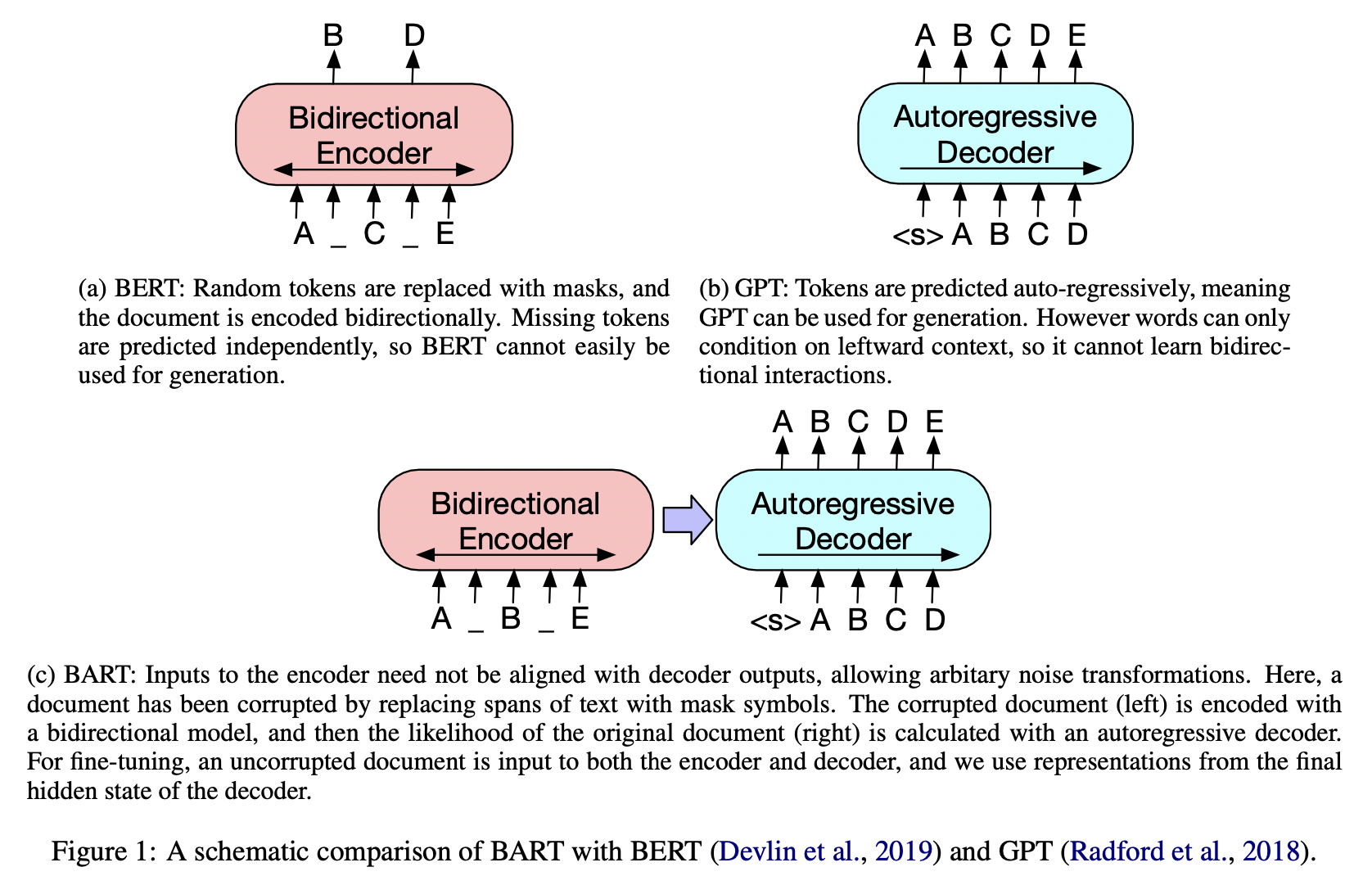 → 다양한 방식의 noising method 가능
→ 다양한 방식의 noising method 가능
- Pretraining Process
: arbitrary noising function- 원문 문장의 순서를 랜덤하게 뒤바꿈
- in-filling scheme : 다양한 길이의 텍스트를 하나의 mask token으로 대체
→ 모델이 문장 길이라는 요인을 더 고려하게 됨
- New Fine-tuning Scheme
- e.g., for machine translation
additional transformer layer 위에 BART 모델을 쌓는 구조- additional transformer layer, 외국어를 noised English로 번역하도록 학습
- BART로 noised English를 denoise하는 방식
- e.g., for machine translation
- Model Structure
Model
- Overview
- Model: Seq2seq model with BERT’s encoder + GPT’s decoder
“…seq2seq model with bidirectional encoder over corrupted text and a left-to-right autoregressive decoder…”
- Pre-training
: optimize the negative log likelihood of the original document
- Model: Seq2seq model with BERT’s encoder + GPT’s decoder
- Architecture
- 기본적으로 Seq2seq Transformer architecture 차용
- decoder의 각 layer, encoder의 마지막 layer에 대해 cross-attention 수행
- Base Model : 6 layers for encoder / 6 layers for decoder
- Large Model : 12 layers for encoder / 12 layers for decoder
- decoder의 각 layer, encoder의 마지막 layer에 대해 cross-attention 수행
- BERT의 encoder + GPT의 decoder 결합된 형태
- GPT’s trace
- activation function : ReLU → GeLU
- initialize parameters from N(0, 0.02)
- BERT’s trace
- BERT, word prediction 이전에 feed-forward network 추가적으로 거침. BART는 이 부분 생략
→ BART, 동일 규모의 BERT 모델에 비해 parameter 수가 약 10% 많음
- BERT, word prediction 이전에 feed-forward network 추가적으로 거침. BART는 이 부분 생략
- GPT’s trace
- 기본적으로 Seq2seq Transformer architecture 차용
-
Pre-training BART
-
process
- corrupt document
- optimize reconstruction loss
(decoder의 output - original document 사이 cross-entropy 계산)
-
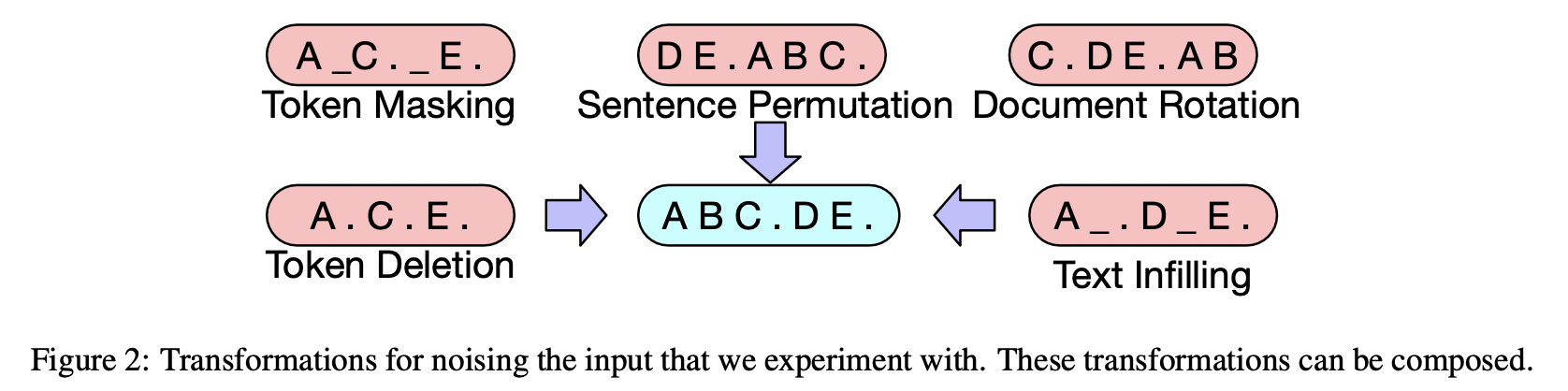
BART, 모든 종류의 document corruption 적용 가능
-
Token masking
: 토큰들이 랜덤하게 [MASK] 토큰으로 교체e.g. NLP 최고야 짜릿해 늘 새로워 → NLP 최고야 [MASK] 늘 [MASK] -
Token deletion
: 토큰들이 랜덤하게 지워짐. token masking과 달리 모델이 어떤 위치의 토큰이 없어졌는지 판단해야 함e.g. NLP 최고야 짜릿해 늘 새로워 → NLP 최고야 늘 -
Text infilling
: 다양한 길이(0~n)의 text span이 포아송 분포에 따라 샘플링되고, 각 text span이 하나의 [MASK] 토큰으로 교체됨. (text span의 길이가 0일 경우 해당 위치에 [MASK] 토큰이 삽입됨)
→ masked된 text span의 길이를 예측하게끔 함 -
cf. SpanBERT에서 제안된 방식이나 text span이 샘플링되는 분포가 다르고, text span 길이만큼 [MASK] 토큰이 삽입됨
e.g. text span = 3 SpanBERT : NLP 최고야 짜릿해 늘 새로워 → NLP [MASK] [MASK] [MASK] 새로워 BART : NLP 최고야 짜릿해 늘 새로워 → NLP [MASK] 새로워 -
Sentence permutation
: document를 마침표를 기준으로 문장 단위로 나눈 후, 문장 순서를 랜덤하게 뒤섞음e.g. NLP는 짜릿하다. NLP는 최고다. NLP는 늘 새롭다. → NLP는 최고다. NLP는 늘 새롭다. NLP는 짜릿하다. -
Document rotation
: 토큰을 랜덤하게 뽑은 후, 해당 토큰으로 document가 시작하게끔 함.
→ document의 시작점을 판단할 수 있게끔 학습e.g. NLP는 짜릿하다. NLP는 최고다. NLP는 늘 새롭다. → 최고다. NLP는 늘 새롭다. NLP는 짜릿하다. NLP는
-
-
Fine-tuning BART
: using BART for downstream tasks
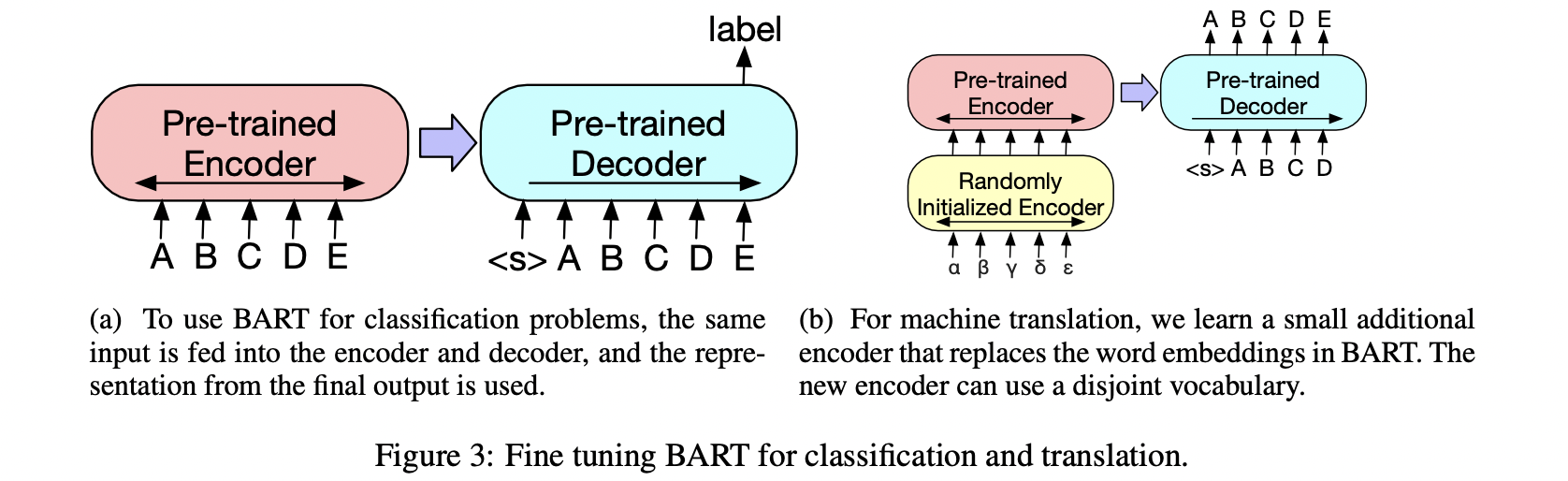
- Classification Tasks
- Sequence classification tasks
( decoder 마지막 layer 뒤에 multiclass linear classifier를 추가 )
1. encoder - decoder 모두에 동일한 input.
2. decoder 마지막 layer 결과값이 multiclass linear classifier의 input으로 들어감 - Token classification tasks
- 전체 document이 encoder - decoder의 input으로 들어감
- decoder 가장 위의 hidden state를 각 토큰의 representation으로 사용
- token을 classify하기 위해 해당 representation을 사용
- Sequence classification tasks
- Sequence Generation Tasks
: BART의 autoregressive decoder로 인해 가능 → BERT는 할 수 없었던 task- input sequence → encoder → decoder → output generated autoregressively
- Machine Translation
-
process
- BART의 encoder embedding layer를 randomly initialized encoder로 교체
- BART 자체를 하나의 pretrained decoder로 사용
- cf. randomly initialized encoder training
- BART의 parameter freeze하고 encoder / BART positional embeddings / BART의 encoder 첫 layer의 self-attention input projection matrix만 update
- 전체 model parameter을 적은 수의 iteration으로 학습시킴
- e.g., French to English translation
- additional transformer layer, French를 noised English로 번역하도록 학습
- BART로 noised English를 denoise하는 방식
-
Comparing Pre-training Objectives
-
BART base model (6 encoders - 6 decoders)과 유사한 규모의 BERT base model 간 성능 비교
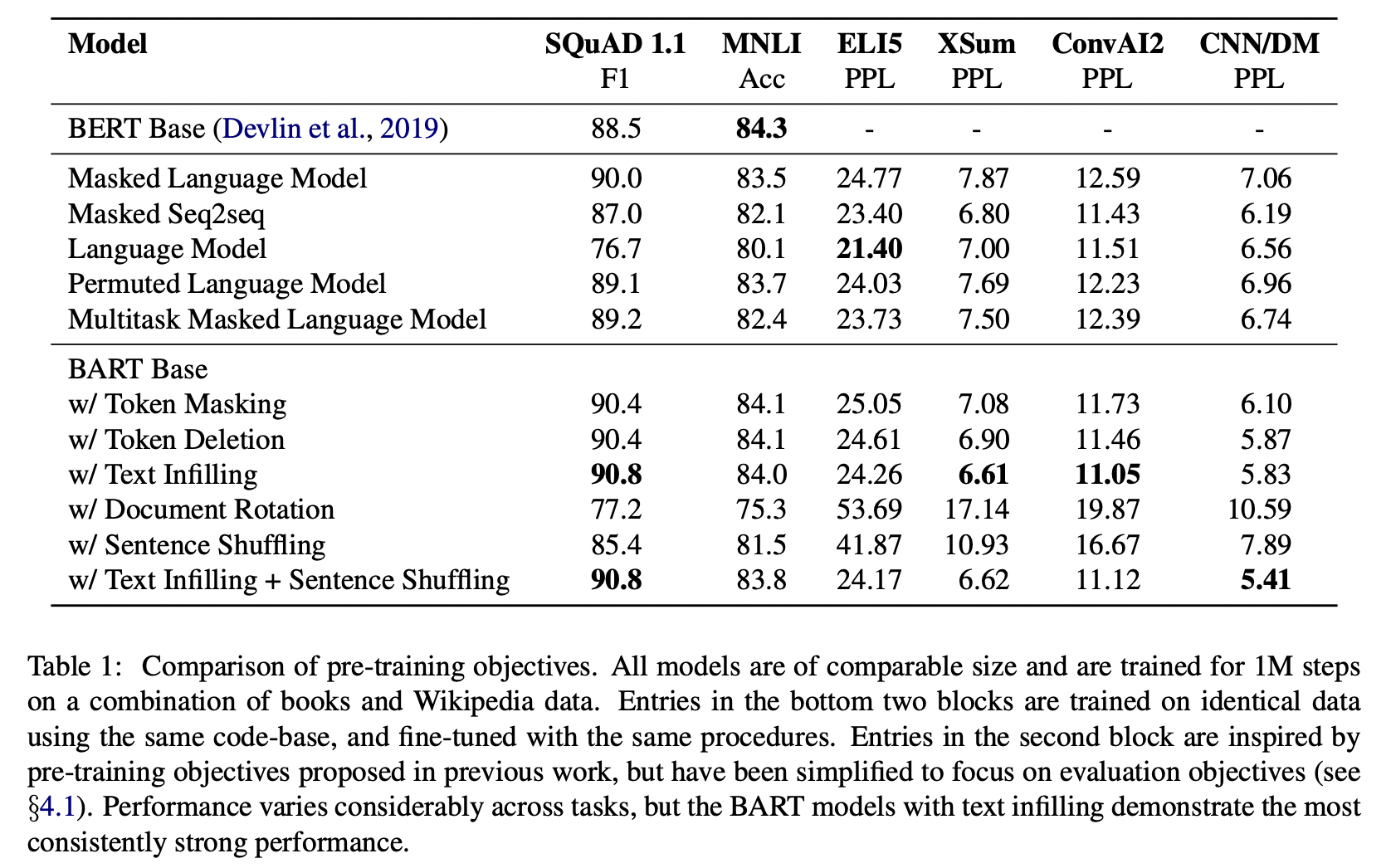
- 시사점
- downstream task에 맞는 pre-training method가 존재
- token masking이 중요
: rotating documents / permuting sentences 단일로는 성능 개선 미미
token deletion / token masking 등의 방법을 사용했을 때 성능 🫶
( 둘 중에서는 deletion의 효과가 더 좋음 ) - Left-to-right pre-training이 generation의 성능을 높임
- SQuAD task를 위해서는 Bidirectional encoder가 필수적
( Left-to-right decoder만으로는 성능 🥲 )
- 시사점
-
BART large model (12 encoders - 12 decoders)과 유사한 규모의 다른 model 간 성능 비교
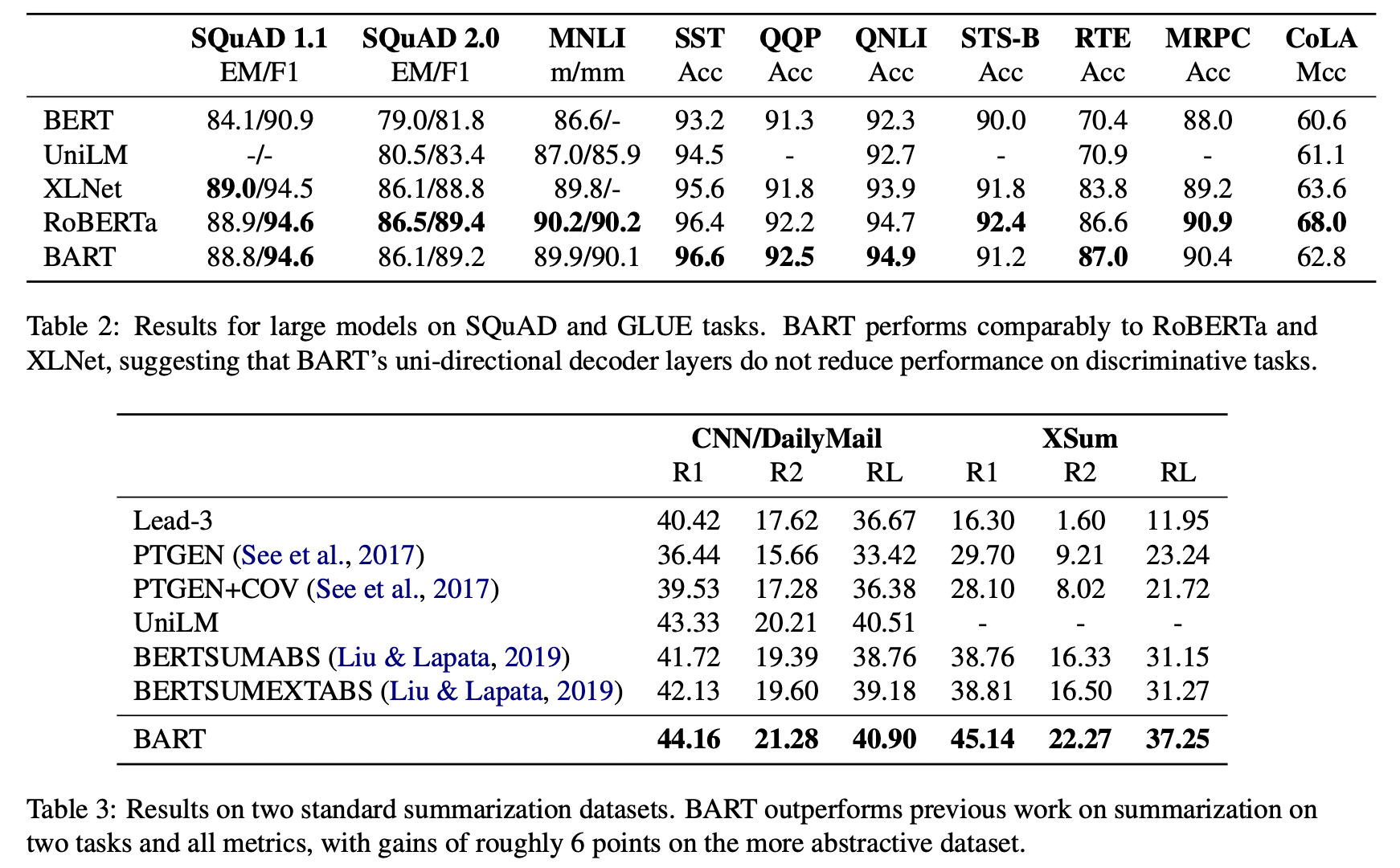
- 시사점
- BART의 uni-directional decoder(left-to-right autoregressive decoder)가 bidirectional encoder를 요하는 것으로 알려진 task들에서도 눈에 띄는 성능 저하를 야기하지 않았음
- Summarization에는 BART가 특화되어있다 !
- 시사점
Conclusion
- BART, BERT와 GPT를 결합한 형태의 seq2seq 모델.
GPT의 left-to-right autoregressive decoder와 BERT의 bidirectional encoder를 결합한 형태 - 넓은 range의 noising scheme 제안 및 적용
- 분류 task에 있어 RoBERTa와 유사한 성능 + text generation task에 있어 SOTA 달성
