date: 09/12/2022

Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1 (8), 9.
Abstract
- (논문 저술 시점) NLP task, 대체로 task-specific dataset에 대한 supervised learning task로 접근
→ 대용량 dataset을 갖고 unsupervised manner로 모델을 학습시켜보겠다 ! - GPT-2, 1.5B parameter Transformer → zero-shot setting에서 SOTA 달성
1. Introduction
- 기존 ML system의 한계
-
large data + high capacity model + supervised learning = 좋은 성능
-
but data distribution 혹은 task specification이 조금이라도 어긋났을 때 성능 저하 초래
: 다양한 input에 대한 대처 어렵→ 보다 generalizable한 모델 要
-
- Multitask learning
- (논문 저술 시점) 성능 좋은 모델, pre-training + supervised fine-tuning 방식
-
recurrent network를 pretrain (pre-training)
-
task-specific architecture에 word vectors가 input으로 사용됨 (supervised fine-tuning)
-
기존 recurrent network의 contextual representation이 transferred
→ task-specific architecture + supervised learning, 더이상 필요없다 !
-
- “general method of transfer”
- zero-shot setting에서 down-stream tasks 수행 可한 방식 제안
- (논문 저술 시점) 성능 좋은 모델, pre-training + supervised fine-tuning 방식
2. Approach
- language modeling : 언어 모델이 이전 단어들로부터 다음 단어를 예측하는 일 cf. 언어모델 (language model)
: 언어라는 현상을 모델링하고자 단어 시퀀스(문장)에 확률을 할당하는 모델
→ 언어 모델로 하여금 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 방식이 가장 일반적- 기존 language modeling
- single task : 조건부확률 예측
- general task (multi-task setting) : 조건부확률 예측
- 기존 language modeling
- hypothetical setup
- supervised learning, unsupervised learning과 목표점은 똑같으나 sequence의 일부에 대해서만 evaluated
( supervised learning에서는 dataset이 임의로 짝지어진 pair 형식(corpus의 일부, objective)으로 주어지니까 corpus 전체가 하나의 dataset으로 주어지는 unsupervised learning과 비교했을 때 sequence의 subset으로만 evaluated 된다~ 라는 의미로 해석함 ) - 그런데 결국 supervised learning의 objective과 unsupervised learning objective은 동일하기에 supervised learning의 global minimum = unsupervised learning의 global minimum
- supervised learning, unsupervised learning과 목표점은 똑같으나 sequence의 일부에 대해서만 evaluated
- 해당 hypothetical setup 下, 어떤 것이 예측해야 할 output(objective)인지 supervised 되지 않아도 language modeling이 가능하다 !
- language model의 규모가 충분히 큰 경우 multitask learning 수행 可, but 학습 속도는 supervised 방식보다 느림
2.1. Training Dataset
- (기존 연구) dataset, 단일 도메인의 text인 경우 多
↠ e.g., 뉴스 기사, 위키피디아, 소설 등 - 우리는 다양한 도메인과 문맥을 아우르는 대규모 text dataset WebText를 구축했다 !
-
웹 크롤링 데이터 활용하는 경우 data quality 문제 有
→ 사람이 선별한 웹페이지만을 크롤링하는 방식 채택
-
Reddit에서 추천수가 3 이상인 포스트 내 포함된 링크 4500만 개 크롤링
( 위키피디아 링크는 크롤링하지 않음 )
-
2.2. Input Representation
- LM(language model)의 두 방식
- byte-level LMs : word-level LMs에 비해 대규모 데이터셋에는 적합하지 않음
- word-level LMs
- BPE(Byte Pair Encoding) 채택
-
byte-level LM과 word-level LM의 중간지점
→ word-level LM의 경험적 이점 + byte-level LM의 범용성 모두를 가짐 -
but BPE를 byte sequence에 적용할 경우 sub-optimal allocation 발생
(e.g., dog. dog! dog, dog? 를 각기 다른 token으로 인식)
→ BPE가 단어와 특수기호 카테고리를 구분하게끔 함→ 정보 소실을 야기하는 pre-processing 및 tokenization 필요 X
-
2.3. Model
-
Transformer based arichitecture
-
GPT-1과 기본적으로 동일한 구조
-
Modifications
- Layer normalization → sub-block의 input으로 옮겨짐(≒ pre-activation residual network) : LayerNorm(sublayer(x) + x) → x+sublayer(LayerNorm(x))의 형태
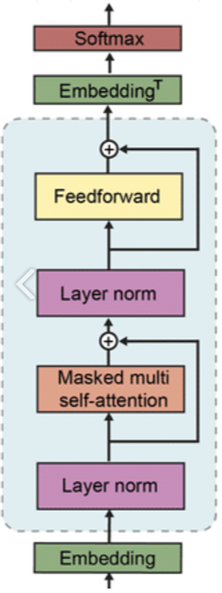
- Additional layer normalization → 마지막 self-attention block에 추가됨
- Modified initialization 사용
: residual layer 가중치, initialize할 때 로 scale ( N = number of residual layers ) - 대용량 data 사용
: context size 512 → 1024 tokens & batch size 512
- Layer normalization → sub-block의 input으로 옮겨짐(≒ pre-activation residual network) : LayerNorm(sublayer(x) + x) → x+sublayer(LayerNorm(x))의 형태
-
3. Experiments

- 4 LMs
- 117M model ≡ GPT-1
- 345M model ≡ BERT-large
- 1542M model ≡ GPT-2
- a
- lr of each model, manually tuned
- all model underfit WebText dataset
→ 더 오래 학습시키면 성능 더 올라갈수도
- a
3.1 Results
- zero-shot setting에서 다양한 language modeling datasets에 대해 SOTA 달성 ( fine-tuning X )
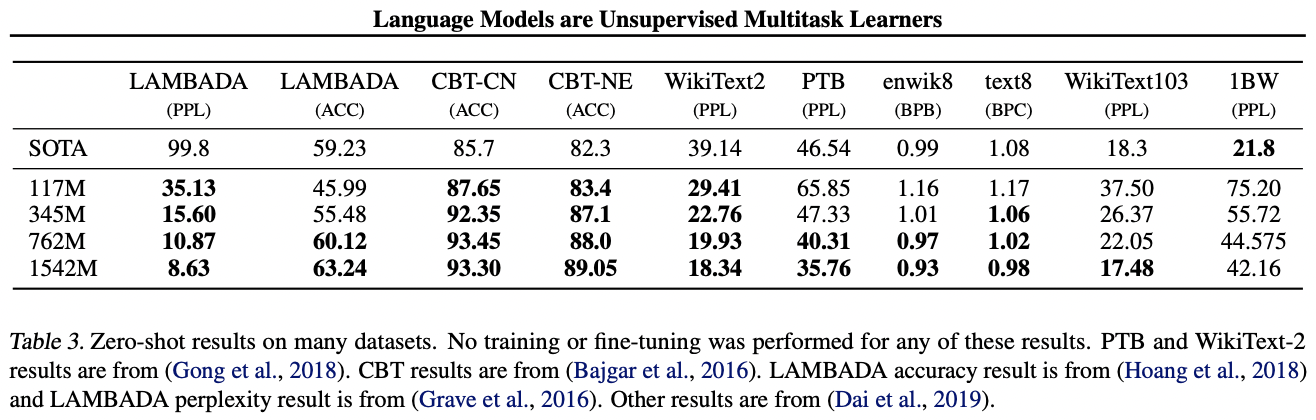
- downstream tasks에 대한 성능은 task들마다 다르고, 편차가 심함
4. Discussion
- NLP 분야의 unsupervised task learning, potential이 있다 !
- GPT-2, zero-shot setting에서 reading comprehension 성능 뛰어남
- 하지만 아직 question answering, translation 등 다른 task에서의 성능은 그닥 좋지 못하고, summarization의 성능은 현저히 떨어짐 (no better than random) 😢 → 발전 要
5. Conclusion
- 큰 규모의 Language model이 상당한 규모의 dataset으로 학습된 경우, 도메인을 초월해서 좋은 성능을 낼 수 있다 !
- GPT-2, 8개 중 7개의 language modeling datasets에 대해 SOTA
- zero-shot setting에서 GPT-2가 수행할 수 있는 task의 다양성↑
→ 다양한 도메인를 포괄하는 대규모 corpus로 학습된 language model 은 supervised learning이 없이도 좋은 성능을 낼 수 있음을 시사
💡 Key Point
- 대규모 dataset + 대규모 model + unsupervised learning으로 fine-tuning 없이 zero-shot setting에서 downstream tasks에 바로 적용할 수 있는 모델인 GPT-2 구축
- downstream task에 바로 사용할만한 성능을 내지는 못했지만, NLP 분야의 unsupervised task learning에도 가능성이 있음을 여실히 보여줌
