arxiv: https://arxiv.org/abs/1905.07129
date: 09/26/2022

Zhang, Z., Han, X., Liu, Z., Jiang, X., Sun, M., & Liu, Q. (2019). ERNIE: Enhanced language representation with informative entities. arXiv preprint arXiv:1905.07129.
Abstract
- (논문 저술 시점) 대규모 코퍼스로 학습된 pre-trained model (e.g., BERT) 은 텍스트의 의미 패턴을 잘 포착하며, 이를 fine-tuning 시켰을 때 다양한 NLP task에서 좋은 성능을 내고 있음
- 그러나 현존하는 pre-trained language model은 knowledge graph를 반영하고 있지 않음
- Knowledge graphs를 언어모델 학습에 반영시켰을 때 더 나은 언어 모델이 구축된다 !
-
학습 시 대규모 코퍼스 + knowledge graphs를 활용한 발전된 언어모델 ERNIE 제안
-
언어의 의미 + 어휘 + 지식 정보 모두 활용 가능하다는 이점
( 실제로 지식 기반 task에서 발전된 성능을 보였고, 여타 다른 NLP task에 대해서도 BERT 모델의 SOTA에 근접한 성능을 보였다~ )
-
Introduction
Background
-
대규모 pre-trained language model의 단점
-
언어 이해에 있어 지식 정보를 통합하여 활용하지 않는다 !
-
e.g., Bob Dylan wrote Blowin’ in the Wind in 1962, and wrote Chronicles: Volume One in 2004
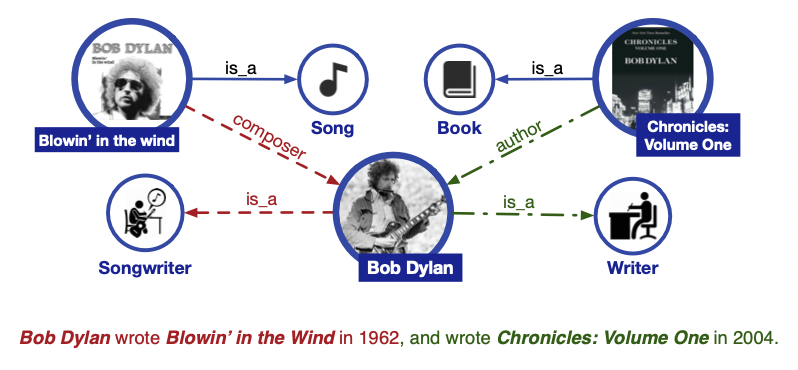
-
문제점
- Entity typing task 차원
cf. entity typing task : 특정 개체에 독자적인 특성을 부여하는 task. e.g., 밥 딜런 : 작곡가/작가- Blowin’ in the Wind 가 노래 제목이고, Chronicles: Volume One 가 책 제목이라는 것을 알지 못하면, Bob Dylan이 작곡가이자 작가로서 활동했다는 것을 알 수 없음
- Relation classification task 차원
cf. relation classification task : 문맥에 따라 entity 쌍의 관계 label을 분류하는 task- Bob Dylan이 작곡가이자 작가로서 활동했다는 것을 알 수 없기 때문에 작곡가 - 작가라는 단어들 간의 세밀한 relation classification 또한 어려움
- Entity typing task 차원
-
기존 대규모 pre-trained model 하에서는 병렬적으로 연결된 두 문장의 의미적 관계 고려 X
- “[UNK] wrote [UNK] in [UNK]” 의 형태로 단순 변환된 후, [UNK]에 들어갈 단어를 예측하도록 학습되기 때문
→ 보다 풍부한 지식 정보를 고려한다면 더 나은 언어 이해 + 지식 기반 task의 성능 향상이 야기될 것
-
-
Challenges / ERNIE’s Approaches
-
외부 지식 정보(knowledge graphs)를 언어 모델에 통합시킬 때의 main challenges - approaches
-
Structured Knowledge Encoding
-
주어진 텍스트에 대해, knowledge graph의 중요한 지식 정보를 어떻게 추출하고 인코딩할 것인가
→ ERNIE, knowledge graph의 주요 지식 정보 추출 및 인코딩을 위해 다음과 같은 절차를 거침
-
text의 entity mention과 knowledge graph에 있는 entity를 일치시킴
e.g.,
text = “Da Vinci painted Mona Lisa. Mona Lisa is in Louvre, which is a museum located in Paris. Paris is well-known for its landmark Tour Eiffel.”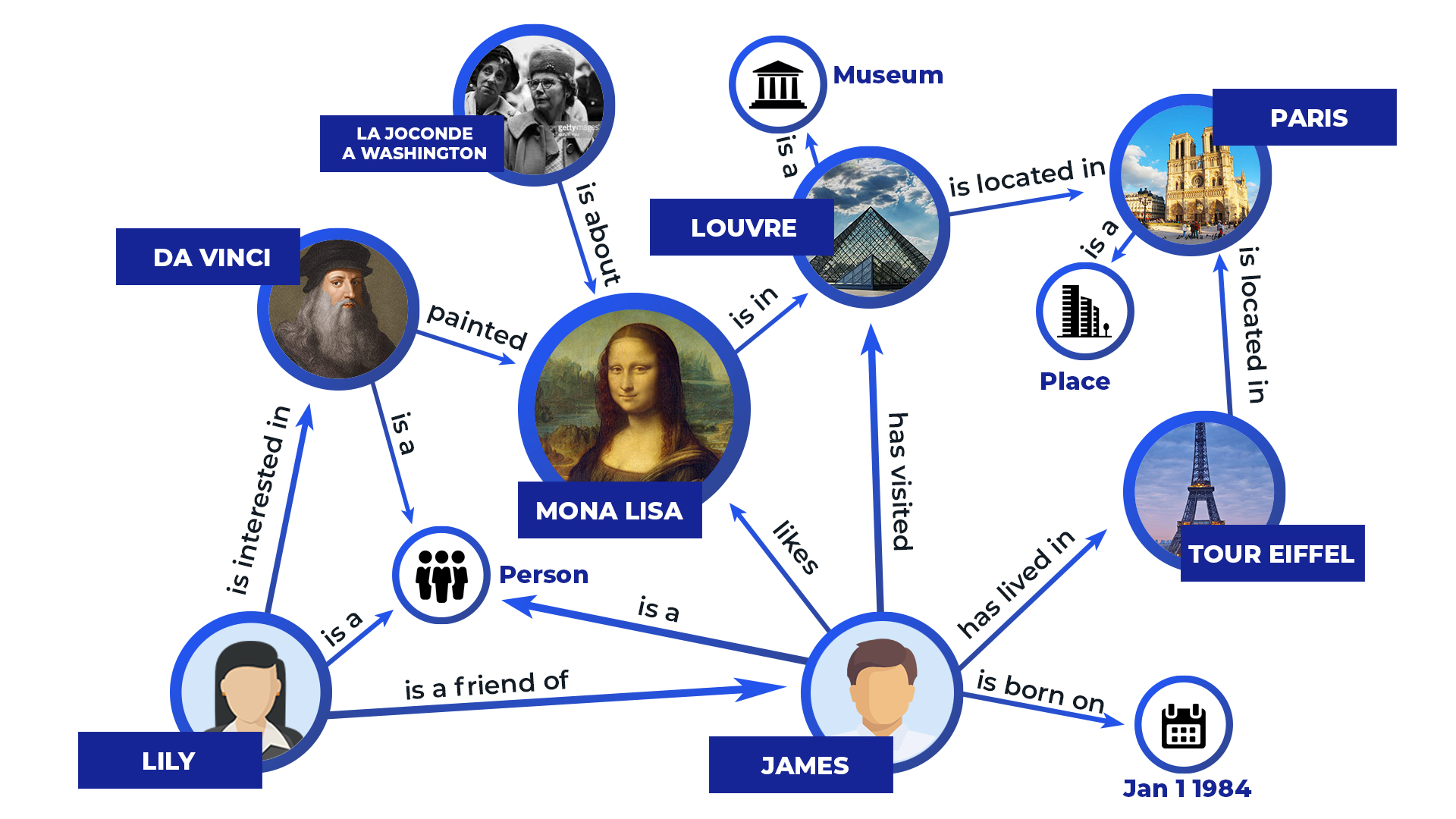
-
text의 entity mentions : Da Vinci, Mona Lisa, Louvre, Paris, Tour Eiffel
-
knowledge graph의 entity mentions : Da Vinci, Mona Lisa, Louvre, Paris, Tour Eiffel, James, Lily, La Joconde a Washington
→ text의 entity mention에 상응하는 knowledge graph의 entity mention align
-
-
knowledge graph의 graph stucture 인코딩
- TransE 등의 지식 임베딩 알고리즘 활용
- TransE, knowledge graph의 벡터 임베딩 분야 포문을 연 논문. 기본적으로 knowledge graph는 entity(대상)들과 그 사이의 relation(관계)로 구성되는데, 해당 분야의 데이터 표현 방식은 다음과 같음. (h,l,t) -> head, label, tail head와 tail은 두 entity이며, label은 두 entity 간의 관계를 의미. head, label, tail의 예시를 하나만 들자면 다음과 같음 e.g., Da Vinci(HEAD) painted(LABEL) Mona Lisa(TAIL). → TransE에서는 HEAD과 TAIL 사이의 관계를 벡터 임베딩으로 표현하고자 하였음
논문에서는 이를 translation이라고 명명했는데, 이에 따라 논문에서는 head와 tail 간의 relationship vector를 translation vector라고 칭함.
→ Translation을 통해 어떠한 개체를 다른 개체로 매핑한다고 생각하면 될 듯.
- TransE, knowledge graph의 벡터 임베딩 분야 포문을 연 논문. 기본적으로 knowledge graph는 entity(대상)들과 그 사이의 relation(관계)로 구성되는데, 해당 분야의 데이터 표현 방식은 다음과 같음. (h,l,t) -> head, label, tail head와 tail은 두 entity이며, label은 두 entity 간의 관계를 의미. head, label, tail의 예시를 하나만 들자면 다음과 같음 e.g., Da Vinci(HEAD) painted(LABEL) Mona Lisa(TAIL). → TransE에서는 HEAD과 TAIL 사이의 관계를 벡터 임베딩으로 표현하고자 하였음
- TransE 등의 지식 임베딩 알고리즘 활용
-
entity에 대한 embedding을 ERNIE의 input으로 넣음
-
-
-
Heterogeneous Information Fusion
- 언어 모델의 pre-training 과정, knowledge representation과 다른데 이를 어떻게 다룰 것인가
cf. knowledge representation → 두 개의 독립적 벡터 공간 수반
→ ERNIE’s approach
- Benchmarking BERT’s pre-train objective
: masked language model(MLM)과 next sentence prediction(NSP) - New pre-train objective
: input text의 entity를 랜덤하게 마스킹하고, 모델로 하여금 knowledge graph에서 이에 상응하는 entity를 선택하게끔 함
→ token 단위 뿐 아니라 entity 단위에서의 학습도 총체적으로 진행. input으로 들어가는 텍스트와 knowledge graph 임베딩 값을 보다 잘 융합시키기 위함.
- 언어 모델의 pre-training 과정, knowledge representation과 다른데 이를 어떻게 다룰 것인가
-
Methodology
Model Architecture - Overview
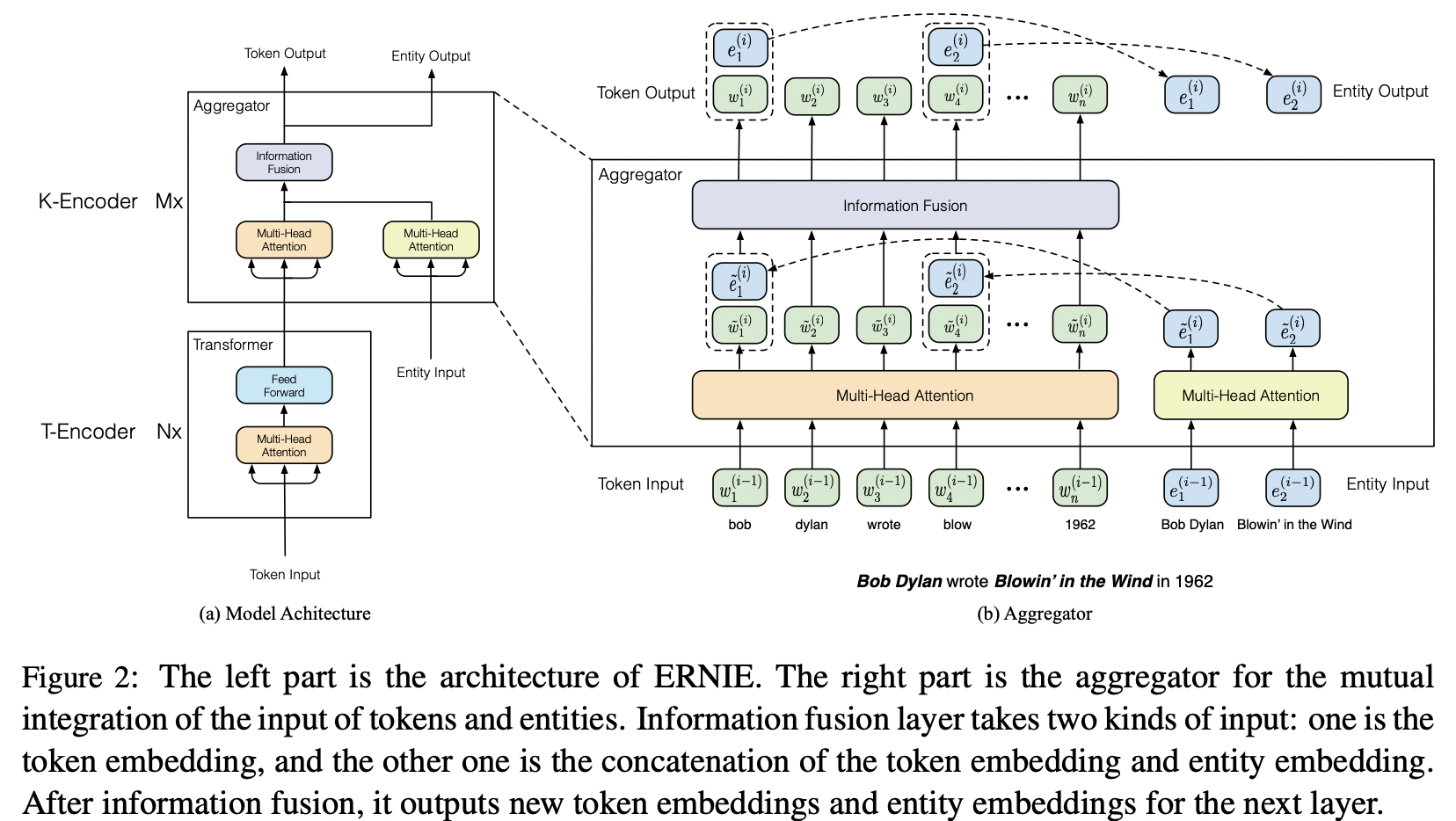
- 두 개의 stacked modules
- T-Encoder ( textual encoder )
: input token의 의미적 + 어휘적 정보 포착 - K-Encoder ( knowledgeable encoder )
: knowledge graph 임베딩 값을 T-Encoder에서 도출된 텍스트 정보에 통합시킴
→ 이질적인 토큰 정보-entity 정보를 하나의 벡터 공간으로 통합
- T-Encoder ( textual encoder )
T-Encoder
- 의미적, 언어적 features = { } 을 도출하는 역할
- Architecture : multi-layer bidirectional Transformer encoder
- Process
- input embedding 도출
token embedding + segment embedding + positional embedding 合 - 결과적으로 의미적, 언어적 features = { } 도출cf. T-Encoder, multi-layer bidirectional Transformer encoder로, BERT 구조와 동일하므로 BERT 모델에 token sequence를 넣어서 의미적, 언어적 맥락을 계산한다고 간단히 생각하면 될 듯 !
- input embedding 도출
K-Encoder
- 의미적, 언어적 features = { } 에 지식 정보 주입하는 역할
- Architecture : stacked aggregators
- token과 entity 모두를 인코딩하되, 이들의 이질적인 feature를 융합시키는 역할 또한 수행
- Process
-
entity sequence를 TransE의 input으로 넣어 entity embedding = 化
-
의미적, 언어적 features = { } 과 ****entity embedding = 모두를
K-Encoder의 input으로 넣음
→ 두 이질적인 정보를 융합 + 마지막 output embedding 도출 -
output embedding 와 , task들에서 features로 사용됨
(이후 수식 bold 생략)
-
- Process in Detail
- i 번째 aggregator의 경우,
이전 aggregator의 output embedding, input token embedding { } 과 entity embedding { } 이 두 개의 각기 다른 multi-head self-attention의 input으로 들어감 - multi-head self-attention의 결과값 { } 와 { },
information fusion layer의 input으로 들어감- token과 entity sequence의 융합 + 각 token과 entity에 대한 output embedding 계산
- information fusion 과정
- e.g., 토큰 와 이에 상응하는 entity 의 경우( = 토큰과 entity 정보를 융합하는 inner hidden state, 𝞼 = 비선형 활성화함수. 주로 GELU )
- e.g., 토큰 에 상응하는 entity 가 없는 경우
- e.g., 토큰 와 이에 상응하는 entity 의 경우
- Overall procedure
- i 번째 aggregator의 경우,
→ 마지막 aggregator의 output, token과 entity들에 대한 최종 output embedding이 됨
Pre-training for Injecting Knowledge
- text embedding에 지식 정보 주입하기 위해 새로운 pre-training task 要
- Denoising Entity Auto-encoder(dEA)
: token-entity mapping 한 것 중 entity 부분 일부를 랜덤하게 masking → token에 상응하는 entity를 예측하게끔 함- 토큰 에 대한 entity distribution( linear = linear layer. (7), dEA의 cross-entropy loss function 계산에 쓰임 )
- 토큰 에 대한 entity distribution
- dEA process
- 5%에 대해 기존 entity를 다른 랜덤한 entity로 교체
: 토큰이 잘못된 entity와 mapping 되었음을 포착하고 이를 고치게끔 학습 - 15%에 대해 token-entity mapping 자체를 masking
: 모든 token-entity 대응을 찾아내지 못했다는 것을 포착하고 이를 고치게끔 학습 - 나머지 80%에 대해서는 token-entity mapping을 그대로 놔둠
: 어떤 것이 올바른 mapping인지 판단하고, token-entity 정보를 융합하여 보다 나은 언어 이해를 도모
- 5%에 대해 기존 entity를 다른 랜덤한 entity로 교체
- BERT와 유사하게, ERNIE도 MLM task와 NSP task를 pre-training task로 채택 (의미적/어휘적 정보 포착)
→ 전체 pre-training loss, dEA, MLM, NSP loss의 合
Fine-tuning for Specific Tasks
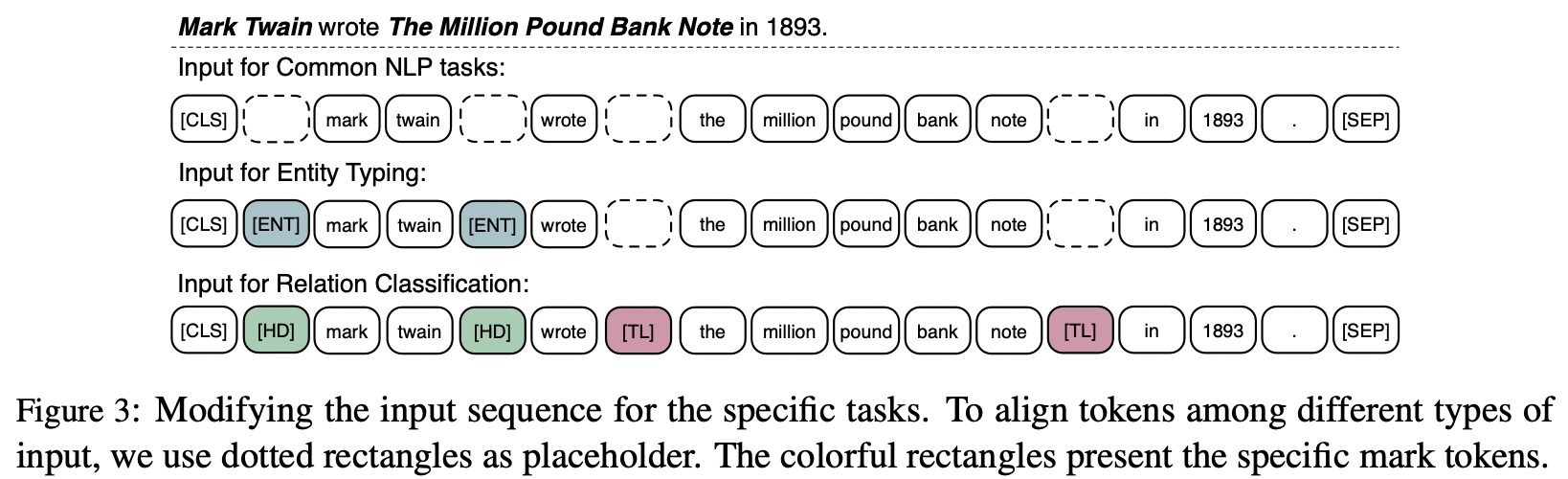
- ERNIE, 기본적으로 BERT와 유사한 fine-tuning 방식
- 문장 구분을 위해 [CLS] 토큰 사용
- 지식 기반 task들에 대해서는 특별한 fine-tuning 방식을 채택
- Relation Classification
: 문맥에 따라 entity 쌍의 관계 label을 분류하는 task- input token sequence에 대해 두가지 mark token 추가
- [HD](head entity), [TL](tail entity)
- input token sequence에 대해 두가지 mark token 추가
- Entity Typing
: 특정 개체에 독자적인 특성을 부여하는 task- relation classification의 단순화된 버전
- input token sequence에 mention mark token 추가
- [ENT] : 타겟이 되는 entity만 표시
- Relation Classification
Experiments
Pre-training Dataset
- from scratch 부터 ERNIE 학습시키는건 무리
→ BERT의 파라미터 차용해서 T-Encoder의 Transformer block initialize - Dataset, English Wikipedia( text ) & Wikidata ( knowledge graph )
- English Wikipedia
: 4500M개의 subwords와 140M개의 entities로 구성. (단, 3개 미만의 entity로 구성된 문장 제외) - Wikidata
: Wikidata의 일부 sampling → TransE를 거쳐 entity embedding 化
- English Wikipedia
Entity Typing
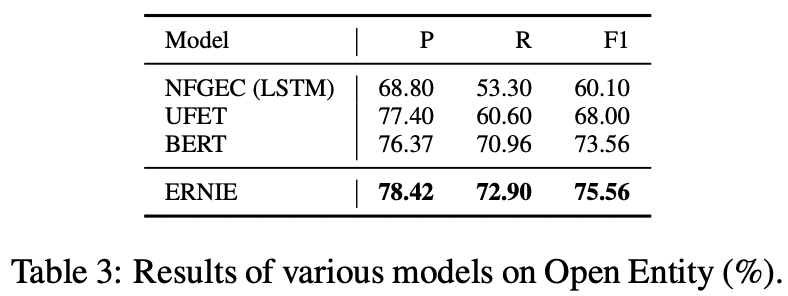
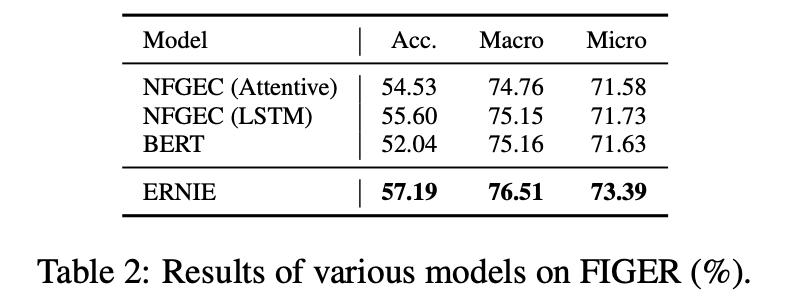
ERNIE, entity typing의 다른 baseline model + BERT 보다 좋은 성능 !
Relation Classification
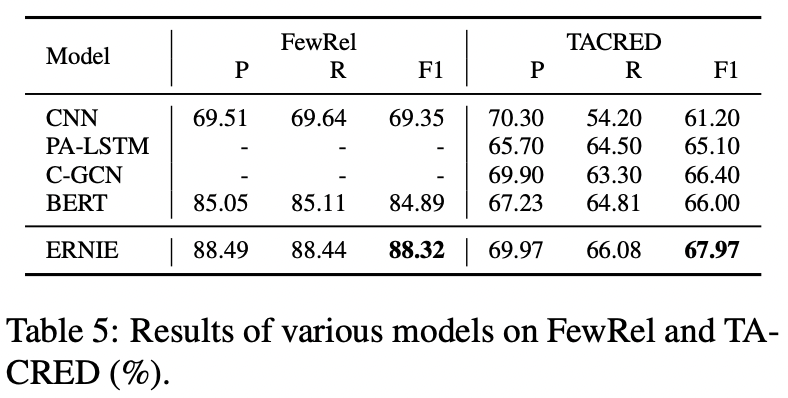
ERNIE, relation classification의 다른 baseline model + BERT 보다 좋은 성능 !
GLUE ; General Language Understanding Evaluation
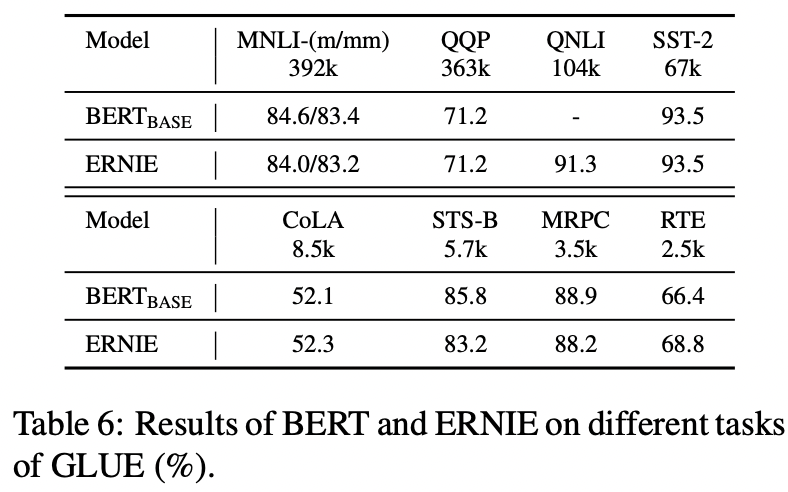
- ERNIE,
대규모 데이터셋을 수반하는 task에 대해서는 BERT_base와 상응하는 성능을 냄
소규모 데이터셋을 수반하는 task에 대해서는 BERT_base보다 살짝 좋거나 살짝 좋지 않은 수준
→ 전반적으로 BERT_base와 유사. GLUE task들은 비교적 외부 지식 정보를 요하지 않음을 확인할 수 있음
- ERNIE, text의 의미적, 어휘적 feature과 knowledge graph의 지식 정보를 융합하여 training data로 썼는데, 그러한 이질적인 information fusion 과정을 거쳤음에도 언어적인 맥락 정보 이해에는 지장이 없었다-.
Conclusion
- 언어 모델에 knowledge graph의 지식 정보를 융합한 ERNIE를 제안한다 !
- knowledgeable aggregator과 새로운 pre-training task dEA의 도입 !
- 지식 기반 task의 경우 + 소규모 데이터셋으로 fine-tune 하는 경우 BERT보다 좋은 성능 !
💡 대규모 코퍼스 + knowledge graphs로 학습시킨 BERT 기반 언어모델 ERNIE를 제안한다 !
- T-Encoder / K-Encoder이라는 새로운 모델 구조 + 새로운 pre-training 방식 + 지식 기반 task에 대한 새로운 fine-tuning 방식 제안
- entity typing / relation classification 등 지식 기반 task에서 발전된 성능을 보였고, 여타 다른 NLP task에 대해서도 BERT 모델의 SOTA에 근접한 성능을 보였음 ( 특히 소규모 데이터셋으로 fine-tune 해야하는 경우 BERT보다 좋은 성능 )
