arxiv: https://arxiv.org/abs/2107.13586
date: 10/03/2022

Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., & Neubig, G. (2021). Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv preprint arXiv:2107.13586.
Abstract
- NLP의 새로운 패러다임 ; prompt-based learning의 제안
- 기존 방식 ( supervised learning )
: 모델이 input x을 받았을 때 output y를 예측하도록 학습 - Prompt-based learning
: 텍스트의 확률을 직접적으로 모델링하도록 학습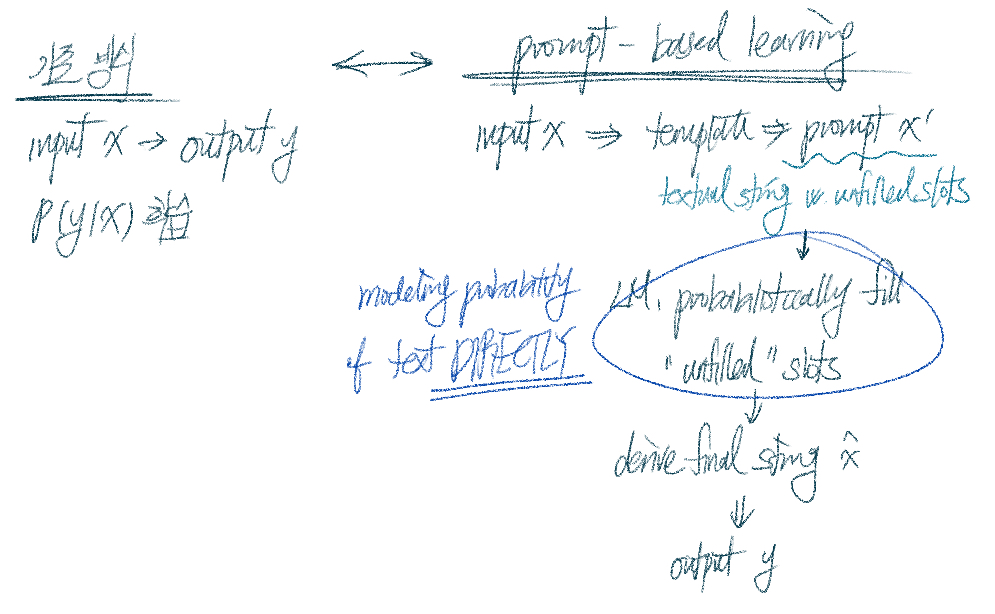
- 기존 방식 ( supervised learning )
- Prompt-based learning의 이점
- 대량의 raw text에 대해 LM pre-train 가능
- Few | no labeled data로 학습 → zero- / few-shot learning에 적합
Two Sea Changes in NLP
-
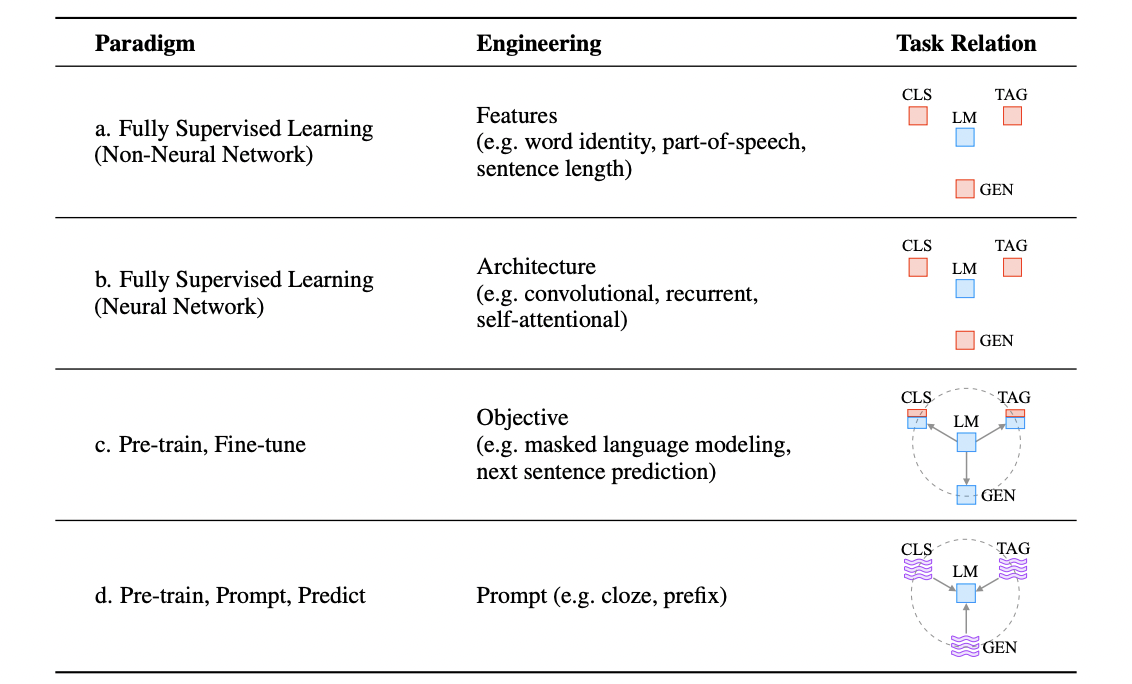
Fully supervised learning
- feature engineering
: raw data에서 주요 feature들을 뽑아내고 이를 모델에 feed하는 방식
→ 연구자의 bias 내재될 수 밖에 + 한정적인 data
- feature engineering
-
Advent of neural network models in NLP
- architecture engineering
: 주요 feature들을 잘 학습할 수 있는 architecture을 구축하는데 중점을 둠
- architecture engineering
-
pre-train and fine-tune paradigm
- objective engineering
: 고정된 architecture의 모델이 언어모델로써 pre-trained, 특정 text data의 확률 계산 ↠ task에 맞게 fine-tune
→ pre-train / fine-tune 단계 모두 특정 objective에 맞게 설계됨
- objective engineering
-
“pre-train, prompt, and predict”
- downstream task, textual prompt를 거치며 재구조화 e.g., 기계번역 task의 경우
-
“ 한국어 : 느리게 숨 쉬어지는 하루 보내기를. 프랑스어 : ____ “ 라는 prompt가 주어지면 언어모델이 빈칸에 알맞은 프랑스어 문장을 채우는 방식으로 학습
e.g., 문맥 활용, 감정표현으로 빈칸 채우는 task의 경우
-
“ 오늘 버스가 만원이었다. “ 라는 문장을 주고 “그래서 ___했다 “ 라는 prompt가 주어지면 언어모델이 빈칸에 알맞은 감정표현을 채우는 방식으로 학습
→ prompt, task 형태를 표방한 일종의 template이라고 보면 됨.
다양한 형태의 template을 적용하면서 학습하면 pre-train 과정에서 이미 다양한 task에 대한 학습이 완료되기 때문에 굳이 따로 fine-tune할 필요가 없는 것. pre-train만으로도 기존의 pre-train + fine-tune process를 마치는 것이라고 이해하면 될 듯.
-
- 해당 방식은 다양한 종류의 prompt로 학습시키는 경우 비지도학습만으로도 downstream task에 대해 좋은 성능을 낼 수 있다는 점에서 주목할 만 함.
→ 그러나 해당 방법은 결국 가장 적절한 형태의 prompt는 무엇인가? 하는 질문과 마주하게 됨 “ prompt engineering “ 이 필수적 !
- downstream task, textual prompt를 거치며 재구조화 e.g., 기계번역 task의 경우
A Formal Description of Prompting
Prompting Basics
- cf. 기존의 supervised learning, 을 학습시키는 방식
- prompt learning, text 의 확률 를 직접 학습 → 해당 확률을 활용, 를 곧바로 예측
- 구체적으로 basic prompting, 세 단계를 거쳐 가장 높은 확률을 보이는 예측
Actual process - sentiment analysis
-
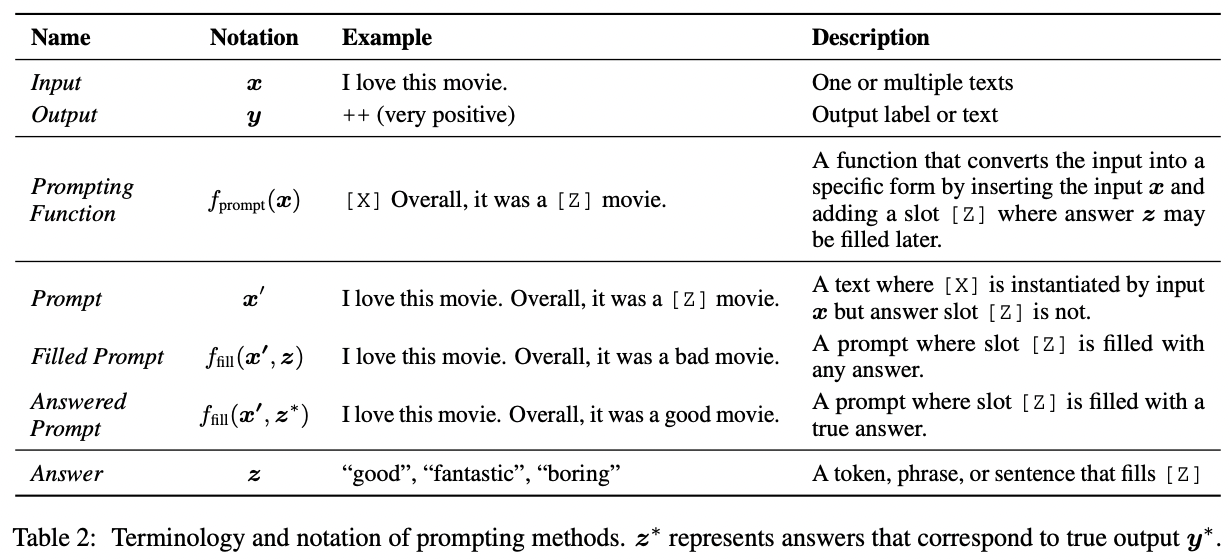
input x → → prompt
- = template 적용하는 것을 의미
cf. template, 두 개의 slot이 있는 text
1. input이 들어갈 자리에 삽입하는 slot [X]
2. 이후 output y에 매핑될 정답 z가 들어갈 slot [Z] - input x = 나 이 영화 좋아해. → = [X] 전반적으로, 그 영화는 [Z]야. → prompt = 나 이 영화 좋아해. 전반적으로, 그 영화는 [Z]야.
- = template 적용하는 것을 의미
-
filled prompt 에서 에 해당하는 단어, 다양한 형태. 정답일수도, 정답이 아닐수도.
-
2 cases
- = [X]에 input x가 채워지고 정답 slot [Z]는 아무렇게나 채워진 경우
(e.g., 나 이 영화 좋아해. 전반적으로, 그 영화는 별로야.) - = [X]에 input x가 채워지고 정답 slot [Z]는 올바르게 채워진 경우
(, 실제 output 에 상응하는 정답 z 의미)
(e.g., 나 이 영화 좋아해. 전반적으로, 그 영화는 최고야.)
- = [X]에 input x가 채워지고 정답 slot [Z]는 아무렇게나 채워진 경우
-
[Z]에 채워질 수 있는 들의 집합 의 원소들 모두에 대해 확률 계산
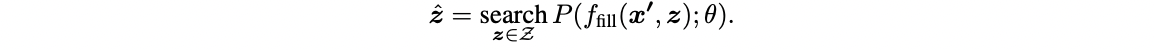
*가장 높은 확률값을 가질 output 찾는 argmax 함수라고 봐도 무방
-
-
정답일 확률이 높은 와 가장 높은 확률을 가지는 매핑
- e.g., = 최고, = ++(very positive)
- 여러 단어가 하나의 동일한 output을 내는 task의 경우(e.g., 기계번역) 이 과정이 필요없으나, 위의 예시로 든 감성분석의 경우 하나의 단어가 하나의 class를 represent하기 때문에 해당 과정이 필요
Design Considerations for Prompting
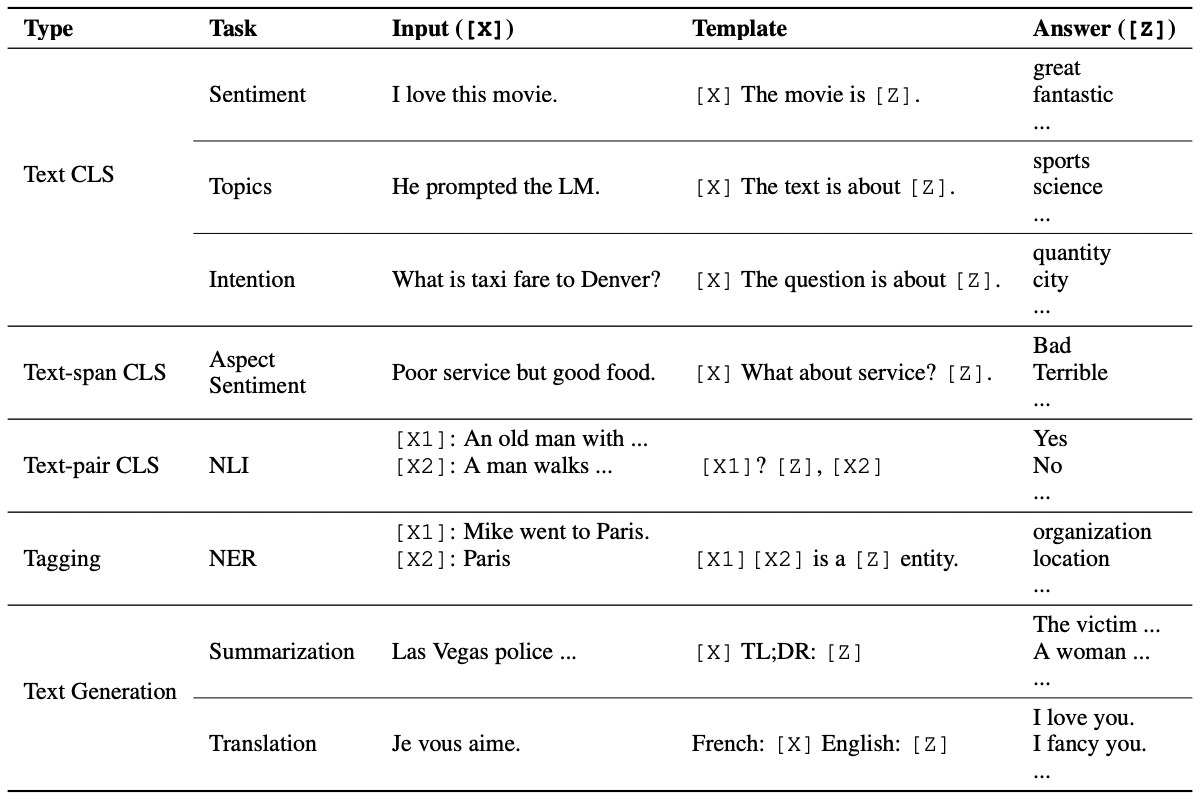
*task에 따라 input, output이 다르고, 이에 맞는 template 또한 다르기 때문에 prompting 설계가 중요
- pre-train model choice
: 다양한 pre-train model 중 backbone으로 어떤 모델을 쓸 것인가? - prompt engineering
: 으로 어떤 prompt를 선택할 것인가? - answer engineering
: [Z]에 채워질 수 있는 들의 집합 를 어떻게 설계할 것인가? + 와 매핑할 함수? - expanding the paradigm
: prompting을 위한 다양한 framework - prompt-based training strategies
: parameter 학습과 연관
→ 다섯개의 요소 중 2번, 3번에 주목해서 정리할 것.
Prompt Engineering
: downstream task에서의 성능을 높이기 위해 어떤 를 선택할 것인가?
- prompt shape
- cloze prompts : 빈칸 채우기 형태
→ masked LM을 사용하는 경우 적합 - prefix prompts : 문장 뒷부분을 잇는 형태
→ 문장 생성을 요하는 task / auto-regressive LM을 backbone으로 활용하는 경우에 적합하다고 알려짐
- cloze prompts : 빈칸 채우기 형태
- two ways of engineering prompts
- manual template engineering : 사람이 직접 생성 → 생성 자체도 어려울 뿐더러 성능 보장 안됨.
= defective ! - automated template learning
- form
- discrete prompts : prompt가 문장형태인 경우
- continuous prompts : LM의 embedding space에 녹아들어간 경우
- state
- static prompts : 모든 input에 대해 동일한 prompt 사용
- dynamic prompts : input에 따라 custom prompt 생성
- form
- manual template engineering : 사람이 직접 생성 → 생성 자체도 어려울 뿐더러 성능 보장 안됨.
Answer Engineering
: 보다 나은 성능을 위해 answer space 집합 를 어떻게 설계할 것인가? + 와 original output 매핑할 함수는 어떻게 설계할 것인가?
-
answer shape
- tokens : pre-trained LM의 단어, 단어의 일부
- span : token들로 이루어진 짧은 어구 ( 주로 cloze prompts와 함께 사용됨 )
- sentence : 문장 / 문서 ( 주로 prefix prompts와 함께 사용됨 )
→ task에 따라 다른 answer shape 채택하는 것이 일반적
- token | text-span = classification tasks ( e.g., 감성분류 , 관계추출, NER 등)
- sentence = language generation tasks ( e.g., 언어 생성 task 등 )
-
two ways of engineering answer space ( answer space & 와 original output 매핑할 함수 구축 )
- manual design
- unconstrained spaces
: answer space 가 모든 토큰 집합인 경우 + 주로 정답 와 original output 를 직접적으로 매핑 ( identity mapping ) - constrained spaces
: answer space 가 제한되는 경우 ( e.g., 텍스트 분류 등 ) + 주로 정답 와 original output 를 class 化하여 매핑
- unconstrained spaces
- discrete answer search = automatic answer search
- discrete answer space
- continuous answer space
- manual design
Conclusion
- prompt-based learning, NLP task에 있어 새로운 패러다임 !
- 기존의 pre-trained LM 형태를 가져가되, prompt라는 새로운 학습방식의 도입으로 fine-tune 과정 없이도 downstream task에 도입 가능
- unsupervised learning method이자, few- / zero-shot learning에도 적합
- 발전 가능성이 무궁무진한 분야이다 ! 연구자들 더 도전적으로 연구해보시길 ~
