arxiv: https://arxiv.org/abs/2005.14165
date: 09/19/2022
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
Abstract
- (논문 저술 시점) 기존에 성능 좋은 NLP 모델,
대규모 corpus로 사전 학습 → task-specific dataset으로 특정 task에 대해 fine-tune - language model의 규모를 키우면 fine-tuning이 필요없어진다 !
= few-shot setting에서 downstream task에 직접 적용 可 - GPT-3, 1750억 개의 파라미터를 가진 autoregressive language model
( 기존 language model보다 10배 이상 많은 파라미터 )
Introduction
Progress of NLP Language Models
- NLP : pre-trained language representation으로의 이행 과정
- word vector로 single-layer representation 학습 → task-specific architecture의 input 化
- RNN 下 multiple layer로 language representation 학습 → 더 나은 representation 학습을 위해 문맥 정보 반영
- Transformer-based model, 대규모 corpus로 pretrained → fine-tune 하는 방식 채택
- pre-trained language representation
-
장점 : task-specific architecture가 필요 없어짐 + 성능의 비약적 발전 이룩
-
한계점 : model 자체는 범용성이 크지만, fine-tune하는 과정에서 task-specific한 dataset 要
→ 해당 한계점을 타개할 필요성
· language model의 활용도 ↓
· fine-tuning을 위한 dataset에 overfit 될 가능성 ↑
· 실제 사람이 언어를 활용하는 방식과 동떨어짐
-
Ideas
- Meta-learning
: unsupervised pre-training → target task 파악 | target task에 맞춰 능력 적용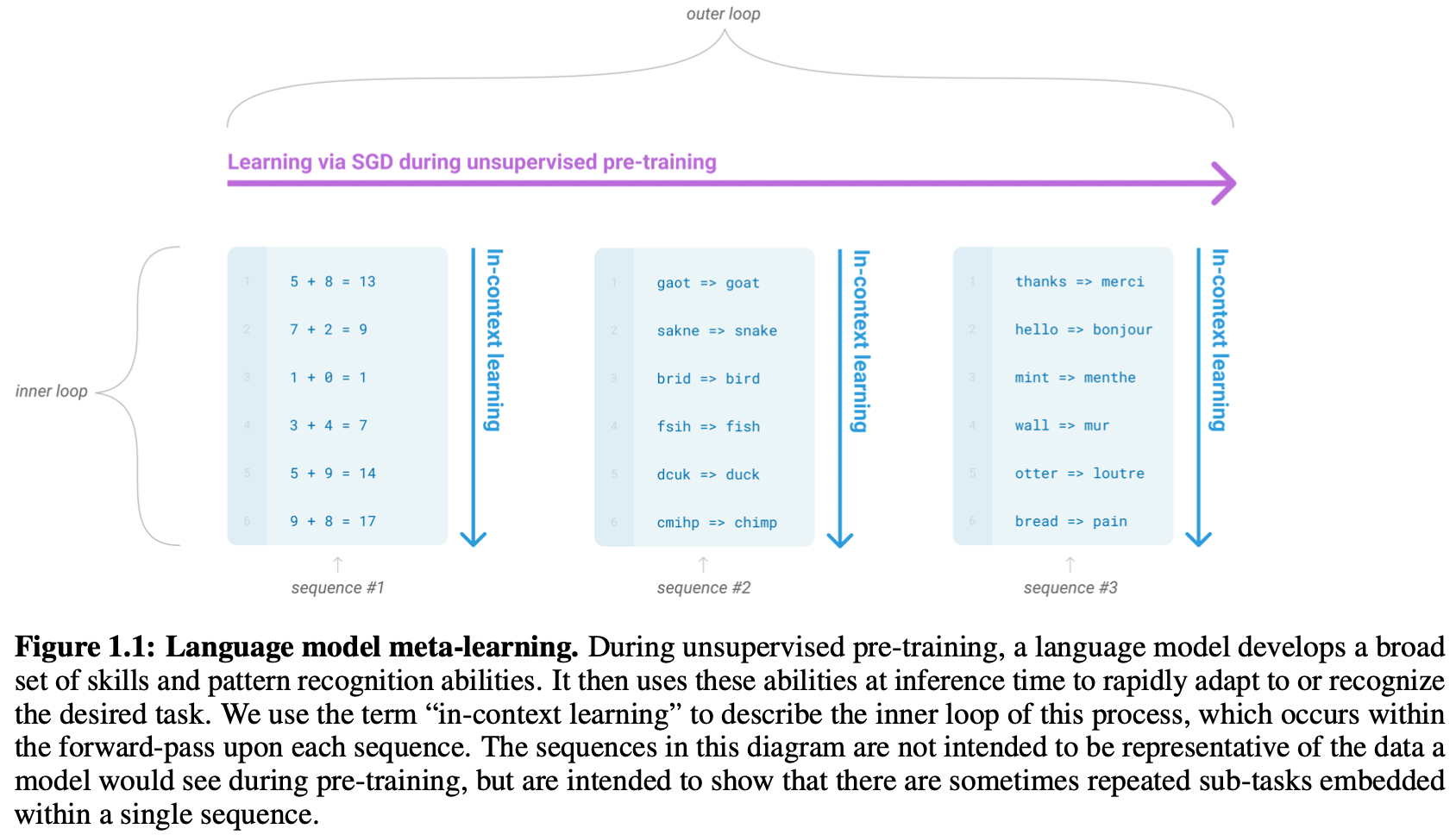
-
Outer loop
: unsupervised training 시 多 skills + 패턴 인지 능력을 익힘 -
Inner loop
: a.k.a. “in-context learning”
pretrained language model의 input을 task specification을 위해 활용→ 자연어로 된 instruction | 소수의 task demonstration만으로도 전체 task 파악 및 수행 可 하다는 이점 O, but fine-tuning 방식보다 성능 ↓. 성능 개선 要.
-
- Model capacity ↑
- Transformer-based models, 파라미터 수 비약적으로 늘리는 추세
( 100 million → 300 million → … → 11 billion → 17 billion ) - 파라미터 수의 증가, downstream NLP tasks에서의 성능 야기하는 경향성
- Transformer-based models, 파라미터 수 비약적으로 늘리는 추세
Hypothesis
Model capacity의 증가는 downstream NLP tasks에서의 성능 향상과 강한 상관관계 有.
따라서 model capacity를 늘리면 meta-learning의 in-context learning 성능도 향상될 것.
→ 본 논문에서 1750억 개의 파라미터를 가진 GPT-3를 통해 해당 가설을 증명해보이겠다 !
Evaluation of GPT-3
- 각 task에 대해, 3가지 조건 下에서 GPT-3의 성능 평가 진행
- few-shot learning
- one-shot learning
- zero-shot learning
- Accuracy curve
( gradient updates + fine-tuning 없이 평가 )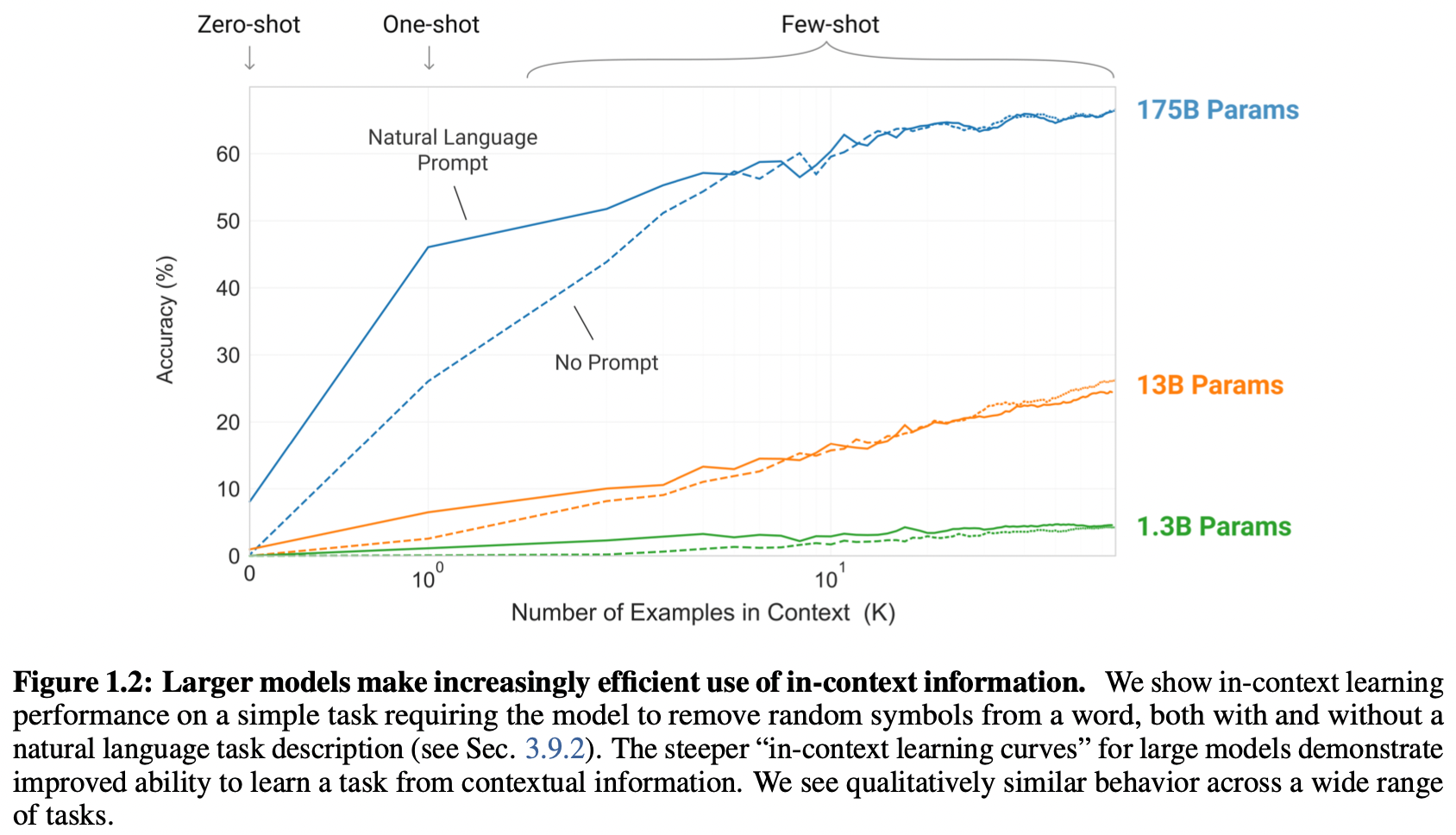
- 시사점
- 모델 규모 ↑ / task description 有 / task demonstration 양 ↑ / 텍스트 전처리 시 특수기호 제거 → accuracy ↑
- 시사점
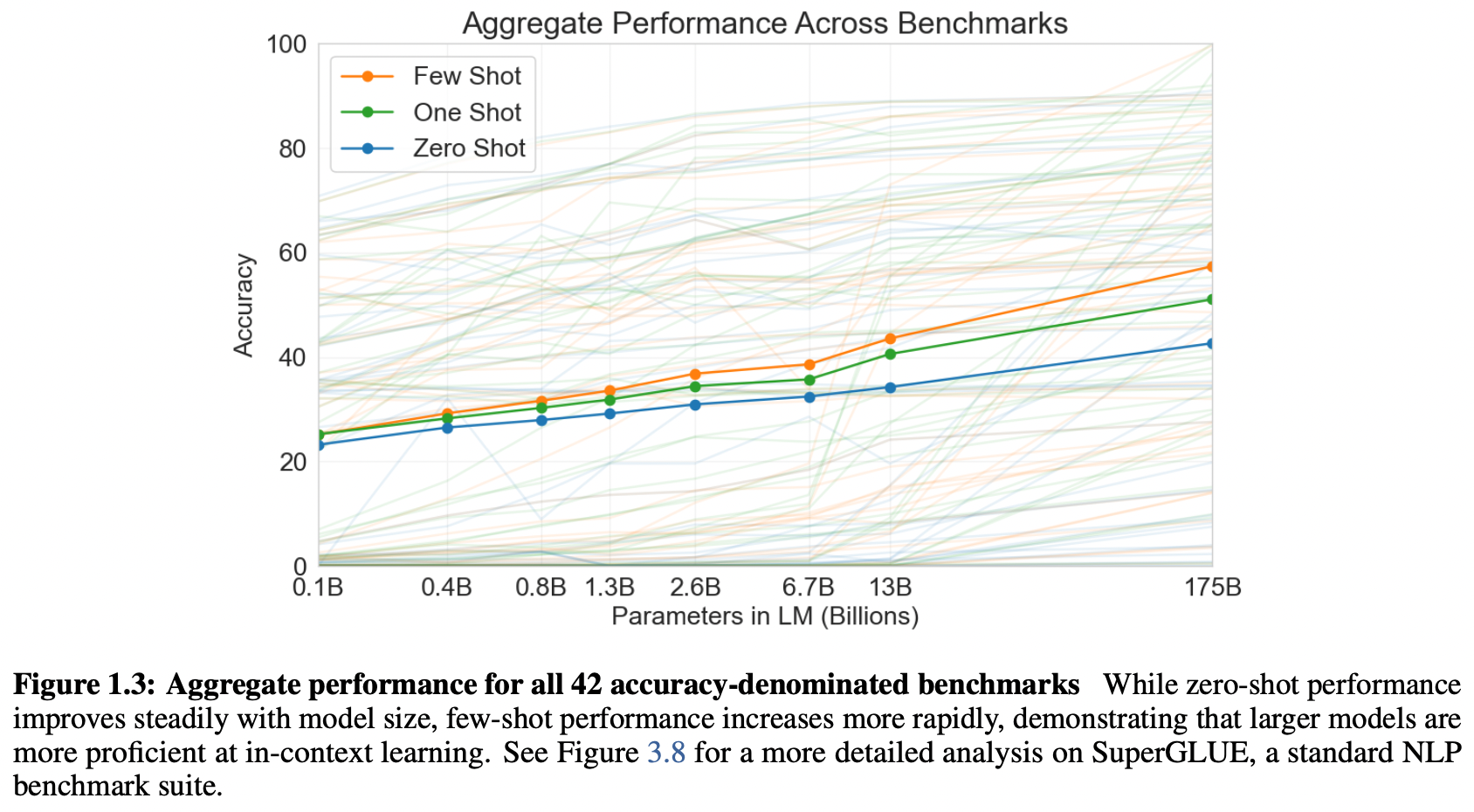
- Evaluation
- GPT-3, zero-shot / one-shot setting에서 나름 괜찮은 성능 + few-shot setting에서는 SOTA에 버금가는 성능을 보임
- 하지만 few-shot setting에서 유독 성능이 떨어지는 task들도 존재
(e.g., natural language inference task : 어떤 가설이 전제에 부합하는지 판단하는 task, reading comprehension task : 독해 task - GPT-3과 비교하기 위해서 파라미터 수가 125 million~13 billion 개 정도 되는 작은 모델들도 학습시켜봤는데, zero shot → one shot → few shot 순으로 성능 향상을 보였지만 향상 폭이 GPT-3보다 작았음. 모델 크기가 클수록 meta-learning에 더 적합하다는 의미 아닐까-.
Approach
Defining methodology

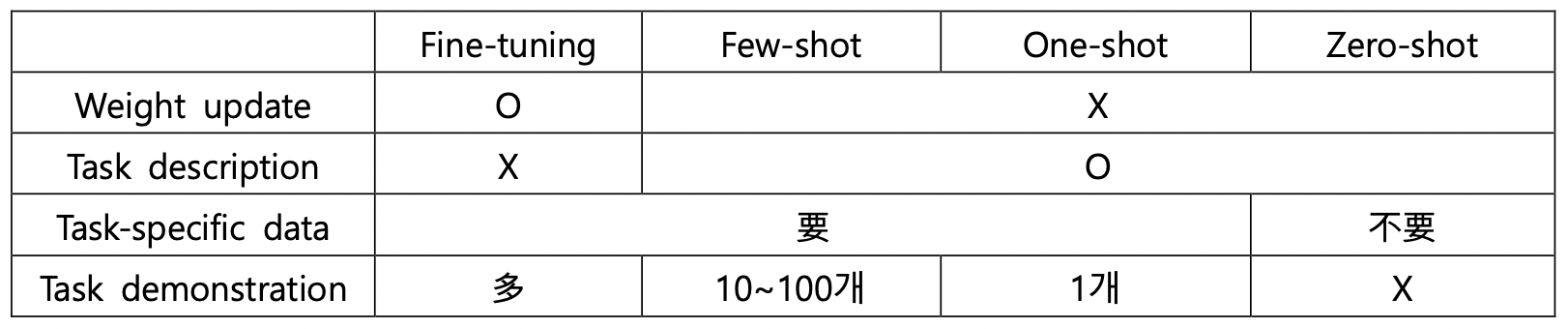
- Fine-tuning
: pre-trained model을 task-specific dataset으로 supervised training하면서 가중치 update- 장점 : fine-tuned 된 task에 대한 성능 좋음
- 단점 : 多 labeled data 要 / fine-tune 위한 data가 bias 되어있을 때 그 bias를 답습할 위험
- Few-shot ( a.k.a. in-context learning )
: 모델의 context window (토큰 너비 = 2048) 에 맞는 task demonstration들이 제공됨 (주로 10개에서 100개). 가중치 update X.task description과 함께 K개의 ( 예시 - 결과값 ) 쌍이 주어지고, 마지막으로 하나의 예시가 주어지면 모델이 그 결과값을 도출해내도록 하는 방식
- 장점 : fine-tuning에 비해 필요한 task-specific data 수가 적음 → narrow dataset의 bias 답습할 확률 ↓
- 단점 : fine-tuned 모델보다 성능이 현저히 떨어짐 + task-specific data가 要
- One-shot
: few-shot과 근본적으로 동일하나 task demonstration이 하나만 주어짐. 현실에서 인간에게 주로 주어지는 자연어 task들과 동일한 조건.task description과 함께 1개의 ( 예시 - 결과값 ) 쌍이 주어지고, 마지막으로 하나의 예시가 주어지면 모델이 그 결과값을 도출해내도록 하는 방식
- Zero-shot
: one-shot과 근본적으로 동일하나 task demonstration이 아예 주어지지 않음. 오로지 task description만 주어짐. 인간에게도 어려울 수 있는, 가장 challenging한 setting.task description만이 주어지고, 하나의 예시가 주어지면 모델이 그 결과값을 도출해내도록 하는 방식
*Fine-tuning vs Few/One/Zero-shot
Model and Architectures / Training Dataset / Training Process
model, data, training 방식 모두 기본적으로 GPT-2와 유사함
그러나 model 규모, data의 규모 및 다양성을 증가시켰고 더 오랜기간 training을 진행했다는 점에서 차별성 有
-
Model and Architectures
- GPT-2의 modified initialization / pre-normalization / reversible tokenization 유지
cf. GPT-2 review - 차별점 : Transformer layer에 “alternating dense and locally banded sparse attention pattern” 사용 ( ≒ Sparse Transformer )
cf. Sparse Transformer, 각각의 출력 중에서 입력들의 일부 subset만 계산하는 sparse attention pattern을 적용
- size and architectures of 8 models
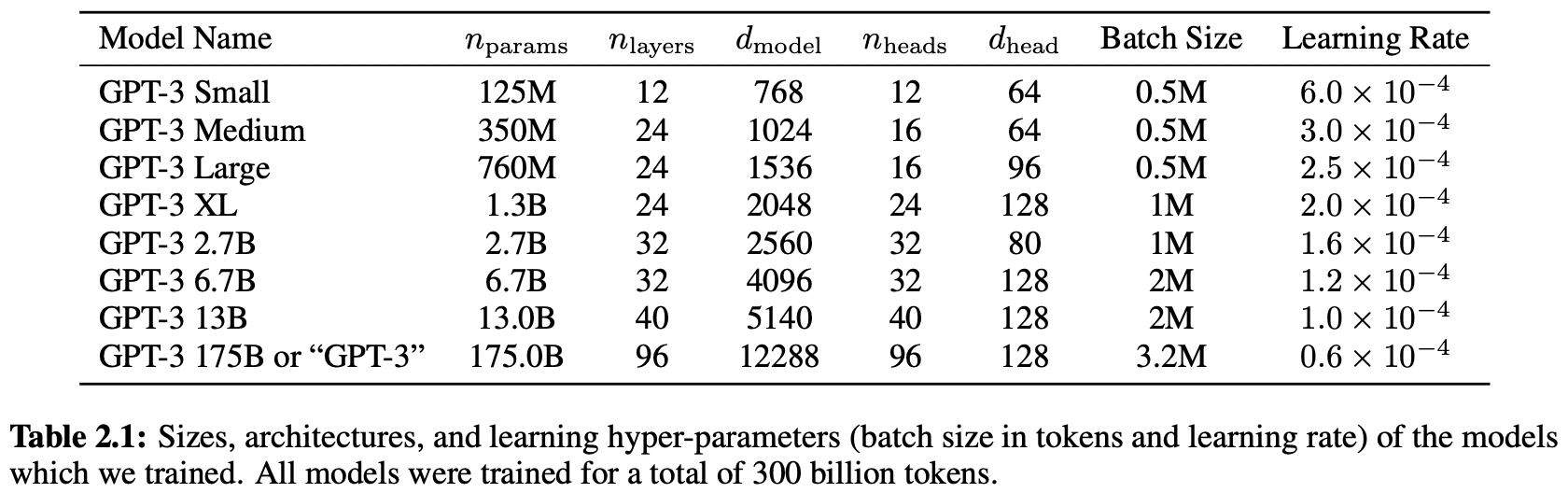
(* = 총 layer 수 , = bottleneck layer의 unit 수 , = 각 attention head의 dimension ) + context window (토큰 너비) = 2048
- GPT-2의 modified initialization / pre-normalization / reversible tokenization 유지
-
Training Dataset
-
pretraining에 사용되는 dataset의 규모 급격히 증가
e.g., Common Crawl dataset, 약 1조 개의 단어로 구성
→ but 제대로 필터링되지 않은 Common Crawl dataset, 퀄리티 ↓ -
Common Crawl dataset의 퀄리티를 높여보자 !
-
Common Crawl dataset filtered ver. 다운로드
-
dataset 내 문서 단위로 중복 제거 ( overfitting 방지 )
-
high-quality reference 코퍼스 추가 ( WebText expanded ver. + 웹크롤링 데이터 + Books1 dataset + Books2 dataset + English-language Wikipedia → 다양성 증대 )
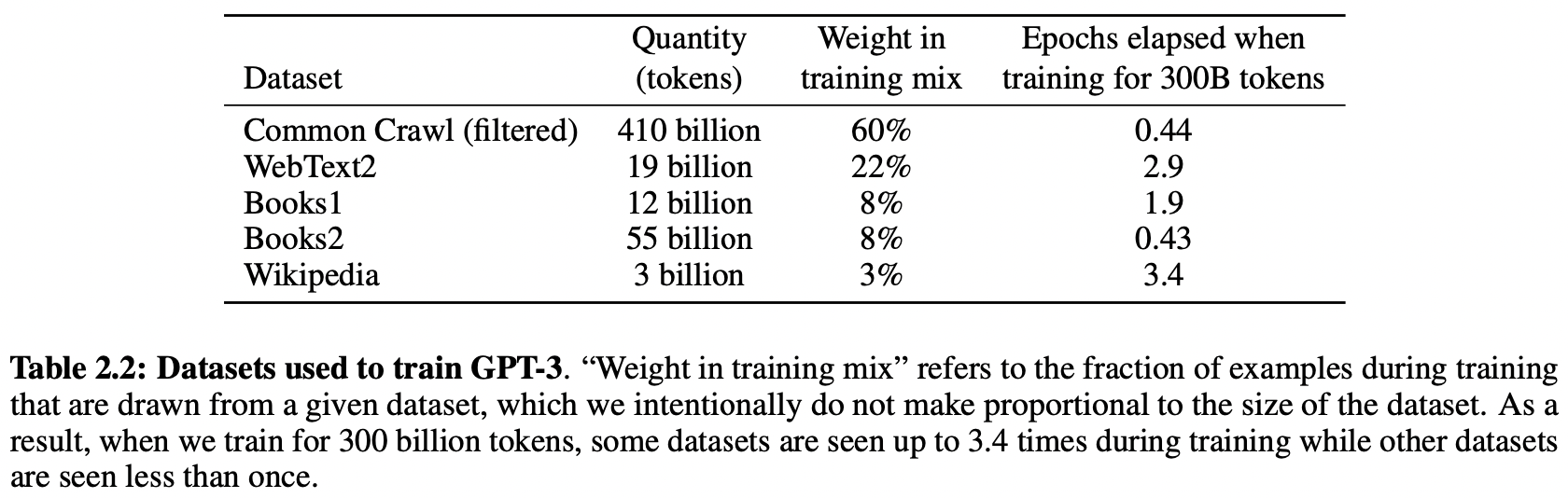
+ contamination 방지를 위해서 dataset 내부의 overlap 전부 제거하고자 했으나 버그로 인해 완벽하게 제거되지 못했음
-
-
-
Training Process
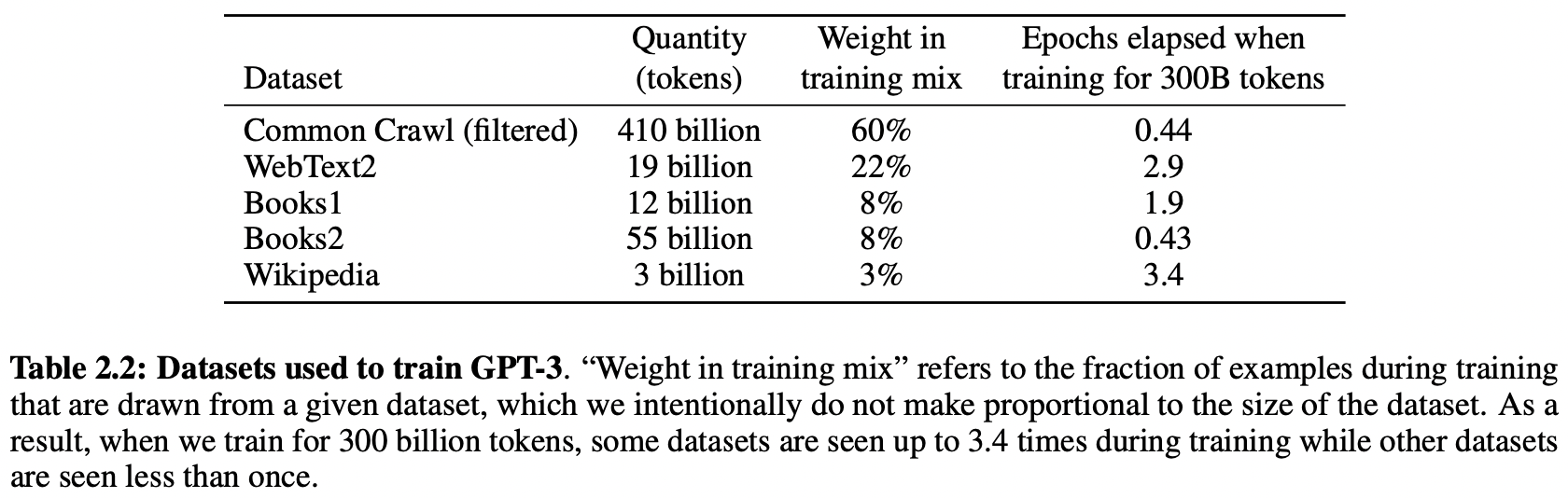
- 규모가 큰 모델은 대체로 더 큰 batch size를 요하지만, lr은 작게 해도 됨
- parameter settings
Results
-
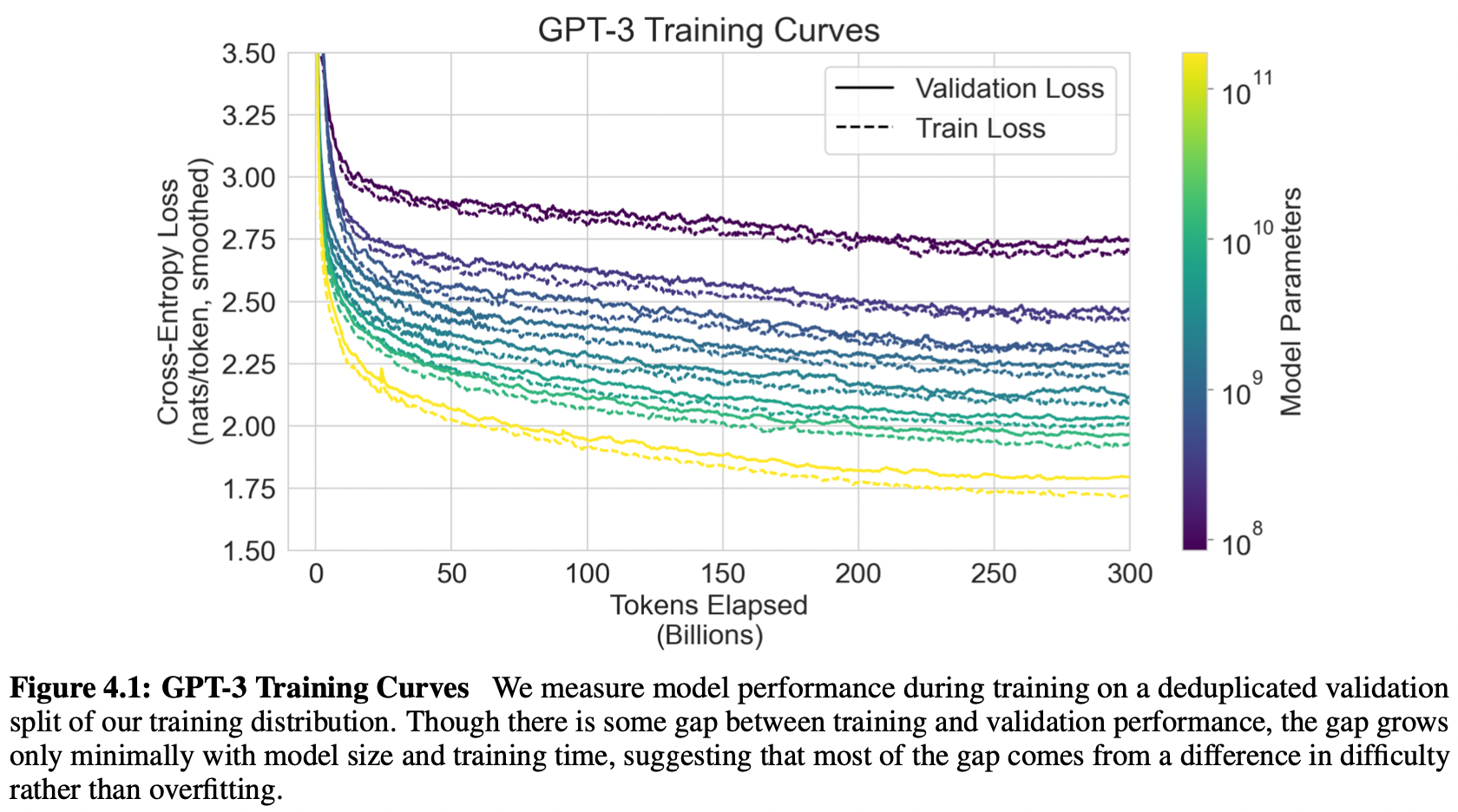
8개 모델에 대한 training curve
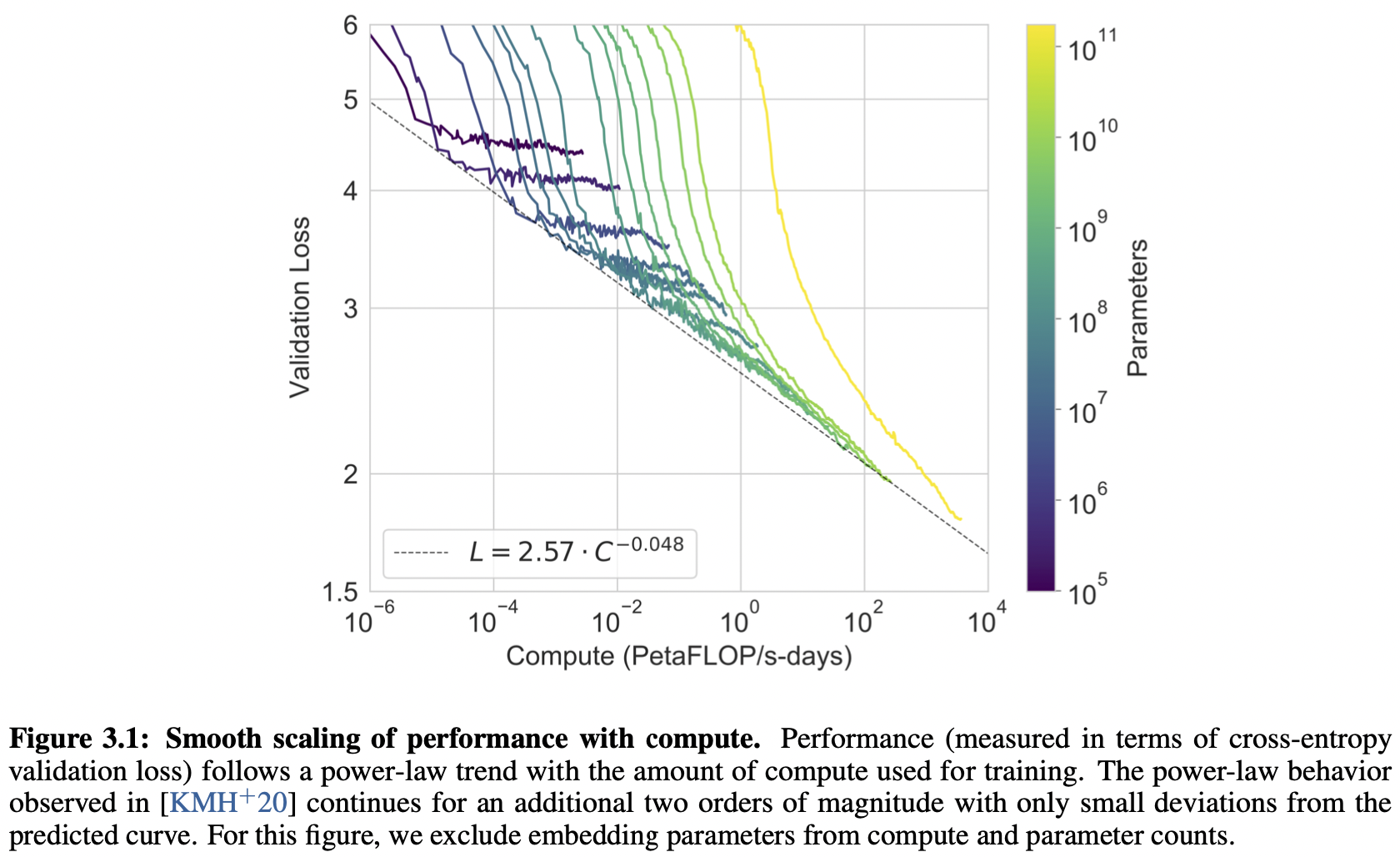
→ amount of compute 가 많을수록 성능 좋음 ! / parameter 많을 수록 성능 좋음 !
cf. total compute used during training
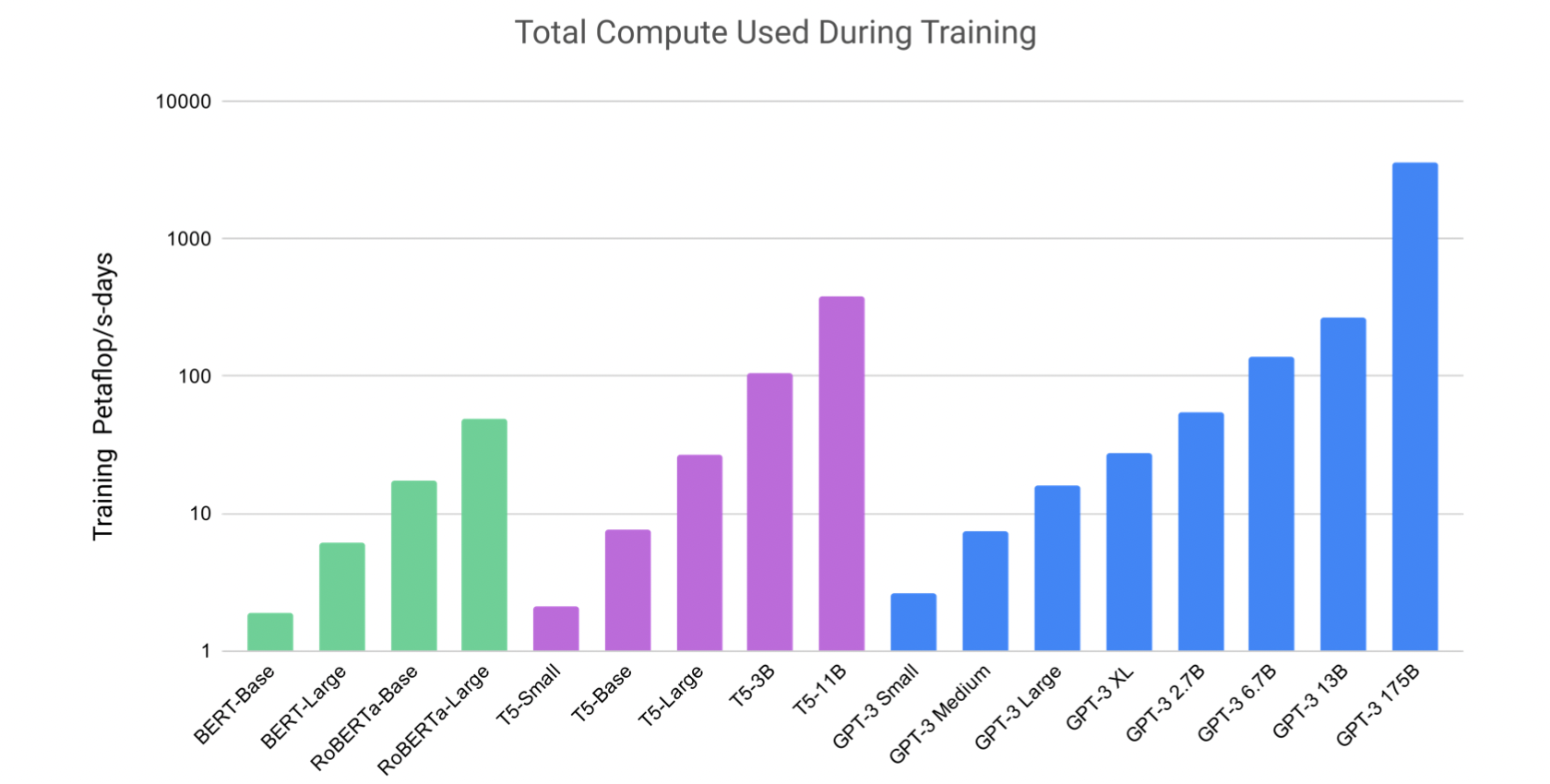
On Downstream Tasks…
-
Language Modeling

- PTB dataset, language modeling 테스트
: GPT-3, zero-shot setting에서 SOTA 달성
- PTB dataset, language modeling 테스트
-
Cloze / Completion Tasks
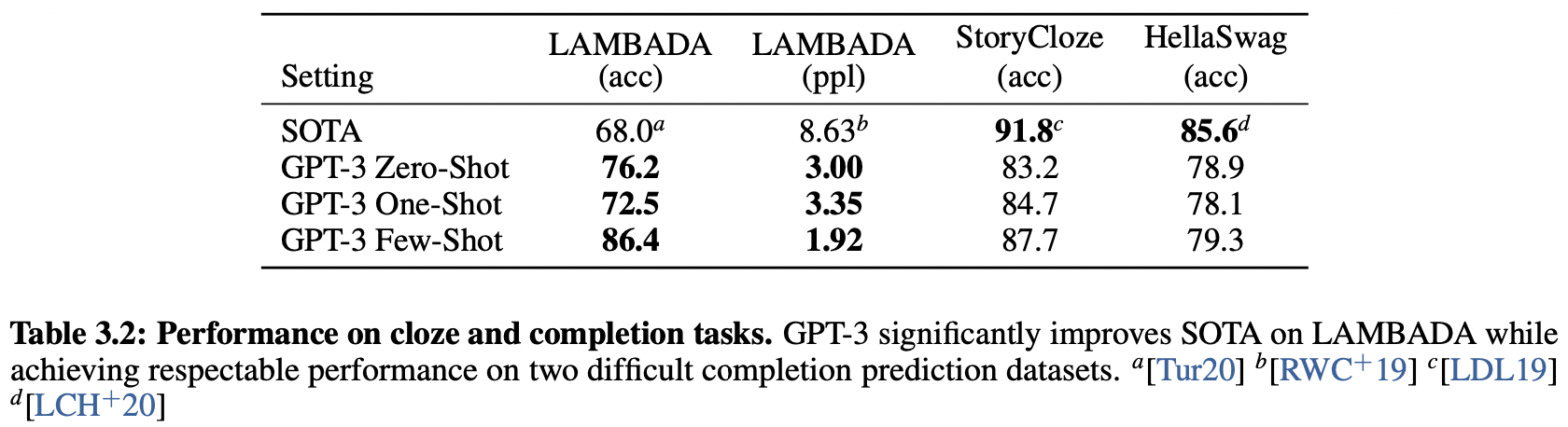
- LAMBADA dataset, long-range dependency 모델링 테스트
( 멀리 떨어져 있는 요소를 잘 예측할 수 있는가? )
: few-shot setting에서 SOTA - StoryCloze / HellaSwag dataset, story의 올바른 ending을 고르는 테스트
: fine-tuned model이 이룩한 SOTA 보다는 못하지만, 나름 준수한 성능
- LAMBADA dataset, long-range dependency 모델링 테스트
-
Question Answering Tasks
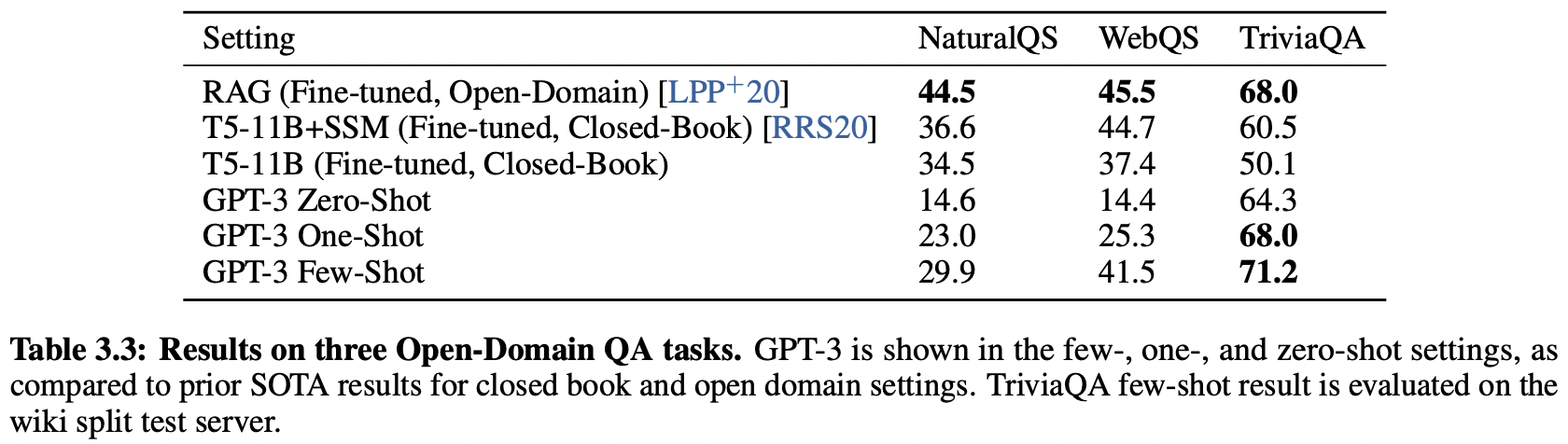
- TriviaQA dataset에 대해 GPT-3의 few-shot setting, SOTA 달성
다른 두 task에 대해서는 closed-book SOTA에 근접
- TriviaQA dataset에 대해 GPT-3의 few-shot setting, SOTA 달성
- 이 외 다른 tasks에 대해서도 zero-shot / one-shot / few-shot setting에서 SOTA 달성 혹은 SOTA 근접한 성능을 보여줌. 특히 text generation에서 준수한 성능을 보여주었는데, GPT-3가 생성한 500자 남짓한 짧은 뉴스 기사의 경우 사람들이 인공지능이 썼다는 것을 알아채기 어려울 정도였다고 함 🫢
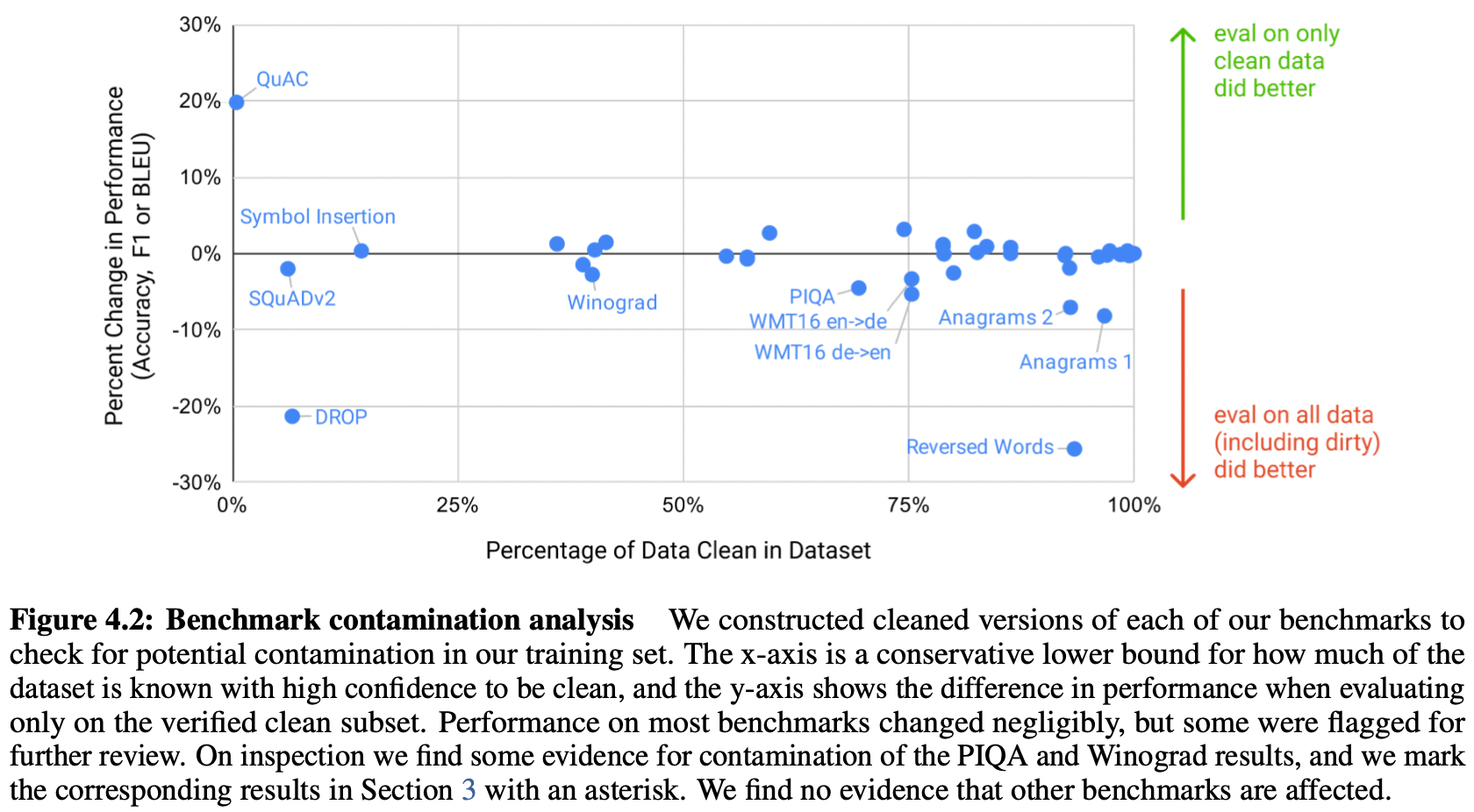
Measuring and Preventing Memorization of Benchmarks
training dataset이 인터넷에서 수집되었기에, model 학습에 쓰인 dataset이 benchmark test set에 쓰였을 가능성 존재 (contamination) → overlapping data 제거할 필요성
- Overlapping data가 성능에 그렇게까지 큰 영향을 미치진 않았음
Limitations
- pretrained model의 근본적 한계
- 현재 대규모 pretrained model,
- 학습 시 모든 token에 동일한 weight 부여
- 모든 task가 prediction에 의존한다는 한계 존재
- real world physical interaction이 부재하기에 현실 반영에 한계가 있음
- sample 효율의 한계
- GPT-3가 pretrained 될 때 쓰이는 학습 데이터, 인간이 평생 보는 텍스트 양보다 많음
→ 학습 데이터가 효율적으로 쓰이는가? 에 대한 의문
- GPT-3가 pretrained 될 때 쓰이는 학습 데이터, 인간이 평생 보는 텍스트 양보다 많음
- 현재 대규모 pretrained model,
- GPT-3의 한계
-
GPT-3, 특정 NLP tasks들에서 명백한 약점을 보임
(e.g., text synthesis task에서 같은 표현을 반복하거나, 자기모순적인 문장을 쓰거나, 전제와 어긋나는 문장을 쓰는 등의 실수를 저지름) -
구조적 문제 / 알고리즘의 문제
: bidirectional architecture의 부재 → bidirectionality가 필요한 task에 대해서는 필연적으로 좋지 못한 성능을 보임 (e.g., fill-in-blank task)
→ zero- / one- / few-shot learning이 가능한 bidirectional architecture 모델을 만들면 보다 비약적인 성능 개선이 가능할 것 같다~ -
모델 활용에의 한계
: 모델 자체가 너무 크기 때문에, 활용 자체가 어렵다는 한계가 존재- 활용한 training dataset에 내재된 bias 반영될 수 밖에 없음
-
- 딥러닝 모델의 고질적 한계 ; blackbox
: GPT-3가 왜 그러한 결과값을 도출했는지, 어떤 과정을 거쳐 그런 결과를 산출한 것인지 알 수 없음
(e.g., GPT-3가 few-shot setting에서 특정 task를 식별할 수 있는 것인지, 아니면 학습한 데이터에서 익힌 task 스타일을 단순히 갖다 쓰는 것인지 확인할 방법이 없음)
Conclusion
- 1750억 개의 파라미터를 가진 GPT-3를 구축했다 !
- zero- / one- / few-shot setting에서 SOTA 달성 or 준수한 성능을 보였다 !
- 규모가 큰 language model, 범용성이 크다는 것을 확인 !
💡 Key Point
- 1750억 개의 파라미터를 가진 pretrained language model GPT-3 구축
- 모델 규모가 커지면 fine-tuning을 하지 않는 meta-learning 방식으로도 downstream task에 대해 준수한 성능을 낼 수 있음을 확인
- NLP에서 zero- / one- / few-shot learning의 potential을 보여준 논문
