
Chen, S., Zeng, Y., Cao, D., & Lu, S. (2022). Video-guided machine translation via dual-level back-translation. Knowledge-Based Systems, 245, 108598.
Abstract
-
Problem Statement
- (논문저술시점) 과거 연구, 보조적인 데이터로 video를 충분히 활용하는데에 초점을 맞춤
→ source language와 target language의 의미적 일관성와 환원 가능성 경시 - visual concept, 서로 다른 언어 간의 alignment와 translation에 도움이 되나 거의 고려되지 않음
- (논문저술시점) 과거 연구, 보조적인 데이터로 video를 충분히 활용하는데에 초점을 맞춤
-
dual-level back translation 방식으로 VMT에 접근해보겠다 !
-
sentence-level back-translation
: 거친 느낌의 의미관계 얻음 -
video concept-level back-translation
: 섬세한 차원의 의미적 일관성-환원 가능성 얻음+ multi-pattern joint learning ; 번역 성능을 높임
-
Introduction
MMT ( Multimodal Machine Translation )
: 번역 시 보조적인 정보로 image / video를 활용
Prior Research
-
IMT의 경우
- static visual content을 제공해주기에 명사 / 형용사 번역 정확도 ↑
- dynamic visual information을 제공해주지 못하기 때문에 다의성을 가지고 있는 동사의 의미적 일관성 개선 어려움
-
VMT의 경우
- 이러한 IMT의 한계점을 타개하기 위해 도래했음
- 기존 방식들과 해당 방식의 한계점은 각각 다음과 같음
- video의 global feature를 사용
↦ video의 불필요한 정보도 활용하게 됨 - text와 video를 연결하기 위해 attention mechanism 사용
↦ action feature을 rough하게 활용
- video의 global feature를 사용
→ 동사 번역에서 dynamic visual concept를 제대로 활용하는 방법에 대한 연구는 아직 미미
-
MMT의 고질적인 문제
: 부수적인 시각정보 추출로 인한 의미적 불일치의 빈번한 발생 ( e.g., 문맥 혼동, 부정확한 단어 선택 )
Key Idea
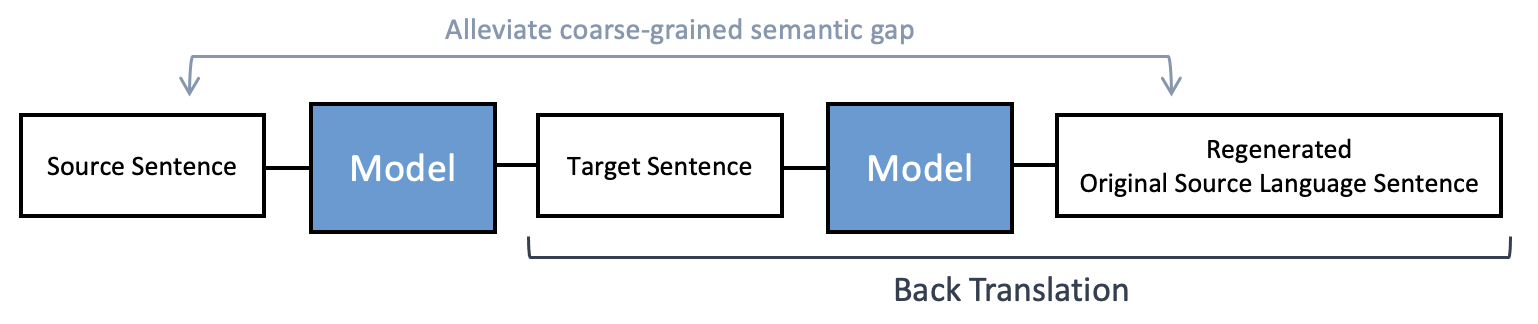
“ 번역에서의 환원 가능성이 의미론적 일관성을 만든다 ! ”
: src → tgt → src의 자연스러운 전환이 가능해야 한다는 것인데,
backtranslation, 언어 간 환원 가능성을 개선함 !
DEAR ( Dual-lEvel bAck-tRanslation )
: multi-pattern joint learning을 통한 dual-level back-translation
-
dual-level back-translation
- sentence-level back-translation
: 의미론적 일관성과 표현 가역성 증진 ( coarse-grained level ) - concept-level back-translation
: concept 일관성 증진 ; src - tgt 이 동일한 concept을 향해있도록 함 ( fine-grained level )
- sentence-level back-translation
-
structure
- 두 모듈, ( sentence feature과 action concept feature 간 co-attention )으로 연결되어 있음
→ modality 융합을 위해 co-attention 활용 - multi-pattern joint learning을 통한 Transformer 공유
→ src - tgt 언어가 공유된 parameter들을 통해 처리됨
- 두 모듈, ( sentence feature과 action concept feature 간 co-attention )으로 연결되어 있음
Our Proposed Framework
: sentence level & concept level back translation 으로 구성 → end-to-end learning으로 강화
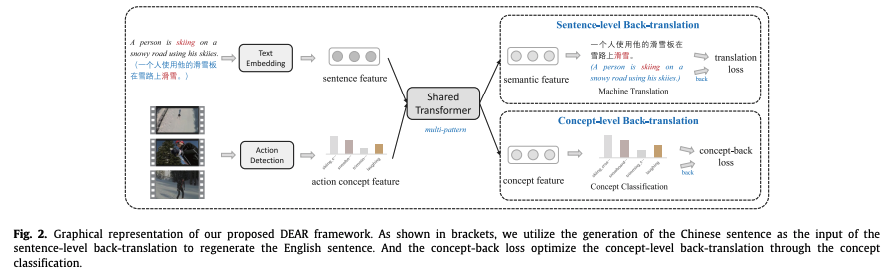
Video-guided Machine Translation ( VMT )
problem formulation
source language 와 이에 상응하는 비디오 가 주어졌을 때 source language와 의미론적으로 가까운 target language 생성
Dual-level back-translation
coarse-grained, fine-grained 의미론적 일관성 포착 위해 dual-level back translation module을 구축
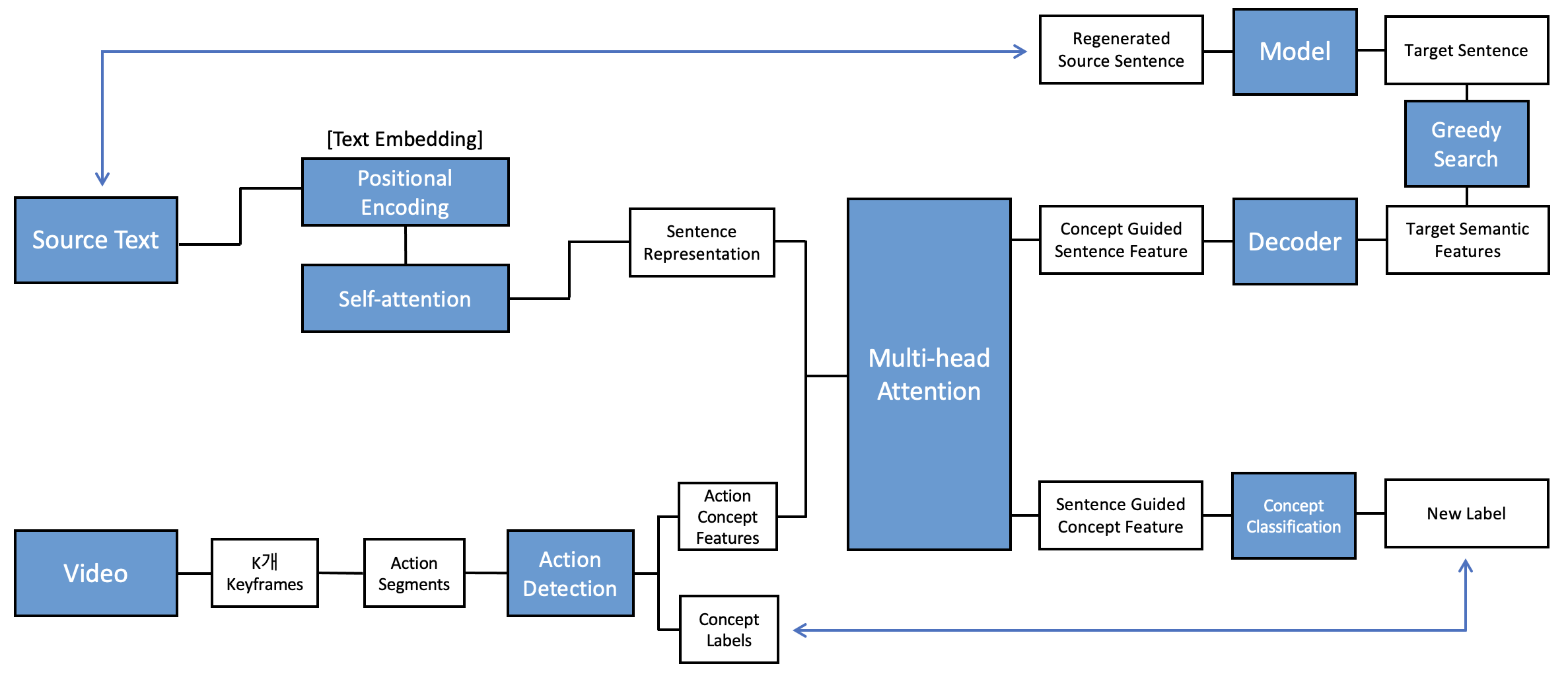
Sentence-level back-translation
-
: source sentence s, encoder들을 거친다 !
: source sentence, positional encoding ( PE ) + N개의 self-attention module ( SA^i ) 거쳐 text embedding = source sentence representation 화
-
: concept-guided sentence feature 얻기 위해 Multi-head attention module 도입
( = i번째 attention layer의 학습가능한 representation matrices / = layer-specific trainable parameter matrice / = scaling factor )
-
target semantic feature ( ) 을 얻기 위해 Transformer decoder 가 쓰인다 !
: 를 기반으로 target sentence = synthetic source sentence 도출
-
: 가 모델을 거쳐 (regenerated) original source language sentence 도출
→ 결국 Sentence-level back-translation의 training objective, translation과 back-translation 모두를 포괄하는
( P = 확률 , Θ = 모델 파라미터 , = tradeoff 파라미터 )
Concept-level back-translation

concept는 fine-grained 의미론적 일관성 차원에서 중요
; 단순히 concept 사용하는데에서 그치지 않고, label까지 재생성해보겠다 !
-
input video에서 k개의 keyframe을 얻고, 하나의 keyframe에 대해 이어지는 32개의 frame을 새로운 action segment로 re-encode
→ 결과적으로 k개의 action concept feature 과 k개의 concept label 을 얻게 됨 -
: sentence-guided concept feature 얻기 위해 Multi-head attention module 도입
( = i번째 attention layer의 학습가능한 representation matrices / = layer-specific trainable parameter matrice / = scaling factor ) -
위의 multi-head attention과 해당 multi-head attention이 co-attention strategy로 활용
→ 문장과 action concepts 융합하는 역할
결국 concept-level back-translation의 목적은 source sentence와 target sentence가 동일한 action concept을 향하게 하는 것
: concept classification layer에 sentence-guided concept feature을 feed해 predicted action concept 도출 ( , types of language ; source language / target language )
→ 결국 Concept-level back-translation의 training objective,
( i, i 번째 concept label index )
action detection 결과로 도출된 k개의 concept label과 reconstruct된 concept category 간 concept-back loss 줄이는 방식
Multi-pattern joint learning
Background
- 기계번역에 있어, 다양한 패턴의 학습 방식은 각기 다른 이점이 있음
( e.g., source-to-source : 언어의 정확도 학습 가능 / source-to-target & back-translation : 문맥의 일관성 + 언어 환원성 탐구 가능 )
→ 다양한 패턴을 결합하면 의미론적 일관성을 보다 잘 학습할 수 있음
- parameter sharing
: 언어 간 상호연관성 증진
Multi-pattern joint learning
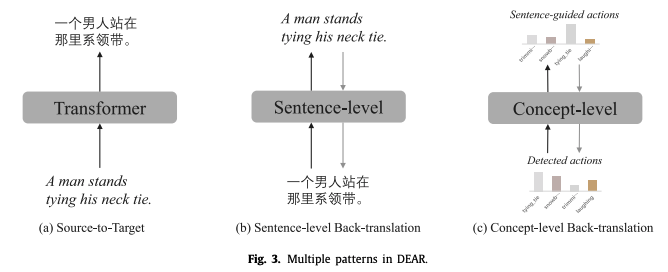
shared Transformer로 multi-pattern을 학습한다 !
→ 언어 간 상호 연관과 의미론적 일관성 포착 위함
-
multi-language learning
: source-to-target & target-to-source 모두 shared Transformer의 동일한 parameter Θ 공유
→ input language에서의 제약 ↓ -
translation & back-translation
: 위와 동일하게 모두 shared Transformer의 동일한 parameter Θ 공유
“ Shared Transformer로 multi-pattern에 대한 joint learning을 가능케 함 “
: coarse-grained sentence-level back-translation과 fine-grained concept-level back-translation이 자연스럽게 결합되어 학습됨
Training Objective
[ ( = translation, = back-translation ) , = source language’s parameter in the concept-level back-translation , = target language’s parameter in the concept-level back-translation ]
Overall Process
Experimental settings
Results
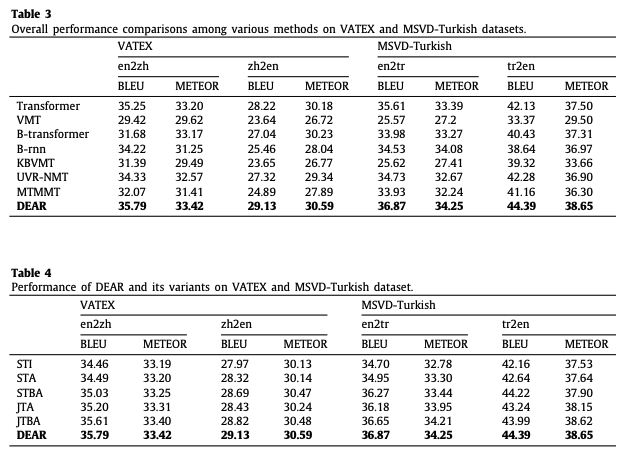
- 논문 저술 당시 SOTA !
Conclusion
- dual-level back-translation을 도입한 VMT 모델 제안
- coarse-grained 의미적 일관성을 위해 sentence-level back-translation 도입
- fine-grained 의미적 일관성을 위해 concept-level back-translation 시 dynamic visual concept (video feature) + action label 활용됨
- multi-pattern joint learning 도입 → multi-pattern과 multi-granularity가 동시에 강화됨
