[Paper Review] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
BART는 Bidirectional Auto-Regressive Transformer를 의미하는 약어입니다. Transformer를 활용해 문장 토큰들을 Bidirectional Encoding하는 BERT와 Auto-Regressive하게 Decoding하는 Generative 모델인 GPT를 합친 모델입니다. 많은 Sota 모델이 Encoder와 Decoder 하나만을 이용한 아키텍쳐였던 것에 반해 BART는 encoder와 decoder 모두를 활용하였습니다. 특히 Transformer의 Encoder-decoder 구조와 같지만, 여러 pre-training task를 적용하고 비교해봄으로써 pre-training의 중요성을 강조했습니다.
사전학습을 어떻게 수행하는지에 따라 모델의 성능에 큰 차이를 비교해서 잘 설명한 논문입니다.
1. Introduction
Self-supervised method는 NLP task에서 괄목할만한 성과를 보여주었다. 특히 랜덤으로 문장 내 토큰 집합을 마스킹하고 복원하도록 훈련하는 denoising autoencoder 방식인 Masked LM이 가장 성공적인 접근 방식이다. 그래서 BERT이후 마스킹을 하는 방법에 대한 여러 연구가 있었다. 하지만, 이런 방식들은 전형적으로 특정 task(span prediction, generation, etc)에만 집중되었고, 다른 task에의 적용이 제한되었다.
BART는 Bidirectional과 Auto-Regressive Transformer를 합친 모델이다. Seq-to-seq 모델로 만들어진 denoising autoencoder이고, 광범위한 task에 적용이 가능하다. 사전학습은 두 단계로 진행이 되는데,
- 텍스트를 임의적인 함수를 통해 손상시키고,
- Seq-to-seq 모델이 원래의 텍스트를 복원하도록 학습한다. BART는 표준 Transformer기반의 기계번역 구조를 사용했는데 BERT와 GPT 그리고 최근의 여러 사전훈련 기법들을 일반화했다고 볼 수 있다.
BART의 핵심 장점은 텍스트 길이의 변화 등 임의의 변형을 원본 텍스트에 적용할 수 있는, noising 유연성이다. 본 논문에서 여러 noising 방식을 실험하고 평가했는데, 원본 문장의 토큰 순서를 랜덤하게 섞고 문장의 임의의 길이를 하나의 마스크 토큰으로 대체하고 채우는 새로운 방식이 가장 좋은 성능을 보여주는 것을 발견했다. 이런 접근법은 BERT의 원래 단어를 마스킹하고 다음 문장 예측 objective를 일반화한 것으로, 모델이 전체 문장 길이에 대해 더 많이 추론하도록 하고 더 긴 범위의 변형(복원)을 하도록 한다.
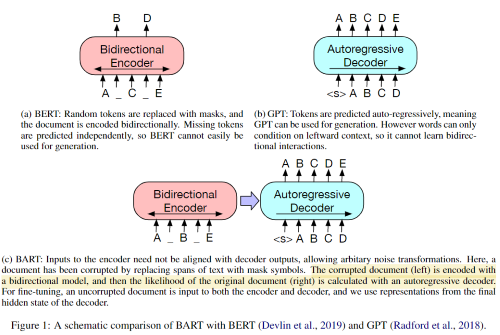
BART는 fine-tuning했을 때, text generation에 효과적이었고 comprehension task에서도 잘 작동했다. GLUE, SQuAD에서 RoBERTa와 비슷한 성능을 보여주었고, abstracitve dialogue, question answering, summarization task에서 Sota를 달성했다.
또한, BART는 fine-tuning에 대해 새로운 방식을 제시했다. BART 모델에 단지 몇개의 추가적인 transformer 레이어를 쌓는 방식의 기계 번역의 새로운 방법을 제시했다. 추가한 레이어는 BART의 전파에 의해 외국어가 noised된 영어로 번역되도록 학습되고, BART는 target-side의 사전 학습된 언어모델로 사용한다.(실험에서 좋은 성능)
BART의 이러한 효과를 이해하기 위해, 최근에 제안된 학습 objectives를 가져와 ablation 실험을 수행했다. 이 결과는 data, optimization parameters를 포함한 다양한 요소들을 신중하게 컨트롤할 수 있도록 해준다. BART는 우리가 고려하는 다양한 범위의 task에서 일관되게 좋은 성능을 보여주고 있었다.
2. Model
BART는 손상된 문서를 원래의 문서로 복원하는 denoising autoencoder이다. 손상된 텍스트를 받는 Bidirectional encoder와 left-to-right의 autoregressive decoder로 구성된 seq-to-seq 구조이다. 사전학습을 위해 negative log likelihood을 최적화하였다.
2.1 Architecture
BART는 표준 seq-to-seq Transformer 아키텍처를 사용하는데, 기존 GPT에서와 다르게 ReLU를 GeLUs로 바꾸고 parameters를 로 초기화했다. BART base 모델에서는 6개의 encoder-decoder를, large 모델에서는 12개의 encoder-decoder를 사용했다. 이 아키텍처는 BERT와 상당히 비슷하지만 2가지의 차이가 있는데,
- decoder의 각 레이어가 추가적으로 encoder의 최종 레이어와 cross-attention을 수행하고(Transformer seq-to-seq 모델과 동일)
- 최종 단어 예측 전에 FFN을 추가하는 BERT와 다르게 BART는 그렇지 않다(decoder가 존재).
BART는 BERT보다 10% 더 많은 parameters를 가지게 된다(cross-attention layer에 의해).
2.2 Pre-training BART
BART는 문서를 손상시키고 decoder가 원래의 문장으로 복원하도록 하며, cross-entropy loss를 최적화하도록 학습한다. 기존에는 특정한 방식으로 노이징된 방식의 denoising autoencoder를 사용한 것과는 달리, BART는 문서를 손상시키는데 어떤 방식이던 적용할 수 있다. 극단적으로 원본 소스가 없는 상황에서, BART는 언어모델과 동일하게 작동한다.
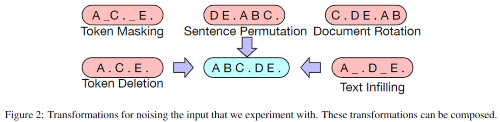
저자들은 이전에 제안된 방법 및 새로운 여러 변형과 함께 실험했고, 다른 새로운 변형 기법을 개발하는 것이 (모델의 발전에) 상당한 가능성이 있을 것이라 한다. 다음은 실험에 사용된 변형들이다.
- Token Masking (BERT)
: BERT에서와 같이 랜덤하게 추출한 토큰을 MASK로 바꾸고 이를 복원하는 기법 - Token Deletion
: 랜덤하게 추출한 토큰을 제거한다. 단순히 마스킹을 하는 것과는 다르게, 모델은 삭제된 곳의 위치도 예측해야 한다. - Text Infilling (Span BERT로부터 영감)
: 텍스트로부터 포아송 분포를 따르는() 길이의 span 몇개를 샘플링하고, 각각의 span을 MASK 토큰으로 대체한다. 길이가 0인 span도 MASK 토큰으로 바꾼다. 텍스트 채우기를 하면서 모델이 없어진 토큰의 수를 예측하도록 가르친다. - Sentence Permutation(XLNet으로부터 영감)
: 문서는 마침표를 기준으로 나뉘고, 분리된 문장들은 랜덤한 순서로 섞는다. 이후 모델은 원래의 순서대로 복원해야 한다. - Document Rotation
: 동일한 확률을 가지는 토큰 하나를 랜덤하게 선택하고, 이후 해당 토큰을 시작으로 하고 문서를 섞는다. 이것은 모델이 문서의 시작지점을 찾도록 학습시킨다.
3. Fine-tuning BART
BART에 의해 생성되는 representation은 여러 다운스트림 어플리케이션에 적용될 수 있다.
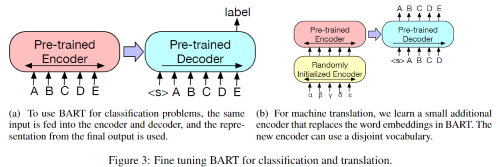
3.1 Sequence Classification Tasks
Sequence 분류 task에서는 동일한 문장을 encoder와 decoder에 넣어주고, 이후 마지막 decoder 토큰의 마지막 hidden state를 새로운 multi-class 선형분류기에 던져준다. BERT의 CLS와 비슷하지만, 본 논문에선 문장 끝에 추가적으로 토큰을 추가하여 decoder의 토큰 representation이 전체 입력된 decoder states를 attend할 수 있게 한다.(마지막 output이 모든 입력을 반영)
3.2 Token Classification Tasks
SQuAD와 같이 문장 내 정답의 endpoint를 찾아야 하는 token classification task을 위해 본 논문에선 완전한 모든 문서를 encoder와 decoder에 주고, 이후 decoder의 가장 위에 있는 hidden state를 각 단어의 representation으로 사용했다. 이 representation은 토큰을 분류하는데 사용된다.
3.3 Sequence Generation Tasks
BART는 autoregressive decoder를 가지고 있기 때문에, abstractive question answering and summarization과 같은 generation task를 바로 fine-tuning할 수 있다. 이러한 task들은 입력 sequence가 복사되거나 조작될 수 있는데, 이는 denoising pre-training objective와 밀접한 연관이 있다. Encoder 입력은 입력 sequence이고, decoder는 autoregressively 출력 sequence를 생성한다.
3.4 Machine Translation
이전의 연구는 사전학습된 encoder를 합쳐서 모델의 성능을 향상시킬 수 있었지만, 사전학습된 언어모델의 decoder로부터의 이점은 제한되었다고 알려졌다. 본 연구에서는 bitext로부터 학습된 새로운 encoder parameters를 추가함으로써, BART 모델을 기계번역을 위한 하나의 사전학습된 decoder로 사용할 수 있음을 보여주었다(BART의 encoder-decoder 전체).
자세히 설명하면, BART의 encoder embedding layer를 랜덤하게 초기화된 새로운 encoder로 바꾼다. 모델은 end-to-end로 학습되는데, 이 새로운 encoder는 BART가 영어(사전학습된 언어)를 de-noising할 수 있도록 외국어를 noising된 영어로 매핑하도록 학습된다. 그렇기 때문에 새로운 encodere에는 BART를 학습시킨 원래의 vocabulary를 사용하지 않아도 된다.
Source encoder는 BART 모델의 output으로부터 cross-entropy loss 역전파 방식으로 두 단계를 거쳐 학습된다.
- BART parameters의 대부분을 freeze하고 랜덤하게 초기화된 source encoder, BART positional embeddings 그리고 self-attention input projection matrix of BART's encoder first layer만 학습시킨다.
- Transformer의 encoder에서 self-attention을 위한 attention matrix
- 모델의 모든 parameters를 작은 iteration으로 학습시킨다.
4. Comparing Pre-training Objectives
BART는 이전 연구보다 더 폭넓은 noising 방법들을 지원한다. base 모델로 여러 noising 옵션에 따라 실험을 수행하고 비교했다.(6 encoder, 6 decoder, hidden size of 768)
4.1 Comparison Objectives
사전학습에는 여러 objectives가 있지만, 학습데이터, 학습 리소스, 모델별 구조적 차이, fine-tuning 절차 등의 차이 때문에 동등한 선상에서의 비교는 힘들다. 저자들은 최근에 제안된 강력한 사전 학습 방법을 통해 discriminative와 generation task에 맞게 모델을 재수행(재구현)했다. 다만, 성능의 향상을 위해 학습률과 layer normalisation을 사용했습니다. 참고로 BERT에서와 동일한 방법에 따라 실험을 진행했다.
Language Model
GPT와 같은 방식으로 left-to-right Transformer 언어모델이다. 해당 모델은 BART의 decoder와 비슷하지만, cross-attention이 없다.
Permuted Language Model
XLNet 기반의 모델로, 토큰의 1/6을 샘플링하고 이를 랜덤한 순서로 autoregressively 생성한다. 다른 모델과의 일관성을 위해 XLNet의 relative positional embeddings와 attention across segments은 사용하지 않았다.
Masked Language Model
BERT와 같이, 토큰의 15%를 MASK 토큰으로 바꾸고 모델이 원래의 토큰을 독립적으로 예측하도록 한다.
Multitask Masked Language Model
UniLM과 같이, Masked LM을 추가적인 self-attention mask와 함께 학습하도록 한다. Self-attention mask는 1/6 left-to-right, 1/6 right-to-left, 1/3 unmasked 그리고 1/3의 처음 50% 토큰은 unmask, 나머지는 left-to-right mask와 같은 비율로 랜덤하게 선택된다.
Masked Seq-to-Seq
Mass에 의한 아이디어인데, 토큰의 50%를 포함하는 span을 마스크하고 seq-to-seq 모델로 마스킹된 토큰을 예측하도록 학습한다.
Permuted LM, Masked LM, Multitask Masked LM 모두 sequence의 출력 likelihood를 효율적으로 계산하기 위해 two-stream attention을 사용했다. 다음과 같은 방식들로 실험했는데, 실험으로부터 첫번째 방식이 BART 모델에 더 잘 작동하고, 두번째 방식은 다른 모델에 더 잘 작동하고 있었다.
- task를 일반적인 seq-to-seq 문제로 다루고 source를 encoder 입력으로 넣고 target은 decoder의 출력이 된다.
- source를 target의 prefix로 decoder에 더하고, sequence의 target 부분만 loss를 구한다.
모델이 fine-tuning objective를 모델링하는 능력을 직접적으로 비교하기 위해 perplexity를 구해보았다.(후에 실험 결과)
4.2 Tasks
SQuAD
Wikipedia 문단에 대한 extractive question answering task이다. 모델이 정답부분의 시작과 끝부분을 예측하기 위해 classifier를 추가했다.
MNLI
하나의 문장이 다른 문장을 수반하는지, 두 문장의 관계가 적절한지 예측하는 bitext classification task이다. 두개의 문장을 EOS 토큰을 추가해 합치고, BERT와는 다르게 EOS 토큰이 문장 관계를 분류하는데 사용된다.
ELI5
긴 형식의 abstractive question anwering 데이터셋이다. 모델은 question과 추가적인 문서를 합친 상태로 answer를 생성한다.
XSum
뉴스 요약 데이터셋으로 abstractive한 요약들이다.
ConvAI2
context와 persona를 기반으로 대화 답변 생성 task이다.
CNN/DM
뉴스 요약 데이터셋이다. 요약들은 source 문장들과 밀접하게 연관되어 있다.
4.3 Results
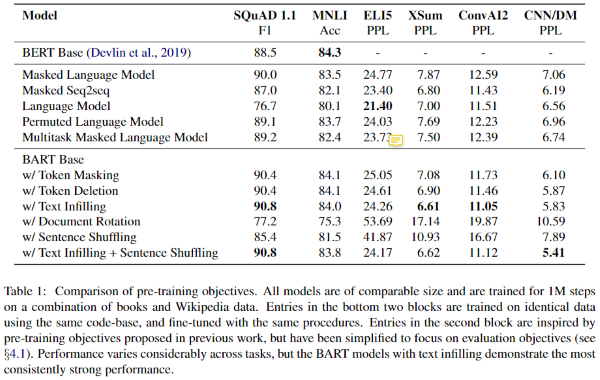
Performance of pre-training methods varies significantly across tasks
사전학습 방법들의 효과는 task에 크게 의존한다(task별로 사전학습의 효과가 다름). 예를 들어, 간단한 LM은 ELI5에서 가장 좋은 성능을 달성했지만 SQuAD 결과는 제일 좋지 않았다.
Token masking is crucial
Rotating documents나 permuting sentence 기반의 사전학습은 독립적으로 보았을 때 성능이 좋지 않았다. 성공적인 방법들은 token deletion, masking 또는 self-attention masks를 사용하는 방법이었다. Deletion은 생성 task에서 masking보다 더 좋은 성능을 보여주었다.
Left-to-right pre-training improves generation
Masked LM과 Permuted LM은 생성 task에서 다른 모델에 비해 성능이 떨어졌고, 이들은 사전학습에서 left-to-right auto-regressive 언어모델링을 고려하지 않은 유일한 모델들이다.
Bidirectional encoders are crucial for SQuAD
이전의 연구는 left-to-right decoder가 SQuAD task에서 성능이 좋지 않다고 밝혔는데, 미래 문맥이 분류 결정에 중요하기 때문이다. 하지만, BART는 절반의 bidirectional layer로 비슷한 성능을 보여주었다.
The pre-training objective is not the only important factor
사전학습 objective 외에도 중요한 요소들이 있다는 것이다. 저자들이 실험한 permuted LM은 XLNet보다 좋지 못한 성능을 보였는데, 이는 relative-position embeddings와 segment-level recurrence와 같은 다른 구조적 향상을 포함하지 않았기 때문이라고 한다.
Pure language models perform best on ELI5
BART는 ELI5 데이터셋에서 outlier 즉, 다른 task에 비해 높은 perplexity를 보였다. 다른 모델이 BART보다 좋은 성능을 보인 유일한 생성 task이다. 이를 통해 순수한 LM이 가장 좋은 성능을 보이고, BART는 문서가 loosely게 연관된 경우 덜 효과적이었다는 것을 알 수 있었다.
BART archieves the most consistently strong performance
ELI5를 제외하면, text-infilling 방법으로 학습한 BART 모델이 모든 task에서 가장 좋은 성능을 보여주었다.
5. Large-scale Pre-training Experiments
최근의 연구는 큰 batch 사이즈와 corpora로 사전학습될 때, downstream 성능이 드라마틱하게 향상되는 것을 보여주었다. BART도 이러한 방법이 얼마나 효과적인지 테스트하기 위해 그리고 downstream task에 유용한 모델을 만들기 위해, 저자들은 BART를 RoBERTa 모델과 같은 스케일로 학습시켜보았다.
이후 BART large를 다른 모델들과 성능을 비교해본다.
5.1 Experimental Setup
- Encoder와 Decoder 각각 12 layer와 1024개의 hidden size
- RoBERTa와 같이, batch size는 8000으로 500000 step 만큼 학습
- 문서들은 GPT-2에서와 같게 byte-pair encoding으로 tokenized
- 앞서 실험결과를 기반으로, text infilling과 sentence permutation을 조합해 사용 (sentence permutation이 CNN/DM 요약 데이터셋에서만 큰 성능 향상을 보이지만, large 학습 모델에서 더 잘 학습할 것이라고 가정)
- 각 문서에서 토큰의 30% mask + 모든 문장을 섞음 - 모델이 데이터를 더 잘 학습하기 위해, 학습 마지막 10%는 dropout하지 않음
- 데이터셋은 160Gb의 뉴스, 책, 이야기, 웹 텍스트
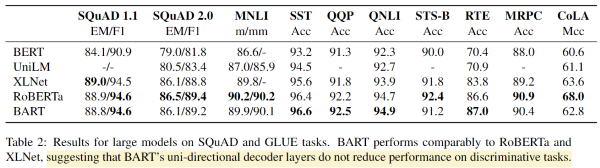
5.2 Discriminative Tasks
SQuAD와 GLUE task에서 BART와 다른 여러 모델을 비교해본다. 가장 직접적으로 비교할만한 baseline은 RoBERTa이다. 같은 리소스로 훈련되지만 다른 objective를 가지고 있기 때문이다. 전체적으로 BART는 대부분의 task에서 다른 모델들과 조금의 차이로, 유사한 성능을 보여주었다. 생성 task에서 BART의 좋은 성능이 분류 성능에까지 영향을 가져오지 못한다는 것을 의미한다.(BART는 생성 task에 강점이 있다는 의미)
5.3 Generation Tasks
여러 텍스트 생성 task 실험도 진행했습니다. BART는 일반적인 seq-to-seq 모델(input으로부터 output text 만드는)로써 fine-tune 했다.
- fine tuning에서 label smoothed cross entropy loss 사용
- smoothing parameter는 0.1로 설정
- beam size=5, beam search에서 중복된 trigram 삭제
- min-len, max-len, length penalty를 검증용 set를 생성할 때 모델에 tune
Summarization
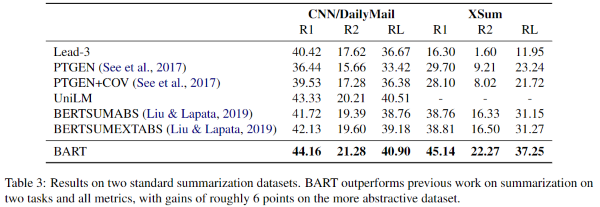
요약 task의 Sota들과 비교하기 위해, 특징이 다른 CNN/DailyMail과 XSum 두개의 요약 데이터셋으로 실험을 수행했다.
CNN/DailyMail은 source 문장과 닮은 경향이 있다. Extractive 모델이 더 잘 수행했고, 1-3에 있는 baseline도 굉장히 경쟁력있는 성능을 보여주었다. 그럼에도, BART는 이전에 존재하는 모든 연구보다 좋은 성능을 보여주었다.
반대로 XSum은 굉장히 abstractive해서, 해당 데이터셋에선 extractive 모델은 성능이 약하다. BERT를 활용한 이전에 좋은 성능을 보여준 연구보다 BART는 대략 6.0 ROUGE 메트릭만큼 향상되었다. 또한, 질적으로도 높은 성능을 보여주었다.
Dialogue
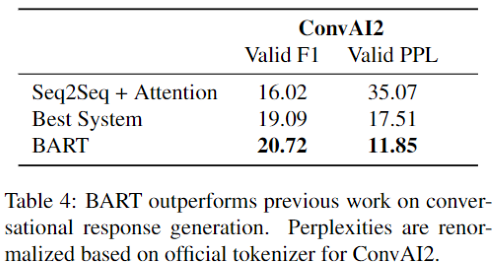
저자들은 CONVAI2의 대화 응답 생성도 실험해보았다. 이는 이전 문맥과 텍스트로 명시된 persona 두 가지를 고려해서 응답을 생성해야 한다. BART는 2개의 자동화된 메트릭에서 이전 연구보다 좋은 성능을 보여주고 있음을 확인할 수 있다.
Abstractive QA
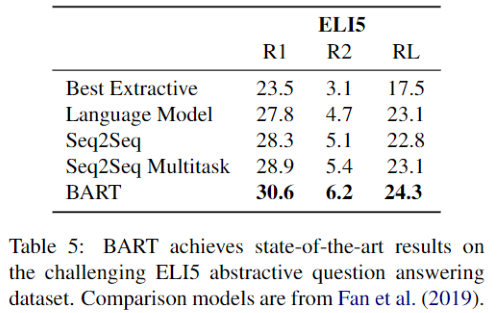
저자들은 모델이 ELI5 데이터셋으로 긴 자유형식의 답을 생성하는 능력을 테스트해보았다. BART가 이전의 연구보다 1.2 ROUGE-L 더 좋았다. 하지만 해당 데이터셋은 답변이 문제에서 잘 정의되지 않기 때문에, 해결해야할 문제들이 남아있다.
5.4 Translation

저자들은 back-translation로 augmented한 WMT16 Romanian-English 데이터셋으로 번역 실험을 수행했다. source encoder로 6개의 transformer layer를 사용해서 Romanian을 noising된 English로 매핑하고 BART가 이를 denoising한다. Transformer large 모델을 baseline으로 두고 실험결과를 비교했다. 앞서 3장에서 밝힌바와 같이 2단계를 거쳐 학습했는데, BART를 freeze하고 한번 학습, 전체 BART fine-tuning 하는 단계로 학습했다. Beam width는 5로 주고 length penalty는 으로 설정했다. 제안한 모델은 back-translation data가 없다면 성능이 별로 효과적이지 않고 overfitting되는 경향이 있었다. 향후 연구에서는 추가적인 정규화 기법을 찾아봐야 한다.
6. Qualitative Analysis
지금까지 BART는 요약 task 평가에서 크게는 기존 Sota모델보다 6 point 더 향상되는 것을 보여줬다. BART의 성능을 자동화된 평가를 넘어 자세히 이해하기 위해, 생성된 문장의 질적인 부분을 분석해보았다.

위의 예들은 BART로 생성한 요약 문장의 샘플들이다. 예시된 문장들은 사전학습 말뭉치에 없는 WikiNews 기사들로 구성해서, 모델의 학습 데이터에 해당 문장들이 존재할 가능성을 제거했다. 또한, 기사의 첫번째 문장을 제거해서 요약 수행하도록 하여 문서의 extractive 요약이 쉽지 않게 했다.
모델은 유창하고 문법적인 English였다. 또한, 모델의 결과는 입력된 문서들로부터 적은 phrase만을 copy했고 굉장히 abstractive했다. 그리고 결과는 일반적이고 사실적으로 정확했으며, 배경지식과 함께 입력 문장에서의 뒷받침 증거들로 요약한 문장을 구성하고 있었다. 저자들은 이러한 요약들이 BART의 사전학습이 자연어의 이해와 생성을 강하게 결합해 학습되고 있다는 것을 증명했다고 말한다.
7. Related Work
초기 사전학습 방법들은 주로 language model에 기반했다.
- GPT는 leftward 문맥만 다루기 때문에 몇몇 task에서 문제가 있다.
- ELMo는 left-only, right-only representation을 각각 합치는데, 이들 사이의 상호작용(상관관계)는 학습하지 않는다.
- Large LM이 비지도 multitask 모델로 사용할 수 있음을 확인했다.
- BERT는 masked language modelling으로 좌우 문맥을 학습할 수 있도록 사전학습을 수행했다.
- 학습을 더 오래하거나, layer간 parameters를 전달해주거나, 단어 대신 spans을 마스킹하는 방식으로 강한 성능을 달성함을 확인했다.
- 다만, 예측은 auto-regressively이므로, generation task에서 BERT는 성능이 좋지 않았다. - UniLM은 몇몇 leftward context 하는 마스킹 방식을 앙상블해서 BERT를 fine-tuning한 모델이다. BERT와 다르게 generative와 discriminative task에서 사용할 수 있고, conditionally independent하게 예측할 수 있다.
- BART는 사전학습 때와 generation task 사이에 불일치가 감소했는데, decoder에 항상 손상되지 않은 원본 문서를 입력해주기 때문이다. - MASS는 BART와 가장 유사한 모델인데, 연속된 span으로 마스킹한 문장을 입력으로 주고, 마스킹된 토큰을 매핑한다. MASS는 discriminative task에서 덜 효과적인데, 분리된 토큰 셋을 encoder와 decoder에 넣어주기 때문이다.
- XLNet은 permuted 순서로 마스킹된 토큰을 auto-regressively 예측하는 방식으로 확장된 BERT라고 볼 수 있다.
몇몇 연구에서는 기계번역을 향상시키기 위해 사전학습된 representation을 사용했다.
- 가장 큰 향상은 source와 target 언어 모두에 사전학습을 함으로써 달성했다. 하지만 이 방식은 번역할 모든 언어에 대해 사전학습을 수행해야만 한다.
- 다른 연구는 사전학습된 representation을 사용함으로써 encoder를 향상시킬 수 있었지만, decoder의 개선은 제한적이었다.
본 논문에서는 BART를 통해 기계번역 decoder를 향상시키는 것을 보여주었다.
8. Conclusion
BART는 손상된 문서를 원래대로 복구하도록 학습하는 접근방식으로 사전학습한 모델이다. BART는 discriminative task에서 RoBERTa와 비슷한 성능을 달성했고, 여러 text generation task에서 Sota를 달성했다. 추후 연구에서는 사전학습을 위해 문서를 손상시키는 새로운 방법에 대해 연구해볼 필요가 있다.
