[Paper Review] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
BERT와 RoBERTa는 semantic textual similarity와 같은 문장 짝짓기 task에서 sota를 달성했었습니다. 하지만 두개의 문장을 network에 입력해야되고 많은 연산량을 요구하기 때문에, semantic similarity를 탐색하는 task에는 다소 적절하지 않습니다.
해당 논문은 BERT network를 siamese and triplet 구조로 구성하고, cosine-similarity를 사용해 각 결과를 비교함으로써 semantically meaningful sentence embedding을 도출해냅니다. 그 결과 여러 문장비교 task에서 sota와 높은 성능을 보여주었습니다.
1. Introduction
이 논문에서는 BERT network를 siamese and triplet network로 구성하여 의미적으로 비슷한 문장을 구별하는게 주요 기여점이다.
기존의 BERT는 두개의 transformer encoder를 사용하기 때문에 두개의 문장을 network에 입력해 regression하기 위해선 모든 가능한 combination을 연산해야 한다. 가령, 10,000개의 문장 쌍을 비교한다면 BERT는 번의 계산을 수행해야만 한다.
문장 쌍을 비교하기 위해서는 각 문장을 vector 공간에 mapping하여 거리를 비교하는게 일반적이다. 그래서 BERT를 사용해 문장비교를 위해 output layer로부터 고정된 크기의 문장 embedding 결과를 도출해 평균내거나, CLS 토큰의 출력을 사용한다. 하지만 이러한 방법은 GloVe embedding을 평균내는 방법보다 성능이 더 좋지 않다.
이러한 단점을 완화하기 위해 본 논문에서는 Sentence-BERT를 제안한다. Siamese network로 구성한 후, input 문장으로부터 나온 고정된 크기의 vector 를 cosine-similarity, Manhatten / Euclidean distance를 사용해 문장쌍을 비교하는 방법이다. 그래서 해당 방법은 문장들의 semantic 유사비교와 clustering에 사용될 수 있고, BERT에 비해 엄청난 속도 향상을 보여주었다.
SBERT를 NLI data에 fine-tune했을 때에는 InferSent, Universal Sentence Encoder와 같은 sota 문장 embedding 방법론보다 더 좋은 성능을 보여주었다. 특히 Semantic Textual Similarity(STS) task에서 SBERT는 11.7의 좋은 성능을 나타냈다. 또한, specific task에도 적용할 수 있다.
2. Related Work
BERT는 사전학습된 transformer network로써 다양한 NLP task에서 sota를 달성한 모델이다. 문장쌍 regression을 위해 BERT는 SEP 토큰으로 구분된 두 문장으로 입력되고, multi-head attention을 거쳐 simple regression을 통해 최종적인 결과를 출력한다.
RoBERTa는 BERT의 성능이 사전학습 과정이 성능 향상을 가져온다는 것을 보여주었다.
하지만 BERT network의 구조는 각 문장에 대한 embedding이 독립적으로 계산되지 않는다는 단점이 존재하므로, BERT로부터 문장 embedding을 도출하는 것이 어렵다. 그래서 연구자들은 문장쌍 비교를 위해서 BERT에 단일 문장을 입력하고 output을 평균내거나 혹은 CLS token의 output을 통해 고정된 크기의 vector를 구하였다. 그러나 이것이 유용한 방식인지는 평가가 존재하지 않는다.
문장 embedding은 꽤 발전된 연구분야이고, 제안된 다양한 선행 연구들이 존재한다.
Skip-Thought, InferSent, a siamese BiLSTM, Universal Sentence Encoder..(문장 비교 task가 주요 분야라면 이전 연구들에 대해 살펴볼 필요가 있겠다...)
본 논문에서는 사전학습된 BERT와 RoBERTa network를 사용하고, 유용한 문장 embedding을 얻기 위해서 fine-tune한다. 그리하여 학습시간도 상당히 감소하였고, 여러 문장 embedding 방법보다 더 좋은 결과를 얻어냈다.
3. Model
먼저 SBERT는 고정된 크기의 문장 embedding을 얻기 위해 BERT, RoBERTa의 output에 pooling operation을 추가한다. 다음과 같은 3가지의 pooling 전략을 가지고 실험을 진행하였다.
- CLS 토큰 사용
- output vector들의 평균 값
- output vector들 중 최대 값
BERT와 RoBERTa의 fine-tune은 다음과 같이 진행된다. Network를 siamese와 triplet 구조로 만들고, 생성된 문장 embedding들을 cosine-similarity를 사용해 비교할 수 있도록 가중치를 업데이트 한다. 아래 3가지의 구조와 목적식으로 구성하여 실험하였다.
Classification Objective Function
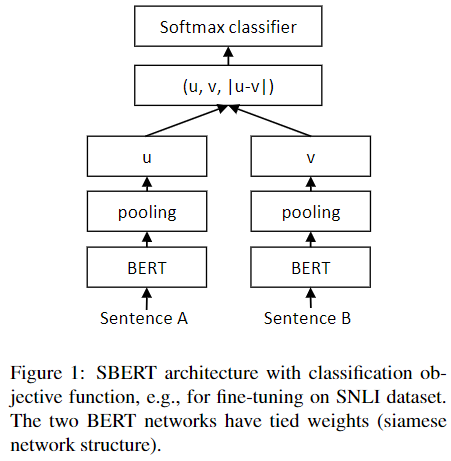
각 문장의 embedding 와 를 와 합하고 학습가능한 가중치 와 곱한다. 은 문장 embedding의 차원이고, 는 label의 개수이다.
이 목적식으로 학습하고 cross-entropy loss를 사용해 최적화한다.
Regression Objective Function
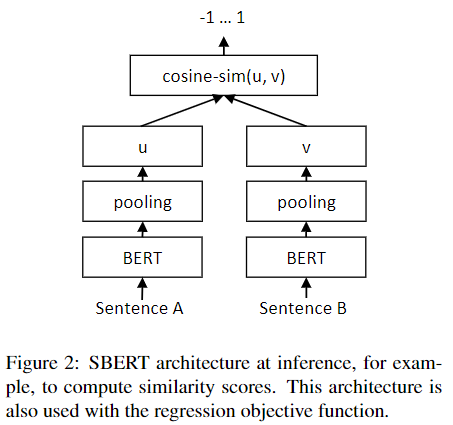
두 문장의 embedding 와 를 cosine-similarity를 계산한다. 그리고 해당 목적식을 Mean-Squared-Error(MSE) loss를 계산하여 최적화한다.
Triplet Objective Function
기준문장 와 그에 따른 긍정(유사한)문장 와 부정(유사하지 않은)문장 이 주어진다면, triplet loss는 와 사이의 거리가 와 사이의 거리보다 더 가깝도록(loss가 작도록) network를 조정하는 목적식이다.
는 의 문장 embedding이고, 은 문장 사이 거리 metric이다. 은 문장 사이의 margin을 나타내는데, 최소한 가 와 최소한 만큼 더 가깝도록 해준다. Euclidean 거리를 사용해 metric을 구하고 로 설정해 실험하였다.
3.1 Training Details
본 논문의 실험에서는 SBERT를 SNLI와 Multi-Genre NLI dataset의 조합으로 학습시킨다. SNLI는 contradiction, eintailment, neutral 를 가지는 570,000 문장쌍들의 집합이고, MultiNLI는 다양한 장르의 말과 글을 다루는 430,000개의 문장쌍이다.
SBERT는 3가지 방식의 softmax-classifier 목적식으로 fine-tune한다. 매 epoch마다 fine-tune하고, batch-size는 16로 설정하였다. 또한, 학습률 로 Adam optimizer를 사용하였고, 학습데이터의 10%마다 선형적으로 학습률을 조정하였다. Pooling 전략은 문장 embedding들의 평균을 사용하였다(default).
4. Evaluation - Semantic Textual Similarity
SBERT를 Semantic Textual Similarity(STS) task를 통해 평가한다. 기존 sota는 문장 embedding을 similarity score에 맵핑하는 regression 함수를 학습하는 방식이다. 하지만 regression 방식은 pair-wise하게 작동하므로 문장 모음이 특정 크기에 도달하면 combinatorial explosion 문제가 있어 확장하지 못한다는 단점이 있다. 대신에 저자들은 두 문장의 cosine-similarity를 비교하는 방식을 사용한다. 또한, negative Manhatten과 negative Euclidean 거리도 동시에 사용해보았고, 결과가 크게 달라지진 않았다.
4.1 Unsupervised STS
저자들은 STS task를 위한 SBERT를 위해 STS를 위한 특정 데이터 없이 학습해보았다. 다만, 이전 연구에서 문장 사이의 cosine-similarity와 gold label간 비교할 때, Pearson correlation가 STS에 적합하지 않다는 것을 알았고, 대신에 Spearman의 rank correlation을 사용해 비교하였다.
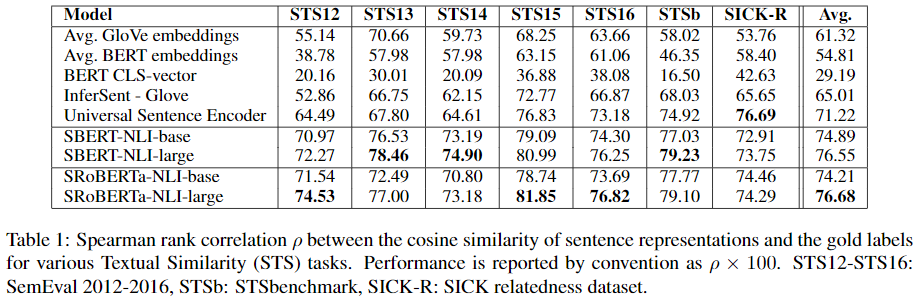
결과를 보면, BERT의 결과가 좋지 않았다. GloVe embedding들을 평균내는 방식보다 좋지 않았다. 본 논문에서 주장한 siamese network 구조의 방식을 사용했을 때는 성능이 크게 증가했다. 다만, SICK-R 데이터셋에서는 Universal Sentence Encoder 방식이 더 좋은 성능을 나타냈다. 이는 해당 모델이 new, question-answer pages 등 다양한 데이터셋으로 학습된 모델인 반면, SBERT는 오직 Wikipedia와 NLI 데이터로만 사전학습 되었기 때문이라고 저자들은 생각했다.
또한, 문장 embedding들의 생성에 있어 SBERT와 SRoBERTa는 성능차이가 미미했다.
4.2 Supervised STS
STS 벤치마크에서 제공하는 Captions, news 등 8,628 문장쌍을 사용했다. 5,749개 쌍을 학습에, 1,500개 쌍을 검증에, 1,379개 쌍을 테스트에 사용했다. 저자들은 regression 목적 함수를 통해 SBERT를 fine-tune했고, 각 문장 embedding들의 cosine-similarity를 계산함으로써 예측을 수행하도록 했다.
저자들은 두 가지의 셋업을 구성하였고, 10 randowm seeds로 학습시켰다.
- STSb 만을 가지고 학습
- NLI을 가지고 1차 학습, STSb로 2차 학습
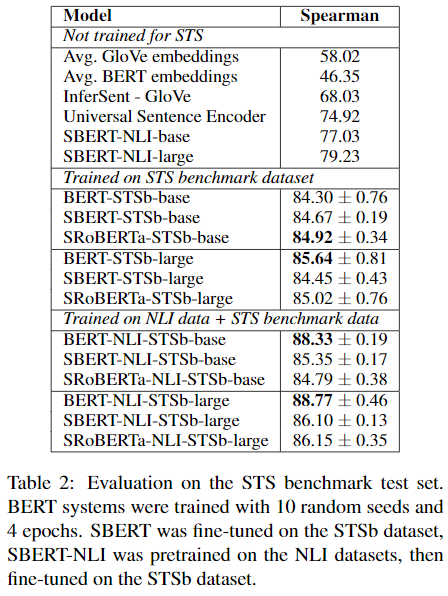
후자의 방식이 1-2 points 더 향상된 성능을 보였다.
4.3 Argument Facet Similarity
SBERT를 Argument Facet Similarity(AFS) corpus를 사용해 평가해보았다. AFS 데이터는 gun control, gay marriage 등의 논란이 있는 소셜 미디어 dialog 데이터이다. 0-5 사이로 주제의 비슷한 정도가 측정된다. STS 데이터는 descriptive한 유사성이라면, AFS는 dialog로부터 발췌했기 때문에 argumentative하다.
저자들은 SBERT를 두 가지의 시나리오로 평가했다.
- 10-fold cross validation을 사용
- cross-topic 설정으로 평가(두가지 주제 제공하고 하나의 문장을 기준으로 상대평가, 총 3가지 토픽)
Regression 목적 함수를 사용해 SBERT를 fine-tune했고, cosine-similarity를 사용해 similarity score를 계산했다. 또한, Pearson correlation 도 같이 사용해 성능을 평가했다.(Spearman correlation에 추가로)
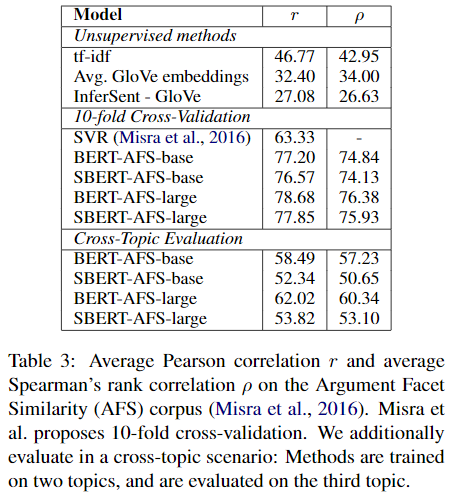
tf-idf, GloVe, InferSent와 같은 unsupervised 방법은 해당 데이터셋에서 낮은 score를 보였다.
첫번째 시나리오에서는 BERT와 SBERT가 비슷한 성능을 보였다.
두번째 시나리오에서는 SBERT가 약 7 points 더 높은 Spearman correlation을 보였다. BERT는 각 문장을 attension을 사용해 직접적으로 비교하는 반면, SBERT는 각 문장을 vector 공간으로 맵핑해 거리를 평가하는 방식이다. 따라서 비슷한 주장과 그의 추론 문장을 vector 공간에 가깝게 맵핑하기 위해서는 두번째 시나리오 방식으로 모델을 학습시킬 필요가 있다.
4.4 Wikipedia Sections Distinction
Wikipedia 기사는 특정 측면에 초점을 맞춘 몇개의 섹션으로 구분된다. 같은 섹션의 문장들은 다른 섹션의 문장보다 주제적으로 더 가깝다고 가정하고(triplet), 데이터 셋을 약하게 라벨링했다. 기준 문장과 positive 예시 문장은 같은 섹션이고, negative 문장은 다른 섹션으로부터 나온 문장이라는 것이다.
기존에 Wikipedia를 주제별로 세분화하고 학습, 검증, 테스트로 나눠진 데이터를 사용했다. Triplet 목적식을 사용하였고, 평가지표로 positive 예시 문장이 negative 문장보다 기준 문장에 더 가까운지 정확도를 통해 평가하였다.
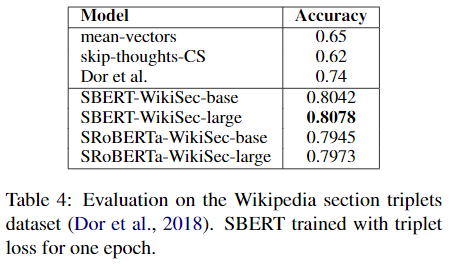
SBERT가 BiLSTM을 사용한 방식보다 더 좋은 성능을 보여주고 있다.
5. Evalutation - SentEval
SentEval은 문장 Embedding의 성능을 평가하기 위한 좋은 툴킷이다. 문장 embedding들은 보통 logistic regression classifier를 위해 문장의 특징으로써 사용되었다. 그래서 logistic regression classifier는 다양한 task에 맞게 학습되는 방식이었다. 하지만 SBERT의 문장 embedding은 해당 방식이 아니므로, transfer learning을 사용하지 않고 해당 task에 대해 fine-tuning한다.
SBERT를 7개의 SentEval transfer task들에 대해 다른 문장 embedding 방법론들과 비교해본다.
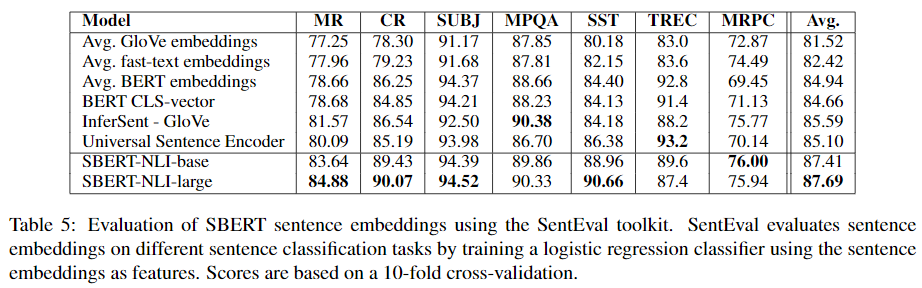
SBERT는 7개 중 5개의 task에서 가장 좋은 성능을 보여주었다. SBERT의 목적은 transfer-learning이 아니지만, 해당 task에서 다른 문장 embedding 방법드보다 좋은 성능을 달성했다. 이는 SBERT의 문장 embedding들이 sentiment 정보를 더 잘 포착하는 것을 의미한다.
SBERT는 유일하게 TREC 데이터셋에 대해 Universal Sentence Encoder보다 좋지 않은 성능을 보였다. 저자들은 Universal Sentence Encoder가 question-answering 데이터로 사전학습되었기 때문에, question-type classificaion task인 TREC에서 유리한 것으로 판단했다.
앞서 STS task에서 BERT의 embedding들의 평균 방법, CLS 토큰 방법이 굉장히 좋지 않은 성능을 보였는데, SentEval에선 꽤 괜찮은 성능을 보여주었다. 이러한 이유는 setup의 차이라고 밝혔다. STS task에서는 각 문장 embedding을 cosine-similarity를 사용해 비교하는데, 모든 차원을 동일하게 간주해 비교하게 된다.
반면, SentEval은 logistic regression classifier를 문장 embedding에 fitting하게 된다. 이는 문장의 의미있는 부분, 특정 차원이 분류 결과에 크게 영향을 줄 수 있도록 해준다. 그러므로 더 좋은 성능을 보여준 것으로 판단된다.
따라서 저자들은 BERT의 embedding 평균, CLS 토큰 방법을 cosine-similarity 혹은 Manhatten/Euclidean 거리를 사용하기 힘들다고 주장한다. 결과적으로 NLI 데이터셋을 사용해 Siamese network 구조의 모델을 fine-tune한 SBERT가 SentEval의 대부분에서 sota를 달성했다.
6. Ablation Study
Pooling strategy를 서로 다르게 해서 실험해본다(Mean, Max, CLS). 또한, classification의 목적함수를 여러 concatenation 방법을 사용해 실험해본다.
또한, classification objective function은 라벨이 있는 SNLI, Multi-NLI 데이터셋으로 학습하고, regression objective function은 STSb 데이터셋으로 학습한다. 평가는 둘 다 STSb로 평가된다. Concatenation 방법에서는 Mean pooling을 사용한다.
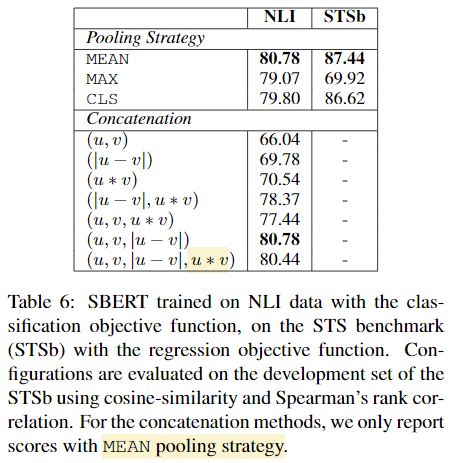
NLI 데이터로 학습시킨 classification objective function에서 pooling strategy는 미미한 차이를 보였고, concatenation에서 큰 영향이 있었다. InferSent와 Universal Sentence Encoder는 softmax classifier의 입력으로 를 사용했지만, SBERT에서는 를 제거한 것이 미미하게 더 좋은 성능을 보였다.
concatenation에서 가장 중요한 요소는 이다. concatenation mode는 오직 softmax classifier 학습에서만 사용하고, 유사성 추론은 문장 embedding 와 의 cosine-similarity를 사용한다.
Regression objective function의 학습에서는 pooling strategy가 중요하게 작용했다. MAX strategy가 MEAN과 CLS 토큰을 사용하는 것보다 성능이 좋지 않았다. (InferSent의 BiLSTM-layer에서 MAX를 사용한 것과 대조적)
7. Computational Efficiency
문장 embedding은 많은 문장에 대해 산출해야 하므로, 계산속도가 빨라야 한다. STSb 데이터셋을 사용해 다른 모델과 속도를 비교해본다.
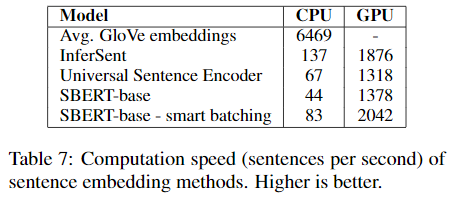
CPU를 사용하였을 때, InferSent는 SBERT보다 65% 빠른 속도를 보였다. InferSent는 단일 Bi-LSTM layer를 사용한 반면, BERT는 12개의 transformer layer가 스택된 구조이기 때문이다. 다만, Transformer 구조는 GPU에서 계산이 빠르다.
8. Conclusion
기존 BERT는 일반적인 유사도 측정 방식에 사용되기엔 부적절하다. 이러한 단점을 개선하기 위해 BERT를 siamese, triplet network 구조로 만들고 이를 fine-tune하는 방식의 SBERT를 제안하였다. SBERT는 다양한 벤치마크에서 향상된 성능을 보여주었고, 연산 속도 측면에서도 smart batch 방법과 GPU를 사용한다면 다른 모델보다 더 빠른 속도를 보였다.
