
CNN
CNN은 이미지 분류 분야에서 좋은 성능을 보여준 아키텍쳐입니다. 이전에 cs231n을 수강했었는데 CNN에 궁금한 점들이 생기면서 다시 공부하면서 정리했습니다.

CNN의 기본 아이디어는 동물이 물체를 구분할 때에 과정에 착안하여 만들어진 신경망 모델입니다. CNN의 기본적인 구조는 위 그림과 같은데, 특징을 추출하는 Conv Layer와 정보를 압축하는 Pooling Layer의 반복이 핵심입니다.
Convolution Layer
Convolution Layer는 CNN의 핵심입니다. 이 layer가 입력받은 이미지의 특징을 추출하는 역할을 하기 때문인데, CNN은 이 convolution layer를 여러겹 쌓아 만들게 됩니다.
Convolution layer에서는 filter를 가지고 이미지를 순회하면서 특징을 추출하는데, 어떤 과정을 통해 추출하는지 알아보겠습니다.(이후에서는 Conv layer라고 하겠습니다)

가장 첫번째의 Conv layer에서 filter는 현미경과 같이 이미지의 세세한 부분을 보게 되는데, 위의 그림과 같이 쥐 사진이 모델에 입력되었다고 가정해보겠습니다. 이때 이미지 크기에 비해 상대적으로 작은 노란색 filter는 이미지의 매우 작은 부분만 볼 수 있겠죠. 그래서 첫번째 layer에서는 점, 선과 같은 단순한 정보를 추출하게 됩니다.
연산 과정은 가중치를 가진 filter가 이미지를 순회하면서 이미지의 점, 선과 같은 특징이 있는 부분과 곱해져, 높은 값은 더 높게 낮은 값은 낮게 하여 픽셀 값을 뽑아내게 됩니다.

Conv layer는 여러개의 filter로 구성하게 되는데, 여러 filter를 가지고 이미지의 여러 특징을 뽑아내겠다는 것입니다. 위의 그림은 이미지가 첫번째 Conv layer에 있는 96개의 filter를 시각화 한 것입니다. 이렇다 다르게 생긴 96개의 filter가 이미지를 순회하면서 서로다른 96개의 특징을 추출하게 됩니다.

filter는 학습하면서 가중치를 계속 업데이트하고, 해당하는 특징을 더 극대화해서 추출할 수 있도록 합니다. 학습 후에 filter의 가중치를 업데이트해서 특징을 더 잘 뽑아내게 됩니다.

이렇게 각 필터가 이미지를 순회하면서 추출한 특징은 feature map에 맵핑하게 됩니다. 위 그림에서는 첫번째 Conv layer에서 6개의 filter를 사용해서, 6개의 feature map을 만들어낸 것을 확인할 수 있습니다. 다시 본론으로 돌아가서 filter의 개수만큼 추출한 feature map은 다음 layer로 보내집니다.
Pooling Layer
Conv layer를 지나면 Pooling layer를 볼 수 있습니다. Pooling layer는 이미지를 down sampling하는 역할을 합니다.
연산은 비교적 간단합니다. 특정 크기의 filter가 Conv layer를 거쳐 나온 feature map를 순회하면서 해당 영역에서 조건에 맞는 값을 추출하는 것입니다. 조건에 따라 pooling 방법이 다른데, 특정 영역에서 가장 큰 값을 추출한다면 max pooling, 영역 내 값들을 평균내 추출하면 average pooling 등 여러 조건이 있습니다. 여기서는 max pooling을 기준으로 설명합니다.
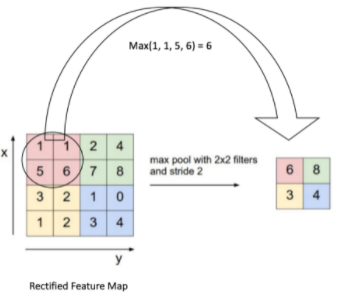
선술했다시피 max pooling은 특정 영역에서 가장 큰 값을 꺼내오는 것입니다. 위의 그림과 같이 예를 들 수 있는데, max pooling을 하게되면 영역 내에 가장 큰 값을 가져오기 때문에 특징이 더욱 뚜렷해지는 효과를 가져옵니다.
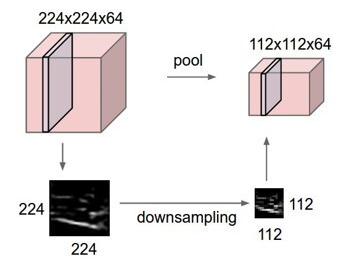
또한, pooling은 이미지의 크기를 작게 만들어주는 down sampling 역할도 수행합니다. 이미지의 형태는 유지하면서 크기만 작아지게 되는데, 크기를 작게 만드는 이유는 이후 Conv layer에서 filter가 이미지의 더 큰 부분을 볼 수 있도록 하기 위함입니다. Conv layer에서 filter의 크기는 변하지 않게 설정해놓기 때문에, 이미지의 크기가 줄어들수록 filter가 포착할 수 있는 이미지의 영역은 점점 더 늘어나겠죠.
위에서 살펴본 쥐 그림의 예시에서는 filter가 쥐의 가장자리 정보만 추출하듯이, 첫번째 Conv layer에서는 이미지의 점과 선같은 부분에 대한 정보만 포착한다고 했었죠. 하지만 Pooling layer를 거쳐 down sampling되면 이미지의 형태와 특징은 유지한채 크기만 작아지므로, 이후 Conv layer filter는 좀 더 이미지 내 물체의 형태적인 특징을 잡아낼 수 있겠죠. 즉, 더 추상적인 부분을 볼 수 있게 됩니다.

위 그림은 4개의 Conv layer를 거쳐 나온 각각의 feature map들 입니다. layer가 깊어질수록 추상적인 특징들을 잡아내고 있는 것을 확인할 수 있습니다. 이처럼 Pooling layer에서는 Conv를 거쳐 나온 이미지의 특징을 간추려 down sampling하는 역할을 합니다.
Conv + Pooling
이제 첫번째 Conv layer와 Pooling layer를 지났다고 가정해보겠습니다. 그럼 다음 Conv layer는 어떻게 연산이 진행되는지 살펴보겠습니다.
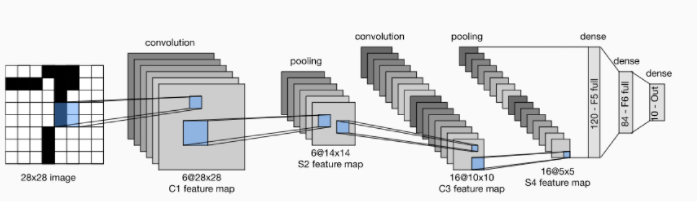
위의 그림을 보면, 첫번째 Conv에서는 6개의 filter를 사용해서 6개의 feature map이 만들어졌고(C1) pooling을 통해 6개의 feature map이 down sampling되었습니다(S2). 그리고 다음 Conv로 전달되는데, 다음 Conv layer는 16개의 filter를 가지고 있습니다. 여기서 이 16개의 filter를 가지고 6개의 feature map에 동시에 conv연산이 적용됩니다. 즉, 6개의 feature map에 새로운 16개의 filter를 통해 특징을 추출하는 연산을 수행하고, 16개의 feature map이 나오게 됩니다.
또한, 보통 뒤로 갈수록 filter의 개수가 많아지는데, 두가지 이유가 있다고 합니다.
첫 번째는 연산량 때문인데, 첫번째 Conv layer에서는 큰 이미지가 입력되어 conv 연산을 수행해야 하므로 적은 수의 filter만으로도 연산량이 많아지게 됩니다. 이후 layer를 지날수록 down sampling되므로 이미지의 크기가 계속 줄어들기 때문에 더 많은 수의 filter를 사용해도 연산량은 크게 증가하지 않게 되죠.
두 번째 이유는 layer를 지날수록 이미지가 더 추상적이기 때문입니다. 왜냐면 점, 선과같은 단순한 정보들로부터는 추출할 특징이 많지 않으므로 여러 filter를 사용하는게 큰 의미가 없을 것입니다. 하지만 이미지가 추상적일수록 추출할 수 있는 특징이 많기 때문에 여러 filter를 적용하는 것이 장점이 있죠. 그렇기 때문에 뒤로 갈수록 많은 filter를 사용하는 것입니다.
FC Layer
앞서 우리는 이미지를 입력받아 Conv와 Pooling layer를 거쳐 특징 추출을 반복했습니다. Layer를 깊게 쌓아 과정을 반복할수록 물체와 유사한 feature map을 추출하게 될 것입니다. 여기서 최종적으로 물체와 유사한 feature map을 가지고 이미지를 분류하게 되는데, 여기서 FC layer를 사용합니다. FC layer는 fully-connected layer로 neural network를 의미합니다

즉, 마지막 feature map을 일렬로 squeeze하고 이것을 FC layer의 입력으로 준 뒤, 여러 hidden layer를 거쳐 분류 문제를 해결하게 되는 것입니다.
CNN 아키텍처를 개략적으로 알아보았습니다. 실제 구현에서는 하이퍼 파라미터를 어떻게 설정할지, layer는 얼만큼 쌓아야 하는지, optimizer는 무엇을 쓸지 등 고려할 변수가 굉장히 많습니다. 또한, CNN을 골격으로 하여 성능을 향상한 여러 모델도 살펴봐야겠습니다.
Reference)
CNN(Convolution Neural Network)는 어떤 구조인가요?

헤으응...