[Paper Review] Deep Residual Learning for Image Recognition
Neural Network가 깊어질수록 학습은 어려워진다. 본 논문에서는 layer에 input되는 값에 대해 residual function을 추가함으로써 모델을 더 쉽게 학습하고자 한다.
1. Introduction
Deep convoultional neural networks는 이미지 분류 task에서 많은 발전을 이루었다. 또한, network를 깊게 쌓을수록 이미지의 feature를 더 잘 포착할 수 있었고, 여러 비전 인식 분야에서 모델을 깊게 쌓을 수록 좋은 성능을 보여주었다.
본 논문은 'layer를 더 많이 쌓을수록 network를 더 잘, 더 쉽게 학습할 수는 없을까?'하는 생각으로부터 시작되었다. 모델이 깊어질수록 기울기 소실, 폭발 문제로 수렴이 어려워지고, 학습은 어려워지기 때문이다. 또한, 더 깊은 모델이 수렴을 시작하더라도 성능 저하의 문제도 존재한다.

이러한 이유들로 모델을 optimize하는 건 쉽지 않은 문제이다. 더 깊은 모델을 구성하는데 있어 좋은 솔루션이 존재한다. identity mapping과 몇 개의 layer들을 통해 학습된 값들을 복사해두는 것이다. 하지만 연산시간이 오래 걸리는 등 기존보다 좋은 해결책이 되지 못했다.
본 논문에서는 deep residual learning을 통해 성능 하락 문제를 다룬다. stack된 layer들로부터 나온 값들을 바로 다음 layer로 보내는 것이 아니라, 해당 값을 residual mapping과 결합하는 것이다. stack된 layer로부터 나온 와 identity mapping 를 결합해 를 다음 layer로 보내준다. input 값을 참조해 구성한 residaul mapping이 optimize에 더 쉽게 도달할 것이라는 생각이다.
그리고 값은 FFN(Feedforward neural networks)를 통해 계산할 수 있다.
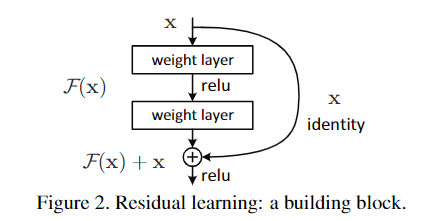
위의 그림에서와 같이 1개 이상 layer들을 skip하는 shortcut connnetion으로부터 identity mapping을 얻고, stack된 layer들로부터 연산된 결과를 더해서 residual mapping을 도출한다. 이러한 방식은 추가 parameter가 없고, 연산량도 늘어나지 않는다.
제시된 아이디어를 통해 ImageNet에서 모델을 깊게 쌓았음에도 이전보다(plain net) 더 좋은 정확도를 얻었으며, 더 쉽게 optimize 할 수 있었다. 다만, CIFAR-10에서의 실험을 통해 특정 데이터셋에서는 해당 방법이 다른 데이터셋에 비해 효과가 동일하지 않고 optimize가 어렵다는 것을 인지했지만, 모델을 더 깊게 쌓아보며 실험했고 성공적인 학습된 모델을 보여줄 수 있었다.
2. Related Work
Residual Representations.
이미지 인식 분야에서 VLAD 등 residual representation을 사용하는 방식의 효과를 보여준 몇몇 연구가 있었다. 또한, residual solution들을 여러 하위 문제로 정의하는 Multigrid 방식과 두 scale 사이의 residual vector를 통한 계층적 사전조건화 등이 있다.
Shortcut Connections.
Shortcut connection을 사용한 이론은 오랫동안 연구되어져 왔다. 초기 Multi-layer perceptron(MLP)의 학습, 기울기 소실과 폭발을 막기 위한 방법, 학습 시 layer의 오류를 센터링하기 위한 방법 등 여러 연구에서 사용되어져 왔다.
또한, 본 논문에서의 방식에 추가로 gating function과 shortcut connection을 나타낸 "highway networks"에 관한 연구도 있다. 그러나 해당 연구에서의 gates들은 parameter들을 가지고 있지만, 본 논문에서는 parameter를 추가로 가지지 않는다. 그리고 해당 논문에서는 gated shortcut이 열리거나 닫힘에 따라 residual function 값을 달리해가며 학습하지만, 본 논문에선 항상 residual functions을 학습한다. 특히 highway network는 모델이 깊어짐에도 정확도 향상을 입증하지 못했다.
3. Deep Residual Learning
3.1. Residual Learning
몇 개의 stack된 layer에 위에서 정의했던 를 고려해보자. 그렇다면 단순히 stack layer로 부터 나온 값이 에 근접하길 예상하기보단 shortcut을 통해 명시적으로 근사하도록 하고. 이를 통해 학습이 더 용이해질 것이다.
3.2. Identity Mapping by Shortcuts
본 논문에서는 몇 개의 stack된 layer마다 residual learning을 적용했다.
x와 y는 각각 layer의 input, output 벡터이다. 는 layer를 거쳐 나온 값으로 학습될 residual mapping을 나타낸다. 는 각 layer를 거치는 과정으로 만약 2개의 layer를 지난다면, 와 같이 나타낼 수 있다. (는 ReLU 함수이다) layer를 거쳐 나온 값을 shortcut connection과 element-wise로 더해주는데, 이를 로 나타낸다. 이후 산출된 값은 다시 비선형적 함수에 보내진다.
Residual net은 plain net과 parameter, depth, width, 연산량(element-wise와 같이 무시할 수 있는 요소 제외)이 동일하다.
앞선 수식은 와 의 차원이 같다고 가정했지만, 만약 차원이 같지 않다면 차원을 맞춰주어야 한다. shortcut connection을 linear projection하는 를 통해 차원을 맞춘다.
는 2개 이상의 layer를 포함할 수 있기 때문에 유연하지만, 만약 1개의 layer만 포함한다면 그 자체로 선형 layer가 되기 때문에 해당 방법의 이점이 사라지게 된다.()
간단한 설명을 위해 각 layer가 단순한 FC layer로 가정했지만, 각 layer는 Convolutional layer가 될 수도 있다. Conv layer라면 residual learning의 과정에서 element-wise addition은 채널별로 2개의 feature map에서 수행된다.
3.3. Network Architectures
ImageNet에 대하여 plain net과 residual net을 비교해본다.
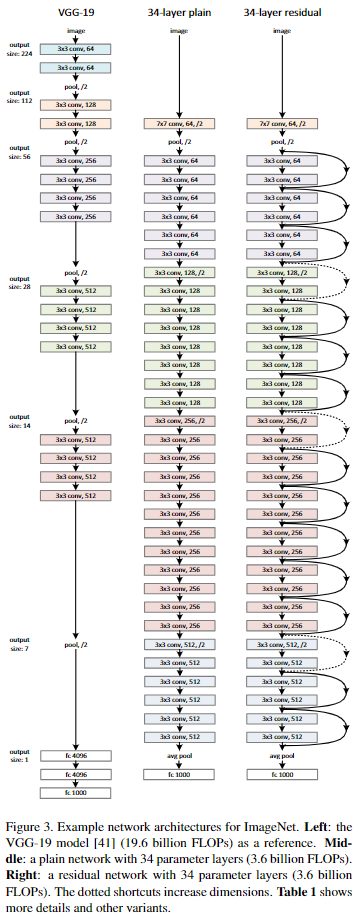
Plain Network.
VGGnet(왼쪽)으로부터 plain net baseline(가운데)을 구성한다. Conv layer는 3x3 filter를 사용하는데; 동일한 output feature map 크기를 위해 각 layer는 동일한 수의 filter를 가지고, 만약 feature map 크기를 절반으로 줄인다면 filter 수를 두 배로 늘린다.
새로 구성한 baseline이 VGGnet보다 더 적은 필터와 더 낮은 계산 복잡도를 가지고 있다.
Residual Network.
앞서 구성한 plain network에 shortcut connection을 추가해 residual network를 정의한다.(오른쪽)
Identity shortcut은 같은 차원의 input과 ouput을 연결한다.(오른쪽 network 중 실선) 차원이 증가할 때는 두 가지 옵션을 고려해볼 수 있다.
1. identity mapping에 추가된 차원만큼을 zero padding하여 차원을 맞춘다.(parameter 증가 없음)
2. 3.2.의 두 번째 수식과 같이 projection shortcut을 도입해 차원을 맞춘다.
3.4. Implementation
실험은 이미지의 픽셀 당 평균을 뺀 상태로 랜덤하게 샘플링, horizontal flip하고 사이즈 224x224 crop했다. 또한, 실험 조건은 아래와 같다.
<모델 학습조건>
- Conv를 지나고 activation function 전에 Batch Normalization을 수행
- Weight들은 초기화하여 처음부터 학습
- SGD 적용, mini-batch size=256
- Learning rate는 0.1부터 시작하고 error가 안정되면 10으로 나눠 rate를 줄임
- 모델의 학습 반복은 iteration=
- Weight decay=0.0001, momentum=0.9
- Dropout은 사용하지 않음
4. Experiments
4.1. ImageNet Classification
실험은 layer를 깊게 쌓아보면서 비교해보았다.
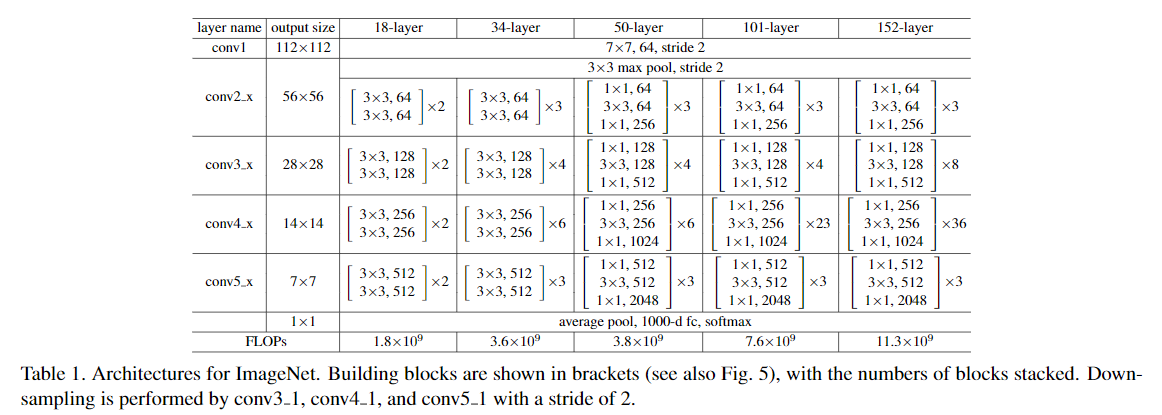
ResNet은 깊게 쌓을수록 성능의 저하 문제를 잘 처리하며, 깊게 쌓을수록 더 높은 정확도를 얻는 것을 보여준다.(차원 증가는 zero-padding으로 맞춰줌) 또한, ResNet은 plain net보다 더 좋은 성능을 보여주는데 있어 파라미터의 증가 없이 이루었다는 것이 주목할만 하다.
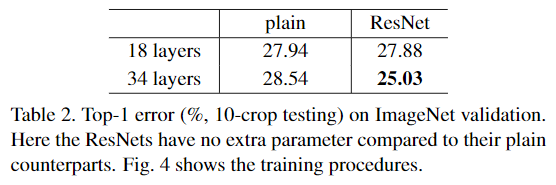
기존 plain net은 layer가 깊어지면 error가 더 높아지는데 반해, ResNet은 layer를 깊게 쌓으면 error가 크게 감소하고 있는 것을 보여준다.

차원이 증가할 때, 증가된 차원을 어떻게 맞춰줄 것인가에 따라서도 실험을 진행했다.
A: Zero-padding
B: 차원 증가에만 Zero-padding, 나머지는 No-padding
C: Shortcut projection
모든 옵션의 경우에서 전반적으로 기존의 plain net보다 좋은 성능을 보여주고 있다.
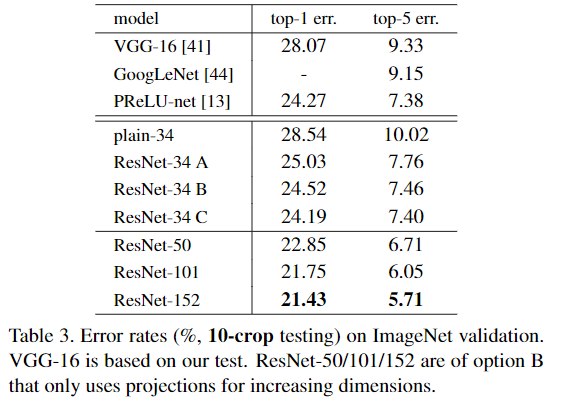
깊은 모델에 대해서는 차원 증가를 맞춰주어 모델을 효율적으로 구성하기 위해, layer들을 bottleneck design으로 수정했다. 이를 통해 identity shortcut을 더 효율적으로 사용할 수 있게 한다.
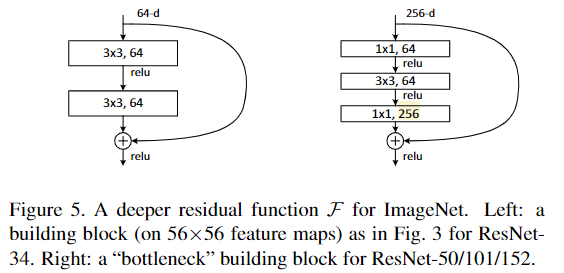
앞서 말했던 방식으로 깊은 모델을 쌓은 ResNet-101/152의 실험결과에서, 깊은 모델에서도 성능하락 없이 정확도가 향상되는 것을 보여주고 있다.
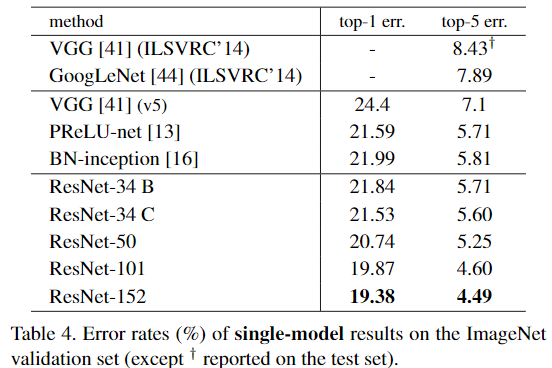
특히 기존의 Sota 모델보다 더 좋은 성능을 보여주고 있다.
(여타 CIFAR-10, PASCAL, MS COCO 데이터셋에서도 실험을 수행하였고, 해당 데이터셋의 특성에 맞게 모델을 변형해가며 진행했다.)
