[Paper Review] Large Language Models are Zero-Shot Reasoners
최근 사전학습된 Large 언어 모델이 자연어 생성 task에서 논리적인 사고를 수행할 수 있도록 예시 정답을 few-shot으로 학습하여 성능을 끌어올리기 위한 몇몇 연구가 존재합니다.
이번에 발표된 해당 논문은 언어 모델이 질문-답변 task에서 답변에 단순한 trigger를 추가함으로 엄청난 성능을 이끌어내었습니다.
1. Introduction
언어 모델을 많은 양으로 학습하는 것은 그동안 큰 성능 향상을 이끌어 왔습니다. 특히 기존의 연구에서 많은 양의 데이터로 학습된 언어 모델을 몇 가지 예시를 few-shot하여 다양한 답변 작업을 해결할 수 있었습니다. 이러한 언어 모델의 조건화 방법을 "prompting"이라고 합니다.
이러한 방식으로 Large Language Models(LLM)이 multi-step 추론 작업을 하기 위해선 모델 학습량을 늘리거나 더 많은 파라미터를 사용해왔었습니다.
단점을 해결하기 위해 최근 연구에서는 chain of thought prompting(CoT), 즉 LLM에게 step-by-step으로 추론할 수 있도록 적절한 예시를 few-shot하는 방법이 제안되었습니다. Chain of thought는 모델이 복잡한 추론을 여러 단순한 step으로 분해해서 추론할 수 있도록 하였습니다.
하지만 few-shot을 위해서는 해당 task에 맞는 특정 답을 사람이 만들어내야 합니다. 해당 논문에서는 LLM에 answering에 심플하게 "Let's think step by step"이라는 prompt를 제안하였고, 이렇게 zero-shot으로 모델이 쉽게 추론을 수행할 수 있음을 발견했습니다. 저자들은 이를 Zero-shot-CoT라고 명명하였고, 특정 task에 구애받지 않고 모델이 문제에 대한 추론을 수행할 수 있었다고 합니다.

위의 그림에서 볼 수 있듯이 답변에 "Let's think step by step"으로 시작하게끔 하여 모델이 문제를 해결에 있어 적절한 추론 과정을 거쳐 정답을 도출할 수 있었습니다.
특히 이런 단일 prompt에 의해 다양한 추론 task를 수행할 수 있음으로 Zero-shot으로 LLM의 능력을 높이기 위해 모델 안에 숨겨진 능력을 발견하기 위한 향후 연구가 기대됩니다.
2. Background
Large language models and prompting
언어모델(LM)은 text에 대해 확률 분포를 추청하는 모델이다. 최근 모델의 크기를 늘리거나 더 많은 데이터로 학습한 Large Language Models은 NLP의 여러 downstream task에 좋은 성능을 보여주었습니다.
기존에 NLP task에서 사용되던 pre-train 및 fine-tune 방식이 아닌, pre-train 및 prompt 방식으로 모델이 few-shot learning으로 원하는 task에 대한 답변을 생성할 수 있는 연구가 진행되었습니다.
Chain of thought prompting
최근의 연구에서 제안한 Few-shot prompting의 예로 Chain of thought(CoT) prompting은 몇 가지의 step-by-step 예시 답변을 LLM에 few-shot함으로써 상당한 성능을 달성했습니다.
Few-shot learning이 여러 어려운 task에 당연시하게 여겨졌고 zero-shot 방식은 고려되지 않았었습니다. 해당 논문에서는 zero-shot learning을 제안하기 위해 기존 방식과 구분하기 위해 이를 few-shot-CoT라고 명명합니다.
3. Zero-shot Chain of Thought
본 논문은 step-by-step의 간단한 예시를 통한 few-shot 없이 모델이 문제를 추론하고 답변할 수 있도록 하는데 목적이 있습니다. Figure1에서 보았듯이 답변에 'Let's think step by step'을 통해 step-by-step 추론을 이끌어냅니다.
3.1 Two-stage prompting
LLM이 정답을 도출하기까지 문제를 추론하고 최종 정답을 내는 것까지 2단계로 prompting합니다.
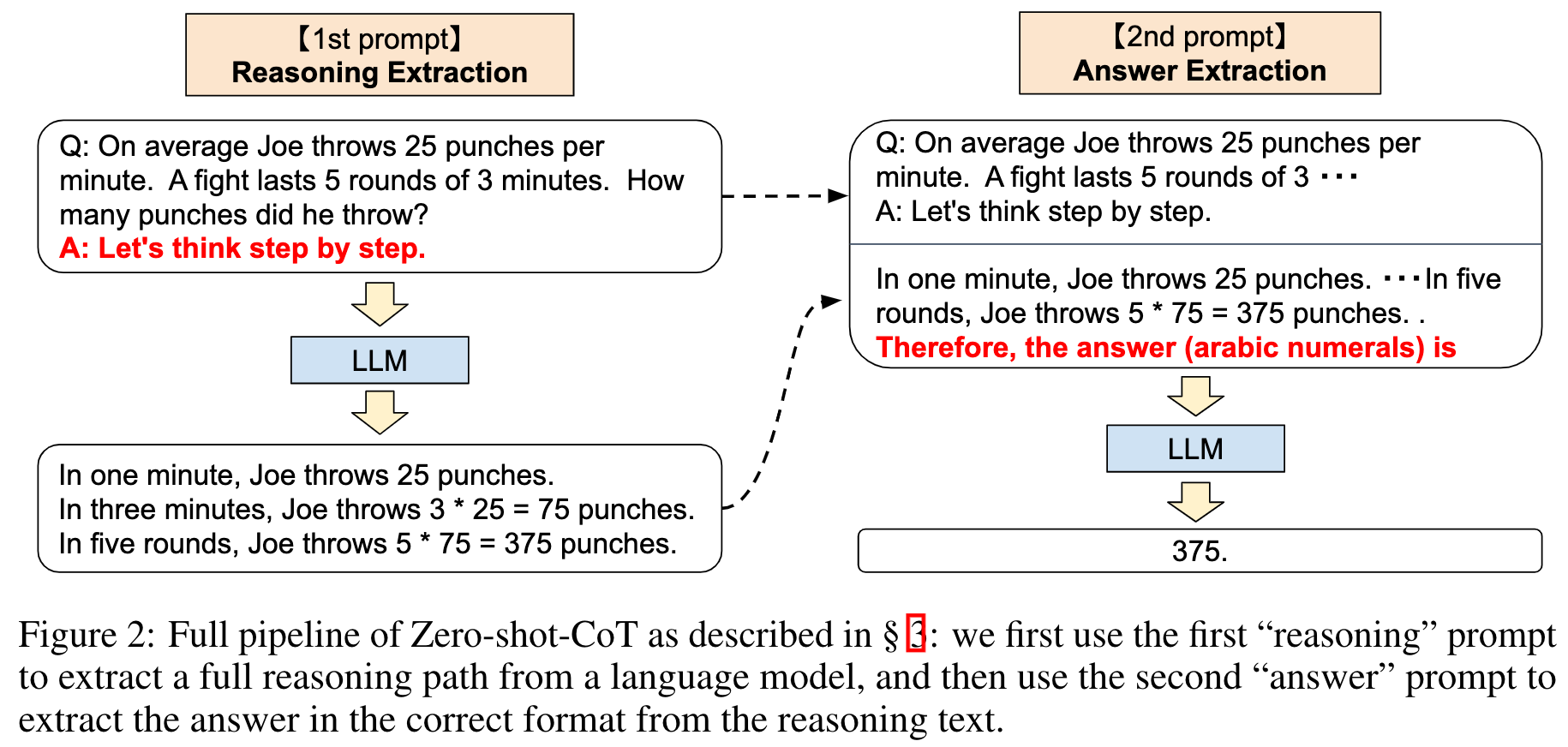
1st prompt: reasoning extraction
1단계에서는 trigger sentence를 통해 답변을 추론하도록 합니다.
먼저 입력 template을 간단하게 수정합니다.
Q: [X]
A: [Z]
[X]는 질문 x를 입력하기 위한 슬롯이고, 1차적으로 답변 부분에 LLM이 추론할 수 있도록 인위적인 trigger [T]를 추가한 즉,prompted된 질문 x'를 모델에 입력합니다.
Figure2의 1st prompt를 보면 이해가 쉽습니다.
2nd prompt: answer extraction
2단계에서는 모델이 추론된 답변으로부터 최종 답변 z를 추출하도록 합니다.
구체적으로 prompted된 질문 [X']와 1차 prompt에서 모델이 생성한 답변 [Z]와 모델이 최종 정답을 추출할 수 있도록 하는 trigger sentence [A], 3개의 요소를 결합합니다.
다만, [A]의 trigger의 경우에는 task에 따라 다른 형식을 사용하여 답변을 추출해낼 수 있습니다.
Figure2의 오른쪽 부분을 보면 됩니다.
4. Experiment
추론 task를 위한 4개 종류의 총 12가지 데이터 셋으로 실험을 수행하였습니다. 또한, LLM으로 13개의 모델을 써보며 비교했습니다.
Zero-shot-CoT
CoT의 효과를 파악하기 위해, 비슷한 prompt를 준 Zero-shot과 비교합니다.
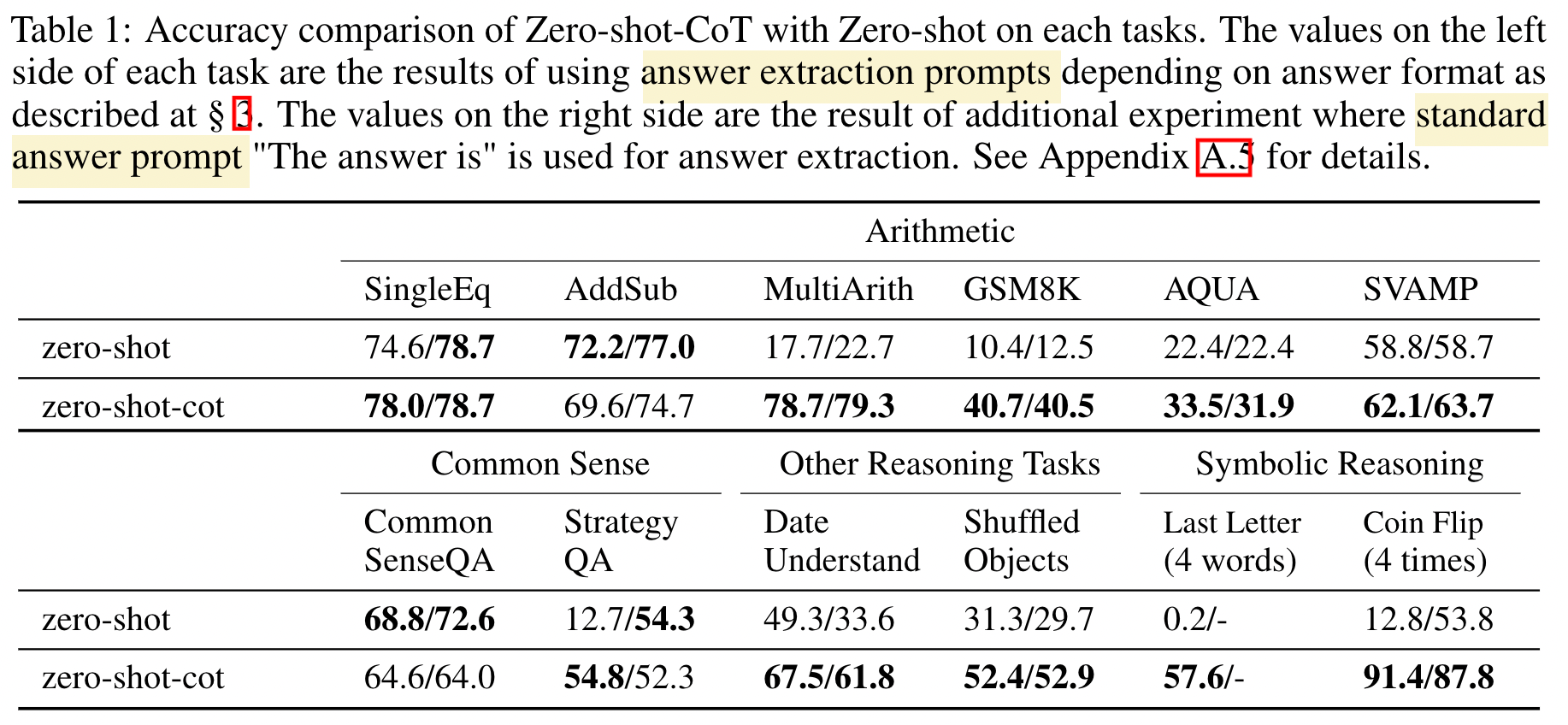
대부분의 task에서 성능이 크게 향상된 것을 볼 수 있습니다. 특히 2개의 arithmetic reasoning task에서 비약적인 성능 향상이 이뤄졌습니다.
CoT가 모델이 논리적으로 추론할 수 있도록 하고, 때로는 사람보다 더 상식적인 추론을 이끌어내었다고 저자들을 밝히고 있었습니다.
Comparison with other baselines
비약적인 성능을 보였던 arithmetic task의 MultiArith, GSM8K 데이터 셋에서 모델에 따른 성능 비교를 수행해보았습니다.
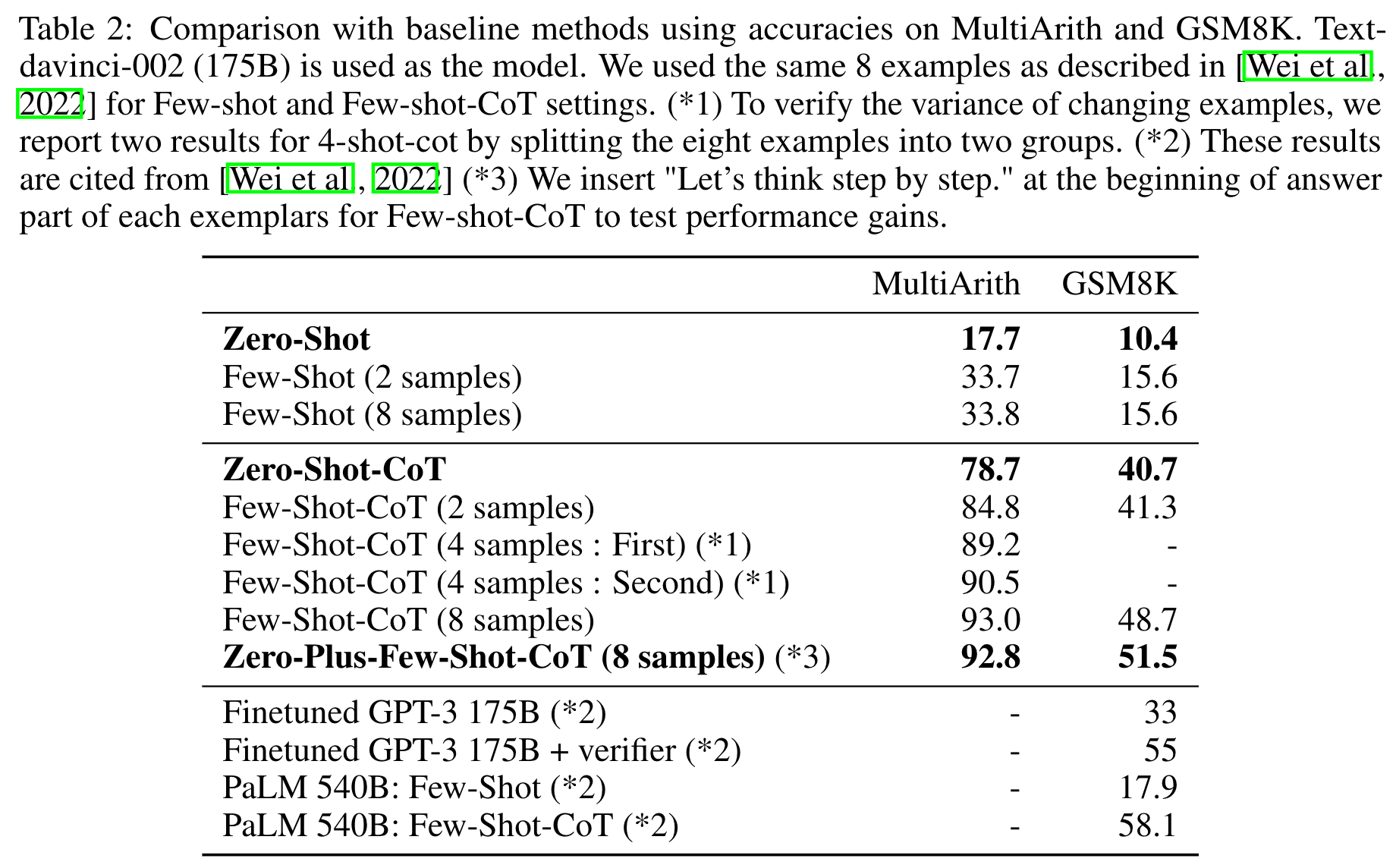
CoT의 유무에 따라 큰 성능차이를 보여주고 있습니다. 이것은 모델이 다단계 추론 없이는 정답을 유추하기 어렵다는 것을 의미합니다.
Error Analysis
Zero-shot-CoT prompt를 사용하였을 때 생성된 예시를 무작위로 뽑아서 살펴보았습니다.

Commonsense reasoning task에서는 Zero-shot-CoT가 정답은 맞추지 못했더라도 상당히 유연하고 논리적인 추론과정을 거치고 있었습니다.
Arithmetic task에서는 Zero-shot-CoT와 Few-shot-CoT의 에러 패턴이 상당히 다르게 나타나고 있었습니다.
Model size
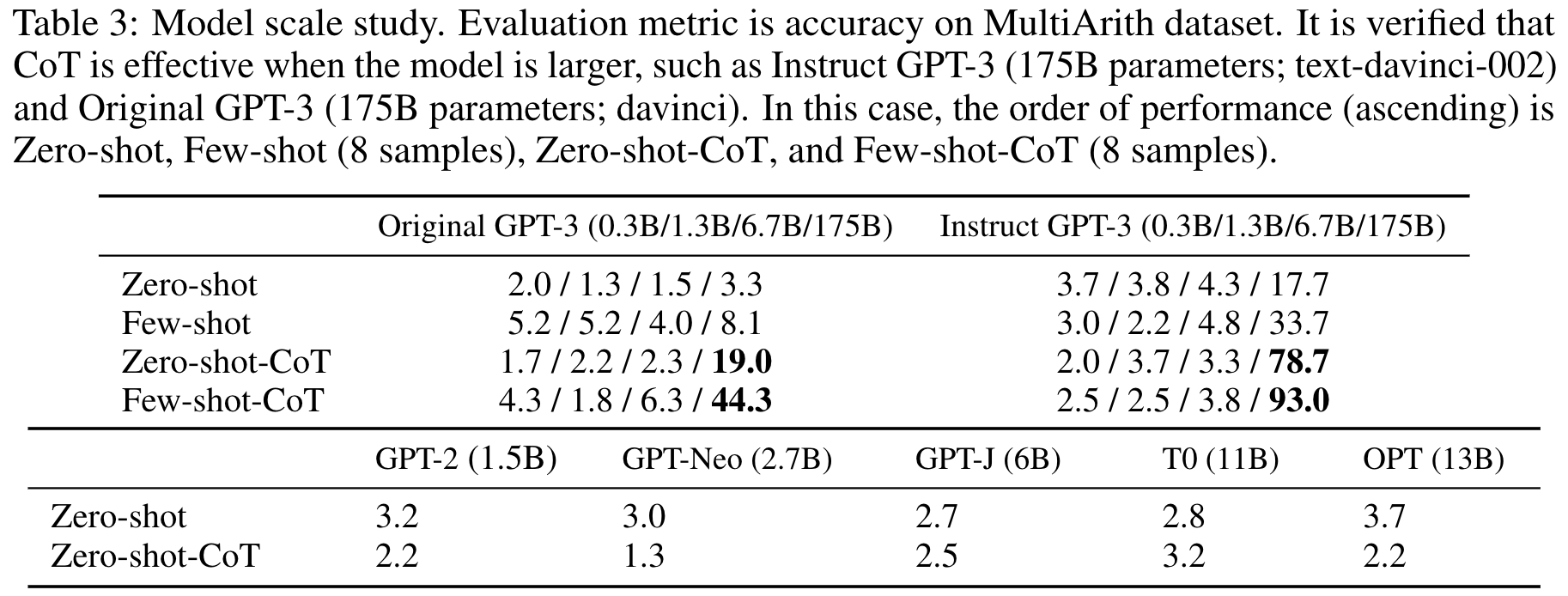
모델의 크기가 커질수록 CoT 추론 성능이 눈에 띄게 향상되고 있었습니다. 다만, 모델의 사이즈가 작을 때는 CoT의 효과는 거의 없었습니다.
Prompt Sentence(Zero-shot)

'Let's think step by step'의 prompt가 가장 좋은 성능을 이끌어냈습니다. 다만, 해당 실험을 통해 chain of thought을 할 수 있도록 prompt sentence를 작성하면 모델의 성능이 향상됨을 알 수 있었습니다.
Prompt Sentence(Few-shot)

추론 task에 맞지 않는 서로 다른 예시를 few-shot 했을 때의 성능을 확인해보았습니다. 다른 domain이지만 같은 답변 format인 경우 few-shot이 zero-shot일 경우보다 성능이 덜 하락되었습니다.(2, 3번째 AQUA-RAT)
6. Conclusion
해당 논문에서는 zero-shot prompt를 통해 large language model이 chain of thought를 수행할 수 있도록 하였습니다.
제안한 zero-shot-CoT를 통해 어려운 step-by-step 추론 작업에 대한 zero-shot baseline을 제시하였고, 특정 task에 한정한 추론이 아니라 광범위한 인지 능력을 이끌어낼 수 있는 multi-task prompt를 발견했습니다.
(본 논문에서의 여러 task에서 더 많은 샘플들은 appendix에 제시되어 있습니다.)
Personal
해당 논문에서는 사전학습된 언어모델이 chain of thought를 할 수 있도록하는 trigger sentence를 발견한 것이 가장 큰 기여점이었습니다.
기존 NLP 관련 여러 연구에서는 모델의 크기를 늘리거나, 학습 데이터양을 늘려 성능을 높이고 있었습니다. 하지만 이러한 방식의 연구를 통한 성능 향상은 한계점에 이른 듯 해보였습니다.
물론, 새로운 아키텍쳐로 더 좋은 성능을 보여주는 모델이 제안될 수도 있지만, 많이 학습된 기존의 Large 언어모델을 새로운 방식으로 사용해보면서(prompt) 엄청난 성능향상을 이끌어 냈다는 것이 매우 흥미로웠습니다.
해당 논문이 나오기 이전에 CoT를 제안했던 선행 논문을 읽어봐야겠습니다.
