[Paper Review] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
모델을 먼저 pre-train하고 목적에 맞는 task에 맞게 fine-tune하는 transfer learning은 deep learning을 활용한 다양한 분야의 강력한 성장을 이루게 하였습니다. 또한, 2017년 발표된 transformer 아키텍처는 여러 NLP task에서 좋은 성능을 달성할 수 있게 해주었습니다. 이후 SOTA를 달성한 여러 언어모델들 또한 주로 transformer 기반입니다.
해당 논문은 새로운 모델을 제안하기보단, NLP의 모든 task를 text-to-text로 변형함으로써 transfer learning을 수행하는데 여러 방법들을 실증적으로 탐색하며 최적의 case를 찾으려 했습니다. transformer의 encoder-decoder 구조를 base 모델로하여 pre-training objectives, architectures, unlabeled data sets, scale 등에 대해 선행 연구들을 인용하여 여러 방식으로 실험해 보았고, 인사이트를 발견한 것에 대해 의미가 있는 것 같습니다. (baseline 모델을 가지고 transfer learning 과정에 많은 부분에 대해 변형을 취해보며, 각 NLP task에 성능을 측정)
1. Introduction
NLP task를 수행하기 위해 machine learning model을 학습시키는 것은 궁극적으로 모델이 다방면에서 text 관련 task를 수행할 수 있도록 text를 이해할 수 있도록하는데 목적이 있습니다.
Vision분야에서 transfer learning이 연구된 이후, 라벨링된 ImageNet과 같은 라벨링된 데이터를 지도 학습하여 pre-train을 수행합니다. 반면, NLP 분야에선 transfer learning을 조금 다르게, 라벨링되지 않은 데이터 셋을 비지도 학습하여 pre-train하는 것이 최근의 추세입니다.
해당 연구의 기본 아이디어는 모든 text task를 “text-to-text” 문제로 해결할 수 있도록 하는 것입니다. text-to-text 방식을 통해 모든 task에 대해 동일 model, objective, training procedure, decoding process를 적용할 수 있기 때문입니다. 이는 transfer learning을 조금씩 변형해보며 서로 효과를 비교할 수 있다는 장점을 가져옵니다.
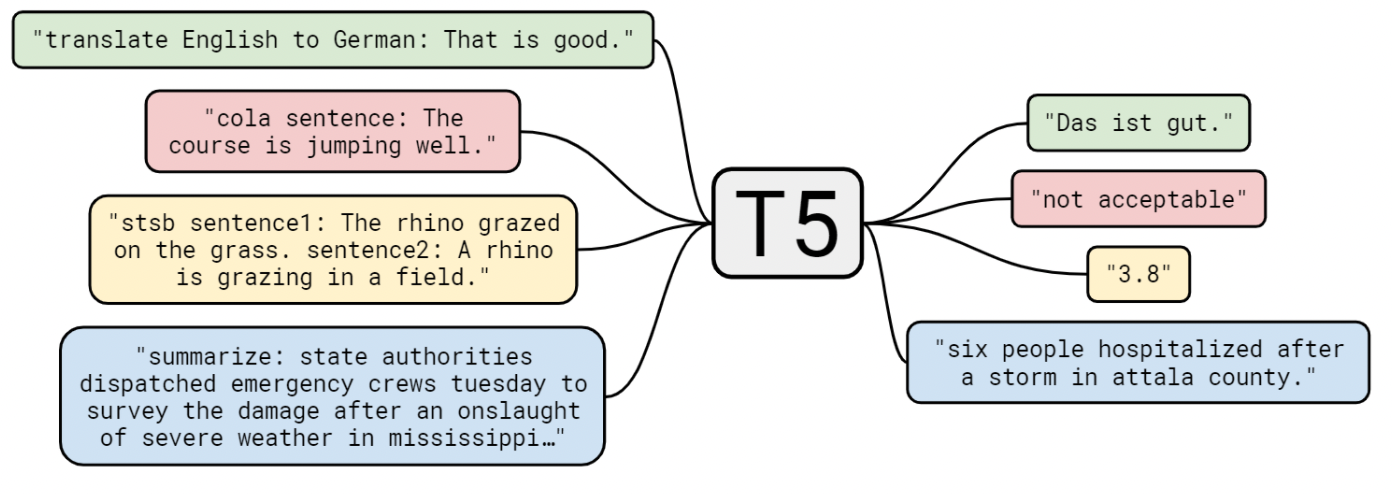
text-to-text 방식으로 바꿈으로 여러 방법론들을 비교할 수 있기 때문에, 본 논문에서는 새로운 방법을 제시하기보단 기존의 주장들을 인용하여 비교실험을 수행하여 인사이트를 얻어내 최종 모델을 제안합니다.
저자들은 이처럼 text-to-text 접근 방식으로 모든 task를 수행하도록 한 모델, 프레임워크를 “Text-to-Text Transfer Transformer” 즉, T5라고 부르기로 정합니다!
2. Setup
여러 방법론의 실험 결과 분석에 앞서, 본 논문에서 사용한 transformer, downstream task 등 필수적인 배경지식을 간략하게 설명합니다.
2.1 Model
초기 NLP의 transfer learning은 recurrent 신경망을 통해 주로 이뤄졌습니다. 하지만 transformer가 등장한 이후 NLP에서는 transformer를 기반으로하는 모델이 일반적입니다.
Transformer는 encoder-decoder 구조로 구성됩니다. 구조는 문장 sequence의 각 요소를 서로 참조할 수 있도록 한 self-attention들로 이루어져 있습니다. 다만, 이후 등장한 언어모델에서는 transformer의 encoder만 사용하는 등 목적에 맞도록 다양한 형태로 변형한 후속 연구들이 이어졌습니다.
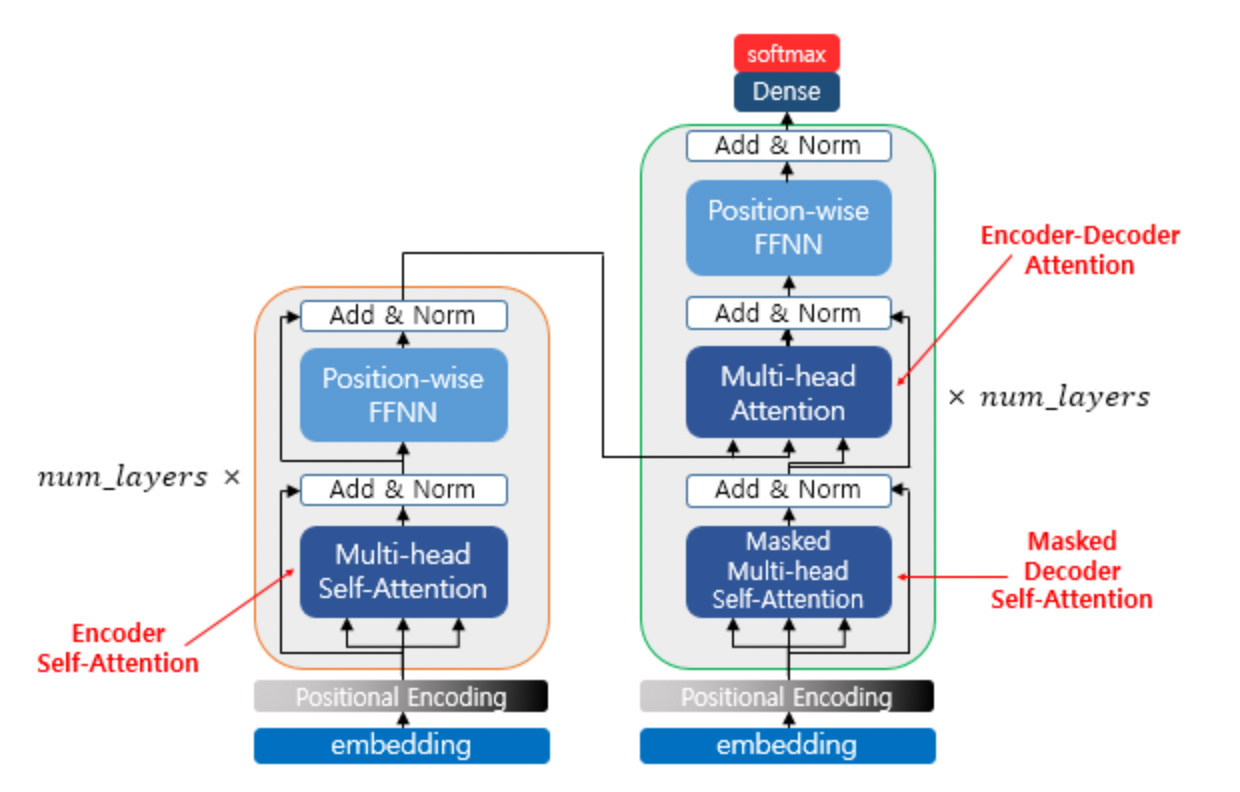
본 논문에서는 original transformer의 기본 형태를 모델로 사용합니다만, 조금의 수정을 적용합니다.
- 활성함수가 rescale되는 단순한 normalization
- 추가적인 bias는 적용되지 않음
- Positional encoding에서 relative position embedding 사용(original 논문에서는 sinusoidal position signal or learned position embedding)
- 위의 relative position embedding parameters를 모델의 모든 layer에서 공유(layer 내에 각 attention head는 서로 다르게 position embedding 학습)
2.2 The Colossal Clean Crawled Corpus (Dataset)
모델을 효과적으로 pre-train하기 위해서는 unlabeled datasets도 중요하다. 저자들은 unlabeled data의 quality, characteristics, size 등을 바꿔가며 실험해봅니다.
- 웹에서 텍스트를 크롤링하여 새로운 데이터 셋 생성
- 매달 약 20TB 분량의 데이터 셋
수집한 raw 데이터 셋은 자연어로만 구성된 것이 아니기 때문에 전처리 작업이 필요합니다. 저자들은 경험적으로 설정한 기준에 맞게 수집한 데이터들을 전처리 하였습니다. 또한, 영어에 한해 downstream task를 수행하기 때문에 영어가 아닌 페이지는 삭제하였습니다.
2.3 Downstream Tasks
이후 저자들은 NLP의 여러 task에 대해 downstream task를 수행했는데요. text 분류 벤치마크인 GLUE와 SuperGLUE, 추상적 요약 task인 CNN/Daily Mail, 질문 답변 task인 SQuAD, 영어를 독일어 프랑스어 루마니아어로 번역하는 task인 WMT 작업을 수행합니다.
2.4 Input and Output Format
하나의 언어모델로 다양한 task를 수행하기 위해, 해당 논문에서는 2.3에서 언급된 모든 task 작업을 text-to-text 형태로 변환합니다.
모델이 수행해야되는 작업을 알려주기 위해 input sequence에 task-specific prefix를 추가합니다. 예를 들어, “That is good.”이라는 영어 문장을 독일어로 번역하고자 하는 task라면, “translate English to German: That is good.”으로 입력하고 모델은 “Das ist gut.”라고 출력하는 것입니다.
이를 위해 각 개별 task에 대해 모델을 개별적으로 fine-tune하고 prefix를 통해 모델이 무슨 task를 수행해야 하는지 명시적으로 알려주어 output을 얻습니다.
3. Experiments
최근 NLP 분야에서 transfer learning은 pre-training objectives, model architectures, unlabeled datasets 등 여러 기술의 개발을 통해 발전을 이뤄왔습니다. 저자들은 NLP task의 성능을 올리기 위해 발전되어 온 여러 기술의 개발에 대해 실험해보며 중요성을 조사해보았습니다. 이후 실험을 통해 얻은 결과들을 통해 각종 NLP task에서 좋은 성능을 낼 수 있도록 결합하였습니다.
이를 위해 baseline을 설계한 뒤, 설정을 하나씩 바꿔가며 각 기술이 성능에 기여하는 정도를 측정해갑니다.
3.1 Baseline
Model
저자들은 encoder-decoder 구조를 그대로 사용하는 것이 생성, 분류 task 둘 다에서 좋은 결과를 보여주는 것을 알았고, 따라서 original Transformer 구조를 baseline 모델로 사용합니다. 아래의 설정과 같이 모델을 구성하였고, 이 경우에 parameter는 220M 이라고 합니다.
- 모델은 BERT_BASE 모델의 구성과 같이 12개 블록으로 구성된 encoder, decoder를 사용
- feed-forward network는 output 차원이 인 dense layer와 ReLU로 구성
- Transformer attention은 64차원의 key와 value 행렬()과 12개의 attention head로 구성
- 다른 모든 sub-layer와 embedding들은 768차원()
Train
모델의 사전학습을 위한 hyperparameter들은 원문에 상세하게 나와있습니다.
Vocabulary
SentencePiece를 사용하여 text를 WordPiece 토큰으로 인코딩하여 실험을 수행합니다. 실험에서는 32,000개 단어에 대한 사전을 구축하고 인코딩합니다.
(추가적으로 번역 task를 위해 독일어, 프랑스어, 루메니안어 단어도 인코딩하였습니다.
Unsupervised Objective
Unlabeled data를 사용해 모델을 pre-train하기 위해선 label을 요구하지 않지만 downstream task를 잘 수행하기 위해 일반화된 지식을 학습시킬 수 있는 objective가 필요합니다.
기존 NLP 분야에서는 causal language modeling objective를 사용했었지만, input sequence의 일부를 missing하거나 corrupted한 뒤 모델이 원래의 토큰을 예측하는 denoising objective가 등장한 이후 표준으로 자리매김 하였습니다.
하지만 저자들은 denoising 방식을 조금 수정하였습니다. 기존에는 일부 토큰을 corrupted 하고 전체 sequence를 예측하는 방식이었지만, corrupted된 토큰만 맞추는 방식으로 말이죠.

- input sequence에서 15%의 토큰을 랜덤으로 drop out
- drop out된 연속된 토큰들의 자리는 하나의 sentinel 토큰으로 대체
- Target은 drop out할 때와 동일한 sentinel 토큰을 사용하며, sequence의 끝을 의미한 final sentinel 토큰을 추가로 사용
Baseline Performance
저자들은 baseline을 10번 pre-train하였고, 이어 각 downstream task에 대해 step 수행하여 모델의 성능을 측정하였습니다.

baseline모델로 모든 task에 대한 실험 결과이고 score는 아래의 기준으로 산정했다고 합니다.
- GLUE, SGLUE 모든 하위 task의 평균 점수
- 번역 task는 BLEU score
- CNN/Daily 요약 task는 ROUGE-2-F score
- SQuAD 질문 답변 task는 “exact match” score
실험 결과는 대체적으로 모델 크기가 비슷한 기존의 모델과 비슷했습니다. 또한, pre-train이 거의 모든 task에서 중요하게 기여하고 있음을 확인했습니다.
3.2 Architectures
해당 장에서는 아키텍처를 변형해보며 실험해보고 비교했습니다.
Model Structures
모델의 구조에 따라 making 방식을 다르게 적용하기 때문에 masking 방식에 대해서도 간략히 설명합니다.
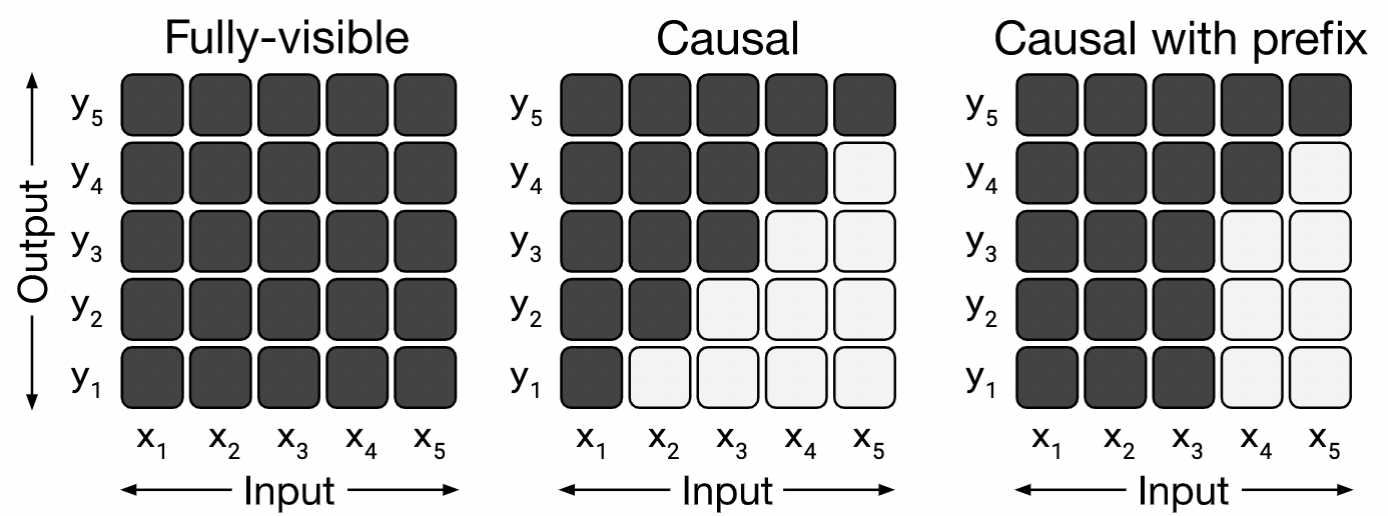
- fully-visible attention mask는 output sequence를 생성할 때 input의 모든 요소를 self-attention할 수 있음 (그림 좌측)
- casusal attention mask는 output sequence의 번째 요소를 생성할 때 모델이 input sequence의 에 대한 번째 요소를 attention하는 것을 방지하여 output 정답을 보지 못하게 함 (그림 가운데)
- causal with prefix attention mask는 causal mask에서 input sequence에서 일부 prefix는 fully-visible (그림 우측)
이어 저자들은 여러 모델의 구조를 고려해보았습니다.
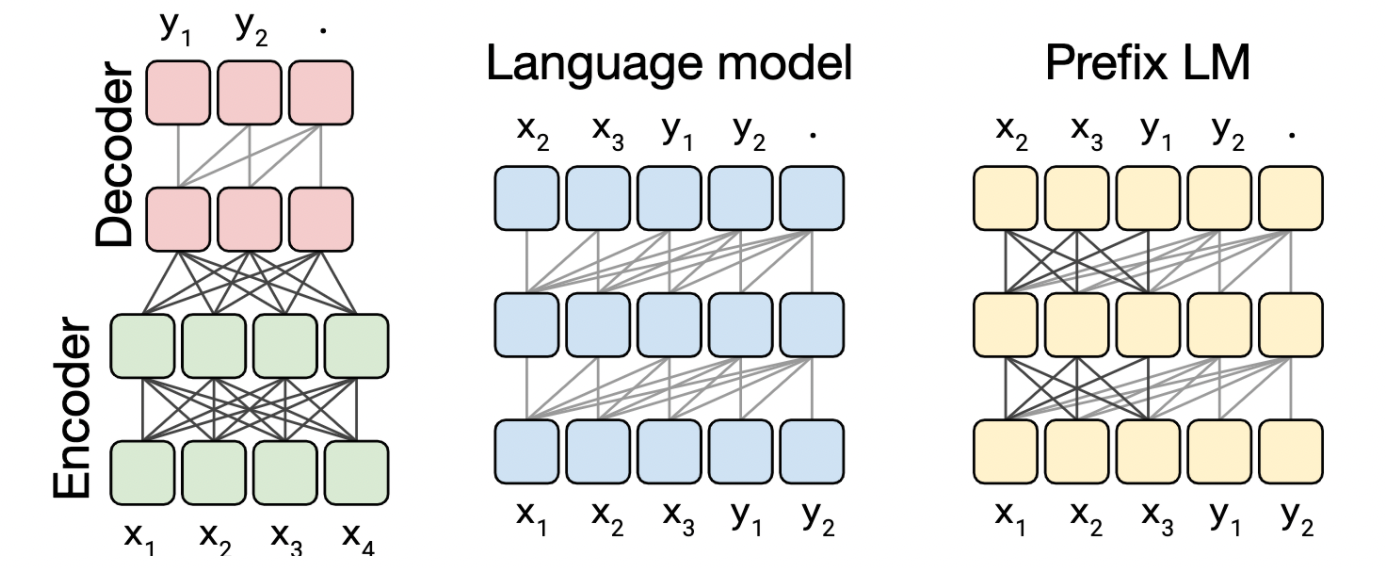
- Transformer의 encoder-decoder 구조(그림 왼쪽)
- input sequence를 받는 encoder, output sequence 생성하는 decoder
- encoder는 fully-visible, decoder는 causal 방식의 maksing
- Transformer의 encoder나 decoder 하나의 layer stack만으로 구성된 언어모델(그림 가운데)
- input에 “English to German: That’s good. target:”과 같이 주고 나머지 정답 부분을 예측
- casual 방식의 masking
- Transformer의 decoder layer stack(그림 오른쪽)
- causal with prefix 방식의 making
- text-to-text 방식으로 task를 수행하기 때문에, 입력 sequence의 prefix부분을 모두 attending할 수 있도록 LM 방식을 개선
저자들은 objective로 기존의 baseline과 basic LM에서 사용한 denoising 방식과 조금 수정한 denoising objective를 사용합니다.
고려했던 여러 모델 구조에 따른 실험 결과입니다.
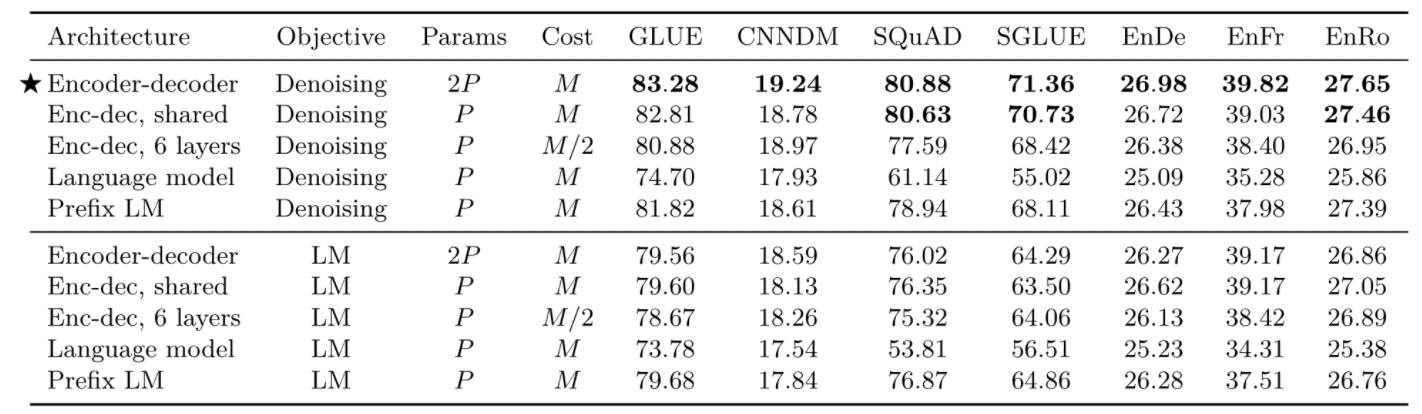
- encoder-decoder 구조의 denoising objective로 사전학습 한 모델이 가장 좋은 성능
- 저자들이 주장한 denoising objective가 좋은 성능을 보여줌
3.2 Unsupervised Objectives
이번 장에서는 모델을 pre-train 간 여러 objective를 사용해가며 실험합니다. 먼저 high-level 접근 방식의 objective들 입니다. 토큰을 corrupted하는 방식과 target을 맞추는 방식이 다른 것을 확인할 수 있습니다.

실험 결과입니다.

- BERT-style의 denoising 방식의 objective가 대체로 좋은 성능을 보여줌
저자들은 추가로 BERT-style Objective들을 text-to-text task에 효율적이도록 수정해보며 추가적인 실험을 수행하였고, 실험 결과입니다.

- Replace corrupted spans; 일정 길이의 토큰을 다른 토큰으로 corrputed하고 예측하는 방식이 대체로 좋은 성능
- target token만 예측하는 방식이므로 training이 속도 측면에서 이점이 있음
- GLUE task의 경우에선 drop 방식이 더 높게 나왔지만, GLUE의 하위 task인 CoLA에서 크게 높은 성능을 보여 평균 점수가 올라간 것임
앞서 Replace corrupted spans 방식이 가장 좋은 성능을 보였는데요. 그렇다면 input sequence를 얼만큼 corrupted해야 하는지 결정하기 위해 추가 실험을 진행합니다.

- 전반적으로 corruption 비율은 모델의 성능에 크게 영향을 미치진 않음
- corruption 비율이 높아질수록 training이 오래 걸릴 수 있기 때문에, BERT에서 선택한 비율과 같이 15%의 corruption 비율을 사용하기로 결정
또한, corrupting spans에서 span의 길이를 얼만큼 해야 할지도 실험적으로 결정합니다. (개별 토큰을 corrupted하는 것보다 일정 범위의 토큰을 corrupted하는 것이 속도적으로 이점)
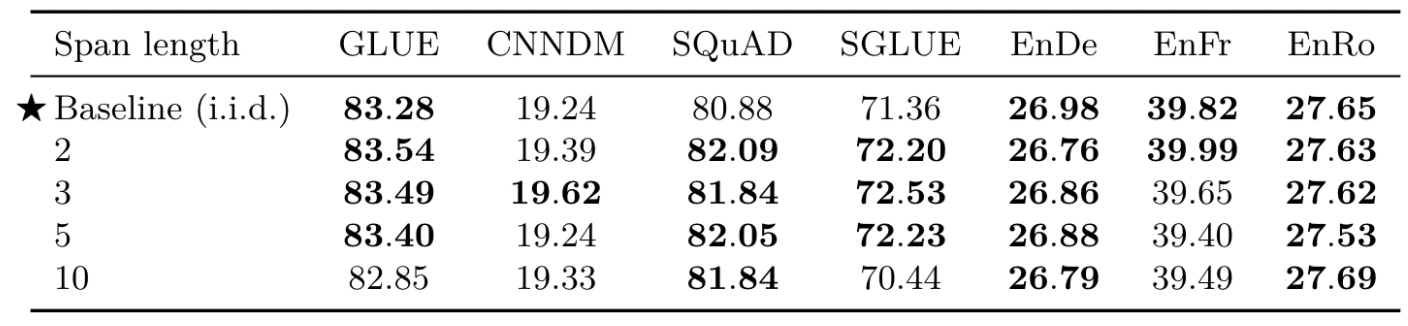
- 성능 차이에 큰 변화가 없었고, span의 길이가 10 이상이면 약간의 저하가 일어나고 있었음
- 평균 span 길이가 3일 때 대체적으로 약간 좋은 성능을 보여주고 있었음
결과적으로, 해당 장에서는 아래와 같은 flow로 unsupervised objective를 결정했습니다.
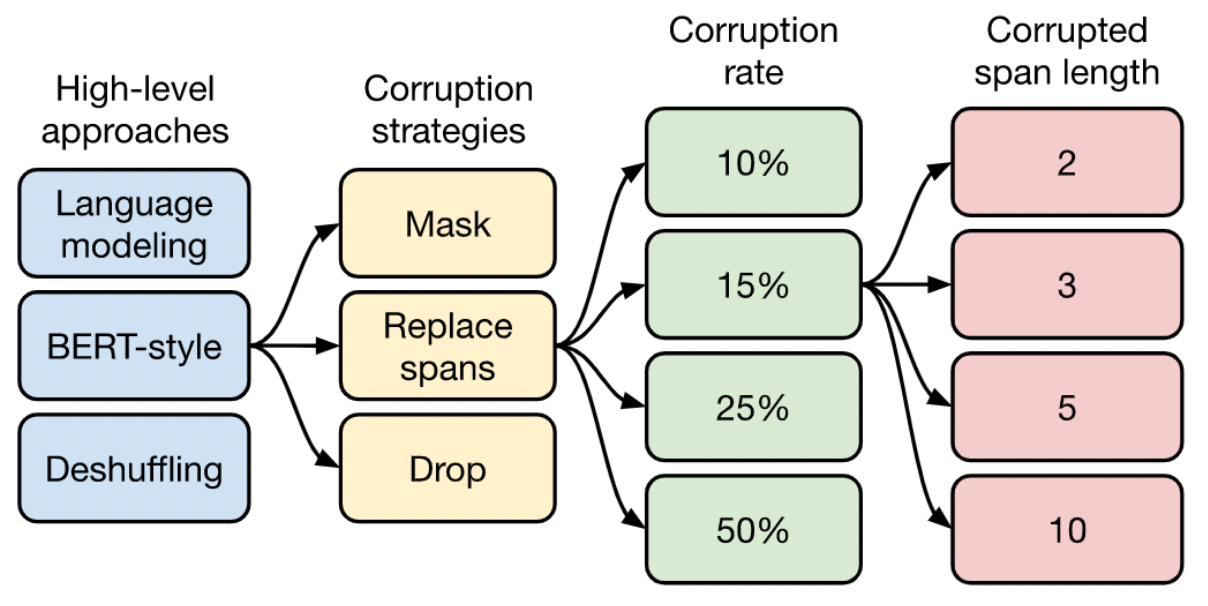
3.4 Pre-training Data Set
저자들은 pre-traing을 위한 data set에 관해서도 실험을 수행하였는데요.
Unlabeled Data Sets
저자들이 수집한 C4 dataset이 효과적인지 확인하기 위해 다른 데이터 셋으로도 pre-train해보며 실험을 수행해보았습니다. 웹 크롤링으로 수집하고 전처리한 C4 dataset, 전처리하지 않은 C4, 실제 뉴스 웹페이지로부터 수집한 RealNews-like, 웹 페이지의 여러 내용들을 수집한 WebText-like, 위키피디아 내용들인 Wikipedia, 위키피디아에 ebooks의 말뭉치를 추가로 수집한 Wikipedia+TBC 가 비교대상입니다.
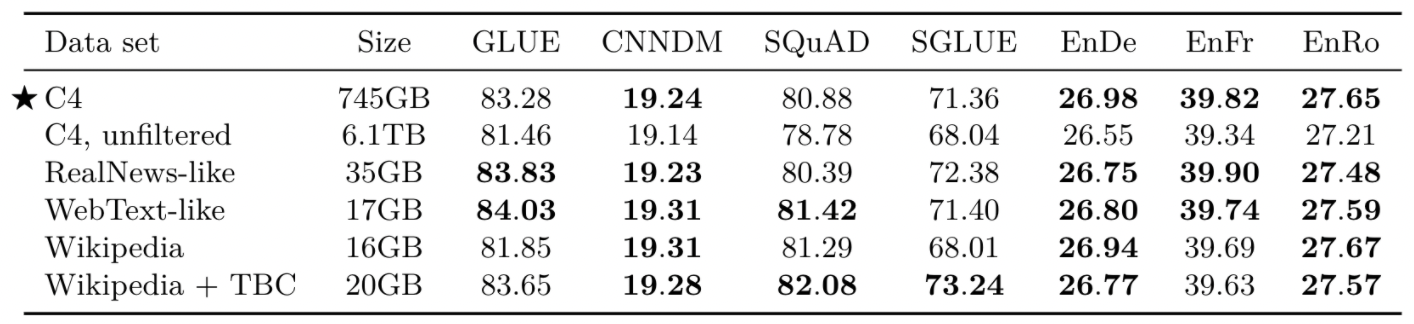
- 도메인이 한정된 dataset으로 pre-train한 것이 때로는 더 좋은 성능을 보여줌
- downstream task와 비슷한 도메인의 unlabeled dataset으로 pre-train하는 것이 task의 성능을 향상시켜 줄 수 있음을 의미
- 다만, 단일 도메인에 대한 pre-train은 dataset의 크기가 작다는 점
Pre-training Data Set Size
저자들은 baseline의 모델의 pre-train을 토큰으로 기본 설정했었습니다. 이번엔 C4 데이터 셋의 크기를 제한해보며 데이터 셋 크기에 따른 효과를 실험해보았습니다. 또한, 모델이 데이터를 반복적으로 학습했을 때의 성능도 확인합니다.

- 데이터 셋의 크기가 줄면 성능이 저하됨
- 데이터 셋을 줄이고 반복이 높아지면 모델이 데이터 셋을 단순히 기억하기 시작할 수도 있음을 의미
3.5 Training Strategy
앞서 모델은 unsupervised pre-train 과정을 거친 후, 각 task에 대해 fine-tune 했습니다. 해당 장에서는 모델을 pre-train 할 때, fine-tune을 수행하는 2가지 방식과 task에 맞는 fine-tune을 동시에 수행하는 multiple task 접근 방식을 실험해봅니다.
Fine-Tuning Methods
저자들은 fine-tune동안 adapter layers만 조정하고 나머지 부분은 고정하는 전략으로 feed-forward의 차원을 바꿔보며 수행해보고, 또한 fine-tune이 순차적으로 진행됨에 따라 맨 끝 layer부터 파라미터들을 조정해가는 gradual unfreezing 방식을 비교해보았습니다.
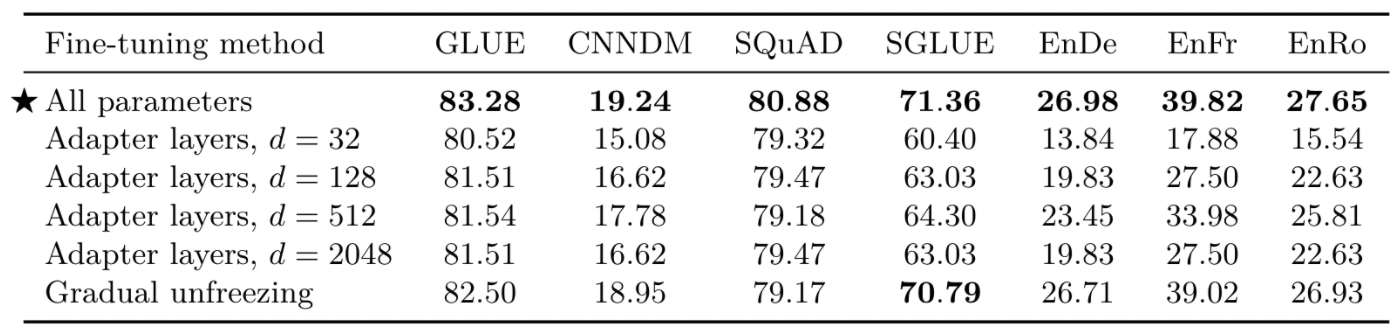
- 본 논문에서는 low-resource인 GLUE와 SuperGLUE는 데이터 셋을 합쳐 fine-tune하기 때문에, low-resource임에도 불구하고 큰 값을 필요로 함(기존 low-resource는 값이 커지면 성능이 저해됨)
- gradual unfreezing 전략은 약간의 성능 저하를 보여주지만, 속도에 대한 이점은 있음
Multi-task Learning
다음은 모델을 각 task별로 따로 fine-tune하는 것이 아니라, 한 번에 여러 task에 대해 학습하는 전략입니다. 모든 task에 대해 모델을 학습하지만, 각 task별로 좋은 성능을 보일 때에 checkpoint를 선택합니다. multi-task learning에서 중요한 것은 각 task의 데이터 셋 크기이기 때문에, 어떻게 학습 data를 구성할지 탐색해보았습니다.
- Examples-proportional mixing: 각 task의 데이터 셋 사이즈의 비율만큼 샘플링 (K는 인위적인 데이터 셋 사이즈 제한 parameter)
- Temperature-scaled mixing: 데이터 셋 크기간 차이 완화를 위해 혼합 비율을 T정도로 조절
- Equal: 각 batch의 데이터 셋을 구성할 때, 모든 task의 데이터 셋을 합친 상태에서 무작위로 샘플링
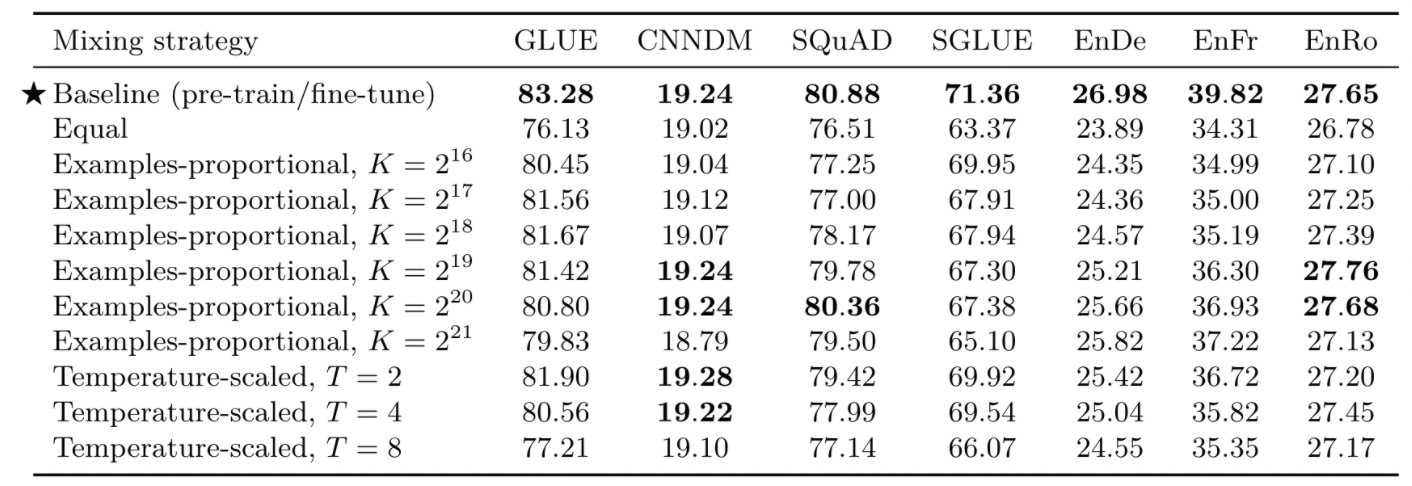
- Multi-task training은 기본적으로 pre-training-then-fine-tuning 전략보다 성능이 저하됨
- equl 전략의 경우 low-resource task에서 overfit되는 등 성능이 크게 저하됨
- Examples-proportional에서 특정 task에서 좋은 성능을 보여주는 sweet spot이 있음
- Temperature-scaled에서는 T=2일 때가 가장 괜찮은 성능을 보여줌
Combining Multi-task Learning with Fine-tuning
선행 연구들에서 multi-task 모델이 각 개별 task별로 분리해 학습하는 것보다 좋은 성능을 보여준다고 밝힌 바 있어, 저자들은 multi-task training과 pre-train-then-fine-tune 방식을 비교 실험해보았습니다.
multi-task training는 3가지 변형을 추가로 고려했습니다.
- 각 개별 downstream task를 fine-tune하기 전 pre-train에서 examples-proportional mixture, 로 샘플링한 데이터 사용
- 각 개별 downstream task를 fine-tune하기 전 pre-train에서 examples-proportional mixture, 로 샘플링한 데이터를 사용하지만, 해당 task에 대한 데이터 셋은 pre-train에선 제외하고 fine-tune에서 유일하게 사용
- 각 개별 downstream task를 fine-tune하기 전 pre-train에서 examples-proportional mixture, 로 샘플링한 데이터를 사용하지만, supervised로 pre-train 수행

- fine-tuning after multi-task pre-training 전략이 비교적 좋은 성능을 보여줌 (baseline과 거의 동등하게)
3.6 Scaling
해당 장에서는 모델의 사이즈를 늘려보면서 성능을 비교해보았습니다.
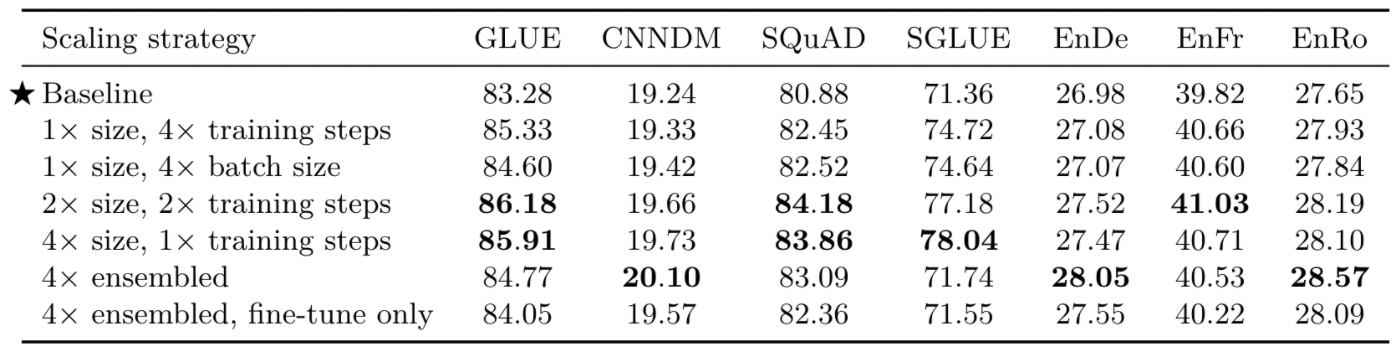
- 당연하게, training time and/or model size를 늘림에 따라 더 좋은 성능을 보여줌
- 4x ensembled, fine-tune only는 pre-train된 모델에 대해 4개의 fine-tuning한 모델을 앙상블한 것인데, 비교적 괜찮은 성능을 보여주기 때문에 cost적으로 의미가 있음
다만, 큰 모델을 pre-train하고 fine-tune하는 것은 비용이 많이 들기 때문에, 저자들은 작은 모델을 pre-train time을 늘리고 fine-tune하는 것이 더 효율적이라고 주장했습니다.
3.7 Putting It All Together
앞서 저자들은 NLP 모델의 transfer-learning을 여러가지 방식에 따라 실험해보았습니다. 각 방식에서의 이점들로 baseline을 수정하고 보완합니다. 이후 최종 transfer learning을 위한 Transformer encoder-decoder 모델을 제안합니다.
Objective
- denoising: mean span length of 3 and corrupt 15% of the original sequence
Longer training
- pre-train our model for 1 million steps on a batch size of sequences of length 512
- C4 dataset을 pre-train에 사용
Model Size
smaller model이 제한된 computing resources에서 이점이 있지만, 다양한 모델 사이즈로 실험 수행
- Base: baseline
- Small: , , 8-headed attention, 6 layers encoder & decoder
- Large: , , , 16-headed attention, 24 layers encoder & decoder
- 3B: , , , 32-headed attention, 24 layers encoder & decoder
- 11B: , , , 128-headed attention, 24 layers encoder & decoder
Multi-task pre-training
fine-tuning after multi-task pre-training 전략 즉, unsupervised와 supervised를 섞어 fine-tune하는 것이 효과적이었습니다. 따라서 저자들은 해당 전략을 사용하며, example-proportional mixing, 를 사용하여 샘플링한 데이터 셋으로 pre-train합니다.
Fine-tuning on individual GLUE and SuperGLUE tasks
GLUE와 SuperGLUE task의 경우 low-resource이기 때문에 같은 setting으로 fine-tune하면 overfit이 우려되므로 개별적으로 fine-tuning합니다. GLUE와 SuperGLUE task 각각에 대해 수행합니다.
- batch size of 8 length-512 sequences
Beam search
대부분의 task에서는 greedy decoding을 사용하며, 일부 long output sequence를 요구하는 WMT 번역 및 CNN/DM 요약 task에 대해서는 beam search를 사용합니다.
- beam width of 4 and a length penalty of
Test set
- validation set이 아닌 test set에 대한 결과
Setting
- baseline과 동일한 hyperparameters로 실험 수행
최종 실험 결과입니다.
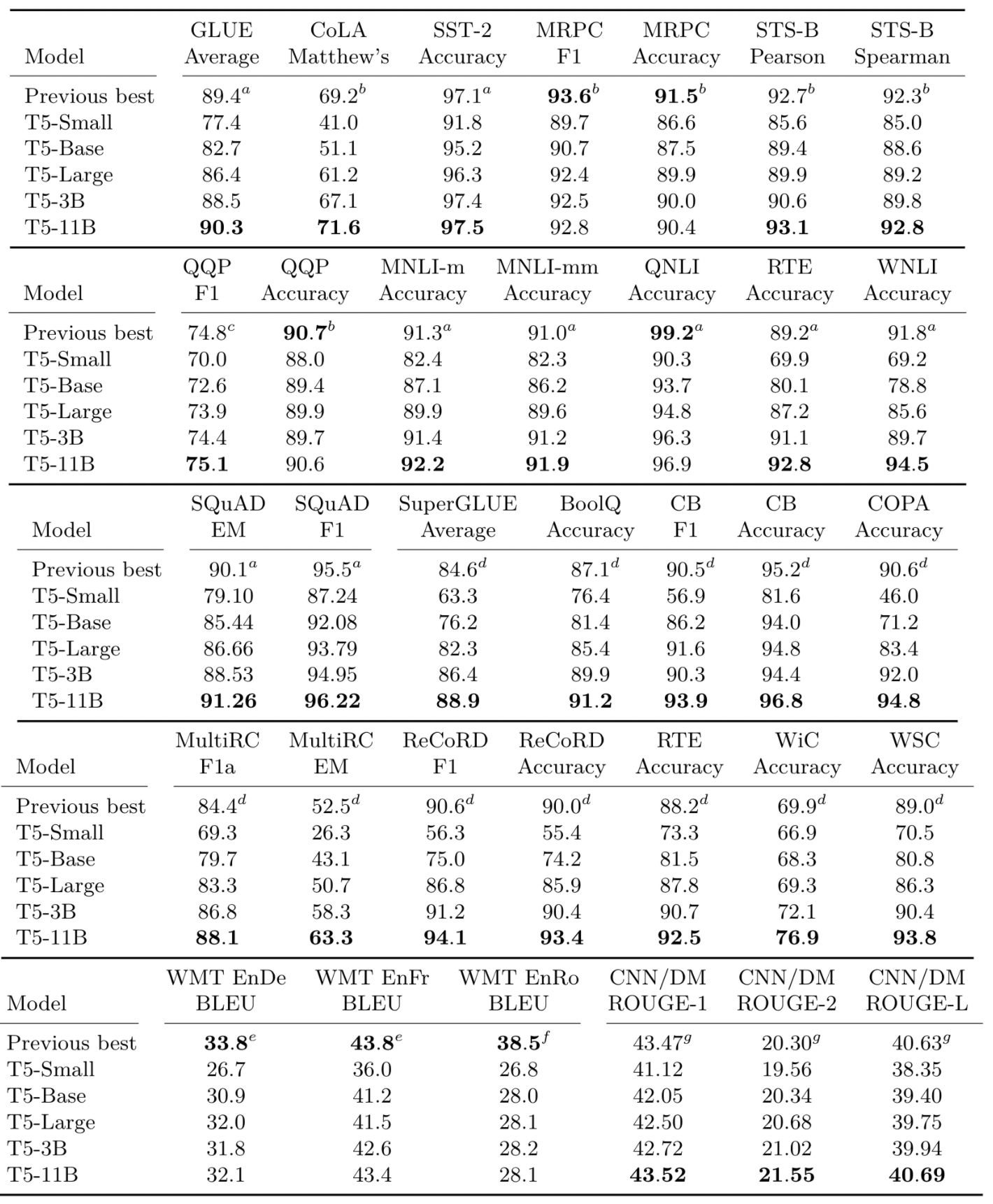
- 24개의 task 중 18개에서 SOTA를 기록함
- 모델 사이즈가 가장 클 때(11B) 제일 좋은 성능을 보여줌, 가장 좋은 성능을 보여주는데 모델 사이즈 확장이 중요한 요소였음..
- 번역 task에서는 SOTA를 달성하지 못함 → English-only unlabeled data set을 사용했기 때문으로 추정(보통 backtranslation을 사용하여 좋은 성능을 보여주었음)
저자들은 단순히 모델 사이즈의 변화가 아닌, baseline과 비슷한 수준의 제안된 T5 모델이 성능을 알고 싶어했습니다.

- 제안한 T5 모델이 가장 좋은 성능 → 추가적인 pre-training이 전반적인 성능 향상을 이끌었다는 것을 의미함
- baseline의 모델 사이즈를 키운 것보다 제안된 T5 모델이 더 좋은 성능을 보여줌
본 논문에서 제안한 text-to-text 방식은 모든 task에 대해 동일한 loss function, decoding을 수행할 수 있도록하면서 여러 transfer learning의 method를 수행해볼 수 있었습니다.
실증적으로 original encoder-decoder 구조가 text-to-text에서 가장 좋은 성능을 보여주고 있었습니다. 또한, denoising 방식의 unsupervised objectives를 사용하되, pre-train 간의 computing이 효율적이도록 짧은 span을 사용하는 것이 좋다고 밝혔습니다. 데이터 셋은 in-domain unlabeled data를 사용하는 것이 downstream task에서 성능을 향상시킬 수 있었지만, in-domain dataset의 크기가 작을 경우 오히려 성능을 저하시키기 때문에 방대하고 일반적인 C4 dataset을 사용하였습니다.
Training 전략으로는 fine-tuning after pre-training이 unsupervised pre-training보다 비교적 좋은 성능을 보이고 있었기 때문에 해당 전략을 사용합니다. 또한, 모델의 크기가 계속해서 키우는 것보다 때로는 더 작은 모델과 training step을 더 많이 가져가는 것이 더 좋은 성능을 보이기도 했습니다.
다만, 본 연구의 한계점과 개선점이 존재하기도 합니다. 최종 실험 결과에서 사이즈가 큰 모델이 대부분의 task에서 SOTA를 달성했기 때문에 비용이 많이 든다는 단점이 있습니다. 그리고 이런 단순한 방식의 pre-train이 모델에 general-purpose knowledge를 학습시키는데 효율적이라고 장담할 순 없다고 밝혔습니다. 또한, 번역 task에 대해서는 English-only pre-training으로 인해 좋지 못한 성능을 보였기 때문에, 궁극적으로는 언어에 영향받지 않은 모델의 필요성을 제기하며 논문을 마무리 하였습니다.
